Tomato leaf curl New Delhi virus 2
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_002824165.1 |
| Isolate |
India |
| Release date |
2018/8/25 |
| Submitter |
Chaudhary,A., Kumar,R., Mukherjee,S.K. |
| Host |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
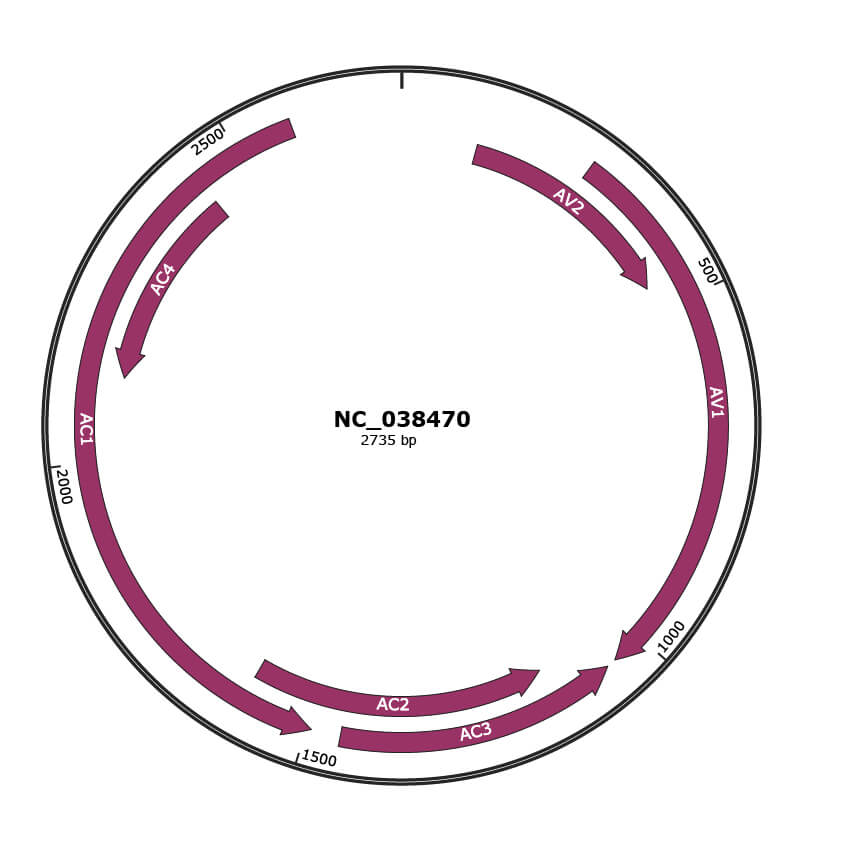
JBrowse
Genome
ACCGGATGGCCGCGCGTTTTTTTGTGGCCCCTCGACCAATCACATCTCGCGCTCAAAGCTTAAATAACTCTCCCGCCTGTTATAAATACTTACGCTCTAAGTATCCGCTTGCAAAATGTGGGATCCACTGGTTAACGAGTTCCCCGAGACGGTTCACGGGTTTCGGTGCATGCTTGCCATCAAATATCTTCAGCTACTCTCTCAGGAATACTCTCCCGATACGGTAGGTTACGATCTAATACGCGATTTGATCTGTATTTTGCGTTCCAGGAATTATGTCGAAGCGTCCTGCAGATATCGTCATTTCTACCCCCGCGTCGAAGGTGCGTCGGCGTCTGAACTTCGACAGCCCGTACGCGACCCGTGTGGCTGTCCCCACTGTCCGCGTCACAAAATCGCGAATGTGGGCGAACAGGCCCATGAATCGGAAGCCCAGAATTTACAGGATGTACAGAAGCCCTGATGTTCCAAAGGGCTGTGAGGGTCCATGTAAGGTACAGTCTTTCGAGTCCAGACACGATGTAGTGCATATAGGTAAGGTAATGTGCATCAGTGATGTCACCCGCGGTACTGGGCTGACCCATCGAGTAGGGAAGCGTTTCTGCGTGAAATCTGTTTATGTTTTGGGTAAGATATGGATGGATGAAAACATCAAGTCCAAAAATCATACTAACAATGTCATGTTCTTTCTCGCCCGTGATCGACGGCCCACTGACAAGCCTCAGGATTTTGGAGAGGTGTTCAACATGTTTGACAACGAGCCTAGCACTGCCACTGTGAAGAATATGCATCGAGACCGCTACCAGGTATTGCGTAAGTGGTATGCAACCGTCACGGGTGGACAGTATGGTGCAAAGGAACAGGCCCTTGTCAAGAAGTTTGTTAGGGTTAACAATTATGTAGTTTATAACCAGCAGGAGGCTGGTAAATATGAGAATCACACCGAGAATGCTCTGATGTTGTATATGGCATGTACCCATGCCTCTAATCCCGTGTACGCGACTCTTAAGATTAGGATTTACTTCTACGATTCTGTAACGAACTGAAATTAATAAATGTTTAATTTTTATTTCTGATCAGGTCTACATACATAGTTTGCTCTAATTTATTCCATAATACATGATTTACAGCCCTAATAATTGCATTAATTGATATTACACCGATATTGTTGAGATACTTGAGGACTTGGGTCTTGAATACCCTTAAGAAAAGACCAGTCGGAGGGTGTAAGGTCGTCCAGATTCGGTAGGTCAGAAAACATTTGTGCACTCCCAGAGCTCTCCGGAGGTTGTAGTTGAATTGGATCCTGATCGTGAGTATGTCCATGTTCGTCGTGAATGGACGGACGTCGTGGCTGAGGAGCTTGAAATAGAGGGGATTTGGAATCTCCCAGATATAGGCGCCATTCCATGCTTGAGCTGCAGTGATGGGTTCCCCTGTGCGTGAATCCATGATTGTGGCAGTTGATGGACAGATAATAAGAACACCCGCATTCAAGATCTACTCTCCTCCTCCGGTTGCGCCTCTTCGCTTCCCTGTGCTGTACTTTGATTGGAACCTGAGTACAGTGGTCCTTCGAGGGTGACGAAGATCGCATTTTTGACGGCCCAGTTCTTTAATGCGGTGTTCTTTTCCTCGTCGAGGAATTCCTTATAACTGCTGTTGGGACCAGGATTGCACAGGAAGATTGTCGGTATCCCGCCTTTAATTTGAACTGGCTTCCCGTATTTTGTGTTGGACTGCCAGTCTCTTTGGGCCCCCATGAACTCTTTAAAGTGTTTGAGGAAGTGCGGGTCAACGTCATCAATGACGTTATACCAAGCGTCGTTACTGTATACTTTGGGACTTAGGTCCAGGTGTCCACACAAATAGTTGTGTGGTCCCAGTGACCTAGCCCACATCGTCTTCCCCGTTCGACTGTCTCCCTCAATTACTATACTCTGAGGTCTAAGGGGCCGCGCAGCGGGATCGACAACGTTCTCGGACGCCCAATCTTCAAGTTCTTCTGGAACTTGATCGAAAGAAGATGAAGAAAAAGGAGAAATATAGGGAGCCGGTGGCTCCTGAAAGATTCTGTCTAGATTTGCATTTAAATTATGAAATTGTAGTACAAAATCTTTAGGAGCTAGTTCCCTAATGACTCTAAGAGCCTCTGACTTACTGCCTGCGTTAAGTGCTGCGGCGTAAGCGTCGTTGGCTGTCTGTTGTCCTCCTCTTGCTGATCTTCCATCGATCTGAAACTCTCCCCACTCGAGAGTGTCCCCGTCCTTGTCGATGTAGGACTTGACATCGGAGCTTGATTTAGCTCCCTGAATGTTCGGATGGAAATGTGCTGACCTGCTTGGGGAGACCAGGTCGAAGAATCGCTGATTCTGGCACTTGTATTTCCCCTCGAACTGGATGAGCACGTGCAGATGAGGTTCCCCATTCTCATGTAATTCTCGGCAGATTTTAATATATTTTTTTGAAGTTGGGGTTTGGAAATTCTGGATTTGGGAAAGTGCTTCCTCTTTGGTTAGTGAGCACTTAGGATAAGTGAGGAAATAATTTTTGGAGTTTATAACGAAGCGCTTTGGAGGCATGTTGACCAAAGTTGAGACCCAATTGACCGCTCTCGCAACTTATCCCTGGTATATCGGGTCTCAATATATAGTGAGACCCAAATGGCACAATTGTAATTTCTCCAATAAATTCAAAATCCTCACGCTCCAAAAAGCGGCCATCCGTATAATATT
Gene Information
|
NCBI Accession
|
YP_009506526.1
|
|
Location
|
116-463 |
|
Gene Name
|
AV2 |
|
Protein Name
|
AV2 |
|
Coding Region
|
ATGTGGGATCCACTGGTTAACGAGTTCCCCGAGACGGTTCACGGGTTTCGGTGCATGCTTGCCATCAAATATCTTCAGCTACTCTCTCAGGAATACTCTCCCGATACGGTAGGTTACGATCTAATACGCGATTTGATCTGTATTTTGCGTTCCAGGAATTATGTCGAAGCGTCCTGCAGATATCGTCATTTCTACCCCCGCGTCGAAGGTGCGTCGGCGTCTGAACTTCGACAGCCCGTACGCGACCCGTGTGGCTGTCCCCACTGTCCGCGTCACAAAATCGCGAATGTGGGCGAACAGGCCCATGAATCGGAAGCCCAGAATTTACAGGATGTACAGAAGCCCTGA |
