Blechum interveinal chlorosis virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_000897995.1 |
| Isolate |
Mexico |
| Release date |
2015/2/22 |
| Submitter |
Mauricio-Castillo,J.A., Banuelos-Hernandez,B., Patino-Rodriguez,O., Salazar-Gonzalez,J., Ambriz-Granados,S., Arguello-Astorga,G.R. |
| Host |
|
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
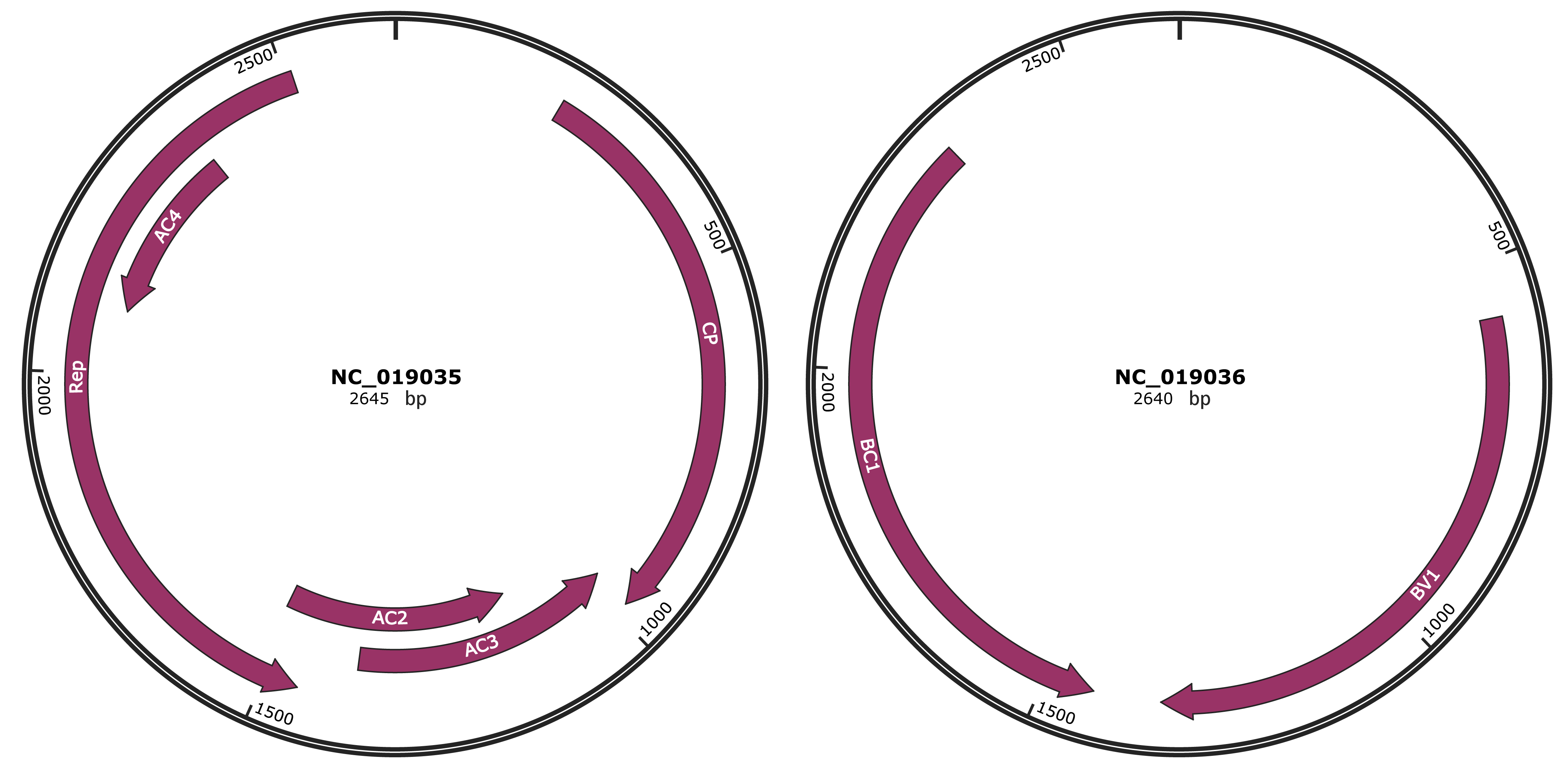
JBrowse
Genome
ACCGGATGGCCGCCCGTTTTTATCACCCGGTCCCACCTCATACCCGCCCCGCTCTCACACATGCTTTTGGGACCACTAATTTAATTTATGTTGGACCACTTAATTTAAATCCAGCCAATCAGCGGGCCCATTTAAAGCTTATTTATCAACAACTTGGTGTCCAAGTTTTACCGTTGTTCTATAAAGAGTAATGATTTAAAACAATATCTATTGTCTTTAATTCAAAATGCTTAAGCGGGATGCCCCATGGCGCTCAATTGCTGGGGCCTCTAAGGTTAGACGCTCCCTCAATTTTTCGCCTCGTGGAGGTATGGGTCCCAAATCTGATAAGGCATATGCATGGGTCAACAGGCCCATGTATAGGAAGCCCAGGATTTACAGGACGTTGAGAACCCCTGATGTTCCCAGAGGATGTGAAGGACCTTGTAAGGTTCAATCATATGAATCTCGCCATGATGTGTCTCATGTTGGGAAGGTTATTTGTATATCTGACGTCACACGTGGTAATGGTATTACTCATCGTGTTGGTAAACGTTTCTGTGTCAAGTCTGTGTATATTTTAGGTAAGGTTTGGATGGATGATACCATCAAACTGAGGAACCACACGAATAGTGTGATGTTCTGGTTAGTTAGGGATAGGAGACCATATGGTACGCCTATGGATTTTGGTCAGGTGTTTAATATGTTTGACAATGAGCCTAGTACTGCTACTGTGAAGAACGATCTACGTGATCGTTTTCAGGTGATGCACAAGTTTTCAACCAAGGTTACAGGAGGACAATATGCTGCCAATGAACAGTCACTTGTGAAGCGTTTCTGGAAGGTCAATACTCATGTTGTGTACAACCATCAAGAAGCTGCTAAGTACGAGAATCACACAGAGAATGCTCTGTTATTGTATATGGCATGTACACATGCCTCTAATCCTGTGTATGCTACATTGAAAATTCGGATCTATTTTTATGATTCGATTACGAATTAATAAAGTTTGAATTGTATTTCATGATTTTCAAGTACATGGTTTACATATGATTTGAGTGTTGCAAAACGAACAGCTCTTATTACATTATTAATTCCAATAACACCTAATTGATTTAAATACAACATAACTAAATGTTTAAATCTATTTAAATAATCCATCCCAGAAGCTCGAATCGAAGTCGTCCAGATTTGGAAATTGAAGTAGGCTTTGTGTAGATTCAGTTCCTTCCTCAGGTTGTGGTTGAACCGAATTTGGATGGAGTATATTCTGGTTGTTGTGTATGGTGGGTCTTCTACTTTGTGTATCATGAAAAATAGGGGATTTGGAACCTTCCAGATAAAAACGGAACTCTCTGCCTGACGTGCAGTGATGCTCTCCTCTGTGCGTGAATCCATAGTTGATGCAGTCGATGTGTTGGTATATAGAACAGCCACAATTGAAATCAATTCGTTTTCGACGAATTGCTCTCTTCTTAGCTATCCTGTGTTGTGGTTTGATAGAGGGGGGAGTTGAGGAAGATGAATTTTGCATTATGAAGTGTCCACGCTTTTAAAGCTGAATTTTCCTCTTTGTCTAGGAAATCTTTATAGCTAGACCCCTCTCCTGGATTGCAAAGCACGATTGATGGTATACCACCTTTAATTTGAACTGGCTTTCCGTATTTGCAATTTGATTGCCAGTCTCTTTGGGCCCCAATCAATTCTTTCCAGTGCTTTAACTTTAAATATTGTGGACTGACGTCATCAATGACGTTATATTCCACTTCGTTTGAATAAACCCTAGAATTGAAATCCAGGTGTCCACTTAAATAATTATGTGAGCCCAAAGAACGGGCCCACATTGTCTTGCCGGTTCTAGAATCACCTTCAACGATGATACTAATAGGTCTTTCCGGCCGCGCAGCGGAACCCCTCCCAAAATAATCATCAGCCCACTCTTGCATATCTTCTGGAACATGAGTGAATGATGATAGTTGAAATGGAGGAACCCATGGTTCCGGAGCCTTAGCAAATATTTTATCCAGATTACTGGACAAATTGTGAAATTGAAAAAGAAACTCTTTAGGGAGCTTCTCTTTTATAATCCTCATTGCATCCTCTTTTGACGATGCATTCAATGCCTCTGCTGCAGCATCATTAGCTGTATGTTGACCTCCTCTAGCAGTTCTGCCGTCGATCTGGAATTCTCCCCAGTCAATTGTATCTCCATCCTTGCTGATGTAGGACTTGACGTCGGAGCTGGATTTAGCTCCCTGAATGTTCGGATGGAAATGTGCTGACCTGACTGGGGATACCAAGTCGAACTGTCTGTGATTCGTGCAGTTGTATTTCCCCTCAAACTGGATAAGCACGTGCAGATGTGGTTCCCCATTTTCATGGAGTTCTCTACAGATCTTGATGTATTTTTTATTCACCGGAGTATGTAGATTCTTGAGTTGTTCCAATGCTGCTTCTTTTGGTAAATCACAGTGAGGATATGTGATGAAATAATTTTTGGCTTTTATTGAGAAAGAACCCTTTCGTGGCATTTTGGTAAATATGAGTGTTCCCCCAATTCAGAGCTCTCATAAAACTCTAGAGAATTGGGGGAACTGGGGGAAAATATATACTAAAACCTCCTATCCAGGATCTTGCAACACGTGTCGGCCATCCGTTATAATATT
ACCGGATGGCCGCGTTTTCCCCCCTCTCAGGCCCACCACTCTCTCCAGGGCCGCCCATCATTTAAAAGAATATTAGGCCCATTTAAATGGGCCTGATATTTTGAGCCCATCTGAGACCTGTTTTTGTTATCTTTTTTAAAAGGAGGGACCACAATAACACTATATTTAACTTTGTCCATTTAGAATGTTTCTGACATGCTTAGATATTAACGACGTAAACTTTAAATTGTGGTCCACAATAATAAAATAATTTTATTATTGTCATGTAAACTTTAATTCAAAATTTGTAAGCGGAGCGTCGTAATACTTTCATAGAGGGGACCACTTAGAAAATTGGTCTGATGACCAATTTTAAATATTGTATGGCCCACATATGCATTGGTTAACGTATTATATTTTGAGTTACATCACATATTGCATAAACCAATGAAATTTCCTCTTCACAGACTAGTTAACATATATTTCATACATTAATTTTCTATTTAAATATCATATTGATTTCATTGGTTACCACGTCTATATGCATTAGCCTCATTTTATTGTATTTTAATATTAATTAGTATAGTATTAACTATGTATTTTACTAGATATAGACGTGGTGGATCGTTAACCCATCGACGAGGTTATTCACGTTATACATTGTATAAACGACCTTTTTCTGTTCATCGTGTGGATGTGAAACGTCGACGAACCAGTTCTACTAAGTATCATGATGATGCAAAGATGTCACAGCAACGTATACATGAGGATCAGTTTGGTCCCGAATTTGTTCTGGGTCATAATACAGCTTTGTCTACATTCATTACATTTCCCAGTCTTGTTAAGAATGAACCTAATCGTTGTAGATCATATATTAAGTTAAAACGTTTACGTTTCAAAGGTACCGTGAAGATTGAACGTGTAATTGCTGATATTAATATGGATGGTCCTACTCAAAAGATTGAAGGAGTCTTCTCTATGGTTATTGTTGTTGATCGTAAACCACATCTTAGTCCAACTGGCTGTCTACATACATTTGATGAGTTATTTGGTGCTAGGATTCATAGCCATGGTAATCTAGCCATCGTTCCCGCATTGAAAGACCGTTTCTACATACGTCATATAATGAAACGTGTTTTATCTGTTGAGAAGGATACTTTGATGGTAGACTTGGAAGGAATTACATACTTATCTAATAGGCGTTTTAATTGTTGGTCTGCATTTAATGATCTTGATAGAGAATCATGCAATGGTGTTTATGCTAATATAAATAAGAATGCTTTATTAGTCTATTATTGTTGGATGTCAGATGCTTTGTCTAAAGCATCAACTTTTGTATCATTTGATCTTGAATATCTCGGTTGAATAATAAAATATTTTTATATTTTATCAGTAACTTCTTTTTGGTCTCAGATGAATGTTTATTATAACATAGATAAATATATGATAATATATTTATTTTAACTGTTTTGGATGTGAGGGAATACAATTGGTGTTTATACATTCTTGTACTGTTGATCTAACTATTTCGTTTAACTGGGACATAGACATTGTAATGTTGGATTGGGTTCTCTGAATTCCAATTTGTGAAACAGAGTCACCTGGGTCTAACATTGGCGTTCCTATTCTGTTCATTTCTCTATATGGATGTATCTCGTTTGCCACATCTGAACTGACATTGGAATGTGTTATACCTACTGCACTCCTTGTAGCCCAAGTTTCACCTGGATTTAACTCTATTGGGTTATGAAGTCCAAATCTTGCTGATGCAGTAGATTTAATCATTCTTCTTTCATATTTTCCATATCCAACATGGTGAAAATCAATATCCTTGTCTGTAAACTGTTTTGACAAAATTCTCACCGTTGGTGCACGGAAAGGGATATCAACAGAATGTTTTGCTGTTGACAGTTTTAATTTACCCTTGAATTTTGCAAAATGTGTACCTTGATGAACATTTGAGTCACATACTTTATAATACAGTTTCCATGGAATTGGATCCTTGAGTGAGAAAAATGAAGATGAGAAATAGTGGAGATCTATGTTACACCTAATTGGAAAAGTCCACGACGCCTGTAATGACTCATTGTCTGTCATTCTTTTATCATGAATCTCCACGATTACTGTTCCTGCTGCGTTAATAGGAACCTGCTGTCGATATTCTATAACGCAATGATCTATCTTCATACAGCTACGATTCAGCCTTGCAGTTAATTGAGCTGCAGTTGAAGGAAATTGCAAGATGATTTCTGTAAGGTCATGAGACAGTTGATACTCATCTCGATGAGACTCCACATAATTAAAAACACTTGGTGGTACGACTAATTTAGAATCCATATGGCCGCGCAGCGGGATGCTTAACTGATATTAATAGCGAAGGGGACTGTTTAACGGGATACTTAAGACTATCAGGTGGCTTATTAATTTTTTATATAAGAAGAAGAAGGGATTTGAGATATACTCTGGAGAGTAATATCATATATTGATCTGTTTATATAGCAATTAATTTGTATGGAGTGAGGGCAATTTGGTAAATATTGGTGTTCCCCCAAATCAGAGCTCTCATAAAACTCTAGAGAATTGGGGGAACTGGGGGAAAATATATACTAAAACCTCCTTACCAGGATCTTGCAACACGTGGCGGCCATCCGATATAATATT
