Boerhavia yellow spot virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_002821785.1 |
| Isolate |
Mexico |
| Release date |
2018/8/25 |
| Submitter |
Hernandez-Zepeda,C., Idris,A.M., Carnevali,G., Brown,J.K., Moreno-Valenzuela,O.A. |
| Host |
|
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
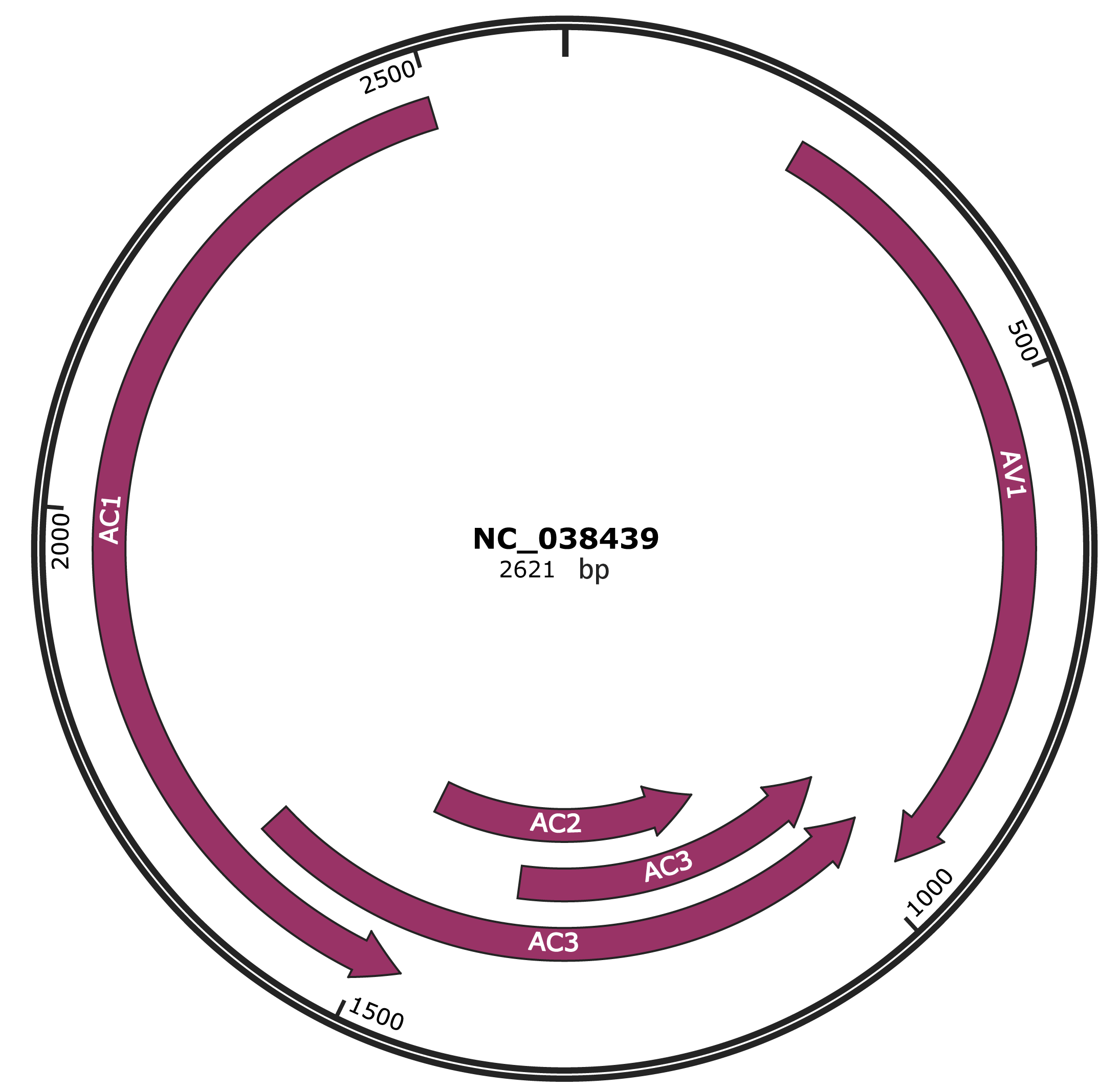
JBrowse
Genome
ACCGGATGGCCGCGATTTTTTTTGGACGGTCACGATTTGATTAGGCCCCACCACAAATGACAAAGCACTGCGTTTTGAGTGCCCCCCTTTAATTTGAACAGCTAGTGGACACGTGGTCCACCCATATTTCGTTTGTGGGGCCTATGTAATGACTTAACTGTTAAGTTGACAGGCAATAAATAGATGGTCCCCCCCATTATCTATTTTTGCTTTAATTTGAAATGCCTAAGCGGGACGCCCCTTGGCGCCTAATGGCTGGGCCCTCCAAGGTTAGCCGTAATGTCAATTATTCGCCTAGGGCTGGTCCCAAAGCTGATAAGCCGTCGATTTGGGCGAACAGGCCCATGTACAGGAAGCCAAGGTTTTACCGGCTATTCAGAACTCCAGACGTCCCCAAAGGATGTGAAGGGCCGTGTAAGGTCCAGTCGTTTGAGCAGCGCCATGATATATCCCATGTGGGTAAGGTCATGTGCATTTCCGACGTGACAAGGGGCAACGGCATTACGCACCGCGTTGGTAAGCGGTTCTGCGTCAAGTCTGTGTACATATTAGGCAAGGTGTGGATGGACGATAATATTAAACTGAAGAACCACACCAACATCGTCATGTTCTGGCTGGTCAGGGACCGGAGACCCTACGGCACTCCCATGGATTTTGGCCAGGTGTTCAACATGTTCGACAACGAGCCTAGTACTGCCACTGTGAAGAACGATCTGCGTGATCGGTTCCAAGTCATGCACAAGTTCCACGCGAAGGTTACCGGCGGTCAGTATGCCAGTAACGAGCAGTCCCTGGTGAAGAGATTCTGGAGGGTCAACAACCACGTGGTGTACAACCATCAGGAGGCTGCCAAGTACGAGAATCACACTGAGAACGCCCTGTTATTGTATATGGCATGTAGTCATGCCTCAAATCCTGTGTATGCGACATTGAAAATTCGGATCTATTTTTATGATTCGATAACAAATTAATAAAAATTGAATTTTATTTCATGATTCTCGAGTACATGTTGTACATATGGTTTGTCTGTTGCAAACCGAACAGCTCTTATTACATTGTTTATACAGATGAGCCCTAGATTGTCTAGGTACAACATGACTAAGTGCCTAAATCTATTTAAATAAGTCGTCCCAGAAGCTCGAACTGATGTCGTCCAGACTTGGAAATTCAGGAAGGCCTTGTGTAGATGCAGTGCCCTCCTCAGGTTGTGGTTGAACCGGATCTGGACGTGGTATATCCTCGTGTCTATGTACGGGAGGTCCTCTATTTTCTGCATCCTGAAATAGAGGGGATTTGGAACCTCCCAGATAAAAGCGGAATTCTCTGCCTGACGAGCAGTGATGCTCTCCCCTGTGCGTGAATCCATAGTTTGCACAGCTGAGAGAGAGGAAAATAGTGCAGCCGCAGTTCAGGTCGATGCGTCGTCTCCGGATGGCTCTTCTCTTAGCAATCCTGTGTTGTGGTTTAATAGAGGGGGGAGTGGATGAAGATGAATTTTGCATTTTGCTCTGTCCACTCCCTGAGAGCTGCATTCTCCAATTTATTGAGGAAGTCTTTATAGCTGGACCCCTCGCCAGGATTGCAAAGCACGATTGATGGGATGCCACCTTTAATTTGAACTGGCTTGCCGTACTTGCAATTTGATTGCCAGTCCCTTTGGGCCCCAATCAATTCTTTCCAGTGCTTTAGCTTTAGATAATGCGGGCTGACATCATCGATGACGTTGTACATCACATCGTTTGAGTAAACCCTTGGATTGAAATCCAGGTGGCCACTCAGATAGTTGTGCCGCCCCAAAGCACGGGCCCACATTGTTTTGCCCACCCTCGAACCACCTTCAACGATTAAGCTTATAGGCCTGTGCGGCCGCGCAGCGGAATGGCCACCGAAATACTCATCAGCCCAGCATTGCATCTCCTCCGGCACATTTGTGAAAGAGGAAAGTTCAAATGGAGGAACCCATGGTTGAGGAGCCTTTGCGAAGATCCTCTCTAGGTTAGACTTCAGATTGTGATAATCTTTCACAAAGTCCCTTGGTTGTTCCTCCTTTAGAACTTGAAGTGCTTCTTGCACTCCAGATGCGTTCAGCGCCTTGGCGTATGAGTCGTTAGACGTCTGCTGACCTCCTCTAGCAGATCTCCCGTCGACCTGGAATTCCCCCCATTCAAGGGTATCTCCGTCCTTGTCAATGTAGGACTTGACATCGGAGCTTGATTTAGCTCCCTGAATGTTCGGATGGAAATGTGCTGATCGGGTTGGGGAAACCAGGTCGAACTGTCGTTGATTCGTGATCTGGACTTTCCCTTCCAACTGCAAGAGCACATGGAGGTGAGGTTCCCCATTTTCGTGTAGCTCCCTGCAGATTTTAATGTATTTCTTGTTGGAAGGGAGCTGGAGAGACCTTATTTGCTGAAGAGCCGCTTCCTTTGTAAGCGAGCATTTGGGATATGTGAGGAAGATGTTTTTAGCTTGGAGTCTAAAACGTTTAGCCAGTGGCATTTTGTGTAAATAAGGGGTGTACTCCAATTGAGGTTCCCTTCAAAATGCTGAAACAATTGGAGTATTGGAGTACAATATATAGTAAGAGAAGTCAGTACATAGCGGCCATCCGATCTAATATT
Gene Information
|
NCBI Accession
|
YP_009506374.1
|
|
Location
|
222-971 |
|
Gene Name
|
AV1 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGCCTAAGCGGGACGCCCCTTGGCGCCTAATGGCTGGGCCCTCCAAGGTTAGCCGTAATGTCAATTATTCGCCTAGGGCTGGTCCCAAAGCTGATAAGCCGTCGATTTGGGCGAACAGGCCCATGTACAGGAAGCCAAGGTTTTACCGGCTATTCAGAACTCCAGACGTCCCCAAAGGATGTGAAGGGCCGTGTAAGGTCCAGTCGTTTGAGCAGCGCCATGATATATCCCATGTGGGTAAGGTCATGTGCATTTCCGACGTGACAAGGGGCAACGGCATTACGCACCGCGTTGGTAAGCGGTTCTGCGTCAAGTCTGTGTACATATTAGGCAAGGTGTGGATGGACGATAATATTAAACTGAAGAACCACACCAACATCGTCATGTTCTGGCTGGTCAGGGACCGGAGACCCTACGGCACTCCCATGGATTTTGGCCAGGTGTTCAACATGTTCGACAACGAGCCTAGTACTGCCACTGTGAAGAACGATCTGCGTGATCGGTTCCAAGTCATGCACAAGTTCCACGCGAAGGTTACCGGCGGTCAGTATGCCAGTAACGAGCAGTCCCTGGTGAAGAGATTCTGGAGGGTCAACAACCACGTGGTGTACAACCATCAGGAGGCTGCCAAGTACGAGAATCACACTGAGAACGCCCTGTTATTGTATATGGCATGTAGTCATGCCTCAAATCCTGTGTATGCGACATTGAAAATTCGGATCTATTTTTATGATTCGATAACAAATTAA |
|
Protein Sequence
|
MPKRDAPWRLMAGPSKVSRNVNYSPRAGPKADKPSIWANRPMYRKPRFYRLFRTPDVPKGCEGPCKVQSFEQRHDISHVGKVMCISDVTRGNGITHRVGKRFCVKSVYILGKVWMDDNIKLKNHTNIVMFWLVRDRRPYGTPMDFGQVFNMFDNEPSTATVKNDLRDRFQVMHKFHAKVTGGQYASNEQSLVKRFWRVNNHVVYNHQEAAKYENHTENALLLYMACSHASNPVYATLKIRIYFYDSITN |
|
NCBI Accession
|
YP_009506375.1
|
|
Location
|
968-1366 |
|
Gene Name
|
AC3 |
|
Protein Name
|
AC3 |
|
Coding Region
|
ATGGATTCACGCACAGGGGAGAGCATCACTGCTCGTCAGGCAGAGAATTCCGCTTTTATCTGGGAGGTTCCAAATCCCCTCTATTTCAGGATGCAGAAAATAGAGGACCTCCCGTACATAGACACGAGGATATACCACGTCCAGATCCGGTTCAACCACAACCTGAGGAGGGCACTGCATCTACACAAGGCCTTCCTGAATTTCCAAGTCTGGACGACATCAGTTCGAGCTTCTGGGACGACTTATTTAAATAGATTTAGGCACTTAGTCATGTTGTACCTAGACAATCTAGGGCTCATCTGTATAAACAATGTAATAAGAGCTGTTCGGTTTGCAACAGACAAACCATATGTACAACATGTACTCGAGAATCATGAAATAAAATTCAATTTTTATTAA |
|
Protein Sequence
|
MDSRTGESITARQAENSAFIWEVPNPLYFRMQKIEDLPYIDTRIYHVQIRFNHNLRRALHLHKAFLNFQVWTTSVRASGTTYLNRFRHLVMLYLDNLGLICINNVIRAVRFATDKPYVQHVLENHEIKFNFY |
|
NCBI Accession
|
YP_009506376.1
|
|
Location
|
1113-1502 |
|
Gene Name
|
AC2 |
|
Protein Name
|
AC2 |
|
Coding Region
|
ATGCAAAATTCATCTTCATCCACTCCCCCCTCTATTAAACCACAACACAGGATTGCTAAGAGAAGAGCCATCCGGAGACGACGCATCGACCTGAACTGCGGCTGCACTATTTTCCTCTCTCTCAGCTGTGCAAACTATGGATTCACGCACAGGGGAGAGCATCACTGCTCGTCAGGCAGAGAATTCCGCTTTTATCTGGGAGGTTCCAAATCCCCTCTATTTCAGGATGCAGAAAATAGAGGACCTCCCGTACATAGACACGAGGATATACCACGTCCAGATCCGGTTCAACCACAACCTGAGGAGGGCACTGCATCTACACAAGGCCTTCCTGAATTTCCAAGTCTGGACGACATCAGTTCGAGCTTCTGGGACGACTTATTTAAATAG |
