Tomato leaf curl Mali virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_000841705.1 |
| Isolate |
Mali |
| Release date |
2015/2/12 |
| Submitter |
Zhou,Y.C., Noussourou,M., Kon,T., Rojas,M.R., Jiang,H., Chen,L.F., Gamby,K., Foster,R., Gilbertson,R.L., Zhou,Y., Chen,L. |
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
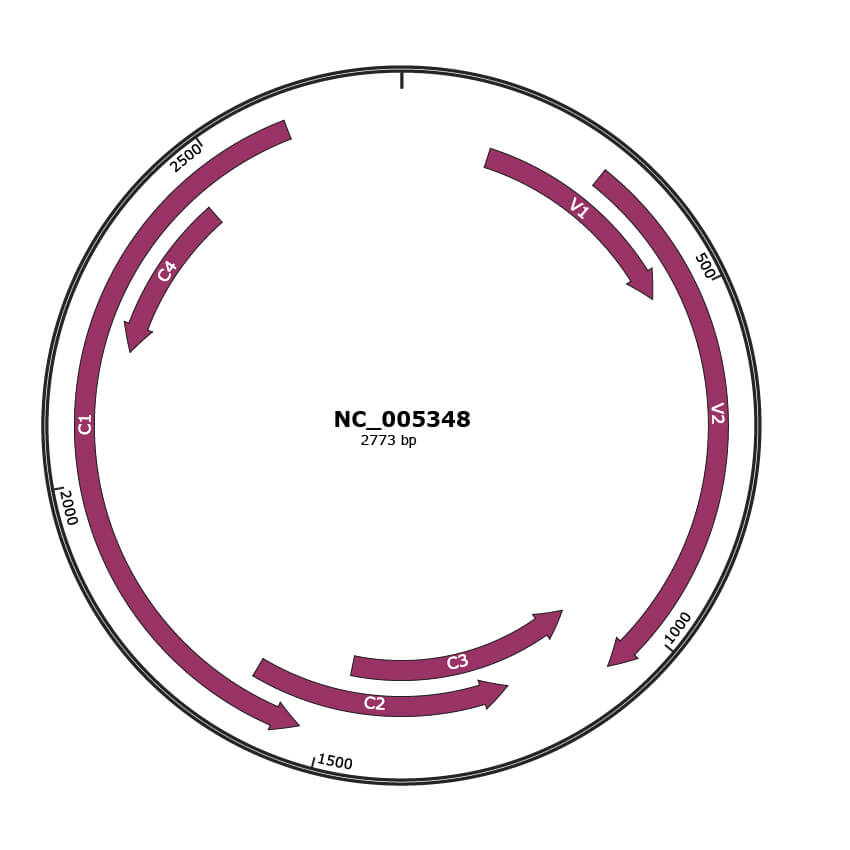
JBrowse
Genome
ACAGGATGGCCGCGCCCGAAAAAGAAAGTGGTCCCTCCTCACTAATTTATGTCGGCCAATCAGAATGTCAGTGAAAACGTTAGATAAGTAGTGTTTTGTCTTATATACTTTGGTCCCAAGTATGTTACAGTTGCACTATGTGGGATCCATTATTGAATGAATTCCCTGAATCAGTACATGGGTTTCGATGTATGCTGGCCATAAAATATTTGCAGGCCATAGAGGAAACATACGAGCCCAATACATTGGGTTACGATTTAATTCGTGATCTCATATCAGTAGTTAGGGCCTCCAACTATGTTGAAGCGACCCGCCGATATATTCATTTCCACTCCCGCCTCGAAGGTTCGTCGAAAACTGAACTTCGACAGCCCATACTCCAGCCGTGCTGTTGTCCCCACTGTCCGAGGCACAAGCAAGCGTCAACTATGGACGTACCGGCCCATGTACCGAAAGCCCAAGTTTTACAAAATGTACAGAAGTCCTGATGTACCACGGGGATGTGAAGGTCCATGTAAGATCCAGTCGTATGAGCAAAGGGATGACGTGAAGCATACCGGTATTGTACGTTGTGTTAGTGATATAACTCGTGGTCCTGGTTTGACTCATAGAACAGGGAAGAGATTCTGTATCAAGTCCATGTATATATTGGGTAAGATTTGGATGGATGAGAACATTAAGAAGACGAATCACACTAACAATGTCATGTTCTACTTGGTCCGTGATAGAAGGCCCTATGGAAAAAGCCCAATGGATTTTGGACAGGTTTTCAATATGTTTGACAATGAGCCCAGTACTGCCACTGTGAAGAATGATCTCCGTGATAGATATCAAGTACTTAGGAAGTTTCATGCTACCGTTACGGGTGGACCCTCTGGAGTGAAGGAACAGGCATTAGTGAAAAGATTTTATAGGCTTAATAGTCATGTAGTGTATAACCATCAGGAAGAGGCTAAATATGAGAATCATACAGAGAATGCGTTGTTATTGTATATGGCATGTACTCATGCTTCTAACCCAGTGTATGCTACCCTTAAAATACGCATCTATTTCTATGATGCAGTTACGAATTAATAAATATTAAATTTTATTTCATGATTTTCTGATACATCAATAATGTTTTCAAGAATATTGTACAATACATGGTTGACTGCCCTAATGATATTATTAATAGAAATTACATTCAAATTATCTAAATATTTAATTATTTGGGTCTTAAAGACCCTTAAGAAATGACCAGTCTGAGGCCGTAAGGTCGTCCAGATCTGGAAGTTCAGATAACACTTGTGAATCCCCAACTCTTTCCTGAGGTTGTGGTTGAACCTGATTTGGTCTGATATCATGTCGTGGTTCCTGTTGAATGGTCGGCTGATGTGTTTTATTATCTTGAAATATAGGGGATTGTTGAGCTCCCAGATAAACACGCCACTCTGAGCTTGAAGAGCAGTGATGTGTTCCCCTGTGCGTAAATCCATGGTTGGTGCAGTTAATGTGTAGATAGTATGAGCACCCGCAGTTGAGGTCTACTCGTCTACGCCTGATCGGTTTCTTCTTGGCTTGTTTGTGGAGAACCTTGATTGGCGTTGGAGAACAATGGCTCTGTGAGGGTGACGAAGGTCGCATTTTTTACTGCCCAAGCCTTCAGTGCTCTGTTTTTTTCCTCGTCTAGAAATTCCTTATATGATGAAGTTGCCCCTGGATTGCAGAGGAAAATACTGGGAATGCCCCCTTTAATTTGAACTGGCTTTCCGTATTTTGTGTTGCTTTGCCAGTCTCTTTGGGCCCCCATCAGCTCTTTAAAATGCTTTAAATAATGTGGGTCGACATCATCAATGACGTTATACCATGCGTTATTGGAGTACACCTTTGGGCTTAAGTCTAGGTGCCCACATAAATAATTATGTGGACCCAGAGAACGGGCCCATACAGTTTTGCCGGTCCGACTGTCACCCTCTAAGACTATACTCTTGGGTCTCCATGGCCGCGCAGCGGAATCTCTTATATTATCTGCCACCCACTCTTCAAGTTCGTCTGGAACTTGAGTAAAAGAAGAAGAAGAAAAAGGGGATACATATACTTCAGGAGGTTCCTGGAAGATTCTATCTAAATTGGATTTTAAATTATGATATTGAAATATATAATCTTTTGGGAGTTTTTCTTTAATTATAGCTAAAGCAGCTTCAGTTGAACCTGCATTTAATGCCTCGGCGGCTGCGTCGTTAGCTGTTTGGCAGCCTCCTCTAGCAGATCTGCCGTCAATTTGGAATTCTCCCCATTCGAGAGTGTCTCCGTCCTTATCGATATAGGACTTGACGTCGGAGCTGGATTTAGCTCCCTGTACATTCGGATGGAAATGTGCTGACCGGGTTGGGGATACCAGGTCGAAGAATCGTTGATTTGTGCAGTTGTATTTACCCTCGAATTGGATAAGCACGTGGAGATGATGTTCCCCATCTTCGTGGAGTTCTCTACAGATTTTAATGAATTTTTTATTTGTGGGAGTCTGTAGGTTCTGTAATTGAGAAAGTGCCTCTTTTTTAGTAAGAGAGCATTGGGGATAAGTGAGGAAGTAATTCTTGGCTTTAATACTAAAACGACCGGCTCTAGGCATAGTGATAAATGAATTGGGGGGCACTAAAAGTCATATGAATTGGGGGAACTGGGGGGCAATTTATATGTGCCCCCCAAATGGCATAACTGTAATATCGTAAACCTTTAAGTCTCATTAGAAATCCAAATTCCATTTAAATCTAGCGGCCATCCTTCTAATATT
Gene Information
|
NCBI Accession
|
NP_958316.1
|
|
Location
|
138-488 |
|
Gene Name
|
V1 |
|
Protein Name
|
pre-coat protein |
|
Coding Region
|
