Tomato leaf distortion virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_002824485.1 |
| Isolate |
Brazil |
| Release date |
2018/8/25 |
| Submitter |
Castillo-Urquiza,G.P., Beserra,J.E. Jr., Bruckner,F.P., Lima,A.T., Varsani,A., Alfenas-Zerbini,P., Murilo Zerbini,F., Beserra,J.E.A. Jr., Lima,A.T.M., Zerbini,P.A., Zerbini,F.M. |
| Host |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
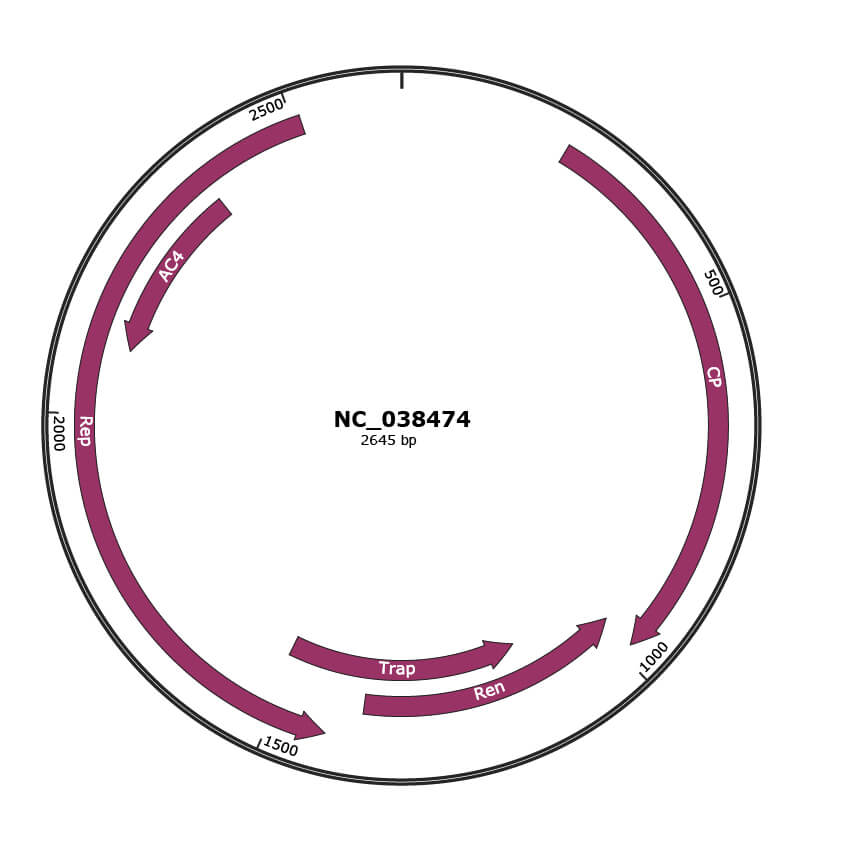
JBrowse
Genome
ACCGGATGGCCGCGCGATTTTTTGCCCCCCGCACGTGGCGCTTTTGTGGCCGCTGGATATTTTTCTCCCGCGCGCTGTACTCTTTAATTCTAATTAAAGGTATAACTTTAGTTTCCACCAATGATAGTGCGCCTGGGAAGTCTAGATATGTGCGCGATACTTGGGGCCGAAGTTGTTGATCAACGGCTATAAATTAAAAGAAGACTGACCACAGTCTTTAATTCATAATGCCTAAGCGGGATGCCCCGTGGCGCCTGATGGCGGGAACTTCGAAGGTTAGCCGCTCTTCCAATTTCTCCCCCCGTGGAGGTGGAGGCCCAAAGTTCAACAAGGCCTCGGAATGGGTTAACAGGCCCATGTACAGGAAGCCCAGGATATATCGGACGCTGAGAACGCCTGATGTCCCTAGAGGCTGTGAAGGGCCCTGTAAGGTCCAGTCCTACGAGCAGCGTCACGACATCTCACATGTCGGTAAGGTGATGTGCATTTCTGATGTGACACGTGGTAATGGTATTACCCACCGTGTCGGTAAGCGTTTCTGCGTTAAGTCTGTGTACATTTTAGGTAAGATATGGATGGACGAGAACATCAAGCTGAAGAACCACACGAATAGTGTCATGTTCTGGTTGGTCAGAGATCGTAGACCGTATGGTACTCCTATGGACTTTGGCCAGGTGTTCAATATGTTTGACAACGAGCCCAGCACTGCTACGGTGAAGAACGATCTCCGTGATCGTTATCAAGTTATGCACAAGTTCTACGCCAAAGTCACTGGTGGTCAATATGCCAGCAATGAACAGGCTCTGGTCAAGAGGTTCTGGAAGGTCAACAATCATGTGGTGTACAACCACCAGGAAGCTGGCAAGTATGAGAATCACACGGAGAATGCTTTGTTACTGTATATGGCATGTACTCATGCCTCTAACCCTGTGTATGCAACGCTAAAGATTCGAATTTATTTTTACGATTCGATCACCAATTAATAAAATTTGAATTTTATTGAATGATTTTCTAGTACATGATTTACATATGATTTGTCTGTTGCGAATCGAACAGCTCTAATTACATTATTAAGTGCAATTACACCTAATTGTTCTAAGTACATCATTACTAAGTGCCTAAACCTACTTAAATAAGTCATCCCAGAAGCTCTCATCGATGTCGTCCAGACTTGGAAGTTCAGGAATGCCTTGTGGAGACCCAACGCTTTCCTGAGGTTGTGGTTGAACCGTATCTGGATGTGATACACTCTGGTCCTTGTGAACGGGATGTCTTCTACTCGGTGCATCTTGAAATACAGGGGATTTGTTATCTCCCAGATATAGACGCCATTCTCTGCCTGATGTGCAGTGATGAGTTCCCCGGTGCGTGAATCCATGACCTATGCAGTTTATATGGACGTATATGGAGCAGCCGCACTCGATATCAATCCGTCGCCGCCGGATTGCTCTCTTCTTCGCAATCCTGTGTTGCTGTTTGATAGAGGGGGGAGTCGAGGAAGATGAATTTAGCATTGTATAGTGTCCACGACTTCAGGGATGCATTTTCCTCTTTCTCCAGGAAATCTTTATAGCTGGCCCCCTCGCCAGGATTGCAAAGCACGATTGAAGGAATTCCACCTTTAATTTGAACTGGCTTGCCGTACTTACAATTTGACTGCCAGTCTTTTTGAGCACCAATCAATTCCTTCCAGTGCTTTAACTTTAAATAATGCGGGGTGACATCATCGATGACGTTATACTCAACGTCATTTGAGTAAACCCTAGAATTGAAGTCCAGGTGTCCACTCAGATAATTGTGAGACCCCAAAGCTCTGGCCCACATCGTCTTCCCCGTTCGACTATCACCTTGGACGATTATACTCATGGGTCTCACTGGCCGCGCAGCGGCTCCTCTTCCAAAATACTCATCGGCCCATTCCTGCATCTCGTCAGGAACGTTAGTGAAGGATGAGAGGGGAAACGGAGGAACCCAAGGATCCGGAGCCTTTTTGAATATTCTATCCAGGTTACTGGATAGGTTATGGTATTGGAAGAGGAATTTTTCCGGCAGCTTTTCCTTGATAATCATCATCGCCTCTTCCTTTGATGATGCATTCAACGCCTCAGCTGCAGCGTCGTTAGACGTTTGCTGACCTCCTCTAGCACTTCTGCCGTCGACTTGGAATTCTCCCCATTCGATAGTATCACCGTCCTTATCGATGTAGGACTTGACGTCGGACGATGATTTAGCTCCCTGAATGTTCGGATGGAAATGTGCTGACCTGGATGGGGATACCAAGTCGAAGAATCTGTTATTTGTGCACTGGTATTTCCCTTCGAACTGTATAAGCACGTGTAGATGAGGTTCCCCATTCTCATGCAGTTCTCTGCAGATTTTGATATACTTCTTGTTGGTTGGGGTGTTAAGGAGTTTAAGTTGGGCAAGTGCTTCTTCTTTGGTCAGAGAACAATGAGGGTATGTGACAAAATAGTTTTTGGAAGATATTTTAAACCGCTTTGGGGGTGGCATATTTGTAAATATAGCCTTGTACCCCAATTGCTCCGGCTCTCAAAACTCTATATGAATTGGGGTAATGGGGTACAATATATAGTAAGGAGTTCCATAAGCTCCTAGGGGCACGTGGCGGCCATCCGTATAATATT
Gene Information
|
NCBI Accession
|
YP_009506553.1
|
|
Location
|
228-983 |
|
Gene Name
|
CP |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGCCTAAGCGGGATGCCCCGTGGCGCCTGATGGCGGGAACTTCGAAGGTTAGCCGCTCTTCCAATTTCTCCCCCCGTGGAGGTGGAGGCCCAAAGTTCAACAAGGCCTCGGAATGGGTTAACAGGCCCATGTACAGGAAGCCCAGGATATATCGGACGCTGAGAACGCCTGATGTCCCTAGAGGCTGTGAAGGGCCCTGTAAGGTCCAGTCCTACGAGCAGCGTCACGACATCTCACATGTCGGTAAGGTGATGTGCATTTCTGATGTGACACGTGGTAATGGTATTACCCACCGTGTCGGTAAGCGTTTCTGCGTTAAGTCTGTGTACATTTTAGGTAAGATATGGATGGACGAGAACATCAAGCTGAAGAACCACACGAATAGTGTCATGTTCTGGTTGGTCAGAGATCGTAGACCGTATGGTACTCCTATGGACTTTGGCCAGGTGTTCAATATGTTTGACAACGAGCCCAGCACTGCTACGGTGAAGAACGATCTCCGTGATCGTTATCAAGTTATGCACAAGTTCTACGCCAAAGTCACTGGTGGTCAATATGCCAGCAATGAACAGGCTCTGGTCAAGAGGTTCTGGAAGGTCAACAATCATGTGGTGTACAACCACCAGGAAGCTGGCAAGTATGAGAATCACACGGAGAATGCTTTGTTACTGTATATGGCATGTACTCATGCCTCTAACCCTGTGTATGCAACGCTAAAGATTCGAATTTATTTTTACGATTCGATCACCAATTAA |
