Tomato leaf curl Sinaloa virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_000871805.1 |
| Isolate |
Nicaragua:Santa Lucia |
| Release date |
2015/2/13 |
| Submitter |
Rojas,A., Kvarnheden,A., Marcenaro,D., Valkonen,J.P. |
| Host |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
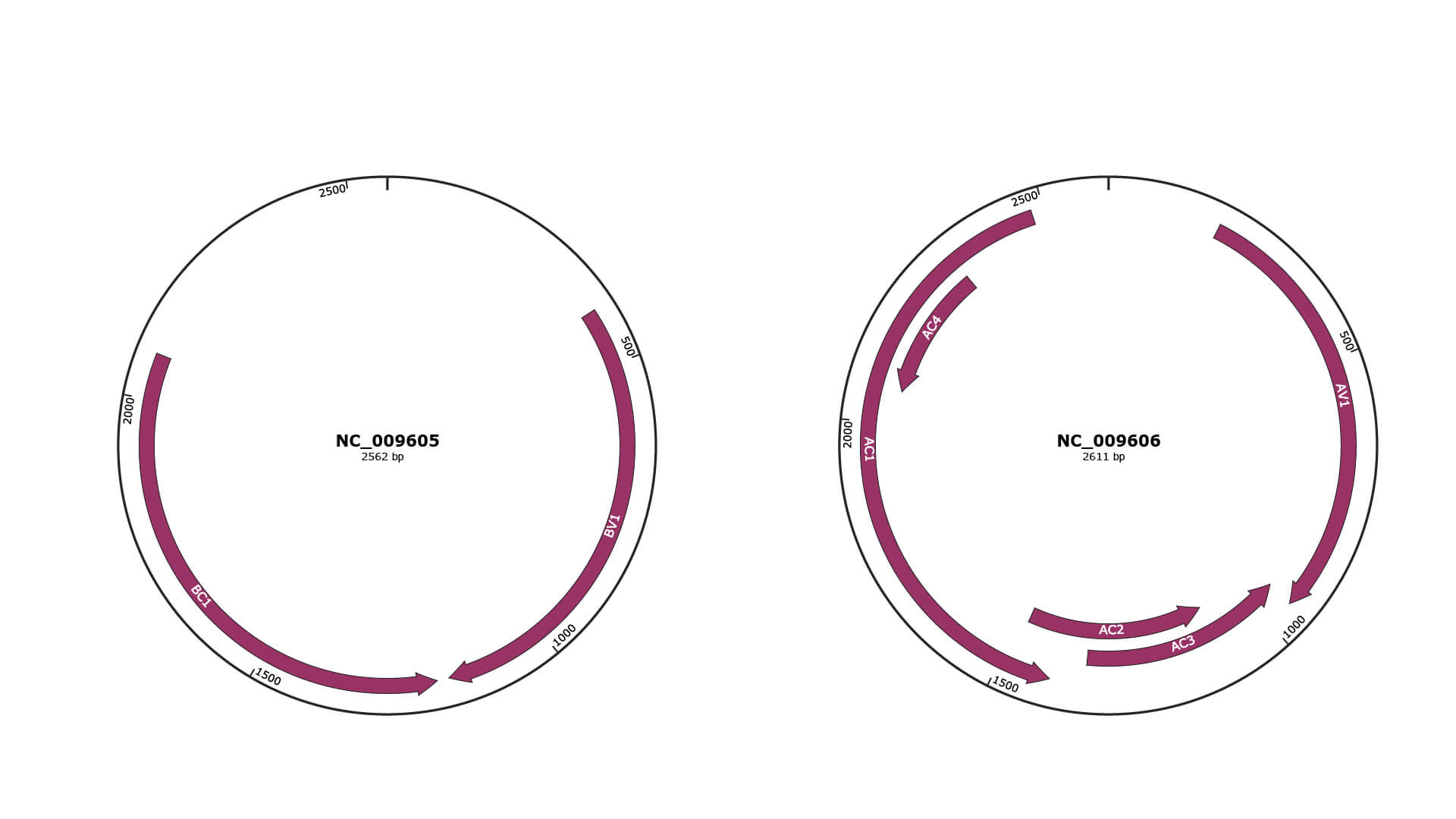
JBrowse
Genome
ACCTGATGGCCGCGCGATTTTTCACCCACCTATACGTGGCGCGCTCGCTGCCCTTGGATCTCTATTGGTGCTTTTCTTTTTGGTGCTTTCTACGTGGCGTCTTGCTATTCGCGTTTTTTGGGTGTTAGTGGTCGATAATGTCAGTGCTCAGCCTTTGAACATTCTTTTGTTCAAATTAAAGTGTATTGCTTTATTGACGTCATATATCATTACAACGACCACTTATCCTCTCCGTCGACGTGGTCGAATTGAGACCATGCTGTTGAGTCAAGTTAGGTTGTAGTTTGAGTCATCCTTTTCTATATATTGTGTCTGTCTGTTATATTATAATCGATATGACTCAACAGTCAACCACGTTAAAACGTTAGCTTATTATCCCTATAACGACTTGTCAAGTATTGATTATGTATTATTTTAGGAATAAACGTGGTTCATCCTTTATTCAACGGCGGTATCATTCACGTAATAATGTGTTTAAGCGTAATACTTCGATCAAACGAGATGATGGTAAACGTCGTCATGTCTATTCTAACAAGTCCAATGATGAGCCAAAGATGTCATCGCAACGTATTCACGAGAACCAGTTTGGTCAAGAGTTTGTGATGGTCCATAATTCTGCCATATCTACGTTTGTAAGCTATCCCAGTCTCGGTAAGACTGAACCGAATCGTAGCAGGTCCTACATTAAGTTGAAACGACTGCGTTTTAAGGGTACTGTGAAGATTGAACGTGTTGTGTCGGAAATGAACATGGACGGTTCTACTTCGAAGGTAGAAGGAGTGTTTTCACTTGTCATCGTAGTGGACCGTAAACCCCACTTGGGTGCATCTGGTTGTCTACATACCTTTGACGAACTCTTTGGAGCTAGGATTCACAGCCATGGTAATCTTAGCATAACACCTTCTCTCAAGGATCGCTTCTATATAAGACATGTGTTCAAACGTGTTCTATCTGTGGAGAAGGATACGACGATGGTGGATGTGGAAGGATCTACCACGCTTTCTAACAGGCGATATAGTTGTTGGTCTACATTTAAGGATTTGGATCACGACTCGTGCAATGGTGTTTATGGAAACATTAGCAAGAACGCTCTCTTAGTTTACTACTGTTGGATGTCAGATACTATGTCTAAGGCATCTACTTTTGTATCGTTTGACCTTGATTATGTCGGATGAATAATGAAAACTAATAAATTTTATTTCAATGATTTCGGCTGAACAGCCTTACAGTTACTTTTAATACATTCTTGTACAGTAGTCCTAACTAATTCGTTTAACTGCCCCATTGACATAGTTATATTGGATTCCGCTCTTTGGGCTCCTACTATAGAAGCAGATTCTCCTGGATCTAGGACTTCTGTTCCGAGCTTACTTATGTGTCTATACGGATGGAGCTCGTTCTCTATCTCGGAGTCCGCATCTGAATGGCCGCCTCCTATTGTACTTCTAGAAGCCCATGACTCTCCAGGCCTTATTTCAATTGGGCCTCTAAGCCCAACTCTGGACATGGACGCACATCTAATGGGCTTCCTCTCCCATTTACCGTAGTCGACGTGCGAGAAATCCACATCCTTGTCATTGAACTGTTTGGACAGGATTTTTACCGTGGGTGCCCGGAAAGGGATGTCCACCGAGTGTTTCGCCGTCGACAGCTTCAGCTTCCCTTTGAATTTCGCGAAGTGGGTCCTTTGATGAACATTTGTATCGCAAACTCTGTAATAGAGTTTCCATGGAATTGGGTCTTTCAACGAGAAGAACGAAGCGGAAAAGTAGTGGAGATCTATGTTGCATCTTATCGGAAAAGTCCATGATGCCTGTAGAGATTCGTTGTCTGTCATTCTTTTGTCGTGGATCTCCACTACCACCGACCCAGTTGCGTTAATCGGGACTTGTTGTCTGTATTCTATGACGCAGTGGTCTATTTTCATGCAGCTCCGACTTAGTCTAGCCGTCAACTGTGACGCCGTCGACGGAAATTGCAGAATTATCTCAGTTAAATCATGGGAAAGCTGATATTCGTCCCGATGAGACTCTATATAATTGAAGGCATTAGGAGGAAATGCTAATTGAGATTCCATTAGAGAAAGAATGGCCGCGCAGCGGAAGCAATTACTGAAGTTGAACTGGTGAAGATGAAATTAGGGAGCAATAACTAAAGTTGAACTGGTGAAGATGAAATTATGTTTAATTTGGGAATCATTCGCTGAAGAACAGTTGAAGAGGACGAATGTTTTGTGGGTCCACAAAAGTAATTTGAAACTGAAATCAGTTTTACAAACTCACTTGGTTGAACGAATTGTTTCTGAGAAATATGAGCAAAATGTTAAATAATTGGACTATGTGTAATTCTTAAATCTGATAGTCTTTATATAGAAACAGCATACCCTGGTTTGAGAGCTTTCAAGAGAAGATAAATGTTAACCGATGGCATTTTTGTAATAAGAAGGGTGTACTCCGATTGAGCTCTCAAACTTCTGTCTATGTAATTGGGGTAATGGTGTACAATATATACTAGAACTCTCTATAGAGTTTTGGGACACGTGGCGGCCATCAGTATAATATT
ACCTGATGGCCGCGCGATTTTCCCCCCCCTACACGCGCGTACGCTCCTCTTTAATTTGAATTAAAGTGTATTAGTGCGCTGTCGTCCAATCATATTGCGTCTGACGAGTCTAGATATTTGCAACAACTTTGGGCCCAAGTTGTTGAGTGTCTGCTATAAATTAAAGAGGCTTTGGCCCACTGACTTTAAATCAAAATGCCTAAGCGTGATGCCCCATGGCGCTCGTTCGCGGCAACTTCCAAGGTTAGTCGCAATGCTAATTATTCTCCACGGACTGGTATGGGGCCAAAGGTCGACAAGGCCACTGCTTGGGTGAATAGGCCCATGTATAGAAAGCCCAGGATCTACCGGGTTATGAGAGGCCCAGATGTTCCAAAAGGATGTGAAGGCCCATGTAAGGTCCAGTCATACGAGCAGCGCCACGATATTTCACATGTTGGGAAGGTCATGTGTATCTCCGACGTGACACGTGGTAATGGTCTCACCCACCGTGTGGGGAAGCGTTTTTGTGTTAAGTCCGTGTATATTCTCGGCAAGGTTTGGATGGATGATAACATCAAGTTGAAGAACCACACGAACAGTGTTATGTTTTGGTTGGTCAGGGACCGTAGGCCTTATGGTATTCCTATGGATTTCGGACAAGTGTTTAACATGTTCGATAACGAACCCAGTACCGCGACGATCAAGAACGATCTTAGAGATCGGTTTCAGGTCATGCACAGGTTTTATGCTAAGGTTACAGGTGGACAGTATGCTAGTAACGAGCAAGCTATAGTGAGGCGTTTTTGGAAGGTCAACAATCATGTGGTCTACAATCATCAAGAGGCAGGAAAATATGACAACCATACTGAGAACGCCCTGTTATTGTATATGGCATGTACTCATGCTTCTAACCCCGTGTATGCAACATTGAAAATTCGGATCTATTTTTATGATTCGATTGCTAATTAATAAAGTTTTATTTTTATTGAATGATCTTCAAGTACATAATTTACATATGATCTGTCTGTTGCAAAACGAACAGCTCTGATTACATTGTTTATCGAAATCACACCTAACTGATCTAAATACATATTAACTAAATGTCTAAACCTAGCTAAATAATTCGACCCAGAAGCTGTTATCAATGTCGTCCAGATTTGGAAGTTCAGGTATGCTTTGTGGAGATGCAACACTCTCCTCAGGTTGTGGTTGAACCGTATCTGTACATGGTATACCCTGGTCCTCGTGTACACTATGTCCTCTTCTCGGTACATCTTGAAATAGAGGGGATTTTCTATCTCCCAGATATAAACGCCATTCTCTGCTTGAGGTGCAGTGATGAGCGCCCCGGTGCGTGAATCCATGTCCCGTGCAGTCTATGTGGAGGTAGATGGTGCACCCGCACTCTAGATCAATCCGCCTTCTTCTAATGCTCCTCTTCTTGGCCTGCCTGTGTGCTGTCTTGATAGAGGGCGGATTGGAGGGTGACGAAGATTGCATTCTTGAGTGTCCAATTTTTGAGTGATGTGTTTTCTTCTTTGTTTAGGTAATCTTTATAGCTGGCACCCTCACCAGGATTGCAAAGCACGATTGATGGGATCCCACCTTTAATTTGAACTGGCTTGCCATACTTGCAATTTGACTGCCAGTCTTTCTGGGCCCCCAGAAGTTCTTTCCAGTGCTTTAGCTTTAGATATTGCGGTGTGACGTCGTCAATGACGTTATACTCCACTTCATTAGAGAACACTCTGGAATTGAAGTCGAGATGTCCACTGAGATAATTATGTGGGCCTAATGCCCGAGCCCACATCGTCTTCCCTGTCCTAGAATCACCTTCTATGATAATACTAATAGGTCTCTCTGGCCGCGCAGCTGAATCCTTTCCAAAATAATCATCTGCCCATTCTTGCATCTCGTCCGGAACGTTAGTGAAAGAAGAGAGTTGAAACGGAGGAACCCAGCGTTCCGGAGCCTTTTTGAATATTTTAGCCGCGTTAGCGACTAGGTTATGATGTTGAAGGAAGAAATGTTGTGGTTGTTCTTCCCGTATGATTCGCATTGCTTCGTCTGCACATGCTGCATTCAACGCCTTGGCATATGTGTCGTTTGTAGATTGTTTACCTCCTCTGGCAGATCTACCGTCGATCTGGAATTGTCCCCATTCGATTGTATCTCCATCCTTGTCGATGTAGGACTTGACGTCGGAACTTGATTTAGCTCCCTGAATGTTCGGATGGAAATGTGCTGACCTGGTAGGGGACACCAGATCGAAGAATCTGTTATTCGTGCACTGGTATTTGCCTTCGAACTGGATAAGGACGTGGAGATGAGGTTCCCCATTCTCGTGGAGCTCTCTGCAGATCTTGATGAATTTCTTGTTAACCGGAATTGTTAGGTTTTGTAATTGGGAAAGTGCTTCTTCTTTTGTAAGAGAACACTGGGGATATGTGAGAAAATAGTTTTTAGCTGAGACTTTGAAGCGTTTAACCGATGGCATTTTGGTAATAAGAAGGGTGTACTCCGATTGAGCTCTCAAACTTCTATCTATGTAATTGGGGTAATGGGGTACAATATATACTAGAACTCTCTATGGAGTTTTGGGACACGTGGCGGCCATCAGTATAATATT
