Tomato leaf curl Seychelles virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_000871445.1 |
| Isolate |
Seychelles:Mahe |
| Release date |
2015/2/13 |
| Submitter |
Lefeuvre,P., Delatte,H., Naze,F., Dogley,W., Reynaud,B., Lett,J.M. |
| Host |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
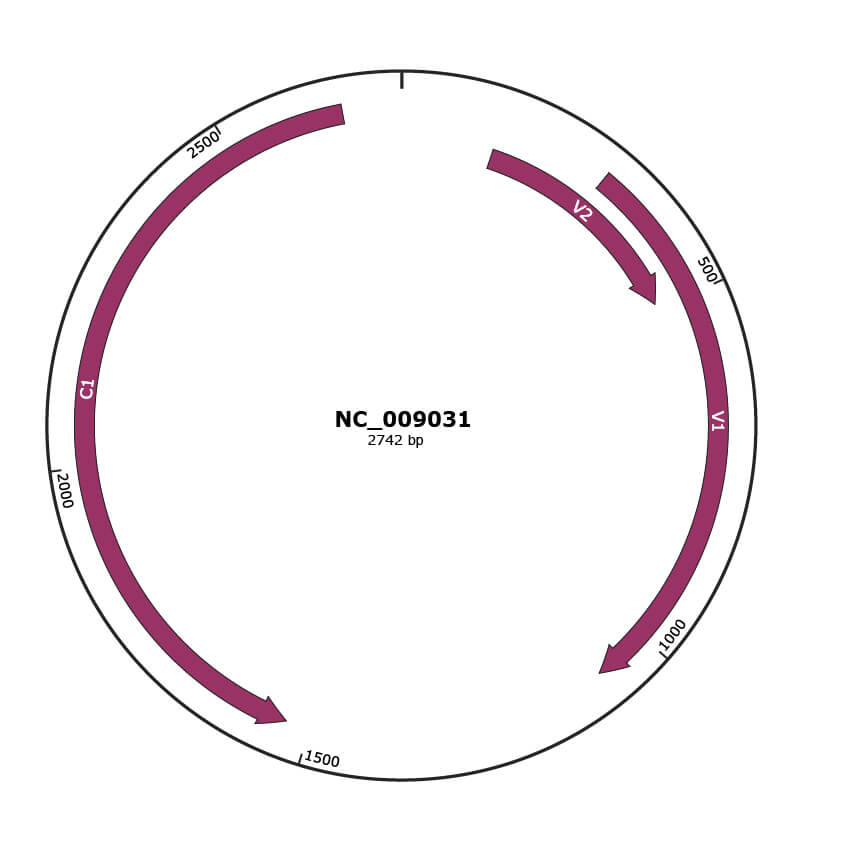
Genomic Organization
JBrowse
Genome
ACCGGATGGCCGCGCCCCCAAAAAAGAAAGTGGGCCCCGCGCACTAGTTTGTGTCGGCCAATGAGAGAGGTCCGTCATAGCTTAGTTATTTCATTTTGGTCTTTAAATTGCGTGGTCCCCAAGCTTCAGTCGTTGTCAGTATGTGGGACCCACTTGTAAACGAGTTCCCAGACTCTGTTCATGGTTTTCGTTGTATGCTTGCTATTAAATATTTGCAGGCCGTGGAAGAAACTTACGAGCCCAATACATTGGGCTACGATTTAATTCGTGATCTTATTTGTGTTATTAGGGCCCGTGATTATGTCGAAGCGACCCGGAGATATAATAATTTCCACACCCGTCTCGAAGGTTCGTCGAAGGCTGAACTTCGACAGCCCTTATACCAGCCGTGTTGCTGCCCCCATTGCCCAAGGCACAAGCAGACGTCGATCATGGACGTACAGGCCCATGTATCGAAAGCCCAGGATGTATCGAATGTACAAAAGTCCTGATGTTCCTCGTGGTTGTGAAGGGCCATGTAAGGTCCAGTCGTATGAGCAGAGGGATGATGTCAAGCACACCGGTATTGTTCGTTGTGTTAGTGATGTTACGCGTGGTTCGGGTATTACCCATAGAGTTGGCAAGAGGTTTTGTATTAAGTCGATATATATCTTAGGTAAGATCTGGATGGATGACAATATCAAGAAGCAGAATCATACTAATCAGGTTATGTTTTTCCTTGTTCGTGATAGAAGGCCCTACGGCTCGGCTCCAATGGATTTTGGACAGGTGTTTAATATGTTTGATAATGAGCCCAGTACAGCTACGGTGAAGAATGATTTGAGGGACAGATATCAGGTCATGAGGAAATTTCATTCAACTGTAGTTGGTGGACCCTCTGGATCGAAGGAGCAGGCATTAGTTAAGAGGTTTTTTAGGATTAATAGCCATGTAACTTATAATCATCAGGAGGCAGCTAAGTATGAGAACCATACTGAGAATGCCTTATTATTGTATATGGCATGTACTCATGCGTCTAATCCAGTGTATGCTACTCTTAAGATACGGATCTATTTCTATGATTCGGTCAGTAATTAATAGATATTAAATTTTATTGCATGATTCTCCGTAACTTGGAGGGTATTTACAAGTACATCGTGTAATACATAATCAACTGCTCTAATTATTGCATTAATTGAAATTACACCTAAGGAATCTAAATACTTGAGAACTTGGGTCTTAAATACGGTTAAGAAACGACCAGTCTGAGGGCGTAAGCTCGTCCAGACCTTGAAGTTGAGAAAACATTTGTGAATCCCCAACGCCTTCCTCAGGTTGTGGTTGAACCTTATTTGGAATGATATGATGTCTTGGTTCGTGTTGAATGGCCGGCTGTCGTGGTCGATGATCTTGAAATAGAGGGGATTTTTTATCTCCCAGATAAACACGCCACTCTGTGCTTGAGCTGCAGTGATGAGTTCCCCGGTGCGTAATCCATGGCTGCTACAATTGATATGTATATAATATGAGCAGCCGCAGTCTAGGTCTATGCGCTTACGTCTGACTGCTCTCGTTTTCGCTATGCGGTGTTGGACCTTGATTGGTACTTGTGAAGAGTGGCTCGTGGAGGGTGATGAAGGTGGCATTCTTGAAGGCCCAGTCTTTTAGTGGTGTATTCTTTTCCTCGTCTAGATACTCTTTATACGAGGATGTTGGTCCTGGATTGCAGAGGAAGATAGTGGGAATTCCGCCTTTAATTTGAATGGGCTTCCCGTACTTGGTGTTGCTTTGCCAGTCCCTCTGGGCCCCCATGAACTCCTTAAAGTGCTTCAGGTAGTGCGGATCAACGTCATCAATGACGTTATACCATGCATCATTGGAGTACACTTTTGGACTCAGGTCCAGATGCCCGCATAGGTAATTGTGGGGTCCTAATGACCTGGCCCACATTGTCTTGCCTGTACGACTATCACCCTCTATCACAATACTAATCGGTCTCCAAGGCCGCGCAGCGGCACCCATCACGTTTTCAGCCGCCCAGACTTCAAGTTCTTCCGGAACTTGATTGAAAGAAGAACAAAGAAAAGGAGAAATATAAGGAGCCGGAGGCTCCTGAAAAATCCTATCTAAATTACTAACTAAATTATGATACTGAAAAATAAATTTTTCAGGGAGTTTCTCCCTTATGATTTGCAAAGCAGCGTCTTTACTACCTGCATTTAAGGCATCCGCTGCCGCATCATTAGCTGTCTGCTGACCTCCTCTAGCAGATCTTCCGTCGACCTGAAAAGTACCCCAGTCGATGTAATCACCGTCCTTCTCGATGTAGGACTTGACATCTGATGAGGATTTAGCTCCCTGGAAATTTGGATGGAATTGGGAGGAGCTGGTGGGGTGTTGAAGGTCGAAATGTCTGGGGTTTTTAAATTGGGCTTTACCCTTGAACTGGATGAGAGCATGGAGGTGCAGAGACCCATCCTGGTGTTTTTCCTGGCTAACTCTGATAAATAATTTATCAGATGGGCATTTTATTGCCTTTAATAGCTCAAGAGCTATTTCTTTAGAAAGAGAGCATTTGGGATATGTAAGGAAGATATTTTTAGCTGACACTCTAAAACCTGGTTGACGAGGCATATTGGTGTCTTTCAAAACTCTACGGAATTGGTGTCTTTGGTGTCTCATTTATAGCTGGGACACCAATGGCATTTTGGTAAATTTAGCACCTTTAATTTGAATTTCAAAAGCGGCCATCCGTATAATATT
Gene Information
|
NCBI Accession
|
YP_001040014.1
|
|
Location
|
141-491 |
|
Gene Name
|
V2 |
|
Protein Name
|
movement protein |
|
Coding Region
|