|
Protein Sequence
|
MPKRDAPWRLMAGTSKVSRSSNFSPRGGGGPKFNKASEWVNRPMYRKPRIYRTLRTPDVPRGCEGPCKVQSYEQRHDISHVGKVMCISDVTRGNGITHRVGKRFCVKSVYILGKIWMDENIKLKNHTNSVMFWLVRDRRPYGTPMDFGQVFNMFDNEPSTATVKNDLRDRYQVMHKFYAKVTGGQYASNEQALVKRFWKVNNHVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSITN |
|
NCBI Accession
|
YP_009506554.1
|
|
Location
|
980-1378 |
|
Gene Name
|
Ren |
|
Protein Name
|
replication enhancer protein |
|
Coding Region
|
ATGGATTCACGCACCGGGGAACTCATCACTGCACATCAGGCAGAGAATGGCGTCTATATCTGGGAGATAACAAATCCCCTGTATTTCAAGATGCACCGAGTAGAAGACATCCCGTTCACAAGGACCAGAGTGTATCACATCCAGATACGGTTCAACCACAACCTCAGGAAAGCGTTGGGTCTCCACAAGGCATTCCTGAACTTCCAAGTCTGGACGACATCGATGAGAGCTTCTGGGATGACTTATTTAAGTAGGTTTAGGCACTTAGTAATGATGTACTTAGAACAATTAGGTGTAATTGCACTTAATAATGTAATTAGAGCTGTTCGATTCGCAACAGACAAATCATATGTAAATCATGTACTAGAAAATCATTCAATAAAATTCAAATTTTATTAA |
|
Protein Sequence
|
MDSRTGELITAHQAENGVYIWEITNPLYFKMHRVEDIPFTRTRVYHIQIRFNHNLRKALGLHKAFLNFQVWTTSMRASGMTYLSRFRHLVMMYLEQLGVIALNNVIRAVRFATDKSYVNHVLENHSIKFKFY |
|
NCBI Accession
|
YP_009506555.1
|
|
Location
|
1125-1514 |
|
Gene Name
|
Trap |
|
Protein Name
|
trans-activating protein |
|
Coding Region
|
ATGCTAAATTCATCTTCCTCGACTCCCCCCTCTATCAAACAGCAACACAGGATTGCGAAGAAGAGAGCAATCCGGCGGCGACGGATTGATATCGAGTGCGGCTGCTCCATATACGTCCATATAAACTGCATAGGTCATGGATTCACGCACCGGGGAACTCATCACTGCACATCAGGCAGAGAATGGCGTCTATATCTGGGAGATAACAAATCCCCTGTATTTCAAGATGCACCGAGTAGAAGACATCCCGTTCACAAGGACCAGAGTGTATCACATCCAGATACGGTTCAACCACAACCTCAGGAAAGCGTTGGGTCTCCACAAGGCATTCCTGAACTTCCAAGTCTGGACGACATCGATGAGAGCTTCTGGGATGACTTATTTAAGTAG |
|
Protein Sequence
|
MLNSSSSTPPSIKQQHRIAKKRAIRRRRIDIECGCSIYVHINCIGHGFTHRGTHHCTSGREWRLYLGDNKSPVFQDAPSRRHPVHKDQSVSHPDTVQPQPQESVGSPQGIPELPSLDDIDESFWDDLFK |
|
NCBI Accession
|
YP_009506556.1
|
|
Location
|
1426-2511 |
|
Gene Name
|
Rep |
|
Protein Name
|
replication-associated protein |
|
Coding Region
|