Gene Information
|
NCBI Accession
|
YP_001294912.1
|
|
Location
|
405-1175 |
|
Gene Name
|
BV1 |
|
Protein Name
|
nuclear shuttle protein |
|
Coding Region
|
ATGTATTATTTTAGGAATAAACGTGGTTCATCCTTTATTCAACGGCGGTATCATTCACGTAATAATGTGTTTAAGCGTAATACTTCGATCAAACGAGATGATGGTAAACGTCGTCATGTCTATTCTAACAAGTCCAATGATGAGCCAAAGATGTCATCGCAACGTATTCACGAGAACCAGTTTGGTCAAGAGTTTGTGATGGTCCATAATTCTGCCATATCTACGTTTGTAAGCTATCCCAGTCTCGGTAAGACTGAACCGAATCGTAGCAGGTCCTACATTAAGTTGAAACGACTGCGTTTTAAGGGTACTGTGAAGATTGAACGTGTTGTGTCGGAAATGAACATGGACGGTTCTACTTCGAAGGTAGAAGGAGTGTTTTCACTTGTCATCGTAGTGGACCGTAAACCCCACTTGGGTGCATCTGGTTGTCTACATACCTTTGACGAACTCTTTGGAGCTAGGATTCACAGCCATGGTAATCTTAGCATAACACCTTCTCTCAAGGATCGCTTCTATATAAGACATGTGTTCAAACGTGTTCTATCTGTGGAGAAGGATACGACGATGGTGGATGTGGAAGGATCTACCACGCTTTCTAACAGGCGATATAGTTGTTGGTCTACATTTAAGGATTTGGATCACGACTCGTGCAATGGTGTTTATGGAAACATTAGCAAGAACGCTCTCTTAGTTTACTACTGTTGGATGTCAGATACTATGTCTAAGGCATCTACTTTTGTATCGTTTGACCTTGATTATGTCGGATGA |
|
Protein Sequence
|
MYYFRNKRGSSFIQRRYHSRNNVFKRNTSIKRDDGKRRHVYSNKSNDEPKMSSQRIHENQFGQEFVMVHNSAISTFVSYPSLGKTEPNRSRSYIKLKRLRFKGTVKIERVVSEMNMDGSTSKVEGVFSLVIVVDRKPHLGASGCLHTFDELFGARIHSHGNLSITPSLKDRFYIRHVFKRVLSVEKDTTMVDVEGSTTLSNRRYSCWSTFKDLDHDSCNGVYGNISKNALLVYYCWMSDTMSKASTFVSFDLDYVG |
|
NCBI Accession
|
YP_001294913.1
|
|
Location
|
1196-2077 |
|
Gene Name
|
BC1 |
|
Protein Name
|
movement protein |
|
Coding Region
|
ATGGAATCTCAATTAGCATTTCCTCCTAATGCCTTCAATTATATAGAGTCTCATCGGGACGAATATCAGCTTTCCCATGATTTAACTGAGATAATTCTGCAATTTCCGTCGACGGCGTCACAGTTGACGGCTAGACTAAGTCGGAGCTGCATGAAAATAGACCACTGCGTCATAGAATACAGACAACAAGTCCCGATTAACGCAACTGGGTCGGTGGTAGTGGAGATCCACGACAAAAGAATGACAGACAACGAATCTCTACAGGCATCATGGACTTTTCCGATAAGATGCAACATAGATCTCCACTACTTTTCCGCTTCGTTCTTCTCGTTGAAAGACCCAATTCCATGGAAACTCTATTACAGAGTTTGCGATACAAATGTTCATCAAAGGACCCACTTCGCGAAATTCAAAGGGAAGCTGAAGCTGTCGACGGCGAAACACTCGGTGGACATCCCTTTCCGGGCACCCACGGTAAAAATCCTGTCCAAACAGTTCAATGACAAGGATGTGGATTTCTCGCACGTCGACTACGGTAAATGGGAGAGGAAGCCCATTAGATGTGCGTCCATGTCCAGAGTTGGGCTTAGAGGCCCAATTGAAATAAGGCCTGGAGAGTCATGGGCTTCTAGAAGTACAATAGGAGGCGGCCATTCAGATGCGGACTCCGAGATAGAGAACGAGCTCCATCCGTATAGACACATAAGTAAGCTCGGAACAGAAGTCCTAGATCCAGGAGAATCTGCTTCTATAGTAGGAGCCCAAAGAGCGGAATCCAATATAACTATGTCAATGGGGCAGTTAAACGAATTAGTTAGGACTACTGTACAAGAATGTATTAAAAGTAACTGTAAGGCTGTTCAGCCGAAATCATTGAAATAA |
|
Protein Sequence
|
MESQLAFPPNAFNYIESHRDEYQLSHDLTEIILQFPSTASQLTARLSRSCMKIDHCVIEYRQQVPINATGSVVVEIHDKRMTDNESLQASWTFPIRCNIDLHYFSASFFSLKDPIPWKLYYRVCDTNVHQRTHFAKFKGKLKLSTAKHSVDIPFRAPTVKILSKQFNDKDVDFSHVDYGKWERKPIRCASMSRVGLRGPIEIRPGESWASRSTIGGGHSDADSEIENELHPYRHISKLGTEVLDPGESASIVGAQRAESNITMSMGQLNELVRTTVQECIKSNCKAVQPKSLK |
|
NCBI Accession
|
YP_001294914.1
|
|
Location
|
196-951 |
|
Gene Name
|
AV1 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGCCTAAGCGTGATGCCCCATGGCGCTCGTTCGCGGCAACTTCCAAGGTTAGTCGCAATGCTAATTATTCTCCACGGACTGGTATGGGGCCAAAGGTCGACAAGGCCACTGCTTGGGTGAATAGGCCCATGTATAGAAAGCCCAGGATCTACCGGGTTATGAGAGGCCCAGATGTTCCAAAAGGATGTGAAGGCCCATGTAAGGTCCAGTCATACGAGCAGCGCCACGATATTTCACATGTTGGGAAGGTCATGTGTATCTCCGACGTGACACGTGGTAATGGTCTCACCCACCGTGTGGGGAAGCGTTTTTGTGTTAAGTCCGTGTATATTCTCGGCAAGGTTTGGATGGATGATAACATCAAGTTGAAGAACCACACGAACAGTGTTATGTTTTGGTTGGTCAGGGACCGTAGGCCTTATGGTATTCCTATGGATTTCGGACAAGTGTTTAACATGTTCGATAACGAACCCAGTACCGCGACGATCAAGAACGATCTTAGAGATCGGTTTCAGGTCATGCACAGGTTTTATGCTAAGGTTACAGGTGGACAGTATGCTAGTAACGAGCAAGCTATAGTGAGGCGTTTTTGGAAGGTCAACAATCATGTGGTCTACAATCATCAAGAGGCAGGAAAATATGACAACCATACTGAGAACGCCCTGTTATTGTATATGGCATGTACTCATGCTTCTAACCCCGTGTATGCAACATTGAAAATTCGGATCTATTTTTATGATTCGATTGCTAATTAA |
|
Protein Sequence
|