ATGTGGGACCCACTTGTAAACGAGTTCCCAGACTCTGTTCATGGTTTTCGTTGTATGCTTGCTATTAAATATTTGCAGGCCGTGGAAGAAACTTACGAGCCCAATACATTGGGCTACGATTTAATTCGTGATCTTATTTGTGTTATTAGGGCCCGTGATTATGTCGAAGCGACCCGGAGATATAATAATTTCCACACCCGTCTCGAAGGTTCGTCGAAGGCTGAACTTCGACAGCCCTTATACCAGCCGTGTTGCTGCCCCCATTGCCCAAGGCACAAGCAGACGTCGATCATGGACGTACAGGCCCATGTATCGAAAGCCCAGGATGTATCGAATGTACAAAAGTCCTGA |
|
Protein Sequence
|
MWDPLVNEFPDSVHGFRCMLAIKYLQAVEETYEPNTLGYDLIRDLICVIRARDYVEATRRYNNFHTRLEGSSKAELRQPLYQPCCCPHCPRHKQTSIMDVQAHVSKAQDVSNVQKS |
|
NCBI Accession
|
YP_001040015.1
|
|
Location
|
301-1077 |
|
Gene Name
|
V1 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGTCGAAGCGACCCGGAGATATAATAATTTCCACACCCGTCTCGAAGGTTCGTCGAAGGCTGAACTTCGACAGCCCTTATACCAGCCGTGTTGCTGCCCCCATTGCCCAAGGCACAAGCAGACGTCGATCATGGACGTACAGGCCCATGTATCGAAAGCCCAGGATGTATCGAATGTACAAAAGTCCTGATGTTCCTCGTGGTTGTGAAGGGCCATGTAAGGTCCAGTCGTATGAGCAGAGGGATGATGTCAAGCACACCGGTATTGTTCGTTGTGTTAGTGATGTTACGCGTGGTTCGGGTATTACCCATAGAGTTGGCAAGAGGTTTTGTATTAAGTCGATATATATCTTAGGTAAGATCTGGATGGATGACAATATCAAGAAGCAGAATCATACTAATCAGGTTATGTTTTTCCTTGTTCGTGATAGAAGGCCCTACGGCTCGGCTCCAATGGATTTTGGACAGGTGTTTAATATGTTTGATAATGAGCCCAGTACAGCTACGGTGAAGAATGATTTGAGGGACAGATATCAGGTCATGAGGAAATTTCATTCAACTGTAGTTGGTGGACCCTCTGGATCGAAGGAGCAGGCATTAGTTAAGAGGTTTTTTAGGATTAATAGCCATGTAACTTATAATCATCAGGAGGCAGCTAAGTATGAGAACCATACTGAGAATGCCTTATTATTGTATATGGCATGTACTCATGCGTCTAATCCAGTGTATGCTACTCTTAAGATACGGATCTATTTCTATGATTCGGTCAGTAATTAA |
|
Protein Sequence
|
MSKRPGDIIISTPVSKVRRRLNFDSPYTSRVAAPIAQGTSRRRSWTYRPMYRKPRMYRMYKSPDVPRGCEGPCKVQSYEQRDDVKHTGIVRCVSDVTRGSGITHRVGKRFCIKSIYILGKIWMDDNIKKQNHTNQVMFFLVRDRRPYGSAPMDFGQVFNMFDNEPSTATVKNDLRDRYQVMRKFHSTVVGGPSGSKEQALVKRFFRINSHVTYNHQEAAKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSVSN |
|
NCBI Accession
