Blechum yellow vein virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_004787075.1 |
| Isolate |
Philippines |
| Release date |
2021/6/1 |
| Submitter |
Tsai,W.S., Shih,S.L., Lee,L.M., Dolores,L.M., Kenyon,L. |
| Host |
|
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
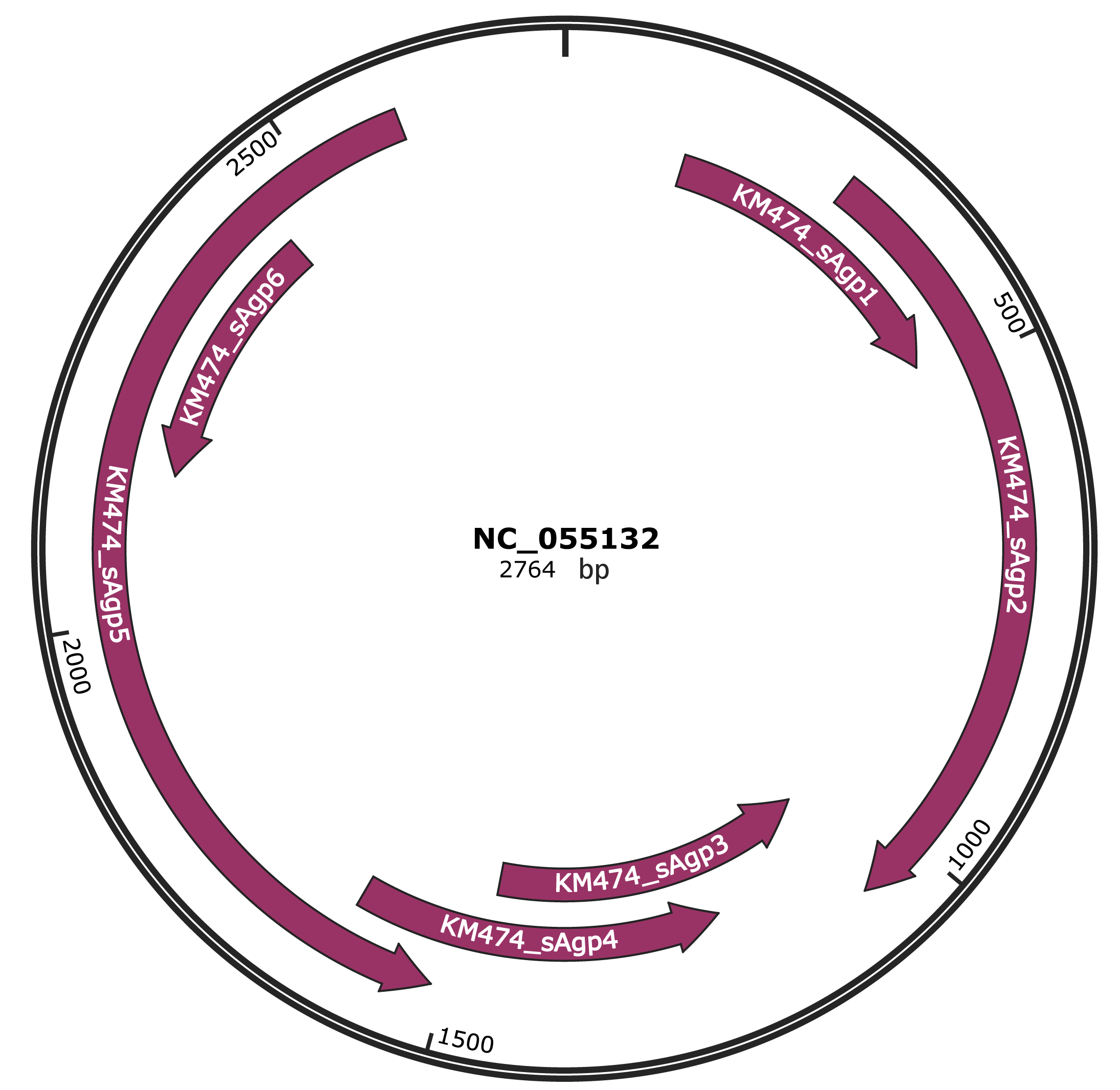
JBrowse
Genome
ACCGGATGGCCGCGATTTTTTTAAGGTGGGCCCCCTCCACTAACTCTTGTCGGCCAATAGAAACGCTCCCTCATCGCTTAGTTATCATGTGGTCCCCTATTTAATTCTTGCTCAGCAAGTTTTGTTTAACAATGTGGGATCCATTGTTGAACGAGTTCCCTGAAACCATGTACGGTTTCAGGTGTATGCTCGCTGTAAAATACTTGCAGTTGGTAGAATCTACGTATTCACCAGATACACTCGGGTACGATCTTATTCGAGATTTAATTTCTGTCTTACGTGCAAGGAATTATGTCGAAGCGACCAGCAGATATTGTCATTTCCACACCCGCCTCGAAGGTACGACGCCGTCTCAACTTCGAGAGCCCTTACAACAGCCGTGCTGCTGCCCCCACTGTCCTCGTCACAAACAAAAGGAGAACATGGGTCAACCGGCCCATGTACAGGAAGCCCAGAATGTACAGAATGTACAGAAGCCCTGATGTCCCCCGTGGGTGTGAAGGCCCATGTAAGGTCCAATCTTATGAACAGCGTCATGATATAGCCCATGTAGGTAAGGTTATTTGTGTCTCCGATGTCACGCGTGGTAATGGGCTTACCCATCGTGTGGGTAAGAGGTTTTGTGTTAAGTCCGTTTATGTGTTGGGTAAGGTCTGGATGGATGAAAACATCAAGACTAAGAACCACACAAATACCGTCATGTTTTTTTTAGTTCGTGATAGGAAACCTTTTGGTTCTCCCCAGGATTTCGGTCAGGTGTTTAACATGTATGATAACGAGCCTAGTACTGCTACTGTGAAGAATGACAACAGAGATAGGTTTCAAGTCCTCCGTCGATTTCAAGCTACTGTGACTGGTGGTCAGTATGCAAGCAAGGAGCAAGCTCTAGTGAGGAAGTTTATGAAGATTAACAACCATGTGACTTACAATCATCAGGAAGCTGCGAAGTATGAAAACCATACTGAGAATGCTTTGTTGTTGTATATGGCATGTACTCATGCCGCTAATCCAGTGTATGCGACTTTGAAAATTCGGATCTATTTTTATGATTCGATACAGAATTAATAAAGATTGAATTTTATTATATATCGATCTTGTACATCTATTGTCCCTACGAATACATCCAGCAATACATGTCTAATTGCTCGAATTACATTATTGAGACTAATAACACCCAAATTATCTAAGTACTTCATACATTGATATTTAAATACGCGCAAGAAACGCGAGGTCTGAGGATGTAAACGAGTCCAGATCCGGAAGTCCAGAAAACACTGGTGTATCCCCAATGCTTTCCTCAGGTTGTGGTTGAACCTGATGTGTATTGTGATGATGTCGTGGTTCGTGAAGGCTGGTTTGTTCTTGTGGCCTGTTATCTTGAAATACAGGGGATTTGGTACCGTCCAGATATACGCGCCATTCTCGGCTTGAGCTGCAGTGATGTATTCCCCTGTGCGTGAATCCATCGTTGTGGCAGTTTATGGATAGATAGTATGTACAGCCGCAGTTGAGATCAACTCGCCTCCTGCGAATGGTCTTCTTCTTCGCGATGCGGTGCTGGACTTTGATTGGTACCTGAGTAGAGTGGCCCCGTGAGGGTGATGAATTCTGCATTCTTTAATGCCCAGTCTTTGAGTGCAGCATTCTTCTCCTCGTCCAGATATTCTTTATAGCTGGAGTTGGGACCAGGATTGCAGAGGAAGATAGTGGGAATACCTCCTTTAATTTGAATGGGCTTCCCGTACTTTGTGTTGCTTTGCCAGTCTCTCTGGGCCCCCATGAATTCTTTAAAATGCTTTAGGTAGTGGGGGTCGACGTCATCAATGACGTTGTACCAAGCATCATTACTGTAGACCTTTGGACTTAAGTCCAGATGCCCACATAAGTAATTATGTGGTCCCAGAGACCTGGCCCACATCGTCTTCCCTGTCCTACTATCGCCCTCTACCACAATACTCTTGGGCCTCCATGGCCGCGCAGCGGCACTCACAACATTCTCCGCAGCCCACTCTTCAAGTTCTTCTGGAACTTGATCGAATGAAGAAGAAGAAAAAGGACAAACAAAAACCTCTAAAGGAGGTGCAAAAATCCTATCTAAATTGGCATTTAAATTATGAAATTGTAAAATATAATCTTTAGGGGCTAATTCCCTAATTACATTAAGAGCCTCCGACTTACTTCCAGTGTTAAGCGCCTTGGCGTAAGCATCATTGGCTGATTGTTGTCCCCCTCTTGCAGATCTTCCATCGATCTGAAACTCACCCCATTCGAGGGTGTCTCCGTCCTTATCCAAATAGGATTTGACATCTGAGCTTGATTTAGCTCCCTGAATGTTCGGATGGAAATGTGCTGACCTGGAAGGGGATGTAAGGTCGAAGAATCGTTGATTCGTGCACCTGAATTTCCCCTCGAATTGGAGGAGCACGTGGAGATGAGGGCTCCCATCTTCGTGCAGTTCTCTGCAGATCTTGATGAATAGTTTATTTGTTGGTGTATCTAGGGTTTGTAATTGGGAAAGTGCTTCCTCTTTAGTAAGAGAGCAGTGTGGATAAGTAAGGAAATAATTTCTGGCATTTATTTGGAATTTTCTCGGTGGTGCCATGTTGACTGGTCAATGGGTACCGATTGAGAGGATTTCAAAGTGCTCTGGGTATCGGTACACTGGTACCCATATATACTCGGTTACCTAATGGCATAATCGTAATTCCCAAAAGAAATTCAAAATTCAAATTTTGAATCCGAAAGCGGCCATCCGTATAATATT
Gene Information
|
NCBI Accession
|
YP_010084346.1
|
|
Location
|
132-482 |
|
Protein Name
|
V2 |
|
Coding Region
|
ATGTGGGATCCATTGTTGAACGAGTTCCCTGAAACCATGTACGGTTTCAGGTGTATGCTCGCTGTAAAATACTTGCAGTTGGTAGAATCTACGTATTCACCAGATACACTCGGGTACGATCTTATTCGAGATTTAATTTCTGTCTTACGTGCAAGGAATTATGTCGAAGCGACCAGCAGATATTGTCATTTCCACACCCGCCTCGAAGGTACGACGCCGTCTCAACTTCGAGAGCCCTTACAACAGCCGTGCTGCTGCCCCCACTGTCCTCGTCACAAACAAAAGGAGAACATGGGTCAACCGGCCCATGTACAGGAAGCCCAGAATGTACAGAATGTACAGAAGCCCTGA |
|
Protein Sequence
|
MWDPLLNEFPETMYGFRCMLAVKYLQLVESTYSPDTLGYDLIRDLISVLRARNYVEATSRYCHFHTRLEGTTPSQLREPLQQPCCCPHCPRHKQKENMGQPAHVQEAQNVQNVQKP |
|
NCBI Accession
|
YP_010084347.1
|
|
Location
|
292-1065 |
|
Protein Name
|
V1 |
|
Coding Region
|
ATGTCGAAGCGACCAGCAGATATTGTCATTTCCACACCCGCCTCGAAGGTACGACGCCGTCTCAACTTCGAGAGCCCTTACAACAGCCGTGCTGCTGCCCCCACTGTCCTCGTCACAAACAAAAGGAGAACATGGGTCAACCGGCCCATGTACAGGAAGCCCAGAATGTACAGAATGTACAGAAGCCCTGATGTCCCCCGTGGGTGTGAAGGCCCATGTAAGGTCCAATCTTATGAACAGCGTCATGATATAGCCCATGTAGGTAAGGTTATTTGTGTCTCCGATGTCACGCGTGGTAATGGGCTTACCCATCGTGTGGGTAAGAGGTTTTGTGTTAAGTCCGTTTATGTGTTGGGTAAGGTCTGGATGGATGAAAACATCAAGACTAAGAACCACACAAATACCGTCATGTTTTTTTTAGTTCGTGATAGGAAACCTTTTGGTTCTCCCCAGGATTTCGGTCAGGTGTTTAACATGTATGATAACGAGCCTAGTACTGCTACTGTGAAGAATGACAACAGAGATAGGTTTCAAGTCCTCCGTCGATTTCAAGCTACTGTGACTGGTGGTCAGTATGCAAGCAAGGAGCAAGCTCTAGTGAGGAAGTTTATGAAGATTAACAACCATGTGACTTACAATCATCAGGAAGCTGCGAAGTATGAAAACCATACTGAGAATGCTTTGTTGTTGTATATGGCATGTACTCATGCCGCTAATCCAGTGTATGCGACTTTGAAAATTCGGATCTATTTTTATGATTCGATACAGAATTAA |
|
Protein Sequence
|
MSKRPADIVISTPASKVRRRLNFESPYNSRAAAPTVLVTNKRRTWVNRPMYRKPRMYRMYRSPDVPRGCEGPCKVQSYEQRHDIAHVGKVICVSDVTRGNGLTHRVGKRFCVKSVYVLGKVWMDENIKTKNHTNTVMFFLVRDRKPFGSPQDFGQVFNMYDNEPSTATVKNDNRDRFQVLRRFQATVTGGQYASKEQALVRKFMKINNHVTYNHQEAAKYENHTENALLLYMACTHAANPVYATLKIRIYFYDSIQN |
|
NCBI Accession
|
YP_010084348.1
|
|
Location
|
1062-1466 |
|
Protein Name
|
C3 |
|
Coding Region
|