MPKRDAPWRSFAATSKVSRNANYSPRTGMGPKVDKATAWVNRPMYRKPRIYRVMRGPDVPKGCEGPCKVQSYEQRHDISHVGKVMCISDVTRGNGLTHRVGKRFCVKSVYILGKVWMDDNIKLKNHTNSVMFWLVRDRRPYGIPMDFGQVFNMFDNEPSTATIKNDLRDRFQVMHRFYAKVTGGQYASNEQAIVRRFWKVNNHVVYNHQEAGKYDNHTENALLLYMACTHASNPVYATLKIRIYFYDSIAN |
|
NCBI Accession
|
YP_001294915.1
|
|
Location
|
948-1346 |
|
Gene Name
|
AC3 |
|
Protein Name
|
replication enhancer |
|
Coding Region
|
ATGGATTCACGCACCGGGGCGCTCATCACTGCACCTCAAGCAGAGAATGGCGTTTATATCTGGGAGATAGAAAATCCCCTCTATTTCAAGATGTACCGAGAAGAGGACATAGTGTACACGAGGACCAGGGTATACCATGTACAGATACGGTTCAACCACAACCTGAGGAGAGTGTTGCATCTCCACAAAGCATACCTGAACTTCCAAATCTGGACGACATTGATAACAGCTTCTGGGTCGAATTATTTAGCTAGGTTTAGACATTTAGTTAATATGTATTTAGATCAGTTAGGTGTGATTTCGATAAACAATGTAATCAGAGCTGTTCGTTTTGCAACAGACAGATCATATGTAAATTATGTACTTGAAGATCATTCAATAAAAATAAAACTTTATTAA |
|
Protein Sequence
|
MDSRTGALITAPQAENGVYIWEIENPLYFKMYREEDIVYTRTRVYHVQIRFNHNLRRVLHLHKAYLNFQIWTTLITASGSNYLARFRHLVNMYLDQLGVISINNVIRAVRFATDRSYVNYVLEDHSIKIKLY |
|
NCBI Accession
|
YP_001294916.1
|
|
Location
|
1093-1482 |
|
Gene Name
|
AC2 |
|
Protein Name
|
transcriptional activator |
|
Coding Region
|
ATGCAATCTTCGTCACCCTCCAATCCGCCCTCTATCAAGACAGCACACAGGCAGGCCAAGAAGAGGAGCATTAGAAGAAGGCGGATTGATCTAGAGTGCGGGTGCACCATCTACCTCCACATAGACTGCACGGGACATGGATTCACGCACCGGGGCGCTCATCACTGCACCTCAAGCAGAGAATGGCGTTTATATCTGGGAGATAGAAAATCCCCTCTATTTCAAGATGTACCGAGAAGAGGACATAGTGTACACGAGGACCAGGGTATACCATGTACAGATACGGTTCAACCACAACCTGAGGAGAGTGTTGCATCTCCACAAAGCATACCTGAACTTCCAAATCTGGACGACATTGATAACAGCTTCTGGGTCGAATTATTTAGCTAG |
|
Protein Sequence
|
MQSSSPSNPPSIKTAHRQAKKRSIRRRRIDLECGCTIYLHIDCTGHGFTHRGAHHCTSSREWRLYLGDRKSPLFQDVPRRGHSVHEDQGIPCTDTVQPQPEESVASPQSIPELPNLDDIDNSFWVELFS |
|
NCBI Accession
|
YP_001294917.1
|
|
Location
|
1409-2479 |
|
Gene Name
|
AC1 |
|
Protein Name
|
replication protein |
|
Coding Region
|
