Tomato leaf curl New Delhi virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_000842925.1 |
| Release date |
2015/2/12 |
| Submitter |
Padidam,M., Beachy,R.N., Fauquet,C.M. |
| Host |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
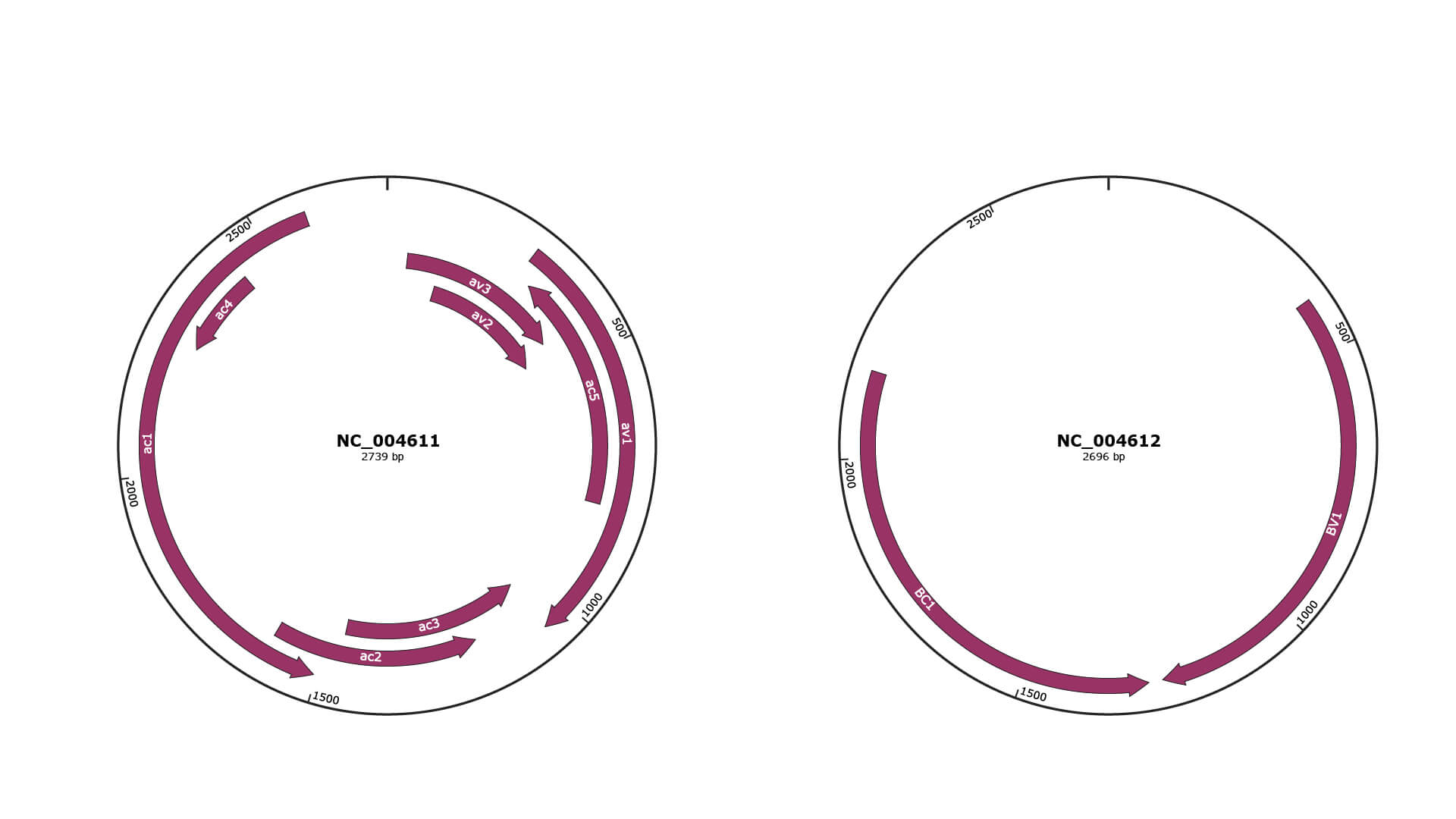
JBrowse
Genome
TAATATTACCGAATGGCCGCGCAAATTTTTAGGTGGGCCCTCAACCAATGAAATTCACGCTACATGGCCTATTTAGTGCGTGGGGATCAATAAATAGACTTGCTCACCAAGTTTGGATCCACAAACATGTGGGATCCATTATTGCACGAATTTCCCGAAAGCGTTCATGGTCTAAGGTGCATGCTAGCTGTAAAATATCTCCAAGAGATAGAAAAGAACTATTCACCAGACACAGTCGGCTACGATCTTATTCGAGATCTCATTCTTGTTCTCCGAGCAAAGAACTATGGCGAAGCGACCAGCAGATATCATCATTTCAACGCCCGCATCGAAGGTACGCCGACGTCTCAACTTCGACAGCCCCTATGGAGCTCGTGCAGTTGTCCCCATTGCCCGCGTCACCAAAGCAAAGGCCTGGACCAACAGGCCGATGAACAGAAAACCCAGAATGTACAGAATGTATAGAAGTCCCGACGTGCCAAGGGGCTGTGAAGGCCCTTGTAAAGTGCAGTCCTTTGAATCTAGGCACGATGTCTCTCATATTGGCAAAGTCATGTGTGTTAGTGATGTTACCCGAGGAACTGGACTCACACATCGCGTAGGGAAGCGATTCTGTGTGAAATCTGTCTATGTGCTGGGAAAGATATGGATGGATGAAAACATCAAGACAAAAAACCATACTAACAGTGTCATGTTTTTTCTGGTTCGTGACCGTCGTCCTACAGGATCTCCCCAGGATTTCGGGGAAGTGTTTAATATGTTTGACAATGAACCGAGCACAGCAACGGTGAAGAACATGCATCGTGATCGTTATCAAGTCTTACGGAAGTGGCATGCGACTGTGACGGGAGGAACATATGCATCTAAGGAGCAAGCATTAGTTAGGAAGTTTGTTAGGGTTAATAATTATGTTGTTTATAATCAACAAGAGGCCGGCAAGTATGAGAATCATACTGAAAACGCATTAATGTTGTATATGGCCTGTACTCACGCATCAAATCCTGTATATGCTACTTTGAAAATCCGGATCTACTTTTATGATTCGGCCACAAATTAATAAATATCCAGTTTTATATCATACGAAGTCCATACATCAATTGTTTGCTCCAATACATTATCCAATACATGATAAACTGCTCTTATTACATTATAAATTCCTATGACACCTAACATATCCAGGTACTTAAGGACCTGGGTTTTGAAGACTCTCAAGAAAATCCCAATCTGAGGGCGTAAGCCCGTCCAGATTTTGAAAGTTAGAAAACACTTGTGAAGTCCCAGGGCTTTCCGCAGGTTGTGGTTGAACTGTATTTGAATCTTGATTATGTCGTGCTGTGTTAGGAAGGGCCTGCTGTCGTGTTTCAAAATTTTGAAATACAGGGGATTTCGAATTTCCCAGGTATATACGCCACTCTCTGCTCGATCCGCAGTGATGTATTCCCCTGTGCGTGAATCCGTGATCATGGCAGTTGATCGATATGTAATACGAACAACCACACGGTAGATCAACTCGCCTCCTGCGAATGCTCTTCTTCTTCTTCTGGGAGAGCGATGTTTTCGCGACCGGAATAGAGTGGTTCTTCGAGTGTGATGAAGACTGCATTCTTGATTGCCCACTGCTTCAGTGCTGCATTTTTTTCTTCATCCAGATATTCCTTATAGCTGCTGTTTGGACCTTTATTGCACAGGAAGATAGTGGGAATTCCACCTTTAATCATGACCGGCTTTCCGTACTTCGTGTTGCTTTGGCAGTCACGCTGGGCCCCCATGAATTCTTTAAAGTGCTTTAGATAGTGGGGATCAACGTCATCAATGACGTTGTACCAGGCATCATTGCTATAGACCTTTGGGCTCAGATCAAGATGTCCACACAAGTAATTGTGTGGTCCTAAGCACCGAGCCCACATCGTTTTGCCCGTCCTACTATCCCCCTCTATGACTATGCTTATGGGCCTAAAAGGCCGCGCAGCGGCACACACAACATTAGACGAGACCCAATCGACGAGGTCTGCCGGAACTCTGTCGAAGGATGAAATTGAAAATGGAGAAACATAAACCTCGGAAGGAGGTTGAAAAATACGATCTAAATTGGTATTTAAATTGTGAAACTGCAGAACGTAATCTTTTGGGGCTAATTCCTTTAATACTCTCAAAGCATCGTCTTTATTTCCCGTGTTAATCGCCTGGGCATATGCATCGTTCGCCGTTTGTTGACCACCACGGGCAGATCGTCCATCGATCTGGAAAACACCCCATTCTAGAACGTCTCCATCTTTGGCGATGTAGTTTTTGACGTCCGACGCTGATTTAGCTCCCTGAATGTTCGGATGGAAATGTGCTGACCGACTTGGGGAAACCAAGTCGAAGAATCTGTTATTTTTGCACTGGAATTTCCCTTCGAATTGGATGAGAACATGGATATGCGGAGACCCATCTTCGTGAAGCTCTCTACAGATCTTGATGAATTTCTTCTTCGTCGGGGTTTCTAGGGTTTGCAATTGGGAGAGTGCCTCTTCTTTAGTTAGAGAGCACTTTGGATATGTGAGGAAATAGTTTTTGGCATTTACTCTAAAACGACGTGGCGAAGCCATAAAACTTGTCGTTTTGATTCGGCGTCCCTCAACTTATCTATATGATTGGTGTCTGGAGTCCTATATATAGGTAAGACACCATATGGCATTATTGTAATTTTGAAAAGAAAATTACTTTAATTCAAATTCCCTAAAGCGGCCATTCGTA
ACCGAAAGGCCGCGAAAATTTTGACCCCCTTATCCTGACCGTTGATGCGTAATCATTGCACGCCGTTATCCGTCCGATTTGCAACACGTGTATCCCACTAACAGACTTTATGGAAAATAAATGTGTGAATGCGTCTCTTTTCTGCATATGTGTTCCCCATATGTCTTTATCGTACTTCTATTATATGCGTCTGTGGTCCCCCCGCATTATATAAAGTCTTTCACATAAATCAAATTGCCTTCTTTGCTATGTATATTTTGATCGGTCGAGATCAAAATTAATATGTTGCGAACATATCCGTCGTTCGATCTTATGAGATATGCTTTAATTCAAACAATACTTGTTTGAATTTTATGCACGCTGTACAATACTAGTTTATAAAACTGCTACATATGTGACATTACATGGTGTTTCCGTTGCCACACATTTCCTATCCCAGCCAAATGGCGTTTCCCTCTCCTTATTCCACGCCTCGTCGTTCGGGTTACCCATTCAACAGAACATACAACGGAAACAAGAGTTTCCGCTTGTGGAAGACCCGGAAGTATCAAAACTGGAAGCGCTATCGCAGTACCCATTCCATAGCACGTTCTCCAACCGAACTGTTTGGCGATCCAATCTCCAAACAATATACGCGTAAGGAAATCTGTGAAACACAGGAGGGTTCGGAGTATCTGCTGCACAACAATCGTTACATGACGTCATATGTCACGTATCCATCAAAAACAAGAACTGGAACGGACAACCGCGTTCGTTCCTATATCAAGCTAAAGAGTCTGAACATATCTGGGACATTTGCTGTTCGTAAATCTGACTTGATGACCGAAGTGGTGCAAACAAATGGTCTATACGGAGTGATGTCTATAGTTGTAGTCCGCGATAAATCTCCAAAGATTTATTCTGCGACCCAACCTTTAATACCGTTTGTTGAGCTATTTGGATCTGTTAATGCTTGCAGGGGCAGTCTGAAAGTGGCAGAACGCCACCATGAACGCTTCGTACTTCTGAATCAAACATCCATCGTTGTCAATACCCCACATTCCAACGCTATCAAGAAATTCTGCATTCGTAACTGCATCCCAAGAACTTACACAACCTGGGTAACGTTCAAGGACGAAGAAGAAGATAGCTGTACTGGACGATATTCTAACACCCTCCGAAATGCAATTATTTTATATTATGTATGGTTAAGCGATGTATCCTCACAAGTCGATCTTTACAGCAATGTAATTCTTAATTACATTGGATAATATATAAAAATGCAGAAGAAACATCTTATTTTTTGAATAAATTTGGCTTAAAATTTATTACACGCTCTTCGATACTGGAGCATTTACATTGGATTTTATACATTGCTCTACAGTCTTCCGTAATTATATCTGCAATCTCTTCCCTTGTAATACTCCCCGCCTGTGATGCCGATGGACCTGGATCAATTGCCGAATCATCCAATCCGCTCAGATTTTTATATGGTCTGCTGGTGACGGACGAAAGTCCGATCTCCGATCTGCTTGCCCATGATTCGTTCGGACCTATAGCCAGATAGGGTACCCGTAACGATCTTGAACTATGTCCCATTAACCTTGAACCATCTACAAGACGCCTTGTTTGTGGTTTGGAACCCACAGACCAGAAATCAATGTCGTTCATAGTGAATTCCTTGGTCTGTATTTCTATCTTTGGTGGTCGGAATTCGACGTCAGTCGAATGTTTAGCCGACGACAGCTTCAATTTCCCTAGCATCTTACAGAAGTGTACCCCATTCACGACGTTTGTGTTCTCCACTCGGTATTCAACTCTCCAAGGATTCTTATCCTTGAGAGAGAAGAATGAGGAAGAGTAGTAGTGCAGGTTGCAATTGCATTTGATCGGAATTGTGAATTCCGCTTGTTTTGTGTCCCCCTCCGTCAATCTCATGTCGTGTATCTCTACCACGACATGACCAACAGCATTAATTGGAACCTGACTGCGATATTCCAGAACTACGTGATCTATTTTCATGCATCTATTCCTCAACTGGCTAAGCTTCTGCTCGAACATGGATGGAAATGACAAGGTAACTTCTGCAGCATCGTTTGTGAGAGCGTACTCAACGCGCTCAGATTGAATATACCCACCTACTCCCATACCCATACCATCATTTCCTATTGACATATTGGCCGCGCAGCGCAAAACCCACTGAAACACAGAAGGACAGACTACGATCAAAGAAACCCCGACGAAGAAGAAACCCTAGCAAACAACGAAGTTGTTTTGCAAAGAACGGATGTAGATGGTTTTATAATGCTATTGCATGTCATGTCTATGTCATACCAATTACCCTAAAATGAACGGCACATATTTTTCTACGAAAAAGGAGTTGTGCATGCATATGGGATGTCTGTTTATTTACGGTATAAATTGGAAGCCCAATTTATTTAATTGGGCTGAAGTTTAAATTCAGAAGAAGTCCATGAAATTGGCCCAGCATCCAGGTCCATTGTTAAAATGACATCGTTTGTGTGTTATTGTGTGTATAGAAGTTAGAGAGAAGCAGCAGTTTCTCTCTCTAGAACTCATCGGGTGTCTCTCAACTTATCTATATAATTGGTGTCTGGAGTCCTATATATAGGTAAGACACCATATGGCATTATTGTAATTGTGAAAAGAAAATTACTTTAATTCAAATTCCCTATAGCGGCCTTTCGTATAATATT
