Tomato leaf curl Sri Lanka virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_000841305.1 |
| Isolate |
Sri Lanka:Bandarawela |
| Release date |
2015/2/12 |
| Submitter |
Shih,S.L., Nakhla,M.K., Maxwell,D.P., Green,S.K., Hanson,P. |
| Host |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
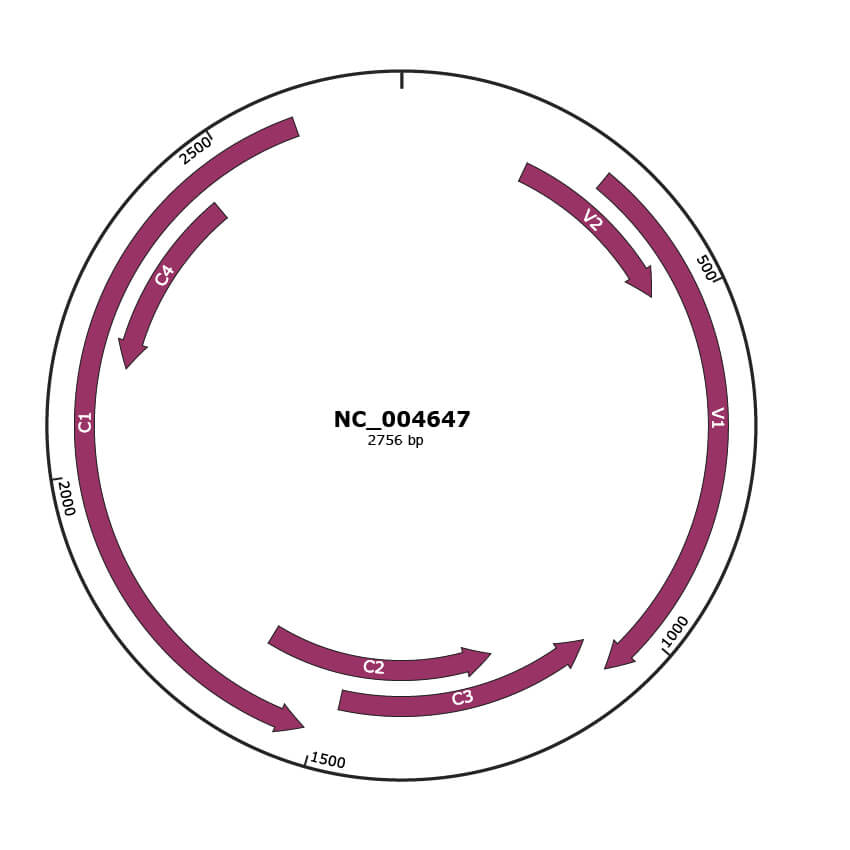
JBrowse
Genome
ACCGGATGGCCGCGCCCCTTTCTGTCTCTATCATTGACCCCACCACTAAATCATGTCCACCAATCATATGTCACACTGAAAGCTTAATTATTTATTTTTGTCCTTATATAAACTTAGTCACCAAGTTTTACTGTTATGTAAAATGTAGGATCCACTCTTAAATGATTTTCCTGAAACCGTACACGGATTCAGGTGTATGCTTGCTATAAAATACTTGCAGCTGATAGAAAATACGTATTCCCCTGACTCATTGGGATACGATCTGATACGTGATTTAATTTCCGTCGTCCGGGCTAAGAGCTATGTCCAAGCGTCCAGCAGATATGATCATTTCCGGGCCCGTCTCGAAGTATCGCCGACTTCTGAGCTCAATCAGCCCATACAGCAAGCGTGCTGCTGTCCGCATTGTCCGCGCCACAAAGGGAAAGGAATGGGCCAACAGGCCCATGAATCGGAAGCCCATGTTCTACAGAATGTATAGAAGCCCTGACGTCCCAAAGGGCTGTGAAGGCCCATGTAAGGTCCAGTCCTTCGAGTCTAGGCATGATGTAGTTCATATTGGTAAGGTTATGTGTATTAGTGATGTTACTAGGGGTACAGGTCTGACCCATAGGATAGGTAAGCGTTTCTGTGCTAAGTCTGTCTATGTTCTGGGAAAGATATGGATGGATGAGAACATCAAAACCAAGAACCACACTAACAGTGTTATGTTTTTCCTTGTTCGTGATCGTCGTCCCGTTGACAAGCCTCAAGATTTTGGTGATGTGTTTAACATGTTCGATAACGAGCCTAGTACCGCAACTGTCAAAAATATGCACAGGGATCGTTACCAGGTTCTCCGGAAGTGGCATGCTACTGTTACTGGTGGTCAGTATGCGTCTAAGGAGCAGGCTCTTGTGAAGAAATTTGTTAGGGTTAATAATTATGTTGTGTATAACCAGCAAGAGGCTGGCAAGTATGAGAATCATAGTGAGAATGCGTTGATGTTGTATATGGCATGTACTCATGCCTCAAACCCTGTGTATGCTACTCTGAAAATACGGATCTATTTCTACGATTCGGTGACAAATTAATAAAGATTAAATTTTATTATGTTAGAACTTTGTACATACATTGTTTGCGTTAATACATTCCATAATACATGATCGACAGCCCTAAGTACATTGTTTATGCTAATTACATCTAAATTTTTGATAAATTGCAACACTTGGGTTCTAAATACCCTTAAGAAATGACCAGTCTGAGGCTGTAAGGTCGTCCAGATTCGGAATGTTAGAAAACATTTGTGTATCCCCAACGCTTTCCGAAGGTTGTGGTTGAACTGAACCCTTACAGTTATCAGGTCTGTGTTCGAGTTGAATGGCCGGTTGTCGTGGTTGAGGATCTTGAAATATAGGGGATTTGGGACCTGCGAGATACTGACGCCATTCATTGCCTGAACTGCAGTTATGTGTTCCCCTGTGCGTAAATCCATGGTTCCTGCAGTTGATGCTTAGGTAATATGAACAACCACACTCAAGGTCTATTCTCTTCCTCCTGATTGTCTTCTTGGCTTGCCTGTGGAGAACCTTGATTGGTACCTGAGTATAGTGGCCCTGCGAGGGTGACGAAGATCGCATTCTTGAGTGCCCAATTTCTTAGTGCGGAATTCTTTTCTTCGTCCAAGAACTCTTTATAGCTGGAGTTGGGCCCTGGATTGCATAGGAATATAGTGGGAATGCCTCCTTTAATTTGAACTGGCTTTCCGTATTTGGTATTGCTTTGCCAGTCCCTTTGGGCCCCCATGAACTCTTTAAAGTGCTTCAAATAATGCGGATCGACATCATCAATGACGTTATACCATGCGTCATTTGAATACACTCTTGGGCTTAAGTCCAAATGGCCGCACAAGTAATTGTGTGGGCCGATGGACCTAGCCCACATTGTTTTGCCCGTACGACTATCACCCTCAACAATAATTCCTATGGGTCTTATAGGCCGCGCAGCGGCACTGACAACGTTAATCGCCGCCCACTCTTCAAGTTCATCAGGAACTTGATCAAAAGAAGAAAGAGAAAAAGGAGAAATATAAACCTCCACTGGAGGTGTAAAGATCCTATCTAAATTAGCATTTAAATTATGAAACTGTAATACATAATCTTTGGGAGCTTTCTCCCTTAAAATATTGAGTGCCGATGATTTAGACCCTGAATTGATTGCCTCGGCATATGCGTCGTTTGCAGACTGGCAACCTCCTCTAGCTGATCTTCCATCGACTTGGAAAATTCCAAAATCAAGGACGTCTCCGTCTTTTTCCATATAGGATTTGACATCCGACGAGCTTTTAGCTCCCTGAATGTTTGGATGGAAATGTGCTGATCGGGTTGGGGATACCAAGTCGAAGAATCTGTTGTTTTGACATTTGAATTTTCCTTCGAATTGGATGAGCACGTGTAGATGAGGTTCCCCATTATCGTGTAATTCTCTGCAAATTCTTATGAATAATTTGTTTGTTGGAGTATTTAGATTTTGTAATTGGGAAAGTGCTTCTTCTTTTGTAAGAGAACACTGAGGATATGTTAGAAAATAATTTTTTGCAAATATTTGAAAACGTTTTGGTGGAGACATATTGACTTGGTCAATTGGTACTCAACAAACTCGGCTATGCTATCGGTACTATGGTACTCAATATATACCTGAGTACTAAATGGCATAATTGTAATTTTGAGGAAATTTCCAATCTAATTCCCACCAAAAGCGGCCATCCGTCTAATATT
Gene Information
|
NCBI Accession
|
NP_808822.1
|
|
Location
|
197-481 |
|
Gene Name
|
V2 |
|
Protein Name
|
pre-coat protein |
|
Coding Region
|