ATGCCATCGGTTAAACGCTTCAAAGTCTCAGCTAAAAACTATTTTCTCACATATCCCCAGTGTTCTCTTACAAAAGAAGAAGCACTTTCCCAATTACAAAACCTAACAATTCCGGTTAACAAGAAATTCATCAAGATCTGCAGAGAGCTCCACGAGAATGGGGAACCTCATCTCCACGTCCTTATCCAGTTCGAAGGCAAATACCAGTGCACGAATAACAGATTCTTCGATCTGGTGTCCCCTACCAGGTCAGCACATTTCCATCCGAACATTCAGGGAGCTAAATCAAGTTCCGACGTCAAGTCCTACATCGACAAGGATGGAGATACAATCGAATGGGGACAATTCCAGATCGACGGTAGATCTGCCAGAGGAGGTAAACAATCTACAAACGACACATATGCCAAGGCGTTGAATGCAGCATGTGCAGACGAAGCAATGCGAATCATACGGGAAGAACAACCACAACATTTCTTCCTTCAACATCATAACCTAGTCGCTAACGCGGCTAAAATATTCAAAAAGGCTCCGGAACGCTGGGTTCCTCCGTTTCAACTCTCTTCTTTCACTAACGTTCCGGACGAGATGCAAGAATGGGCAGATGATTATTTTGGAAAGGATTCAGCTGCGCGGCCAGAGAGACCTATTAGTATTATCATAGAAGGTGATTCTAGGACAGGGAAGACGATGTGGGCTCGGGCATTAGGCCCACATAATTATCTCAGTGGACATCTCGACTTCAATTCCAGAGTGTTCTCTAATGAAGTGGAGTATAACGTCATTGACGACGTCACACCGCAATATCTAAAGCTAAAGCACTGGAAAGAACTTCTGGGGGCCCAGAAAGACTGGCAGTCAAATTGCAAGTATGGCAAGCCAGTTCAAATTAAAGGTGGGATCCCATCAATCGTGCTTTGCAATCCTGGTGAGGGTGCCAGCTATAAAGATTACCTAAACAAAGAAGAAAACACATCACTCAAAAATTGGACACTCAAGAATGCAATCTTCGTCACCCTCCAATCCGCCCTCTATCAAGACAGCACACAGGCAGGCCAAGAAGAGGAGCATTAG |
|
Protein Sequence
|
MPSVKRFKVSAKNYFLTYPQCSLTKEEALSQLQNLTIPVNKKFIKICRELHENGEPHLHVLIQFEGKYQCTNNRFFDLVSPTRSAHFHPNIQGAKSSSDVKSYIDKDGDTIEWGQFQIDGRSARGGKQSTNDTYAKALNAACADEAMRIIREEQPQHFFLQHHNLVANAAKIFKKAPERWVPPFQLSSFTNVPDEMQEWADDYFGKDSAARPERPISIIIEGDSRTGKTMWARALGPHNYLSGHLDFNSRVFSNEVEYNVIDDVTPQYLKLKHWKELLGAQKDWQSNCKYGKPVQIKGGIPSIVLCNPGEGASYKDYLNKEENTSLKNWTLKNAIFVTLQSALYQDSTQAGQEEEH |
|
NCBI Accession
|
YP_001294918.1
|
|
Location
|
2065-2322 |
|
Gene Name
|
AC4 |
|
Protein Name
|
AC4 protein |
|
Coding Region
|
ATGGGGAACCTCATCTCCACGTCCTTATCCAGTTCGAAGGCAAATACCAGTGCACGAATAACAGATTCTTCGATCTGGTGTCCCCTACCAGGTCAGCACATTTCCATCCGAACATTCAGGGAGCTAAATCAAGTTCCGACGTCAAGTCCTACATCGACAAGGATGGAGATACAATCGAATGGGGACAATTCCAGATCGACGGTAGATCTGCCAGAGGAGGTAAACAATCTACAAACGACACATATGCCAAGGCGTTGA |
|
Protein Sequence
|
MGNLISTSLSSSKANTSARITDSSIWCPLPGQHISIRTFRELNQVPTSSPTSTRMEIQSNGDNSRSTVDLPEEVNNLQTTHMPRR |