ATGGATTCACGCACAGGGGAATACATCACTGCAGCTCAAGCCGAGAATGGCGCGTATATCTGGACGGTACCAAATCCCCTGTATTTCAAGATAACAGGCCACAAGAACAAACCAGCCTTCACGAACCACGACATCATCACAATACACATCAGGTTCAACCACAACCTGAGGAAAGCATTGGGGATACACCAGTGTTTTCTGGACTTCCGGATCTGGACTCGTTTACATCCTCAGACCTCGCGTTTCTTGCGCGTATTTAAATATCAATGTATGAAGTACTTAGATAATTTGGGTGTTATTAGTCTCAATAATGTAATTCGAGCAATTAGACATGTATTGCTGGATGTATTCGTAGGGACAATAGATGTACAAGATCGATATATAATAAAATTCAATCTTTATTAA |
|
Protein Sequence
|
MDSRTGEYITAAQAENGAYIWTVPNPLYFKITGHKNKPAFTNHDIITIHIRFNHNLRKALGIHQCFLDFRIWTRLHPQTSRFLRVFKYQCMKYLDNLGVISLNNVIRAIRHVLLDVFVGTIDVQDRYIIKFNLY |
|
NCBI Accession
|
YP_010084349.1
|
|
Location
|
1207-1614 |
|
Protein Name
|
C2 |
|
Coding Region
|
ATGCAGAATTCATCACCCTCACGGGGCCACTCTACTCAGGTACCAATCAAAGTCCAGCACCGCATCGCGAAGAAGAAGACCATTCGCAGGAGGCGAGTTGATCTCAACTGCGGCTGTACATACTATCTATCCATAAACTGCCACAACGATGGATTCACGCACAGGGGAATACATCACTGCAGCTCAAGCCGAGAATGGCGCGTATATCTGGACGGTACCAAATCCCCTGTATTTCAAGATAACAGGCCACAAGAACAAACCAGCCTTCACGAACCACGACATCATCACAATACACATCAGGTTCAACCACAACCTGAGGAAAGCATTGGGGATACACCAGTGTTTTCTGGACTTCCGGATCTGGACTCGTTTACATCCTCAGACCTCGCGTTTCTTGCGCGTATTTAA |
|
Protein Sequence
|
MQNSSPSRGHSTQVPIKVQHRIAKKKTIRRRRVDLNCGCTYYLSINCHNDGFTHRGIHHCSSSREWRVYLDGTKSPVFQDNRPQEQTSLHEPRHHHNTHQVQPQPEESIGDTPVFSGLPDLDSFTSSDLAFLARI |
|
NCBI Accession
|
YP_010084350.1
|
|
Location
|
1514-2602 |
|
Protein Name
|
C1 |
|
Coding Region
|
ATGGCACCACCGAGAAAATTCCAAATAAATGCCAGAAATTATTTCCTTACTTATCCACACTGCTCTCTTACTAAAGAGGAAGCACTTTCCCAATTACAAACCCTAGATACACCAACAAATAAACTATTCATCAAGATCTGCAGAGAACTGCACGAAGATGGGAGCCCTCATCTCCACGTGCTCCTCCAATTCGAGGGGAAATTCAGGTGCACGAATCAACGATTCTTCGACCTTACATCCCCTTCCAGGTCAGCACATTTCCATCCGAACATTCAGGGAGCTAAATCAAGCTCAGATGTCAAATCCTATTTGGATAAGGACGGAGACACCCTCGAATGGGGTGAGTTTCAGATCGATGGAAGATCTGCAAGAGGGGGACAACAATCAGCCAATGATGCTTACGCCAAGGCGCTTAACACTGGAAGTAAGTCGGAGGCTCTTAATGTAATTAGGGAATTAGCCCCTAAAGATTATATTTTACAATTTCATAATTTAAATGCCAATTTAGATAGGATTTTTGCACCTCCTTTAGAGGTTTTTGTTTGTCCTTTTTCTTCTTCTTCATTCGATCAAGTTCCAGAAGAACTTGAAGAGTGGGCTGCGGAGAATGTTGTGAGTGCCGCTGCGCGGCCATGGAGGCCCAAGAGTATTGTGGTAGAGGGCGATAGTAGGACAGGGAAGACGATGTGGGCCAGGTCTCTGGGACCACATAATTACTTATGTGGGCATCTGGACTTAAGTCCAAAGGTCTACAGTAATGATGCTTGGTACAACGTCATTGATGACGTCGACCCCCACTACCTAAAGCATTTTAAAGAATTCATGGGGGCCCAGAGAGACTGGCAAAGCAACACAAAGTACGGGAAGCCCATTCAAATTAAAGGAGGTATTCCCACTATCTTCCTCTGCAATCCTGGTCCCAACTCCAGCTATAAAGAATATCTGGACGAGGAGAAGAATGCTGCACTCAAAGACTGGGCATTAAAGAATGCAGAATTCATCACCCTCACGGGGCCACTCTACTCAGGTACCAATCAAAGTCCAGCACCGCATCGCGAAGAAGAAGACCATTCGCAGGAGGCGAGTTGA |
|
Protein Sequence
|
MAPPRKFQINARNYFLTYPHCSLTKEEALSQLQTLDTPTNKLFIKICRELHEDGSPHLHVLLQFEGKFRCTNQRFFDLTSPSRSAHFHPNIQGAKSSSDVKSYLDKDGDTLEWGEFQIDGRSARGGQQSANDAYAKALNTGSKSEALNVIRELAPKDYILQFHNLNANLDRIFAPPLEVFVCPFSSSSFDQVPEELEEWAAENVVSAAARPWRPKSIVVEGDSRTGKTMWARSLGPHNYLCGHLDLSPKVYSNDAWYNVIDDVDPHYLKHFKEFMGAQRDWQSNTKYGKPIQIKGGIPTIFLCNPGPNSSYKEYLDEEKNAALKDWALKNAEFITLTGPLYSGTNQSPAPHREEEDHSQEAS |
|
NCBI Accession
|
YP_010084351.1
|
|
Location
|
2155-2445 |
|
Protein Name
|
C4 |
|
Coding Region
|
ATGGGAGCCCTCATCTCCACGTGCTCCTCCAATTCGAGGGGAAATTCAGGTGCACGAATCAACGATTCTTCGACCTTACATCCCCTTCCAGGTCAGCACATTTCCATCCGAACATTCAGGGAGCTAAATCAAGCTCAGATGTCAAATCCTATTTGGATAAGGACGGAGACACCCTCGAATGGGGTGAGTTTCAGATCGATGGAAGATCTGCAAGAGGGGGACAACAATCAGCCAATGATGCTTACGCCAAGGCGCTTAACACTGGAAGTAAGTCGGAGGCTCTTAATGTAA |
|
Protein Sequence
|
MGALISTCSSNSRGNSGARINDSSTLHPLPGQHISIRTFRELNQAQMSNPIWIRTETPSNGVSFRSMEDLQEGDNNQPMMLTPRRLTLEVSRRLLM |