ATGCTTGCTATAAAATACTTGCAGCTGATAGAAAATACGTATTCCCCTGACTCATTGGGATACGATCTGATACGTGATTTAATTTCCGTCGTCCGGGCTAAGAGCTATGTCCAAGCGTCCAGCAGATATGATCATTTCCGGGCCCGTCTCGAAGTATCGCCGACTTCTGAGCTCAATCAGCCCATACAGCAAGCGTGCTGCTGTCCGCATTGTCCGCGCCACAAAGGGAAAGGAATGGGCCAACAGGCCCATGAATCGGAAGCCCATGTTCTACAGAATGTATAG |
|
Protein Sequence
|
MLAIKYLQLIENTYSPDSLGYDLIRDLISVVRAKSYVQASSRYDHFRARLEVSPTSELNQPIQQACCCPHCPRHKGKGMGQQAHESEAHVLQNV |
|
NCBI Accession
|
NP_808823.1
|
|
Location
|
303-1073 |
|
Gene Name
|
V1 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGTCCAAGCGTCCAGCAGATATGATCATTTCCGGGCCCGTCTCGAAGTATCGCCGACTTCTGAGCTCAATCAGCCCATACAGCAAGCGTGCTGCTGTCCGCATTGTCCGCGCCACAAAGGGAAAGGAATGGGCCAACAGGCCCATGAATCGGAAGCCCATGTTCTACAGAATGTATAGAAGCCCTGACGTCCCAAAGGGCTGTGAAGGCCCATGTAAGGTCCAGTCCTTCGAGTCTAGGCATGATGTAGTTCATATTGGTAAGGTTATGTGTATTAGTGATGTTACTAGGGGTACAGGTCTGACCCATAGGATAGGTAAGCGTTTCTGTGCTAAGTCTGTCTATGTTCTGGGAAAGATATGGATGGATGAGAACATCAAAACCAAGAACCACACTAACAGTGTTATGTTTTTCCTTGTTCGTGATCGTCGTCCCGTTGACAAGCCTCAAGATTTTGGTGATGTGTTTAACATGTTCGATAACGAGCCTAGTACCGCAACTGTCAAAAATATGCACAGGGATCGTTACCAGGTTCTCCGGAAGTGGCATGCTACTGTTACTGGTGGTCAGTATGCGTCTAAGGAGCAGGCTCTTGTGAAGAAATTTGTTAGGGTTAATAATTATGTTGTGTATAACCAGCAAGAGGCTGGCAAGTATGAGAATCATAGTGAGAATGCGTTGATGTTGTATATGGCATGTACTCATGCCTCAAACCCTGTGTATGCTACTCTGAAAATACGGATCTATTTCTACGATTCGGTGACAAATTAA |
|
Protein Sequence
|
MSKRPADMIISGPVSKYRRLLSSISPYSKRAAVRIVRATKGKEWANRPMNRKPMFYRMYRSPDVPKGCEGPCKVQSFESRHDVVHIGKVMCISDVTRGTGLTHRIGKRFCAKSVYVLGKIWMDENIKTKNHTNSVMFFLVRDRRPVDKPQDFGDVFNMFDNEPSTATVKNMHRDRYQVLRKWHATVTGGQYASKEQALVKKFVRVNNYVVYNQQEAGKYENHSENALMLYMACTHASNPVYATLKIRIYFYDSVTN |
|
NCBI Accession
|
NP_808824.1
|
|
Location
|
1070-1474 |
|
Gene Name
|
C3 |
|
Protein Name
|
C3 protein |
|
Coding Region
|
ATGGATTTACGCACAGGGGAACACATAACTGCAGTTCAGGCAATGAATGGCGTCAGTATCTCGCAGGTCCCAAATCCCCTATATTTCAAGATCCTCAACCACGACAACCGGCCATTCAACTCGAACACAGACCTGATAACTGTAAGGGTTCAGTTCAACCACAACCTTCGGAAAGCGTTGGGGATACACAAATGTTTTCTAACATTCCGAATCTGGACGACCTTACAGCCTCAGACTGGTCATTTCTTAAGGGTATTTAGAACCCAAGTGTTGCAATTTATCAAAAATTTAGATGTAATTAGCATAAACAATGTACTTAGGGCTGTCGATCATGTATTATGGAATGTATTAACGCAAACAATGTATGTACAAAGTTCTAACATAATAAAATTTAATCTTTATTAA |
|
Protein Sequence
|
MDLRTGEHITAVQAMNGVSISQVPNPLYFKILNHDNRPFNSNTDLITVRVQFNHNLRKALGIHKCFLTFRIWTTLQPQTGHFLRVFRTQVLQFIKNLDVISINNVLRAVDHVLWNVLTQTMYVQSSNIIKFNLY |
|
NCBI Accession
|
NP_808825.1
|
|
Location
|
1215-1619 |
|
Gene Name
|
C2 |
|
Protein Name
|
C2 protein |
|
Coding Region
|
ATGCGATCTTCGTCACCCTCGCAGGGCCACTATACTCAGGTACCAATCAAGGTTCTCCACAGGCAAGCCAAGAAGACAATCAGGAGGAAGAGAATAGACCTTGAGTGTGGTTGTTCATATTACCTAAGCATCAACTGCAGGAACCATGGATTTACGCACAGGGGAACACATAACTGCAGTTCAGGCAATGAATGGCGTCAGTATCTCGCAGGTCCCAAATCCCCTATATTTCAAGATCCTCAACCACGACAACCGGCCATTCAACTCGAACACAGACCTGATAACTGTAAGGGTTCAGTTCAACCACAACCTTCGGAAAGCGTTGGGGATACACAAATGTTTTCTAACATTCCGAATCTGGACGACCTTACAGCCTCAGACTGGTCATTTCTTAAGGGTATTTAG |
|
Protein Sequence
|
MRSSSPSQGHYTQVPIKVLHRQAKKTIRRKRIDLECGCSYYLSINCRNHGFTHRGTHNCSSGNEWRQYLAGPKSPIFQDPQPRQPAIQLEHRPDNCKGSVQPQPSESVGDTQMFSNIPNLDDLTASDWSFLKGI |
|
NCBI Accession
|
NP_808826.1
|
|
Location
|
1516-2607 |
|
Gene Name
|
C1 |
|
Protein Name
|
rep protein |
|
Coding Region
|
ATGTCTCCACCAAAACGTTTTCAAATATTTGCAAAAAATTATTTTCTAACATATCCTCAGTGTTCTCTTACAAAAGAAGAAGCACTTTCCCAATTACAAAATCTAAATACTCCAACAAACAAATTATTCATAAGAATTTGCAGAGAATTACACGATAATGGGGAACCTCATCTACACGTGCTCATCCAATTCGAAGGAAAATTCAAATGTCAAAACAACAGATTCTTCGACTTGGTATCCCCAACCCGATCAGCACATTTCCATCCAAACATTCAGGGAGCTAAAAGCTCGTCGGATGTCAAATCCTATATGGAAAAAGACGGAGACGTCCTTGATTTTGGAATTTTCCAAGTCGATGGAAGATCAGCTAGAGGAGGTTGCCAGTCTGCAAACGACGCATATGCCGAGGCAATCAATTCAGGGTCTAAATCATCGGCACTCAATATTTTAAGGGAGAAAGCTCCCAAAGATTATGTATTACAGTTTCATAATTTAAATGCTAATTTAGATAGGATCTTTACACCTCCAGTGGAGGTTTATATTTCTCCTTTTTCTCTTTCTTCTTTTGATCAAGTTCCTGATGAACTTGAAGAGTGGGCGGCGATTAACGTTGTCAGTGCCGCTGCGCGGCCTATAAGACCCATAGGAATTATTGTTGAGGGTGATAGTCGTACGGGCAAAACAATGTGGGCTAGGTCCATCGGCCCACACAATTACTTGTGCGGCCATTTGGACTTAAGCCCAAGAGTGTATTCAAATGACGCATGGTATAACGTCATTGATGATGTCGATCCGCATTATTTGAAGCACTTTAAAGAGTTCATGGGGGCCCAAAGGGACTGGCAAAGCAATACCAAATACGGAAAGCCAGTTCAAATTAAAGGAGGCATTCCCACTATATTCCTATGCAATCCAGGGCCCAACTCCAGCTATAAAGAGTTCTTGGACGAAGAAAAGAATTCCGCACTAAGAAATTGGGCACTCAAGAATGCGATCTTCGTCACCCTCGCAGGGCCACTATACTCAGGTACCAATCAAGGTTCTCCACAGGCAAGCCAAGAAGACAATCAGGAGGAAGAGAATAGACCTTGA |
|
Protein Sequence
|
MSPPKRFQIFAKNYFLTYPQCSLTKEEALSQLQNLNTPTNKLFIRICRELHDNGEPHLHVLIQFEGKFKCQNNRFFDLVSPTRSAHFHPNIQGAKSSSDVKSYMEKDGDVLDFGIFQVDGRSARGGCQSANDAYAEAINSGSKSSALNILREKAPKDYVLQFHNLNANLDRIFTPPVEVYISPFSLSSFDQVPDELEEWAAINVVSAAARPIRPIGIIVEGDSRTGKTMWARSIGPHNYLCGHLDLSPRVYSNDAWYNVIDDVDPHYLKHFKEFMGAQRDWQSNTKYGKPVQIKGGIPTIFLCNPGPNSSYKEFLDEEKNSALRNWALKNAIFVTLAGPLYSGTNQGSPQASQEDNQEEENRP |
|
NCBI Accession
|
NP_808827.1
|
|
Location
|
2157-2450 |
|
Gene Name
|
C4 |
|
Protein Name
|
C4 protein |
|
Coding Region
|
ATGGGGAACCTCATCTACACGTGCTCATCCAATTCGAAGGAAAATTCAAATGTCAAAACAACAGATTCTTCGACTTGGTATCCCCAACCCGATCAGCACATTTCCATCCAAACATTCAGGGAGCTAAAAGCTCGTCGGATGTCAAATCCTATATGGAAAAAGACGGAGACGTCCTTGATTTTGGAATTTTCCAAGTCGATGGAAGATCAGCTAGAGGAGGTTGCCAGTCTGCAAACGACGCATATGCCGAGGCAATCAATTCAGGGTCTAAATCATCGGCACTCAATATTTTAA |
|
Protein Sequence
|
MGNLIYTCSSNSKENSNVKTTDSSTWYPQPDQHISIQTFRELKARRMSNPIWKKTETSLILEFSKSMEDQLEEVASLQTTHMPRQSIQGLNHRHSIF |