Tomato leaf curl Toliara virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_002987065.1 |
| Isolate |
Madagascar:Menabe, Miandrivazo |
| Release date |
2018/8/26 |
| Submitter |
Lefeuvre,P., Martin,D.P., Hoareau,M., Naze,F., Becker,N., Delatte,H., Reynaud,B., Lett,J.M. |
| Host |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
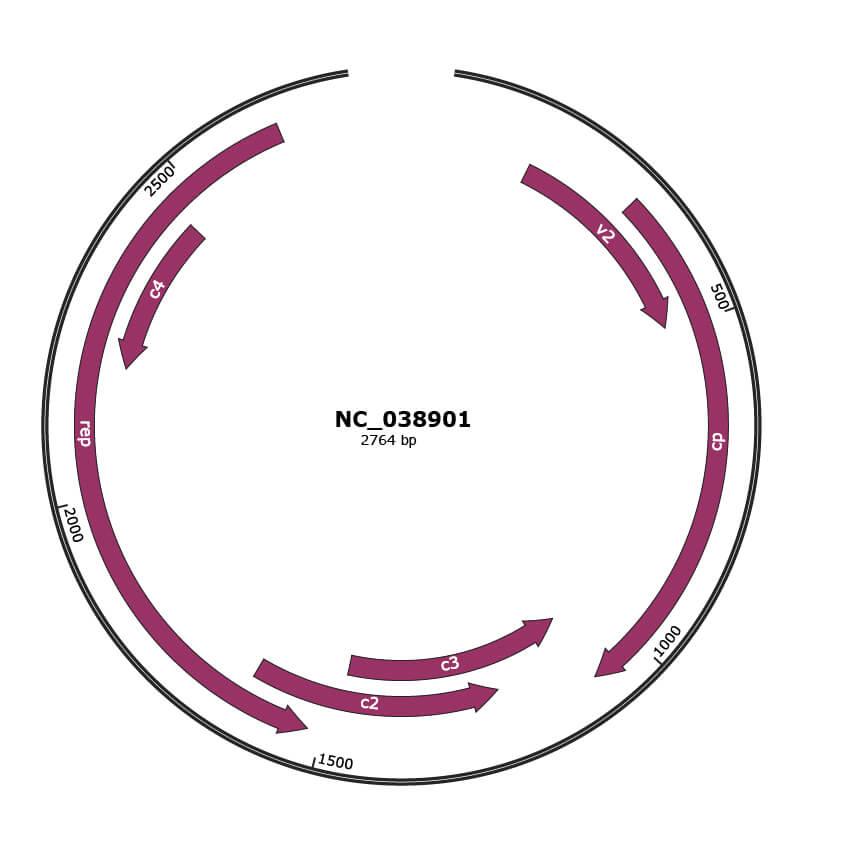
JBrowse
Genome
ACCGGATGGCCGCGCCCCCGAAAAAGCGTGGGCCCCCTTGAACTGCACGGAGCCAATCACACTTCGCGTATGATGCTTATTTAAACTCCTTGTCGACCAAGGAGTCTTTATATTTGTCTTTTTTTGCATTTAAACCGCAATCATGTGGGATCCACTTCTTAACGATTTTCCAGAAACTGTTCACGGTTTCCGTTGTATGTTAGCTATTAAATATTTGCAGGCTGTAGAGAAACAGTACGAGCCAGGTACGTTAGGGTTCGAGTTAATTCGTGATTTAATTGTCGTTCTCAGGACGAAGAATTATGTCGAAGCGACCTGCCGATATAGTAATTTCCACTCCCGCGTCCAAGGTGCGTCGCCGGTTGAACTTCGACAGCCCATACTTGAGCCGTGCTGCTGCCCCCACTGTCCTCGTCACAAACAAACGGCGAGCATGGGTCAACAGGCCCATGTACCGAAAGCCCAGGATGTACCGGATGTACAAAAATCCTGATGTCCCTAGGGGCTGTGAAGGCCCGTGTAAGATCCAGTCTTACGAACAACGTGATGACGTGAAGCATGTTGGTGTGGTTAGGTGTATTAGTGATATTACTAAGGGTCCTGGTTTGACCCATAGGACCGGTAAACGTTTTGTTGTTAAGTCTGTTTATATATTAGGTAAAGTTTGGATGGATGAAAACATTAAGAAGCAGAATCACACGAACAATGTGATGTTTTTCCTGGTTAGAGATAGGAGGCCTTATGGCCCGAGTCCAATGGACTTTGGGCAGGTGTTTAATATGTTTGACAATGAGCCCAGCACAGCAACGGTGAAGAACGATTTTAGGGATCGTTTCCAAGTTTTAAGGAAATTCACTGCTACTGTTGTTGGTGGACCTTCTGGTTTGAAGGAACAGGCCTTGGTAAAGCGATTCTTCAGGCTCAACAGCCATGTGACGTATAATCATCAAGAAGCTGCTAAGTATGAGAACCATACGGAGAATGCTTTGTTGTTGTATATGGCATGTACTCATGCTTCTAATCCAGTGTATGCTACTCTTAAAATACGTGTGTATTTCTACGATTCTGTAACAAATTAATAAAGTTTATATTTTATATCATAATTTTGTTCCACCCATAAGGTTTCGTTGATTACATCAAACAATACATAATCTATTGCTCTAATTACATTATTAATTGAAATTACACCAAGATTGTTTAAATATTTACTAACTTGAGTCTTAAAGACTCTTAAGAAATGACCAGTCTGAGGCTGTAAGGTCGTCCAGATCTTGAAGGTCATGAAACATTTGTGAATCCCCAGTTCCTTCCTTAGGTTGTGGTTGAATCGGAGTTGTACTGTGATTATGTCGTGGTTGTAGTTGAATGGTCTCTTCGAGTGTTCCGTGATGCTGAAATATAGGGGATTGGCGATTTCCCAGGTATAGACGCCACTCTGTGCCTGATGCGCAGTGATGAGTTCCCCGGTGCGTGAATCCATTGTTGCGACAGTTGAGTGACAAGTAGTACGAGCACCCGCAATTAAGGTCTATCCTCTTCCTCCTCTGAAGCCTCTGCTTGGCTGCTCTGTGTTGGACCTTGATAGGAACTTGAGTACAATGGCTGTTGGATGGTGACGAAGATCGCATTCTTAATTGCCCAGGCCTTTAGTGGTGCGTTCTTTTGCTCGTCCAAGTACTCTTTATATGATGAAGTGGGTCCTGGATTGCAGAGGAAGATTGTCGGGATACCTCCTTTAATTTGAATTGGTTTCCCGTACTTTGTGTTGCTTTGCCAGTCCCGTTGTGCGCCCATGAATTCCTTAAAGTGCTTTAGATAATGAGGATCGACGTCATCTATTACGTTGTACCATGCTTCATTTGAATACACCTTTGGACTAAGATCAAGATGACCACACAAATAATTGTGTGGACCCAATGACCTAGCCCACATTGTCTTCCCGGTACGACTATCCCCTTCAATCACAATACTTATGGGTCTCAATGGCCGCGCAGCGGCACTGACAACATTCTCCGCCGCCCACTCTTCAAGTTCTTCCGGAACTTGATCGAAAGAAGAACATAAAAAAGGAGAAACATAATCCTCCAACGGAGGTGTAAAAATCCTATCTAAATTACATTTTAAATTATGATACTGAAAAATAAAATCTTTAGGGAGTTTCTCTTTAATAATAGCCATAGCGGCTTCAGCGGAACCTGCGTTTAATGCCTCGGCGCATGCGTCGTTAGCATTCTGGCAGCCTCCTCTAGCACTTCTGCCGTCGATCTGGAATTCACCCCATTCAAGTGTGTCTCCATCCTTGTCGATGTAGGACTTGACGTCGGAGCTTGATTTAGCTCCCTGAATGTTTGGATGGAAATGTGCTGACCTGGTTGGGGATACCAGGTCGAAGAATCGGTTATTCGTGCAGTGGAATTTGCCCTCGAACTGGATGAGCATGTGGAGATGAGGCTCCCCATCTTCGTGCAACTCTCTGCAGATTTTGATGAATCTTTTATTTGTTGGAGTATCTATATTTAATAATTGGGAAAGTGCTTCTTCTTTAGTTAAATTGCATTTGGGATAAGTAAGGAAATAATTTTTGGCTTGTATTTTAAAACGACGTGGCCGAGCCATTTGGTCAAGTGTCTCCAATTGACTTCTCATTTGCATCTCTCTGATATATTGGGGACAATATATAGTGTCTCCAAATGGCAATATGGTAATAACAAGAAGTTACTTTAACTTTATTTCAAATTGGTAAAGCGGCCATCCGTCTAATATT
Gene Information
|
NCBI Accession
|
YP_009508206.1
|
|
Location
|
143-493 |
|
Gene Name
|
v2 |
|
Protein Name
|
V2 protein |
|
Coding Region
|