|
Protein Sequence
|
MWDPLVNEFPETVHGFRCMLAIKYLQLLSQEYSPDTVGYDLIRDLICILRSRNYVEASCRYRHFYPRVEGASASELRQPVRDPCGCPHCPRHKIANVGEQAHESEAQNLQDVQKP |
|
NCBI Accession
|
YP_009506527.1
|
|
Location
|
276-1046 |
|
Gene Name
|
AV1 |
|
Protein Name
|
AV1 |
|
Coding Region
|
ATGTCGAAGCGTCCTGCAGATATCGTCATTTCTACCCCCGCGTCGAAGGTGCGTCGGCGTCTGAACTTCGACAGCCCGTACGCGACCCGTGTGGCTGTCCCCACTGTCCGCGTCACAAAATCGCGAATGTGGGCGAACAGGCCCATGAATCGGAAGCCCAGAATTTACAGGATGTACAGAAGCCCTGATGTTCCAAAGGGCTGTGAGGGTCCATGTAAGGTACAGTCTTTCGAGTCCAGACACGATGTAGTGCATATAGGTAAGGTAATGTGCATCAGTGATGTCACCCGCGGTACTGGGCTGACCCATCGAGTAGGGAAGCGTTTCTGCGTGAAATCTGTTTATGTTTTGGGTAAGATATGGATGGATGAAAACATCAAGTCCAAAAATCATACTAACAATGTCATGTTCTTTCTCGCCCGTGATCGACGGCCCACTGACAAGCCTCAGGATTTTGGAGAGGTGTTCAACATGTTTGACAACGAGCCTAGCACTGCCACTGTGAAGAATATGCATCGAGACCGCTACCAGGTATTGCGTAAGTGGTATGCAACCGTCACGGGTGGACAGTATGGTGCAAAGGAACAGGCCCTTGTCAAGAAGTTTGTTAGGGTTAACAATTATGTAGTTTATAACCAGCAGGAGGCTGGTAAATATGAGAATCACACCGAGAATGCTCTGATGTTGTATATGGCATGTACCCATGCCTCTAATCCCGTGTACGCGACTCTTAAGATTAGGATTTACTTCTACGATTCTGTAACGAACTGA |
|
Protein Sequence
|
MSKRPADIVISTPASKVRRRLNFDSPYATRVAVPTVRVTKSRMWANRPMNRKPRIYRMYRSPDVPKGCEGPCKVQSFESRHDVVHIGKVMCISDVTRGTGLTHRVGKRFCVKSVYVLGKIWMDENIKSKNHTNNVMFFLARDRRPTDKPQDFGEVFNMFDNEPSTATVKNMHRDRYQVLRKWYATVTGGQYGAKEQALVKKFVRVNNYVVYNQQEAGKYENHTENALMLYMACTHASNPVYATLKIRIYFYDSVTN |
|
NCBI Accession
|
YP_009506528.1
|
|
Location
|
1060-1452 |
|
Gene Name
|
AC3 |
|
Protein Name
|
AC3 |
|
Coding Region
|