Gene Information
|
NCBI Accession
|
NP_803218.1
|
|
Location
|
48-434 |
|
Gene Name
|
av3 |
|
Protein Name
|
AV3 protein |
|
Coding Region
|
ATGAAATTCACGCTACATGGCCTATTTAGTGCGTGGGGATCAATAAATAGACTTGCTCACCAAGTTTGGATCCACAAACATGTGGGATCCATTATTGCACGAATTTCCCGAAAGCGTTCATGGTCTAAGGTGCATGCTAGCTGTAAAATATCTCCAAGAGATAGAAAAGAACTATTCACCAGACACAGTCGGCTACGATCTTATTCGAGATCTCATTCTTGTTCTCCGAGCAAAGAACTATGGCGAAGCGACCAGCAGATATCATCATTTCAACGCCCGCATCGAAGGTACGCCGACGTCTCAACTTCGACAGCCCCTATGGAGCTCGTGCAGTTGTCCCCATTGCCCGCGTCACCAAAGCAAAGGCCTGGACCAACAGGCCGATGA |
|
Protein Sequence
|
MKFTLHGLFSAWGSINRLAHQVWIHKHVGSIIARISRKRSWSKVHASCKISPRDRKELFTRHSRLRSYSRSHSCSPSKELWRSDQQISSFQRPHRRYADVSTSTAPMELVQLSPLPASPKQRPGPTGR |
|
NCBI Accession
|
NP_803219.1
|
|
Location
|
127-465 |
|
Gene Name
|
av2 |
|
Protein Name
|
AV2 protein |
|
Coding Region
|
ATGTGGGATCCATTATTGCACGAATTTCCCGAAAGCGTTCATGGTCTAAGGTGCATGCTAGCTGTAAAATATCTCCAAGAGATAGAAAAGAACTATTCACCAGACACAGTCGGCTACGATCTTATTCGAGATCTCATTCTTGTTCTCCGAGCAAAGAACTATGGCGAAGCGACCAGCAGATATCATCATTTCAACGCCCGCATCGAAGGTACGCCGACGTCTCAACTTCGACAGCCCCTATGGAGCTCGTGCAGTTGTCCCCATTGCCCGCGTCACCAAAGCAAAGGCCTGGACCAACAGGCCGATGAACAGAAAACCCAGAATGTACAGAATGTATAG |
|
Protein Sequence
|
MWDPLLHEFPESVHGLRCMLAVKYLQEIEKNYSPDTVGYDLIRDLILVLRAKNYGEATSRYHHFNARIEGTPTSQLRQPLWSSCSCPHCPRHQSKGLDQQADEQKTQNVQNV |
|
NCBI Accession
|
NP_803220.1
|
|
Location
|
287-1057 |
|
Gene Name
|
av1 |
|
Protein Name
|
AV1 protein |
|
Coding Region
|
ATGGCGAAGCGACCAGCAGATATCATCATTTCAACGCCCGCATCGAAGGTACGCCGACGTCTCAACTTCGACAGCCCCTATGGAGCTCGTGCAGTTGTCCCCATTGCCCGCGTCACCAAAGCAAAGGCCTGGACCAACAGGCCGATGAACAGAAAACCCAGAATGTACAGAATGTATAGAAGTCCCGACGTGCCAAGGGGCTGTGAAGGCCCTTGTAAAGTGCAGTCCTTTGAATCTAGGCACGATGTCTCTCATATTGGCAAAGTCATGTGTGTTAGTGATGTTACCCGAGGAACTGGACTCACACATCGCGTAGGGAAGCGATTCTGTGTGAAATCTGTCTATGTGCTGGGAAAGATATGGATGGATGAAAACATCAAGACAAAAAACCATACTAACAGTGTCATGTTTTTTCTGGTTCGTGACCGTCGTCCTACAGGATCTCCCCAGGATTTCGGGGAAGTGTTTAATATGTTTGACAATGAACCGAGCACAGCAACGGTGAAGAACATGCATCGTGATCGTTATCAAGTCTTACGGAAGTGGCATGCGACTGTGACGGGAGGAACATATGCATCTAAGGAGCAAGCATTAGTTAGGAAGTTTGTTAGGGTTAATAATTATGTTGTTTATAATCAACAAGAGGCCGGCAAGTATGAGAATCATACTGAAAACGCATTAATGTTGTATATGGCCTGTACTCACGCATCAAATCCTGTATATGCTACTTTGAAAATCCGGATCTACTTTTATGATTCGGCCACAAATTAA |
|
Protein Sequence
|
MAKRPADIIISTPASKVRRRLNFDSPYGARAVVPIARVTKAKAWTNRPMNRKPRMYRMYRSPDVPRGCEGPCKVQSFESRHDVSHIGKVMCVSDVTRGTGLTHRVGKRFCVKSVYVLGKIWMDENIKTKNHTNSVMFFLVRDRRPTGSPQDFGEVFNMFDNEPSTATVKNMHRDRYQVLRKWHATVTGGTYASKEQALVRKFVRVNNYVVYNQQEAGKYENHTENALMLYMACTHASNPVYATLKIRIYFYDSATN |
|
NCBI Accession
|
NP_803221.1
|
|
Location
|
317-802 |
|
Gene Name
|
ac5 |
|
Protein Name
|
AC5 protein |
|
Coding Region
|
ATGCATGTTCTTCACCGTTGCTGTGCTCGGTTCATTGTCAAACATATTAAACACTTCCCCGAAATCCTGGGGAGATCCTGTAGGACGACGGTCACGAACCAGAAAAAACATGACACTGTTAGTATGGTTTTTTGTCTTGATGTTTTCATCCATCCATATCTTTCCCAGCACATAGACAGATTTCACACAGAATCGCTTCCCTACGCGATGTGTGAGTCCAGTTCCTCGGGTAACATCACTAACACACATGACTTTGCCAATATGAGAGACATCGTGCCTAGATTCAAAGGACTGCACTTTACAAGGGCCTTCACAGCCCCTTGGCACGTCGGGACTTCTATACATTCTGTACATTCTGGGTTTTCTGTTCATCGGCCTGTTGGTCCAGGCCTTTGCTTTGGTGACGCGGGCAATGGGGACAACTGCACGAGCTCCATAGGGGCTGTCGAAGTTGAGACGTCGGCGTACCTTCGATGCGGGCGTTGA |
|
Protein Sequence
|
MHVLHRCCARFIVKHIKHFPEILGRSCRTTVTNQKKHDTVSMVFCLDVFIHPYLSQHIDRFHTESLPYAMCESSSSGNITNTHDFANMRDIVPRFKGLHFTRAFTAPWHVGTSIHSVHSGFSVHRPVGPGLCFGDAGNGDNCTSSIGAVEVETSAYLRCGR |
|
NCBI Accession
|
NP_803222.1
|
|
Location
|
1054-1464 |
|
Gene Name
|
ac3 |
|
Protein Name
|
AC3 protein |
|
Coding Region
|
ATGATCACGGATTCACGCACAGGGGAATACATCACTGCGGATCGAGCAGAGAGTGGCGTATATACCTGGGAAATTCGAAATCCCCTGTATTTCAAAATTTTGAAACACGACAGCAGGCCCTTCCTAACACAGCACGACATAATCAAGATTCAAATACAGTTCAACCACAACCTGCGGAAAGCCCTGGGACTTCACAAGTGTTTTCTAACTTTCAAAATCTGGACGGGCTTACGCCCTCAGATTGGGATTTTCTTGAGAGTCTTCAAAACCCAGGTCCTTAAGTACCTGGATATGTTAGGTGTCATAGGAATTTATAATGTAATAAGAGCAGTTTATCATGTATTGGATAATGTATTGGAGCAAACAATTGATGTATGGACTTCGTATGATATAAAACTGGATATTTATTAA |