ATGTGGGATCCACTTCTTAACGATTTTCCAGAAACTGTTCACGGTTTCCGTTGTATGTTAGCTATTAAATATTTGCAGGCTGTAGAGAAACAGTACGAGCCAGGTACGTTAGGGTTCGAGTTAATTCGTGATTTAATTGTCGTTCTCAGGACGAAGAATTATGTCGAAGCGACCTGCCGATATAGTAATTTCCACTCCCGCGTCCAAGGTGCGTCGCCGGTTGAACTTCGACAGCCCATACTTGAGCCGTGCTGCTGCCCCCACTGTCCTCGTCACAAACAAACGGCGAGCATGGGTCAACAGGCCCATGTACCGAAAGCCCAGGATGTACCGGATGTACAAAAATCCTGA |
|
Protein Sequence
|
MWDPLLNDFPETVHGFRCMLAIKYLQAVEKQYEPGTLGFELIRDLIVVLRTKNYVEATCRYSNFHSRVQGASPVELRQPILEPCCCPHCPRHKQTASMGQQAHVPKAQDVPDVQKS |
|
NCBI Accession
|
YP_009508207.1
|
|
Location
|
303-1079 |
|
Gene Name
|
cp |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGTCGAAGCGACCTGCCGATATAGTAATTTCCACTCCCGCGTCCAAGGTGCGTCGCCGGTTGAACTTCGACAGCCCATACTTGAGCCGTGCTGCTGCCCCCACTGTCCTCGTCACAAACAAACGGCGAGCATGGGTCAACAGGCCCATGTACCGAAAGCCCAGGATGTACCGGATGTACAAAAATCCTGATGTCCCTAGGGGCTGTGAAGGCCCGTGTAAGATCCAGTCTTACGAACAACGTGATGACGTGAAGCATGTTGGTGTGGTTAGGTGTATTAGTGATATTACTAAGGGTCCTGGTTTGACCCATAGGACCGGTAAACGTTTTGTTGTTAAGTCTGTTTATATATTAGGTAAAGTTTGGATGGATGAAAACATTAAGAAGCAGAATCACACGAACAATGTGATGTTTTTCCTGGTTAGAGATAGGAGGCCTTATGGCCCGAGTCCAATGGACTTTGGGCAGGTGTTTAATATGTTTGACAATGAGCCCAGCACAGCAACGGTGAAGAACGATTTTAGGGATCGTTTCCAAGTTTTAAGGAAATTCACTGCTACTGTTGTTGGTGGACCTTCTGGTTTGAAGGAACAGGCCTTGGTAAAGCGATTCTTCAGGCTCAACAGCCATGTGACGTATAATCATCAAGAAGCTGCTAAGTATGAGAACCATACGGAGAATGCTTTGTTGTTGTATATGGCATGTACTCATGCTTCTAATCCAGTGTATGCTACTCTTAAAATACGTGTGTATTTCTACGATTCTGTAACAAATTAA |
|
Protein Sequence
|
MSKRPADIVISTPASKVRRRLNFDSPYLSRAAAPTVLVTNKRRAWVNRPMYRKPRMYRMYKNPDVPRGCEGPCKIQSYEQRDDVKHVGVVRCISDITKGPGLTHRTGKRFVVKSVYILGKVWMDENIKKQNHTNNVMFFLVRDRRPYGPSPMDFGQVFNMFDNEPSTATVKNDFRDRFQVLRKFTATVVGGPSGLKEQALVKRFFRLNSHVTYNHQEAAKYENHTENALLLYMACTHASNPVYATLKIRVYFYDSVTN |
|
NCBI Accession
|
YP_009508208.1
|
|
Location
|
1076-1480 |
|
Gene Name
|
c3 |
|
Protein Name
|
C3 protein |
|
Coding Region
|
