Tomato leaf curl Nigeria virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_000883635.1 |
| Isolate |
Nigeria |
| Release date |
2015/2/22 |
| Submitter |
Kon,T., Rojas,M.R., Gilbertson,R.L. |
| Host |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
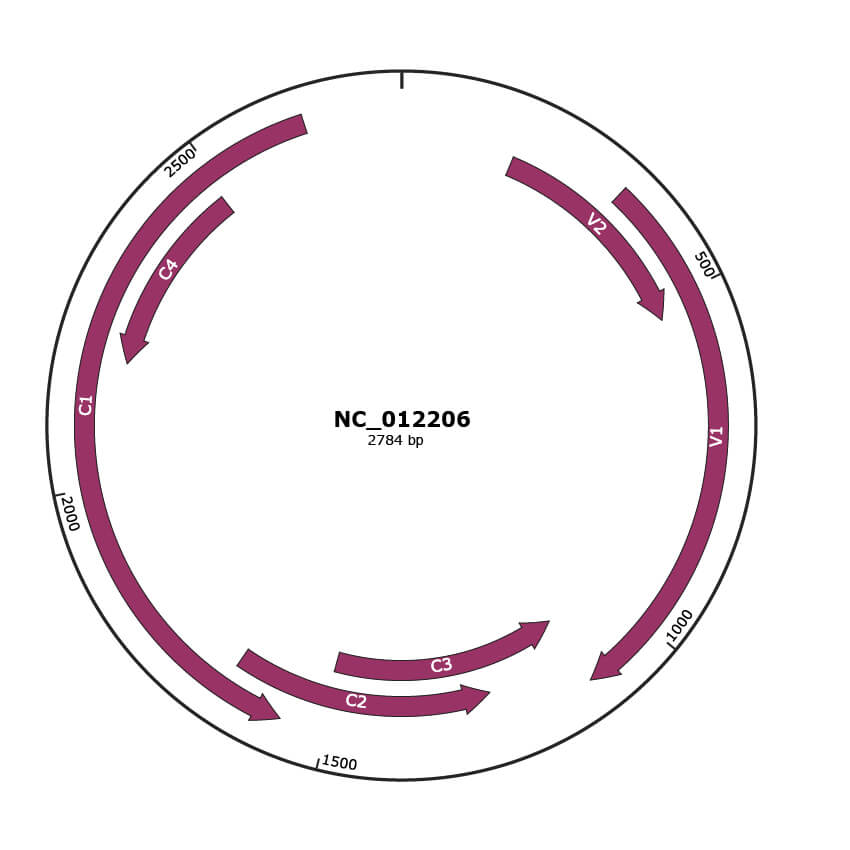
JBrowse
Genome
ACCGGTGGGCGCGAAAAAAAAAAAAGTGGTCCCCTTACACGCTCGAAAGCAAAAGTAAAGAAATCAGTGGTCCCCGTCCACTAATAAATGTCAGCCAATCAGAATGAAGCCTGAAAGCTTTCTTATTTAGATTTTGTTTTTATATACTTCCTCGCCAAGTAGTTATTATTGCAACATGTGGGATCCATTATTGAACGAGTTCCCAGACTCGGTTCATGGTTTTCGTTGTATGCTGGGTATAAAATATCTACAGCTTTTAGAAGAGGAGTACGAGCCCAATACTTTGGGCCACGATTTAATTAGAGATCTCATATCTGTCATTCGGGCTAAGAATTATGTCGAAGCGACCCGGCGATATAATAATTTCCACGCCCGTCTCGAAGGTGCGTCGTCGTCTGAACTTCGACAGCCCCTACACCAGCCGTGCTGCTGTCCCCACTGTCCGAGGCATAAGCAAGCGTCGTTCGTGGACTTATCGGCCCATGTATCGAAAGCCCAGAATGTACCGGATGTTCAGAACCCCTGACATCCCTCGTGGATGTGAAGGCCCATGTAAGGTCCAGTCGTATGAGCAGAGAGATGATGTCAAGCACGTGGGTATAGTTCGATGTGTTAGTGATGTGACCCGTGGGTCCGGTCTGACTCATAGAGTAGGGAAGAGATTTTGCATTAAGTCTATTTATATATTAGGTAAAGTTTGGATGGACGAAAACATCAAGAAGCAGAATCATACTAACAATGTTATGTTTTTCTTAGTTCGTGATCGTAGGCCTTATGGCAGCCCAAGTGATTTTGGACAGATTTTTAACATGTTTGACAACGAGCCCAGTACAGCCACAATCAAGAATGATCTCAGAGACCGTTATCAAGTGCTGCGTAAATTCAGTGCTACTGTTATTGGTGGTCCCTCTGGATGCAAGGAACAGGCTTTAGTGAAGAGATTTTTTAAAGTAAACAATCATGTCGTTTATAATCATCAGGAGGAGGCTAAATATGCCAACCATACTGAGAATGCTTTGTTGTTGTATATGGCTTGTACTCATGCCTCTAATCCAGTGTATGCTACTCTGAAAATACGCATCTATTTCTACGATGCAGTTACGAATTAATAAATATTAAATTTTATTTCATGTGTTTCGACAACGTCGATTGTATTTACAAGAACGTTATACAGTACATGATCAACAGCTCTAATAATTGTATTAATTGAAATTACACCCAAATTATCTAAATACTTTAACACTTGAACCCTAAATACCCTTAAGAAACGACCAGTCTGAGGGCGTAAGCTCGTCCAGACTTTGAAGTTCAGAAAACACTTGTGAATCCCCAACGCCTTCCGCAGGTTGTGGTTGAACCTGATTTGTACTGTGATTATGTCGTGTTGGTAGTTGAACGGTCTCTCGTCGTGGTTGGTTATCTTGAAATACAGGGGATTTTGTATCTCCCAGATAAAAACGCCATTCCGAGCTTGATGCGCAGTGATGAGTTCCCCTGTGCGTGAATCCATGGTTACTGCAGTTAATATGTATGAAGTACGAGCACCCGCACTCTAAGTCCACTCTCTTACGCCTCACTACTTTCTTCTTCGCGATGCGGTGCTGGACTTTGATGGGCACTTGAGTAGAGTGGCTCGTTGAGGGTGACGAAGGTCGCATTTTTTATAGCCCAGGCTTTTAGTGATGCATTCTTTTCCTCGTCTAGATACTCTTTATATGATGATGTTGGACCTGGATTGCAGAGGAAGATAGTGGGAATTCCACCTTTAATTTGAATGGGCTTCCCGTACTTGGTGTTGCTTTGCCAGTCTCTTTGGGCCCCCATAAATTCTTTGAAGTGTTTGAGGTAATGGGGATCGACGTCATCAATGACGTTATACCAAGCATCATTTGAATACACCTTTGGGCTAAGATCAAGATGCCCACACAAGTAATTGTGTGGACCTAATGACCTAGCCCACATCGTCTTGCCGGTACGACTATCACCCTCAATAACAATACTATTCGGTCTCCATGGCCGCGCAGCGGCATCGCTCACATTCTCAGAGACCCACTCTTCAAGTTCTTCCGGAACTTGATTAAAAGAAGAACATAAAAAAGGAGAAACATAAGGAGCCGGAGGCTCCTGAAAAATTCTATCTAAATTATTATTTAAATTATGAAATTGTAATACAAAATCTTTGGGAGCTAATTCCCGTATAACCCTAAGAGCCTCTGCCTTACTTCCTGCGTTAAGCGCTGCGGCGTAAGCGTCATTGGCTGTCTGTTGCCCTCCTCTTGCAGATCTCCCATCGATCTGGAACTCTCCCCATTCGAGTGTATCTCCATCCTTGTCGATGTAGGACTTGACGTCGGAGCTGGATTTAGCTCCCTGTATGTTTGGATGGAAATGTGCTGACCTGGTTGGGGACACCAGGTCGAAGAATCTCTGATTTTGGCAGTTGTATTTGCCTTCGAACTGCAGAAGCACGTGAAGATGAGGCTGGCCATCCTCGTGAAGTTCTCTGCAGATCTTGATATATTTTTTATTCGTTGGGGTTTCTAGTTTTAGAAGTTGCTCTAGGGCTTCTTCTTTAGAAATAGAGCATTTTGGGAAAGTGAGGAAGTAGTTTTTGGAATTTATTCTAAATTTCTTTGGAGGAGCCATATGGTCAACTAGCACCAATTGACTGCCCTGGATACTTCTCCCCTGTTAATTGGGGTTCTATATATACTTAGCACCAAATGGCATAATGGTAATACTCCCAAAAAATTTGAACCCCCAAAGCGCCCACCGAATAATATT
Gene Information
|
NCBI Accession
|
YP_002643045.1
|
|
Location
|
176-526 |
|
Gene Name
|
V2 |
|
Protein Name
|
pre-coat protein |
|
Coding Region
|