|
Protein Sequence
|
MQNSSSSTPPSIKPQHRIAKRRAIRRRRIDLNCGCTIFLSLSCANYGFTHRGEHHCSSGREFRFYLGGSKSPLFQDAENRGPPVHRHEDIPRPDPVQPQPEEGTASTQGLPEFPSLDDISSSFWDDLFK |
|
NCBI Accession
|
YP_009506377.1
|
|
Location
|
1465-2499 |
|
Gene Name
|
AC1 |
|
Protein Name
|
replication protein |
|
Coding Region
|
ATGCCACTGGCTAAACGTTTTAGACTCCAAGCTAAAAACATCTTCCTCACATATCCCAAATGCTCGCTTACAAAGGAAGCGGCTCTTCAGCAAATAAGGTCTCTCCAGCTCCCTTCCAACAAGAAATACATTAAAATCTGCAGGGAGCTACACGAAAATGGGGAACCTCACCTCCATGTGCTCTTGCAGTTGGAAGGGAAAGTCCAGATCACGAATCAACGACAGTTCGACCTGGTTTCCCCAACCCGATCAGCACATTTCCATCCGAACATTCAGGGAGCTAAATCAAGCTCCGATGTCAAGTCCTACATTGACAAGGACGGAGATACCCTTGAATGGGGGGAATTCCAGGTCGACGGGAGATCTGCTAGAGGAGGTCAGCAGACGTCTAACGACTCATACGCCAAGGCGCTGAACGCATCTGGAGTGCAAGAAGCACTTCAAGTTCTAAAGGAGGAACAACCAAGGGACTTTGTGAAAGATTATCACAATCTGAAGTCTAACCTAGAGAGGATCTTCGCAAAGGCTCCTCAACCATGGGTTCCTCCATTTGAACTTTCCTCTTTCACAAATGTGCCGGAGGAGATGCAATGCTGGGCTGATGAGTATTTCGGTGGCCATTCCGCTGCGCGGCCGCACAGGCCTATAAGCTTAATCGTTGAAGGTGGTTCGAGGGTGGGCAAAACAATGTGGGCCCGTGCTTTGGGGCGGCACAACTATCTGAGTGGCCACCTGGATTTCAATCCAAGGGTTTACTCAAACGATGTGATGTACAACGTCATCGATGATGTCAGCCCGCATTATCTAAAGCTAAAGCACTGGAAAGAATTGATTGGGGCCCAAAGGGACTGGCAATCAAATTGCAAGTACGGCAAGCCAGTTCAAATTAAAGGTGGCATCCCATCAATCGTGCTTTGCAATCCTGGCGAGGGGTCCAGCTATAAAGACTTCCTCAATAAATTGGAGAATGCAGCTCTCAGGGAGTGGACAGAGCAAAATGCAAAATTCATCTTCATCCACTCCCCCCTCTATTAA |
|
Protein Sequence
|
MPLAKRFRLQAKNIFLTYPKCSLTKEAALQQIRSLQLPSNKKYIKICRELHENGEPHLHVLLQLEGKVQITNQRQFDLVSPTRSAHFHPNIQGAKSSSDVKSYIDKDGDTLEWGEFQVDGRSARGGQQTSNDSYAKALNASGVQEALQVLKEEQPRDFVKDYHNLKSNLERIFAKAPQPWVPPFELSSFTNVPEEMQCWADEYFGGHSAARPHRPISLIVEGGSRVGKTMWARALGRHNYLSGHLDFNPRVYSNDVMYNVIDDVSPHYLKLKHWKELIGAQRDWQSNCKYGKPVQIKGGIPSIVLCNPGEGSSYKDFLNKLENAALREWTEQNAKFIFIHSPLY |