ATGTGGGATCCATTATTGAATGAATTCCCTGAATCAGTACATGGGTTTCGATGTATGCTGGCCATAAAATATTTGCAGGCCATAGAGGAAACATACGAGCCCAATACATTGGGTTACGATTTAATTCGTGATCTCATATCAGTAGTTAGGGCCTCCAACTATGTTGAAGCGACCCGCCGATATATTCATTTCCACTCCCGCCTCGAAGGTTCGTCGAAAACTGAACTTCGACAGCCCATACTCCAGCCGTGCTGTTGTCCCCACTGTCCGAGGCACAAGCAAGCGTCAACTATGGACGTACCGGCCCATGTACCGAAAGCCCAAGTTTTACAAAATGTACAGAAGTCCTGA |
|
Protein Sequence
|
MWDPLLNEFPESVHGFRCMLAIKYLQAIEETYEPNTLGYDLIRDLISVVRASNYVEATRRYIHFHSRLEGSSKTELRQPILQPCCCPHCPRHKQASTMDVPAHVPKAQVLQNVQKS |
|
NCBI Accession
|
NP_958317.1
|
|
Location
|
298-1074 |
|
Gene Name
|
V2 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGTTGAAGCGACCCGCCGATATATTCATTTCCACTCCCGCCTCGAAGGTTCGTCGAAAACTGAACTTCGACAGCCCATACTCCAGCCGTGCTGTTGTCCCCACTGTCCGAGGCACAAGCAAGCGTCAACTATGGACGTACCGGCCCATGTACCGAAAGCCCAAGTTTTACAAAATGTACAGAAGTCCTGATGTACCACGGGGATGTGAAGGTCCATGTAAGATCCAGTCGTATGAGCAAAGGGATGACGTGAAGCATACCGGTATTGTACGTTGTGTTAGTGATATAACTCGTGGTCCTGGTTTGACTCATAGAACAGGGAAGAGATTCTGTATCAAGTCCATGTATATATTGGGTAAGATTTGGATGGATGAGAACATTAAGAAGACGAATCACACTAACAATGTCATGTTCTACTTGGTCCGTGATAGAAGGCCCTATGGAAAAAGCCCAATGGATTTTGGACAGGTTTTCAATATGTTTGACAATGAGCCCAGTACTGCCACTGTGAAGAATGATCTCCGTGATAGATATCAAGTACTTAGGAAGTTTCATGCTACCGTTACGGGTGGACCCTCTGGAGTGAAGGAACAGGCATTAGTGAAAAGATTTTATAGGCTTAATAGTCATGTAGTGTATAACCATCAGGAAGAGGCTAAATATGAGAATCATACAGAGAATGCGTTGTTATTGTATATGGCATGTACTCATGCTTCTAACCCAGTGTATGCTACCCTTAAAATACGCATCTATTTCTATGATGCAGTTACGAATTAA |
|
Protein Sequence
|
MLKRPADIFISTPASKVRRKLNFDSPYSSRAVVPTVRGTSKRQLWTYRPMYRKPKFYKMYRSPDVPRGCEGPCKIQSYEQRDDVKHTGIVRCVSDITRGPGLTHRTGKRFCIKSMYILGKIWMDENIKKTNHTNNVMFYLVRDRRPYGKSPMDFGQVFNMFDNEPSTATVKNDLRDRYQVLRKFHATVTGGPSGVKEQALVKRFYRLNSHVVYNHQEEAKYENHTENALLLYMACTHASNPVYATLKIRIYFYDAVTN |
|
NCBI Accession
|
NP_958318.1
|
|
Location
|
1071-1475 |
|
Gene Name
|
C3 |
|
Protein Name
|
C3 protein |
|
Coding Region
|
ATGGATTTACGCACAGGGGAACACATCACTGCTCTTCAAGCTCAGAGTGGCGTGTTTATCTGGGAGCTCAACAATCCCCTATATTTCAAGATAATAAAACACATCAGCCGACCATTCAACAGGAACCACGACATGATATCAGACCAAATCAGGTTCAACCACAACCTCAGGAAAGAGTTGGGGATTCACAAGTGTTATCTGAACTTCCAGATCTGGACGACCTTACGGCCTCAGACTGGTCATTTCTTAAGGGTCTTTAAGACCCAAATAATTAAATATTTAGATAATTTGAATGTAATTTCTATTAATAATATCATTAGGGCAGTCAACCATGTATTGTACAATATTCTTGAAAACATTATTGATGTATCAGAAAATCATGAAATAAAATTTAATATTTATTAA |
|
Protein Sequence
|
MDLRTGEHITALQAQSGVFIWELNNPLYFKIIKHISRPFNRNHDMISDQIRFNHNLRKELGIHKCYLNFQIWTTLRPQTGHFLRVFKTQIIKYLDNLNVISINNIIRAVNHVLYNILENIIDVSENHEIKFNIY |
|
NCBI Accession
|
NP_958319.1
|
|
Location
|
1216-1623 |
|
Gene Name
|
C2 |
|
Protein Name
|
C2 protein |
|
Coding Region
|
ATGCGACCTTCGTCACCCTCACAGAGCCATTGTTCTCCAACGCCAATCAAGGTTCTCCACAAACAAGCCAAGAAGAAACCGATCAGGCGTAGACGAGTAGACCTCAACTGCGGGTGCTCATACTATCTACACATTAACTGCACCAACCATGGATTTACGCACAGGGGAACACATCACTGCTCTTCAAGCTCAGAGTGGCGTGTTTATCTGGGAGCTCAACAATCCCCTATATTTCAAGATAATAAAACACATCAGCCGACCATTCAACAGGAACCACGACATGATATCAGACCAAATCAGGTTCAACCACAACCTCAGGAAAGAGTTGGGGATTCACAAGTGTTATCTGAACTTCCAGATCTGGACGACCTTACGGCCTCAGACTGGTCATTTCTTAAGGGTCTTTAA |
|
Protein Sequence
|
MRPSSPSQSHCSPTPIKVLHKQAKKKPIRRRRVDLNCGCSYYLHINCTNHGFTHRGTHHCSSSSEWRVYLGAQQSPIFQDNKTHQPTIQQEPRHDIRPNQVQPQPQERVGDSQVLSELPDLDDLTASDWSFLKGL |
|
NCBI Accession
|
NP_958320.1
|
|
Location
|
1532-2611 |
|
Gene Name
|
C1 |
|
Protein Name
|
replication associated protein C1 |
|
Coding Region
|
ATGCCTAGAGCCGGTCGTTTTAGTATTAAAGCCAAGAATTACTTCCTCACTTATCCCCAATGCTCTCTTACTAAAAAAGAGGCACTTTCTCAATTACAGAACCTACAGACTCCCACAAATAAAAAATTCATTAAAATCTGTAGAGAACTCCACGAAGATGGGGAACATCATCTCCACGTGCTTATCCAATTCGAGGGTAAATACAACTGCACAAATCAACGATTCTTCGACCTGGTATCCCCAACCCGGTCAGCACATTTCCATCCGAATGTACAGGGAGCTAAATCCAGCTCCGACGTCAAGTCCTATATCGATAAGGACGGAGACACTCTCGAATGGGGAGAATTCCAAATTGACGGCAGATCTGCTAGAGGAGGCTGCCAAACAGCTAACGACGCAGCCGCCGAGGCATTAAATGCAGGTTCAACTGAAGCTGCTTTAGCTATAATTAAAGAAAAACTCCCAAAAGATTATATATTTCAATATCATAATTTAAAATCCAATTTAGATAGAATCTTCCAGGAACCTCCTGAAGTATATGTATCCCCTTTTTCTTCTTCTTCTTTTACTCAAGTTCCAGACGAACTTGAAGAGTGGGTGGCAGATAATATAAGAGATTCCGCTGCGCGGCCATGGAGACCCAAGAGTATAGTCTTAGAGGGTGACAGTCGGACCGGCAAAACTGTATGGGCCCGTTCTCTGGGTCCACATAATTATTTATGTGGGCACCTAGACTTAAGCCCAAAGGTGTACTCCAATAACGCATGGTATAACGTCATTGATGATGTCGACCCACATTATTTAAAGCATTTTAAAGAGCTGATGGGGGCCCAAAGAGACTGGCAAAGCAACACAAAATACGGAAAGCCAGTTCAAATTAAAGGGGGCATTCCCAGTATTTTCCTCTGCAATCCAGGGGCAACTTCATCATATAAGGAATTTCTAGACGAGGAAAAAAACAGAGCACTGAAGGCTTGGGCAGTAAAAAATGCGACCTTCGTCACCCTCACAGAGCCATTGTTCTCCAACGCCAATCAAGGTTCTCCACAAACAAGCCAAGAAGAAACCGATCAGGCGTAG |
|
Protein Sequence
|
MPRAGRFSIKAKNYFLTYPQCSLTKKEALSQLQNLQTPTNKKFIKICRELHEDGEHHLHVLIQFEGKYNCTNQRFFDLVSPTRSAHFHPNVQGAKSSSDVKSYIDKDGDTLEWGEFQIDGRSARGGCQTANDAAAEALNAGSTEAALAIIKEKLPKDYIFQYHNLKSNLDRIFQEPPEVYVSPFSSSSFTQVPDELEEWVADNIRDSAARPWRPKSIVLEGDSRTGKTVWARSLGPHNYLCGHLDLSPKVYSNNAWYNVIDDVDPHYLKHFKELMGAQRDWQSNTKYGKPVQIKGGIPSIFLCNPGATSSYKEFLDEEKNRALKAWAVKNATFVTLTEPLFSNANQGSPQTSQEETDQA |
|
NCBI Accession
|
NP_958321.1
|
|
Location
|
2197-2454 |
|
Gene Name
|
C4 |
|
Protein Name
|
C4 protein |
|
Coding Region
|
ATGGGGAACATCATCTCCACGTGCTTATCCAATTCGAGGGTAAATACAACTGCACAAATCAACGATTCTTCGACCTGGTATCCCCAACCCGGTCAGCACATTTCCATCCGAATGTACAGGGAGCTAAATCCAGCTCCGACGTCAAGTCCTATATCGATAAGGACGGAGACACTCTCGAATGGGGAGAATTCCAAATTGACGGCAGATCTGCTAGAGGAGGCTGCCAAACAGCTAACGACGCAGCCGCCGAGGCATTAA |
|
Protein Sequence
|
MGNIISTCLSNSRVNTTAQINDSSTWYPQPGQHISIRMYRELNPAPTSSPISIRTETLSNGENSKLTADLLEEAAKQLTTQPPRH |