ATGTGGGATCCATTATTGAACGAGTTCCCAGACTCGGTTCATGGTTTTCGTTGTATGCTGGGTATAAAATATCTACAGCTTTTAGAAGAGGAGTACGAGCCCAATACTTTGGGCCACGATTTAATTAGAGATCTCATATCTGTCATTCGGGCTAAGAATTATGTCGAAGCGACCCGGCGATATAATAATTTCCACGCCCGTCTCGAAGGTGCGTCGTCGTCTGAACTTCGACAGCCCCTACACCAGCCGTGCTGCTGTCCCCACTGTCCGAGGCATAAGCAAGCGTCGTTCGTGGACTTATCGGCCCATGTATCGAAAGCCCAGAATGTACCGGATGTTCAGAACCCCTGA |
|
Protein Sequence
|
MWDPLLNEFPDSVHGFRCMLGIKYLQLLEEEYEPNTLGHDLIRDLISVIRAKNYVEATRRYNNFHARLEGASSSELRQPLHQPCCCPHCPRHKQASFVDLSAHVSKAQNVPDVQNP |
|
NCBI Accession
|
YP_002643046.1
|
|
Location
|
336-1109 |
|
Gene Name
|
V1 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGTCGAAGCGACCCGGCGATATAATAATTTCCACGCCCGTCTCGAAGGTGCGTCGTCGTCTGAACTTCGACAGCCCCTACACCAGCCGTGCTGCTGTCCCCACTGTCCGAGGCATAAGCAAGCGTCGTTCGTGGACTTATCGGCCCATGTATCGAAAGCCCAGAATGTACCGGATGTTCAGAACCCCTGACATCCCTCGTGGATGTGAAGGCCCATGTAAGGTCCAGTCGTATGAGCAGAGAGATGATGTCAAGCACGTGGGTATAGTTCGATGTGTTAGTGATGTGACCCGTGGGTCCGGTCTGACTCATAGAGTAGGGAAGAGATTTTGCATTAAGTCTATTTATATATTAGGTAAAGTTTGGATGGACGAAAACATCAAGAAGCAGAATCATACTAACAATGTTATGTTTTTCTTAGTTCGTGATCGTAGGCCTTATGGCAGCCCAAGTGATTTTGGACAGATTTTTAACATGTTTGACAACGAGCCCAGTACAGCCACAATCAAGAATGATCTCAGAGACCGTTATCAAGTGCTGCGTAAATTCAGTGCTACTGTTATTGGTGGTCCCTCTGGATGCAAGGAACAGGCTTTAGTGAAGAGATTTTTTAAAGTAAACAATCATGTCGTTTATAATCATCAGGAGGAGGCTAAATATGCCAACCATACTGAGAATGCTTTGTTGTTGTATATGGCTTGTACTCATGCCTCTAATCCAGTGTATGCTACTCTGAAAATACGCATCTATTTCTACGATGCAGTTACGAATTAA |
|
Protein Sequence
|
MSKRPGDIIISTPVSKVRRRLNFDSPYTSRAAVPTVRGISKRRSWTYRPMYRKPRMYRMFRTPDIPRGCEGPCKVQSYEQRDDVKHVGIVRCVSDVTRGSGLTHRVGKRFCIKSIYILGKVWMDENIKKQNHTNNVMFFLVRDRRPYGSPSDFGQIFNMFDNEPSTATIKNDLRDRYQVLRKFSATVIGGPSGCKEQALVKRFFKVNNHVVYNHQEEAKYANHTENALLLYMACTHASNPVYATLKIRIYFYDAVTN |
|
NCBI Accession
|
YP_002643047.1
|
|
Location
|
1106-1510 |
|
Gene Name
|
C3 |
|
Protein Name
|
REn |
|
Coding Region
|