|
Protein Sequence
|
MITDSRTGEYITADRAESGVYTWEIRNPLYFKILKHDSRPFLTQHDIIKIQIQFNHNLRKALGLHKCFLTFKIWTGLRPQIGIFLRVFKTQVLKYLDMLGVIGIYNVIRAVYHVLDNVLEQTIDVWTSYDIKLDIY |
|
NCBI Accession
|
NP_803223.1
|
|
Location
|
1184-1603 |
|
Gene Name
|
ac2 |
|
Protein Name
|
AC2 protein |
|
Coding Region
|
ATGCAGTCTTCATCACACTCGAAGAACCACTCTATTCCGGTCGCGAAAACATCGCTCTCCCAGAAGAAGAAGAAGAGCATTCGCAGGAGGCGAGTTGATCTACCGTGTGGTTGTTCGTATTACATATCGATCAACTGCCATGATCACGGATTCACGCACAGGGGAATACATCACTGCGGATCGAGCAGAGAGTGGCGTATATACCTGGGAAATTCGAAATCCCCTGTATTTCAAAATTTTGAAACACGACAGCAGGCCCTTCCTAACACAGCACGACATAATCAAGATTCAAATACAGTTCAACCACAACCTGCGGAAAGCCCTGGGACTTCACAAGTGTTTTCTAACTTTCAAAATCTGGACGGGCTTACGCCCTCAGATTGGGATTTTCTTGAGAGTCTTCAAAACCCAGGTCCTTAA |
|
Protein Sequence
|
MQSSSHSKNHSIPVAKTSLSQKKKKSIRRRRVDLPCGCSYYISINCHDHGFTHRGIHHCGSSREWRIYLGNSKSPVFQNFETRQQALPNTARHNQDSNTVQPQPAESPGTSQVFSNFQNLDGLTPSDWDFLESLQNPGP |
|
NCBI Accession
|
NP_803224.1
|
|
Location
|
1506-2591 |
|
Gene Name
|
ac1 |
|
Protein Name
|
AC1 protein |
|
Coding Region
|
ATGGCTTCGCCACGTCGTTTTAGAGTAAATGCCAAAAACTATTTCCTCACATATCCAAAGTGCTCTCTAACTAAAGAAGAGGCACTCTCCCAATTGCAAACCCTAGAAACCCCGACGAAGAAGAAATTCATCAAGATCTGTAGAGAGCTTCACGAAGATGGGTCTCCGCATATCCATGTTCTCATCCAATTCGAAGGGAAATTCCAGTGCAAAAATAACAGATTCTTCGACTTGGTTTCCCCAAGTCGGTCAGCACATTTCCATCCGAACATTCAGGGAGCTAAATCAGCGTCGGACGTCAAAAACTACATCGCCAAAGATGGAGACGTTCTAGAATGGGGTGTTTTCCAGATCGATGGACGATCTGCCCGTGGTGGTCAACAAACGGCGAACGATGCATATGCCCAGGCGATTAACACGGGAAATAAAGACGATGCTTTGAGAGTATTAAAGGAATTAGCCCCAAAAGATTACGTTCTGCAGTTTCACAATTTAAATACCAATTTAGATCGTATTTTTCAACCTCCTTCCGAGGTTTATGTTTCTCCATTTTCAATTTCATCCTTCGACAGAGTTCCGGCAGACCTCGTCGATTGGGTCTCGTCTAATGTTGTGTGTGCCGCTGCGCGGCCTTTTAGGCCCATAAGCATAGTCATAGAGGGGGATAGTAGGACGGGCAAAACGATGTGGGCTCGGTGCTTAGGACCACACAATTACTTGTGTGGACATCTTGATCTGAGCCCAAAGGTCTATAGCAATGATGCCTGGTACAACGTCATTGATGACGTTGATCCCCACTATCTAAAGCACTTTAAAGAATTCATGGGGGCCCAGCGTGACTGCCAAAGCAACACGAAGTACGGAAAGCCGGTCATGATTAAAGGTGGAATTCCCACTATCTTCCTGTGCAATAAAGGTCCAAACAGCAGCTATAAGGAATATCTGGATGAAGAAAAAAATGCAGCACTGAAGCAGTGGGCAATCAAGAATGCAGTCTTCATCACACTCGAAGAACCACTCTATTCCGGTCGCGAAAACATCGCTCTCCCAGAAGAAGAAGAAGAGCATTCGCAGGAGGCGAGTTGA |
|
Protein Sequence
|
MASPRRFRVNAKNYFLTYPKCSLTKEEALSQLQTLETPTKKKFIKICRELHEDGSPHIHVLIQFEGKFQCKNNRFFDLVSPSRSAHFHPNIQGAKSASDVKNYIAKDGDVLEWGVFQIDGRSARGGQQTANDAYAQAINTGNKDDALRVLKELAPKDYVLQFHNLNTNLDRIFQPPSEVYVSPFSISSFDRVPADLVDWVSSNVVCAAARPFRPISIVIEGDSRTGKTMWARCLGPHNYLCGHLDLSPKVYSNDAWYNVIDDVDPHYLKHFKEFMGAQRDCQSNTKYGKPVMIKGGIPTIFLCNKGPNSSYKEYLDEEKNAALKQWAIKNAVFITLEEPLYSGRENIALPEEEEEHSQEAS |
|
NCBI Accession
|
NP_803225.1
|
|
Location
|
2258-2434 |
|
Gene Name
|
ac4 |
|
Protein Name
|
AC4 protein |
|
Coding Region
|
ATGGGTCTCCGCATATCCATGTTCTCATCCAATTCGAAGGGAAATTCCAGTGCAAAAATAACAGATTCTTCGACTTGGTTTCCCCAAGTCGGTCAGCACATTTCCATCCGAACATTCAGGGAGCTAAATCAGCGTCGGACGTCAAAAACTACATCGCCAAAGATGGAGACGTTCTAG |
|
Protein Sequence
|
MGLRISMFSSNSKGNSSAKITDSSTWFPQVGQHISIRTFRELNQRRTSKTTSPKMETF |
|
NCBI Accession
|
NP_803226.1
|
|
Location
|
405-1250 |
|
Gene Name
|
BV1 |
|
Protein Name
|
nuclear shuttle protein |
|
Coding Region
|
ATGGTGTTTCCGTTGCCACACATTTCCTATCCCAGCCAAATGGCGTTTCCCTCTCCTTATTCCACGCCTCGTCGTTCGGGTTACCCATTCAACAGAACATACAACGGAAACAAGAGTTTCCGCTTGTGGAAGACCCGGAAGTATCAAAACTGGAAGCGCTATCGCAGTACCCATTCCATAGCACGTTCTCCAACCGAACTGTTTGGCGATCCAATCTCCAAACAATATACGCGTAAGGAAATCTGTGAAACACAGGAGGGTTCGGAGTATCTGCTGCACAACAATCGTTACATGACGTCATATGTCACGTATCCATCAAAAACAAGAACTGGAACGGACAACCGCGTTCGTTCCTATATCAAGCTAAAGAGTCTGAACATATCTGGGACATTTGCTGTTCGTAAATCTGACTTGATGACCGAAGTGGTGCAAACAAATGGTCTATACGGAGTGATGTCTATAGTTGTAGTCCGCGATAAATCTCCAAAGATTTATTCTGCGACCCAACCTTTAATACCGTTTGTTGAGCTATTTGGATCTGTTAATGCTTGCAGGGGCAGTCTGAAAGTGGCAGAACGCCACCATGAACGCTTCGTACTTCTGAATCAAACATCCATCGTTGTCAATACCCCACATTCCAACGCTATCAAGAAATTCTGCATTCGTAACTGCATCCCAAGAACTTACACAACCTGGGTAACGTTCAAGGACGAAGAAGAAGATAGCTGTACTGGACGATATTCTAACACCCTCCGAAATGCAATTATTTTATATTATGTATGGTTAAGCGATGTATCCTCACAAGTCGATCTTTACAGCAATGTAATTCTTAATTACATTGGATAA |