Gene Information
|
NCBI Accession
|
YP_006905830.1
|
|
Location
|
227-982 |
|
Gene Name
|
CP |
|
Protein Name
|
capsid protein |
|
Coding Region
|
ATGCTTAAGCGGGATGCCCCATGGCGCTCAATTGCTGGGGCCTCTAAGGTTAGACGCTCCCTCAATTTTTCGCCTCGTGGAGGTATGGGTCCCAAATCTGATAAGGCATATGCATGGGTCAACAGGCCCATGTATAGGAAGCCCAGGATTTACAGGACGTTGAGAACCCCTGATGTTCCCAGAGGATGTGAAGGACCTTGTAAGGTTCAATCATATGAATCTCGCCATGATGTGTCTCATGTTGGGAAGGTTATTTGTATATCTGACGTCACACGTGGTAATGGTATTACTCATCGTGTTGGTAAACGTTTCTGTGTCAAGTCTGTGTATATTTTAGGTAAGGTTTGGATGGATGATACCATCAAACTGAGGAACCACACGAATAGTGTGATGTTCTGGTTAGTTAGGGATAGGAGACCATATGGTACGCCTATGGATTTTGGTCAGGTGTTTAATATGTTTGACAATGAGCCTAGTACTGCTACTGTGAAGAACGATCTACGTGATCGTTTTCAGGTGATGCACAAGTTTTCAACCAAGGTTACAGGAGGACAATATGCTGCCAATGAACAGTCACTTGTGAAGCGTTTCTGGAAGGTCAATACTCATGTTGTGTACAACCATCAAGAAGCTGCTAAGTACGAGAATCACACAGAGAATGCTCTGTTATTGTATATGGCATGTACACATGCCTCTAATCCTGTGTATGCTACATTGAAAATTCGGATCTATTTTTATGATTCGATTACGAATTAA |
|
Protein Sequence
|
MLKRDAPWRSIAGASKVRRSLNFSPRGGMGPKSDKAYAWVNRPMYRKPRIYRTLRTPDVPRGCEGPCKVQSYESRHDVSHVGKVICISDVTRGNGITHRVGKRFCVKSVYILGKVWMDDTIKLRNHTNSVMFWLVRDRRPYGTPMDFGQVFNMFDNEPSTATVKNDLRDRFQVMHKFSTKVTGGQYAANEQSLVKRFWKVNTHVVYNHQEAAKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSITN |
|
NCBI Accession
|
YP_006905831.1
|
|
Location
|
979-1377 |
|
Gene Name
|
AC3 |
|
Protein Name
|
rep-interacting protein |
|
Coding Region
|
ATGGATTCACGCACAGAGGAGAGCATCACTGCACGTCAGGCAGAGAGTTCCGTTTTTATCTGGAAGGTTCCAAATCCCCTATTTTTCATGATACACAAAGTAGAAGACCCACCATACACAACAACCAGAATATACTCCATCCAAATTCGGTTCAACCACAACCTGAGGAAGGAACTGAATCTACACAAAGCCTACTTCAATTTCCAAATCTGGACGACTTCGATTCGAGCTTCTGGGATGGATTATTTAAATAGATTTAAACATTTAGTTATGTTGTATTTAAATCAATTAGGTGTTATTGGAATTAATAATGTAATAAGAGCTGTTCGTTTTGCAACACTCAAATCATATGTAAACCATGTACTTGAAAATCATGAAATACAATTCAAACTTTATTAA |