ATGCCACCCCCAAAGCGGTTTAAAATATCTTCCAAAAACTATTTTGTCACATACCCTCATTGTTCTCTGACCAAAGAAGAAGCACTTGCCCAACTTAAACTCCTTAACACCCCAACCAACAAGAAGTATATCAAAATCTGCAGAGAACTGCATGAGAATGGGGAACCTCATCTACACGTGCTTATACAGTTCGAAGGGAAATACCAGTGCACAAATAACAGATTCTTCGACTTGGTATCCCCATCCAGGTCAGCACATTTCCATCCGAACATTCAGGGAGCTAAATCATCGTCCGACGTCAAGTCCTACATCGATAAGGACGGTGATACTATCGAATGGGGAGAATTCCAAGTCGACGGCAGAAGTGCTAGAGGAGGTCAGCAAACGTCTAACGACGCTGCAGCTGAGGCGTTGAATGCATCATCAAAGGAAGAGGCGATGATGATTATCAAGGAAAAGCTGCCGGAAAAATTCCTCTTCCAATACCATAACCTATCCAGTAACCTGGATAGAATATTCAAAAAGGCTCCGGATCCTTGGGTTCCTCCGTTTCCCCTCTCATCCTTCACTAACGTTCCTGACGAGATGCAGGAATGGGCCGATGAGTATTTTGGAAGAGGAGCCGCTGCGCGGCCAGTGAGACCCATGAGTATAATCGTCCAAGGTGATAGTCGAACGGGGAAGACGATGTGGGCCAGAGCTTTGGGGTCTCACAATTATCTGAGTGGACACCTGGACTTCAATTCTAGGGTTTACTCAAATGACGTTGAGTATAACGTCATCGATGATGTCACCCCGCATTATTTAAAGTTAAAGCACTGGAAGGAATTGATTGGTGCTCAAAAAGACTGGCAGTCAAATTGTAAGTACGGCAAGCCAGTTCAAATTAAAGGTGGAATTCCTTCAATCGTGCTTTGCAATCCTGGCGAGGGGGCCAGCTATAAAGATTTCCTGGAGAAAGAGGAAAATGCATCCCTGAAGTCGTGGACACTATACAATGCTAAATTCATCTTCCTCGACTCCCCCCTCTATCAAACAGCAACACAGGATTGCGAAGAAGAGAGCAATCCGGCGGCGACGGATTGA |
|
Protein Sequence
|
MPPPKRFKISSKNYFVTYPHCSLTKEEALAQLKLLNTPTNKKYIKICRELHENGEPHLHVLIQFEGKYQCTNNRFFDLVSPSRSAHFHPNIQGAKSSSDVKSYIDKDGDTIEWGEFQVDGRSARGGQQTSNDAAAEALNASSKEEAMMIIKEKLPEKFLFQYHNLSSNLDRIFKKAPDPWVPPFPLSSFTNVPDEMQEWADEYFGRGAAARPVRPMSIIVQGDSRTGKTMWARALGSHNYLSGHLDFNSRVYSNDVEYNVIDDVTPHYLKLKHWKELIGAQKDWQSNCKYGKPVQIKGGIPSIVLCNPGEGASYKDFLEKEENASLKSWTLYNAKFIFLDSPLYQTATQDCEEESNPAATD |
|
NCBI Accession
|
YP_009506557.1
|
|
Location
|
2097-2360 |
|
Gene Name
|
AC4 |
|
Protein Name
|
AC4 |
|
Coding Region
|
ATGAGAATGGGGAACCTCATCTACACGTGCTTATACAGTTCGAAGGGAAATACCAGTGCACAAATAACAGATTCTTCGACTTGGTATCCCCATCCAGGTCAGCACATTTCCATCCGAACATTCAGGGAGCTAAATCATCGTCCGACGTCAAGTCCTACATCGATAAGGACGGTGATACTATCGAATGGGGAGAATTCCAAGTCGACGGCAGAAGTGCTAGAGGAGGTCAGCAAACGTCTAACGACGCTGCAGCTGAGGCGTTGA |
|
Protein Sequence
|
MRMGNLIYTCLYSSKGNTSAQITDSSTWYPHPGQHISIRTFRELNHRPTSSPTSIRTVILSNGENSKSTAEVLEEVSKRLTTLQLRR |