ATGGATTCACGCACCGGGGAACTCATCACTGCGCATCAGGCACAGAGTGGCGTCTATACCTGGGAAATCGCCAATCCCCTATATTTCAGCATCACGGAACACTCGAAGAGACCATTCAACTACAACCACGACATAATCACAGTACAACTCCGATTCAACCACAACCTAAGGAAGGAACTGGGGATTCACAAATGTTTCATGACCTTCAAGATCTGGACGACCTTACAGCCTCAGACTGGTCATTTCTTAAGAGTCTTTAAGACTCAAGTTAGTAAATATTTAAACAATCTTGGTGTAATTTCAATTAATAATGTAATTAGAGCAATAGATTATGTATTGTTTGATGTAATCAACGAAACCTTATGGGTGGAACAAAATTATGATATAAAATATAAACTTTATTAA |
|
Protein Sequence
|
MDSRTGELITAHQAQSGVYTWEIANPLYFSITEHSKRPFNYNHDIITVQLRFNHNLRKELGIHKCFMTFKIWTTLQPQTGHFLRVFKTQVSKYLNNLGVISINNVIRAIDYVLFDVINETLWVEQNYDIKYKLY |
|
NCBI Accession
|
YP_009508209.1
|
|
Location
|
1221-1628 |
|
Gene Name
|
c2 |
|
Protein Name
|
C2 protein |
|
Coding Region
|
ATGCGATCTTCGTCACCATCCAACAGCCATTGTACTCAAGTTCCTATCAAGGTCCAACACAGAGCAGCCAAGCAGAGGCTTCAGAGGAGGAAGAGGATAGACCTTAATTGCGGGTGCTCGTACTACTTGTCACTCAACTGTCGCAACAATGGATTCACGCACCGGGGAACTCATCACTGCGCATCAGGCACAGAGTGGCGTCTATACCTGGGAAATCGCCAATCCCCTATATTTCAGCATCACGGAACACTCGAAGAGACCATTCAACTACAACCACGACATAATCACAGTACAACTCCGATTCAACCACAACCTAAGGAAGGAACTGGGGATTCACAAATGTTTCATGACCTTCAAGATCTGGACGACCTTACAGCCTCAGACTGGTCATTTCTTAAGAGTCTTTAA |
|
Protein Sequence
|
MRSSSPSNSHCTQVPIKVQHRAAKQRLQRRKRIDLNCGCSYYLSLNCRNNGFTHRGTHHCASGTEWRLYLGNRQSPIFQHHGTLEETIQLQPRHNHSTTPIQPQPKEGTGDSQMFHDLQDLDDLTASDWSFLKSL |
|
NCBI Accession
|
YP_009508210.1
|
|
Location
|
1522-2652 |
|
Gene Name
|
rep |
|
Protein Name
|
replication associated protein |
|
Coding Region
|
ATGCAAATGAGAAGTCAATTGGAGACACTTGACCAAATGGCTCGGCCACGTCGTTTTAAAATACAAGCCAAAAATTATTTCCTTACTTATCCCAAATGCAATTTAACTAAAGAAGAAGCACTTTCCCAATTATTAAATATAGATACTCCAACAAATAAAAGATTCATCAAAATCTGCAGAGAGTTGCACGAAGATGGGGAGCCTCATCTCCACATGCTCATCCAGTTCGAGGGCAAATTCCACTGCACGAATAACCGATTCTTCGACCTGGTATCCCCAACCAGGTCAGCACATTTCCATCCAAACATTCAGGGAGCTAAATCAAGCTCCGACGTCAAGTCCTACATCGACAAGGATGGAGACACACTTGAATGGGGTGAATTCCAGATCGACGGCAGAAGTGCTAGAGGAGGCTGCCAGAATGCTAACGACGCATGCGCCGAGGCATTAAACGCAGGTTCCGCTGAAGCCGCTATGGCTATTATTAAAGAGAAACTCCCTAAAGATTTTATTTTTCAGTATCATAATTTAAAATGTAATTTAGATAGGATTTTTACACCTCCGTTGGAGGATTATGTTTCTCCTTTTTTATGTTCTTCTTTCGATCAAGTTCCGGAAGAACTTGAAGAGTGGGCGGCGGAGAATGTTGTCAGTGCCGCTGCGCGGCCATTGAGACCCATAAGTATTGTGATTGAAGGGGATAGTCGTACCGGGAAGACAATGTGGGCTAGGTCATTGGGTCCACACAATTATTTGTGTGGTCATCTTGATCTTAGTCCAAAGGTGTATTCAAATGAAGCATGGTACAACGTAATAGATGACGTCGATCCTCATTATCTAAAGCACTTTAAGGAATTCATGGGCGCACAACGGGACTGGCAAAGCAACACAAAGTACGGGAAACCAATTCAAATTAAAGGAGGTATCCCGACAATCTTCCTCTGCAATCCAGGACCCACTTCATCATATAAAGAGTACTTGGACGAGCAAAAGAACGCACCACTAAAGGCCTGGGCAATTAAGAATGCGATCTTCGTCACCATCCAACAGCCATTGTACTCAAGTTCCTATCAAGGTCCAACACAGAGCAGCCAAGCAGAGGCTTCAGAGGAGGAAGAGGATAGACCTTAA |
|
Protein Sequence
|
MQMRSQLETLDQMARPRRFKIQAKNYFLTYPKCNLTKEEALSQLLNIDTPTNKRFIKICRELHEDGEPHLHMLIQFEGKFHCTNNRFFDLVSPTRSAHFHPNIQGAKSSSDVKSYIDKDGDTLEWGEFQIDGRSARGGCQNANDACAEALNAGSAEAAMAIIKEKLPKDFIFQYHNLKCNLDRIFTPPLEDYVSPFLCSSFDQVPEELEEWAAENVVSAAARPLRPISIVIEGDSRTGKTMWARSLGPHNYLCGHLDLSPKVYSNEAWYNVIDDVDPHYLKHFKEFMGAQRDWQSNTKYGKPIQIKGGIPTIFLCNPGPTSSYKEYLDEQKNAPLKAWAIKNAIFVTIQQPLYSSSYQGPTQSSQAEASEEEEDRP |
|
NCBI Accession
|
YP_009508211.1
|
|
Location
|
2202-2459 |
|
Gene Name
|
c4 |
|
Protein Name
|
C4 protein |
|
Coding Region
|
ATGGGGAGCCTCATCTCCACATGCTCATCCAGTTCGAGGGCAAATTCCACTGCACGAATAACCGATTCTTCGACCTGGTATCCCCAACCAGGTCAGCACATTTCCATCCAAACATTCAGGGAGCTAAATCAAGCTCCGACGTCAAGTCCTACATCGACAAGGATGGAGACACACTTGAATGGGGTGAATTCCAGATCGACGGCAGAAGTGCTAGAGGAGGCTGCCAGAATGCTAACGACGCATGCGCCGAGGCATTAA |
|
Protein Sequence
|
MGSLISTCSSSSRANSTARITDSSTWYPQPGQHISIQTFRELNQAPTSSPTSTRMETHLNGVNSRSTAEVLEEAARMLTTHAPRH |