ATGGATTCACGCACAGGGGAACTCATCACTGCGCATCAAGCTCGGAATGGCGTTTTTATCTGGGAGATACAAAATCCCCTGTATTTCAAGATAACCAACCACGACGAGAGACCGTTCAACTACCAACACGACATAATCACAGTACAAATCAGGTTCAACCACAACCTGCGGAAGGCGTTGGGGATTCACAAGTGTTTTCTGAACTTCAAAGTCTGGACGAGCTTACGCCCTCAGACTGGTCGTTTCTTAAGGGTATTTAGGGTTCAAGTGTTAAAGTATTTAGATAATTTGGGTGTAATTTCAATTAATACAATTATTAGAGCTGTTGATCATGTACTGTATAACGTTCTTGTAAATACAATCGACGTTGTCGAAACACATGAAATAAAATTTAATATTTATTAA |
|
Protein Sequence
|
MDSRTGELITAHQARNGVFIWEIQNPLYFKITNHDERPFNYQHDIITVQIRFNHNLRKALGIHKCFLNFKVWTSLRPQTGRFLRVFRVQVLKYLDNLGVISINTIIRAVDHVLYNVLVNTIDVVETHEIKFNIY |
|
NCBI Accession
|
YP_002643048.1
|
|
Location
|
1251-1658 |
|
Gene Name
|
C2 |
|
Protein Name
|
TrAP |
|
Coding Region
|
ATGCGACCTTCGTCACCCTCAACGAGCCACTCTACTCAAGTGCCCATCAAAGTCCAGCACCGCATCGCGAAGAAGAAAGTAGTGAGGCGTAAGAGAGTGGACTTAGAGTGCGGGTGCTCGTACTTCATACATATTAACTGCAGTAACCATGGATTCACGCACAGGGGAACTCATCACTGCGCATCAAGCTCGGAATGGCGTTTTTATCTGGGAGATACAAAATCCCCTGTATTTCAAGATAACCAACCACGACGAGAGACCGTTCAACTACCAACACGACATAATCACAGTACAAATCAGGTTCAACCACAACCTGCGGAAGGCGTTGGGGATTCACAAGTGTTTTCTGAACTTCAAAGTCTGGACGAGCTTACGCCCTCAGACTGGTCGTTTCTTAAGGGTATTTAG |
|
Protein Sequence
|
MRPSSPSTSHSTQVPIKVQHRIAKKKVVRRKRVDLECGCSYFIHINCSNHGFTHRGTHHCASSSEWRFYLGDTKSPVFQDNQPRRETVQLPTRHNHSTNQVQPQPAEGVGDSQVFSELQSLDELTPSDWSFLKGI |
|
NCBI Accession
|
YP_002643049.1
|
|
Location
|
1567-2646 |
|
Gene Name
|
C1 |
|
Protein Name
|
replication-associated protein |
|
Coding Region
|
ATGGCTCCTCCAAAGAAATTTAGAATAAATTCCAAAAACTACTTCCTCACTTTCCCAAAATGCTCTATTTCTAAAGAAGAAGCCCTAGAGCAACTTCTAAAACTAGAAACCCCAACGAATAAAAAATATATCAAGATCTGCAGAGAACTTCACGAGGATGGCCAGCCTCATCTTCACGTGCTTCTGCAGTTCGAAGGCAAATACAACTGCCAAAATCAGAGATTCTTCGACCTGGTGTCCCCAACCAGGTCAGCACATTTCCATCCAAACATACAGGGAGCTAAATCCAGCTCCGACGTCAAGTCCTACATCGACAAGGATGGAGATACACTCGAATGGGGAGAGTTCCAGATCGATGGGAGATCTGCAAGAGGAGGGCAACAGACAGCCAATGACGCTTACGCCGCAGCGCTTAACGCAGGAAGTAAGGCAGAGGCTCTTAGGGTTATACGGGAATTAGCTCCCAAAGATTTTGTATTACAATTTCATAATTTAAATAATAATTTAGATAGAATTTTTCAGGAGCCTCCGGCTCCTTATGTTTCTCCTTTTTTATGTTCTTCTTTTAATCAAGTTCCGGAAGAACTTGAAGAGTGGGTCTCTGAGAATGTGAGCGATGCCGCTGCGCGGCCATGGAGACCGAATAGTATTGTTATTGAGGGTGATAGTCGTACCGGCAAGACGATGTGGGCTAGGTCATTAGGTCCACACAATTACTTGTGTGGGCATCTTGATCTTAGCCCAAAGGTGTATTCAAATGATGCTTGGTATAACGTCATTGATGACGTCGATCCCCATTACCTCAAACACTTCAAAGAATTTATGGGGGCCCAAAGAGACTGGCAAAGCAACACCAAGTACGGGAAGCCCATTCAAATTAAAGGTGGAATTCCCACTATCTTCCTCTGCAATCCAGGTCCAACATCATCATATAAAGAGTATCTAGACGAGGAAAAGAATGCATCACTAAAAGCCTGGGCTATAAAAAATGCGACCTTCGTCACCCTCAACGAGCCACTCTACTCAAGTGCCCATCAAAGTCCAGCACCGCATCGCGAAGAAGAAAGTAGTGAGGCGTAA |
|
Protein Sequence
|
MAPPKKFRINSKNYFLTFPKCSISKEEALEQLLKLETPTNKKYIKICRELHEDGQPHLHVLLQFEGKYNCQNQRFFDLVSPTRSAHFHPNIQGAKSSSDVKSYIDKDGDTLEWGEFQIDGRSARGGQQTANDAYAAALNAGSKAEALRVIRELAPKDFVLQFHNLNNNLDRIFQEPPAPYVSPFLCSSFNQVPEELEEWVSENVSDAAARPWRPNSIVIEGDSRTGKTMWARSLGPHNYLCGHLDLSPKVYSNDAWYNVIDDVDPHYLKHFKEFMGAQRDWQSNTKYGKPIQIKGGIPTIFLCNPGPTSSYKEYLDEEKNASLKAWAIKNATFVTLNEPLYSSAHQSPAPHREEESSEA |
|
NCBI Accession
|
YP_002643050.1
|
|
Location
|
2187-2489 |
|
Gene Name
|
C4 |
|
Protein Name
|
C4 protein |
|
Coding Region
|
ATGGCCAGCCTCATCTTCACGTGCTTCTGCAGTTCGAAGGCAAATACAACTGCCAAAATCAGAGATTCTTCGACCTGGTGTCCCCAACCAGGTCAGCACATTTCCATCCAAACATACAGGGAGCTAAATCCAGCTCCGACGTCAAGTCCTACATCGACAAGGATGGAGATACACTCGAATGGGGAGAGTTCCAGATCGATGGGAGATCTGCAAGAGGAGGGCAACAGACAGCCAATGACGCTTACGCCGCAGCGCTTAACGCAGGAAGTAAGGCAGAGGCTCTTAGGGTTATACGGGAATTAG |
|
Protein Sequence
|
MASLIFTCFCSSKANTTAKIRDSSTWCPQPGQHISIQTYRELNPAPTSSPTSTRMEIHSNGESSRSMGDLQEEGNRQPMTLTPQRLTQEVRQRLLGLYGN |