ATGGATTCACGCACAGGGGAACCCATCACTGCAGCTCAAGCATGGAATGGCGCCTATATCTGGGAGATTCCAAATCCCCTCTATTTCAAGCTCCTCAGCCACGACGTCCGTCCATTCACGACGAACATGGACATACTCACGATCAGGATCCAATTCAACTACAACCTCCGGAGAGCTCTGGGAGTGCACAAATGTTTTCTGACCTACCGAATCTGGACGACCTTACACCCTCCGACTGGTCTTTTCTTAAGGGTATTCAAGACCCAAGTCCTCAAGTATCTCAACAATATCGGTGTAATATCAATTAATGCAATTATTAGGGCTGTAAATCATGTATTATGGAATAAATTAGAGCAAACTATGTATGTAGACCTGATCAGAAATAAAAATTAA |
|
Protein Sequence
|
MDSRTGEPITAAQAWNGAYIWEIPNPLYFKLLSHDVRPFTTNMDILTIRIQFNYNLRRALGVHKCFLTYRIWTTLHPPTGLFLRVFKTQVLKYLNNIGVISINAIIRAVNHVLWNKLEQTMYVDLIRNKN |
|
NCBI Accession
|
YP_009506529.1
|
|
Location
|
1145-1597 |
|
Gene Name
|
AC2 |
|
Protein Name
|
AC2 |
|
Coding Region
|
ATGCGATCTTCGTCACCCTCGAAGGACCACTGTACTCAGGTTCCAATCAAAGTACAGCACAGGGAAGCGAAGAGGCGCAACCGGAGGAGGAGAGTAGATCTTGAATGCGGGTGTTCTTATTATCTGTCCATCAACTGCCACAATCATGGATTCACGCACAGGGGAACCCATCACTGCAGCTCAAGCATGGAATGGCGCCTATATCTGGGAGATTCCAAATCCCCTCTATTTCAAGCTCCTCAGCCACGACGTCCGTCCATTCACGACGAACATGGACATACTCACGATCAGGATCCAATTCAACTACAACCTCCGGAGAGCTCTGGGAGTGCACAAATGTTTTCTGACCTACCGAATCTGGACGACCTTACACCCTCCGACTGGTCTTTTCTTAAGGGTATTCAAGACCCAAGTCCTCAAGTATCTCAACAATATCGGTGTAATATCAATTAA |
|
Protein Sequence
|
MRSSSPSKDHCTQVPIKVQHREAKRRNRRRRVDLECGCSYYLSINCHNHGFTHRGTHHCSSSMEWRLYLGDSKSPLFQAPQPRRPSIHDEHGHTHDQDPIQLQPPESSGSAQMFSDLPNLDDLTPSDWSFLKGIQDPSPQVSQQYRCNIN |
|
NCBI Accession
|
YP_009506530.1
|
|
Location
|
1494-2582 |
|
Gene Name
|
AC1 |
|
Protein Name
|
AC1 |
|
Coding Region
|
ATGCCTCCAAAGCGCTTCGTTATAAACTCCAAAAATTATTTCCTCACTTATCCTAAGTGCTCACTAACCAAAGAGGAAGCACTTTCCCAAATCCAGAATTTCCAAACCCCAACTTCAAAAAAATATATTAAAATCTGCCGAGAATTACATGAGAATGGGGAACCTCATCTGCACGTGCTCATCCAGTTCGAGGGGAAATACAAGTGCCAGAATCAGCGATTCTTCGACCTGGTCTCCCCAAGCAGGTCAGCACATTTCCATCCGAACATTCAGGGAGCTAAATCAAGCTCCGATGTCAAGTCCTACATCGACAAGGACGGGGACACTCTCGAGTGGGGAGAGTTTCAGATCGATGGAAGATCAGCAAGAGGAGGACAACAGACAGCCAACGACGCTTACGCCGCAGCACTTAACGCAGGCAGTAAGTCAGAGGCTCTTAGAGTCATTAGGGAACTAGCTCCTAAAGATTTTGTACTACAATTTCATAATTTAAATGCAAATCTAGACAGAATCTTTCAGGAGCCACCGGCTCCCTATATTTCTCCTTTTTCTTCATCTTCTTTCGATCAAGTTCCAGAAGAACTTGAAGATTGGGCGTCCGAGAACGTTGTCGATCCCGCTGCGCGGCCCCTTAGACCTCAGAGTATAGTAATTGAGGGAGACAGTCGAACGGGGAAGACGATGTGGGCTAGGTCACTGGGACCACACAACTATTTGTGTGGACACCTGGACCTAAGTCCCAAAGTATACAGTAACGACGCTTGGTATAACGTCATTGATGACGTTGACCCGCACTTCCTCAAACACTTTAAAGAGTTCATGGGGGCCCAAAGAGACTGGCAGTCCAACACAAAATACGGGAAGCCAGTTCAAATTAAAGGCGGGATACCGACAATCTTCCTGTGCAATCCTGGTCCCAACAGCAGTTATAAGGAATTCCTCGACGAGGAAAAGAACACCGCATTAAAGAACTGGGCCGTCAAAAATGCGATCTTCGTCACCCTCGAAGGACCACTGTACTCAGGTTCCAATCAAAGTACAGCACAGGGAAGCGAAGAGGCGCAACCGGAGGAGGAGAGTAGATCTTGA |
|
Protein Sequence
|
MPPKRFVINSKNYFLTYPKCSLTKEEALSQIQNFQTPTSKKYIKICRELHENGEPHLHVLIQFEGKYKCQNQRFFDLVSPSRSAHFHPNIQGAKSSSDVKSYIDKDGDTLEWGEFQIDGRSARGGQQTANDAYAAALNAGSKSEALRVIRELAPKDFVLQFHNLNANLDRIFQEPPAPYISPFSSSSFDQVPEELEDWASENVVDPAARPLRPQSIVIEGDSRTGKTMWARSLGPHNYLCGHLDLSPKVYSNDAWYNVIDDVDPHFLKHFKEFMGAQRDWQSNTKYGKPVQIKGGIPTIFLCNPGPNSSYKEFLDEEKNTALKNWAVKNAIFVTLEGPLYSGSNQSTAQGSEEAQPEEESRS |
|
NCBI Accession
|
YP_009506531.1
|
|
Location
|
2126-2434 |
|
Gene Name
|
AC4 |
|
Protein Name
|
AC4 |
|
Coding Region
|
ATGAGAATGGGGAACCTCATCTGCACGTGCTCATCCAGTTCGAGGGGAAATACAAGTGCCAGAATCAGCGATTCTTCGACCTGGTCTCCCCAAGCAGGTCAGCACATTTCCATCCGAACATTCAGGGAGCTAAATCAAGCTCCGATGTCAAGTCCTACATCGACAAGGACGGGGACACTCTCGAGTGGGGAGAGTTTCAGATCGATGGAAGATCAGCAAGAGGAGGACAACAGACAGCCAACGACGCTTACGCCGCAGCACTTAACGCAGGCAGTAAGTCAGAGGCTCTTAGAGTCATTAGGGAACTAG |
|
Protein Sequence
|
MRMGNLICTCSSSSRGNTSARISDSSTWSPQAGQHISIRTFRELNQAPMSSPTSTRTGTLSSGESFRSMEDQQEEDNRQPTTLTPQHLTQAVSQRLLESLGN |