|
Protein Sequence
|
MDSRTEESITARQAESSVFIWKVPNPLFFMIHKVEDPPYTTTRIYSIQIRFNHNLRKELNLHKAYFNFQIWTTSIRASGMDYLNRFKHLVMLYLNQLGVIGINNVIRAVRFATLKSYVNHVLENHEIQFKLY |
|
NCBI Accession
|
YP_006905832.1
|
|
Location
|
1124-1513 |
|
Gene Name
|
AC2 |
|
Protein Name
|
transcription activator |
|
Coding Region
|
ATGCAAAATTCATCTTCCTCAACTCCCCCCTCTATCAAACCACAACACAGGATAGCTAAGAAGAGAGCAATTCGTCGAAAACGAATTGATTTCAATTGTGGCTGTTCTATATACCAACACATCGACTGCATCAACTATGGATTCACGCACAGAGGAGAGCATCACTGCACGTCAGGCAGAGAGTTCCGTTTTTATCTGGAAGGTTCCAAATCCCCTATTTTTCATGATACACAAAGTAGAAGACCCACCATACACAACAACCAGAATATACTCCATCCAAATTCGGTTCAACCACAACCTGAGGAAGGAACTGAATCTACACAAAGCCTACTTCAATTTCCAAATCTGGACGACTTCGATTCGAGCTTCTGGGATGGATTATTTAAATAG |
|
Protein Sequence
|
MQNSSSSTPPSIKPQHRIAKKRAIRRKRIDFNCGCSIYQHIDCINYGFTHRGEHHCTSGREFRFYLEGSKSPIFHDTQSRRPTIHNNQNILHPNSVQPQPEEGTESTQSLLQFPNLDDFDSSFWDGLFK |
|
NCBI Accession
|
YP_006905833.1
|
|
Location
|
1455-2510 |
|
Gene Name
|
Rep |
|
Protein Name
|
rolling-circle replication protein |
|
Coding Region
|
ATGCCACGAAAGGGTTCTTTCTCAATAAAAGCCAAAAATTATTTCATCACATATCCTCACTGTGATTTACCAAAAGAAGCAGCATTGGAACAACTCAAGAATCTACATACTCCGGTGAATAAAAAATACATCAAGATCTGTAGAGAACTCCATGAAAATGGGGAACCACATCTGCACGTGCTTATCCAGTTTGAGGGGAAATACAACTGCACGAATCACAGACAGTTCGACTTGGTATCCCCAGTCAGGTCAGCACATTTCCATCCGAACATTCAGGGAGCTAAATCCAGCTCCGACGTCAAGTCCTACATCAGCAAGGATGGAGATACAATTGACTGGGGAGAATTCCAGATCGACGGCAGAACTGCTAGAGGAGGTCAACATACAGCTAATGATGCTGCAGCAGAGGCATTGAATGCATCGTCAAAAGAGGATGCAATGAGGATTATAAAAGAGAAGCTCCCTAAAGAGTTTCTTTTTCAATTTCACAATTTGTCCAGTAATCTGGATAAAATATTTGCTAAGGCTCCGGAACCATGGGTTCCTCCATTTCAACTATCATCATTCACTCATGTTCCAGAAGATATGCAAGAGTGGGCTGATGATTATTTTGGGAGGGGTTCCGCTGCGCGGCCGGAAAGACCTATTAGTATCATCGTTGAAGGTGATTCTAGAACCGGCAAGACAATGTGGGCCCGTTCTTTGGGCTCACATAATTATTTAAGTGGACACCTGGATTTCAATTCTAGGGTTTATTCAAACGAAGTGGAATATAACGTCATTGATGACGTCAGTCCACAATATTTAAAGTTAAAGCACTGGAAAGAATTGATTGGGGCCCAAAGAGACTGGCAATCAAATTGCAAATACGGAAAGCCAGTTCAAATTAAAGGTGGTATACCATCAATCGTGCTTTGCAATCCAGGAGAGGGGTCTAGCTATAAAGATTTCCTAGACAAAGAGGAAAATTCAGCTTTAAAAGCGTGGACACTTCATAATGCAAAATTCATCTTCCTCAACTCCCCCCTCTATCAAACCACAACACAGGATAGCTAA |
|
Protein Sequence
|
MPRKGSFSIKAKNYFITYPHCDLPKEAALEQLKNLHTPVNKKYIKICRELHENGEPHLHVLIQFEGKYNCTNHRQFDLVSPVRSAHFHPNIQGAKSSSDVKSYISKDGDTIDWGEFQIDGRTARGGQHTANDAAAEALNASSKEDAMRIIKEKLPKEFLFQFHNLSSNLDKIFAKAPEPWVPPFQLSSFTHVPEDMQEWADDYFGRGSAARPERPISIIVEGDSRTGKTMWARSLGSHNYLSGHLDFNSRVYSNEVEYNVIDDVSPQYLKLKHWKELIGAQRDWQSNCKYGKPVQIKGGIPSIVLCNPGEGSSYKDFLDKEENSALKAWTLHNAKFIFLNSPLYQTTTQDS |
|
NCBI Accession
|
YP_006905834.1
|
|
Location
|
2096-2359 |
|
Gene Name
|
AC4 |
|
Protein Name
|
AC4 protein |
|
Coding Region
|
ATGAAAATGGGGAACCACATCTGCACGTGCTTATCCAGTTTGAGGGGAAATACAACTGCACGAATCACAGACAGTTCGACTTGGTATCCCCAGTCAGGTCAGCACATTTCCATCCGAACATTCAGGGAGCTAAATCCAGCTCCGACGTCAAGTCCTACATCAGCAAGGATGGAGATACAATTGACTGGGGAGAATTCCAGATCGACGGCAGAACTGCTAGAGGAGGTCAACATACAGCTAATGATGCTGCAGCAGAGGCATTGA |
|
Protein Sequence
|
MKMGNHICTCLSSLRGNTTARITDSSTWYPQSGQHISIRTFRELNPAPTSSPTSARMEIQLTGENSRSTAELLEEVNIQLMMLQQRH |
|
NCBI Accession
|
YP_006902888.1
|
|
Location
|
574-1344 |
|
Gene Name
|
BV1 |
|
Protein Name
|
nuclear shuttle protein |
|
Coding Region
|
ATGTATTTTACTAGATATAGACGTGGTGGATCGTTAACCCATCGACGAGGTTATTCACGTTATACATTGTATAAACGACCTTTTTCTGTTCATCGTGTGGATGTGAAACGTCGACGAACCAGTTCTACTAAGTATCATGATGATGCAAAGATGTCACAGCAACGTATACATGAGGATCAGTTTGGTCCCGAATTTGTTCTGGGTCATAATACAGCTTTGTCTACATTCATTACATTTCCCAGTCTTGTTAAGAATGAACCTAATCGTTGTAGATCATATATTAAGTTAAAACGTTTACGTTTCAAAGGTACCGTGAAGATTGAACGTGTAATTGCTGATATTAATATGGATGGTCCTACTCAAAAGATTGAAGGAGTCTTCTCTATGGTTATTGTTGTTGATCGTAAACCACATCTTAGTCCAACTGGCTGTCTACATACATTTGATGAGTTATTTGGTGCTAGGATTCATAGCCATGGTAATCTAGCCATCGTTCCCGCATTGAAAGACCGTTTCTACATACGTCATATAATGAAACGTGTTTTATCTGTTGAGAAGGATACTTTGATGGTAGACTTGGAAGGAATTACATACTTATCTAATAGGCGTTTTAATTGTTGGTCTGCATTTAATGATCTTGATAGAGAATCATGCAATGGTGTTTATGCTAATATAAATAAGAATGCTTTATTAGTCTATTATTGTTGGATGTCAGATGCTTTGTCTAAAGCATCAACTTTTGTATCATTTGATCTTGAATATCTCGGTTGA |