|
Protein Sequence
|
MVFPLPHISYPSQMAFPSPYSTPRRSGYPFNRTYNGNKSFRLWKTRKYQNWKRYRSTHSIARSPTELFGDPISKQYTRKEICETQEGSEYLLHNNRYMTSYVTYPSKTRTGTDNRVRSYIKLKSLNISGTFAVRKSDLMTEVVQTNGLYGVMSIVVVRDKSPKIYSATQPLIPFVELFGSVNACRGSLKVAERHHERFVLLNQTSIVVNTPHSNAIKKFCIRNCIPRTYTTWVTFKDEEEDSCTGRYSNTLRNAIILYYVWLSDVSSQVDLYSNVILNYIG |
|
NCBI Accession
|
NP_803227.1
|
|
Location
|
1276-2154 |
|
Gene Name
|
BC1 |
|
Protein Name
|
movement protein |
|
Coding Region
|
ATGTCAATAGGAAATGATGGTATGGGTATGGGAGTAGGTGGGTATATTCAATCTGAGCGCGTTGAGTACGCTCTCACAAACGATGCTGCAGAAGTTACCTTGTCATTTCCATCCATGTTCGAGCAGAAGCTTAGCCAGTTGAGGAATAGATGCATGAAAATAGATCACGTAGTTCTGGAATATCGCAGTCAGGTTCCAATTAATGCTGTTGGTCATGTCGTGGTAGAGATACACGACATGAGATTGACGGAGGGGGACACAAAACAAGCGGAATTCACAATTCCGATCAAATGCAATTGCAACCTGCACTACTACTCTTCCTCATTCTTCTCTCTCAAGGATAAGAATCCTTGGAGAGTTGAATACCGAGTGGAGAACACAAACGTCGTGAATGGGGTACACTTCTGTAAGATGCTAGGGAAATTGAAGCTGTCGTCGGCTAAACATTCGACTGACGTCGAATTCCGACCACCAAAGATAGAAATACAGACCAAGGAATTCACTATGAACGACATTGATTTCTGGTCTGTGGGTTCCAAACCACAAACAAGGCGTCTTGTAGATGGTTCAAGGTTAATGGGACATAGTTCAAGATCGTTACGGGTACCCTATCTGGCTATAGGTCCGAACGAATCATGGGCAAGCAGATCGGAGATCGGACTTTCGTCCGTCACCAGCAGACCATATAAAAATCTGAGCGGATTGGATGATTCGGCAATTGATCCAGGTCCATCGGCATCACAGGCGGGGAGTATTACAAGGGAAGAGATTGCAGATATAATTACGGAAGACTGTAGAGCAATGTATAAAATCCAATGTAAATGCTCCAGTATCGAAGAGCGTGTAATAAATTTTAAGCCAAATTTATTCAAAAAATAA |
|
Protein Sequence
|
MSIGNDGMGMGVGGYIQSERVEYALTNDAAEVTLSFPSMFEQKLSQLRNRCMKIDHVVLEYRSQVPINAVGHVVVEIHDMRLTEGDTKQAEFTIPIKCNCNLHYYSSSFFSLKDKNPWRVEYRVENTNVVNGVHFCKMLGKLKLSSAKHSTDVEFRPPKIEIQTKEFTMNDIDFWSVGSKPQTRRLVDGSRLMGHSSRSLRVPYLAIGPNESWASRSEIGLSSVTSRPYKNLSGLDDSAIDPGPSASQAGSITREEIADIITEDCRAMYKIQCKCSSIEERVINFKPNLFKK |