|
YP_001040016.1
|
|
Location
|
1534-2661 |
|
Gene Name
|
C1 |
|
Protein Name
|
replication associated protein |
|
Coding Region
|
ATGAGACACCAAAGACACCAATTCCGTAGAGTTTTGAAAGACACCAATATGCCTCGTCAACCAGGTTTTAGAGTGTCAGCTAAAAATATCTTCCTTACATATCCCAAATGCTCTCTTTCTAAAGAAATAGCTCTTGAGCTATTAAAGGCAATAAAATGCCCATCTGATAAATTATTTATCAGAGTTAGCCAGGAAAAACACCAGGATGGGTCTCTGCACCTCCATGCTCTCATCCAGTTCAAGGGTAAAGCCCAATTTAAAAACCCCAGACATTTCGACCTTCAACACCCCACCAGCTCCTCCCAATTCCATCCAAATTTCCAGGGAGCTAAATCCTCATCAGATGTCAAGTCCTACATCGAGAAGGACGGTGATTACATCGACTGGGGTACTTTTCAGGTCGACGGAAGATCTGCTAGAGGAGGTCAGCAGACAGCTAATGATGCGGCAGCGGATGCCTTAAATGCAGGTAGTAAAGACGCTGCTTTGCAAATCATAAGGGAGAAACTCCCTGAAAAATTTATTTTTCAGTATCATAATTTAGTTAGTAATTTAGATAGGATTTTTCAGGAGCCTCCGGCTCCTTATATTTCTCCTTTTCTTTGTTCTTCTTTCAATCAAGTTCCGGAAGAACTTGAAGTCTGGGCGGCTGAAAACGTGATGGGTGCCGCTGCGCGGCCTTGGAGACCGATTAGTATTGTGATAGAGGGTGATAGTCGTACAGGCAAGACAATGTGGGCCAGGTCATTAGGACCCCACAATTACCTATGCGGGCATCTGGACCTGAGTCCAAAAGTGTACTCCAATGATGCATGGTATAACGTCATTGATGACGTTGATCCGCACTACCTGAAGCACTTTAAGGAGTTCATGGGGGCCCAGAGGGACTGGCAAAGCAACACCAAGTACGGGAAGCCCATTCAAATTAAAGGCGGAATTCCCACTATCTTCCTCTGCAATCCAGGACCAACATCCTCGTATAAAGAGTATCTAGACGAGGAAAAGAATACACCACTAAAAGACTGGGCCTTCAAGAATGCCACCTTCATCACCCTCCACGAGCCACTCTTCACAAGTACCAATCAAGGTCCAACACCGCATAGCGAAAACGAGAGCAGTCAGACGTAA |
|
Protein Sequence
|
MRHQRHQFRRVLKDTNMPRQPGFRVSAKNIFLTYPKCSLSKEIALELLKAIKCPSDKLFIRVSQEKHQDGSLHLHALIQFKGKAQFKNPRHFDLQHPTSSSQFHPNFQGAKSSSDVKSYIEKDGDYIDWGTFQVDGRSARGGQQTANDAAADALNAGSKDAALQIIREKLPEKFIFQYHNLVSNLDRIFQEPPAPYISPFLCSSFNQVPEELEVWAAENVMGAAARPWRPISIVIEGDSRTGKTMWARSLGPHNYLCGHLDLSPKVYSNDAWYNVIDDVDPHYLKHFKEFMGAQRDWQSNTKYGKPIQIKGGIPTIFLCNPGPTSSYKEYLDEEKNTPLKDWAFKNATFITLHEPLFTSTNQGPTPHSENESSQT |