|
Protein Sequence
|
MYFTRYRRGGSLTHRRGYSRYTLYKRPFSVHRVDVKRRRTSSTKYHDDAKMSQQRIHEDQFGPEFVLGHNTALSTFITFPSLVKNEPNRCRSYIKLKRLRFKGTVKIERVIADINMDGPTQKIEGVFSMVIVVDRKPHLSPTGCLHTFDELFGARIHSHGNLAIVPALKDRFYIRHIMKRVLSVEKDTLMVDLEGITYLSNRRFNCWSAFNDLDRESCNGVYANINKNALLVYYCWMSDALSKASTFVSFDLEYLG |
|
NCBI Accession
|
YP_006902889.1
|
|
Location
|
1435-2316 |
|
Gene Name
|
BC1 |
|
Protein Name
|
movement protein |
|
Coding Region
|
ATGGATTCTAAATTAGTCGTACCACCAAGTGTTTTTAATTATGTGGAGTCTCATCGAGATGAGTATCAACTGTCTCATGACCTTACAGAAATCATCTTGCAATTTCCTTCAACTGCAGCTCAATTAACTGCAAGGCTGAATCGTAGCTGTATGAAGATAGATCATTGCGTTATAGAATATCGACAGCAGGTTCCTATTAACGCAGCAGGAACAGTAATCGTGGAGATTCATGATAAAAGAATGACAGACAATGAGTCATTACAGGCGTCGTGGACTTTTCCAATTAGGTGTAACATAGATCTCCACTATTTCTCATCTTCATTTTTCTCACTCAAGGATCCAATTCCATGGAAACTGTATTATAAAGTATGTGACTCAAATGTTCATCAAGGTACACATTTTGCAAAATTCAAGGGTAAATTAAAACTGTCAACAGCAAAACATTCTGTTGATATCCCTTTCCGTGCACCAACGGTGAGAATTTTGTCAAAACAGTTTACAGACAAGGATATTGATTTTCACCATGTTGGATATGGAAAATATGAAAGAAGAATGATTAAATCTACTGCATCAGCAAGATTTGGACTTCATAACCCAATAGAGTTAAATCCAGGTGAAACTTGGGCTACAAGGAGTGCAGTAGGTATAACACATTCCAATGTCAGTTCAGATGTGGCAAACGAGATACATCCATATAGAGAAATGAACAGAATAGGAACGCCAATGTTAGACCCAGGTGACTCTGTTTCACAAATTGGAATTCAGAGAACCCAATCCAACATTACAATGTCTATGTCCCAGTTAAACGAAATAGTTAGATCAACAGTACAAGAATGTATAAACACCAATTGTATTCCCTCACATCCAAAACAGTTAAAATAA |
|
Protein Sequence
|
MDSKLVVPPSVFNYVESHRDEYQLSHDLTEIILQFPSTAAQLTARLNRSCMKIDHCVIEYRQQVPINAAGTVIVEIHDKRMTDNESLQASWTFPIRCNIDLHYFSSSFFSLKDPIPWKLYYKVCDSNVHQGTHFAKFKGKLKLSTAKHSVDIPFRAPTVRILSKQFTDKDIDFHHVGYGKYERRMIKSTASARFGLHNPIELNPGETWATRSAVGITHSNVSSDVANEIHPYREMNRIGTPMLDPGDSVSQIGIQRTQSNITMSMSQLNEIVRSTVQECINTNCIPSHPKQLK |