Tomato leaf curl Mahe virus
Basic Information
Genomic Organization
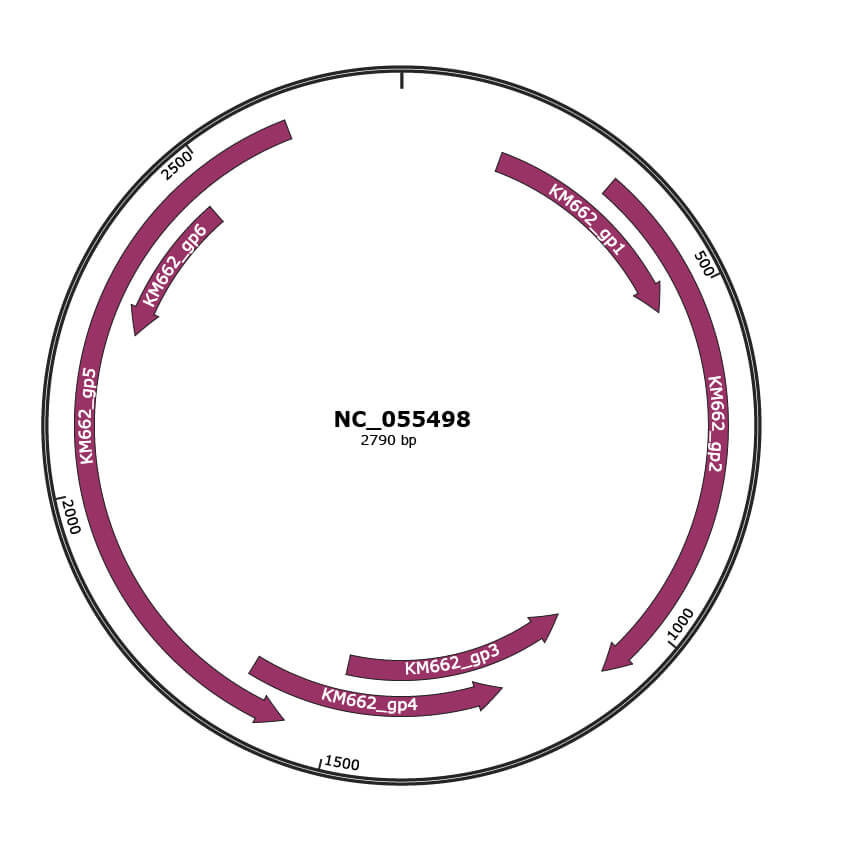
JBrowse
Genome
ACCGGATGGCCGCGCCCCCAAAAAAAGAAGTGGGCCCCGTGCACTAAGAGGGCCCCGCGCACTACCTCTATCGGCCAATCAGATAGGCGAGTCATAGCTTAGTTATTTGAATGGTTGTCTTTATATACTTGCTGGCGAAGTAGTTGGCTTTGTCAGTATGTGGGACCCACTTTTAAACGAGTTCCCAGACTCTGTTCACGGGTTCCGTTGTATGCTTGCTATTAAATATTTGCAGGCCGTGGAAGAAACTTACGAGCCCAACACACTGGGTTACGATCTAATCCGTGATCTTTTCGGTGTTATTAGGGCCCGTGATTATGTCCAAGCGACCCGGAGATATAATCATTTCCACACCCGTCTCGAAGGTTCGTCGAAGGCTGAACTTCGACAGCCCTTACACGAACCGTGCTGCTGCCCCCACTGTCCGCGTCACCAGAAGCAGAATATGGGCCAACAGGCCCATTTATCGGAAGCCCAGGATGTACAGAATGTATCGAAGCCCAGATGTCCCTAAGGGCTGTGAAGGCCCATGTAAGGTCCAATCGTATGAGCAGAGGGATGATGTCAAGCATACCGGTATTGTTCGTTGTGTTAGTGATGTTACCCGTGGGTCGGGTATTACTCATAGAGTTGGCAAGAGGTTTTGTGTTAAGTCTATATACATTTTAGGTAAGATCTGGATGGATGATAATATCAAAAAGCAGAATCATACTAATCAGGTTATGTTTTTCCTTGTTCGTGATAGAAGGCCCTATGGCTTGTCCCCAATGGATTTTGGACAGGTGTTCAACATGTTTGATAATGAGCCCAGTACAGCTACCGTGAAGAATGATTTGAGAGACAGATATCAGGTCATGAGGAAATTTCATGCAACTGTTGTTGGTGGGCCCTCAGGGATGAAGGAACAGGCATTAGTTAAGAGATTTTTTAGGATTAATAGCCACGTAACATATAATCATCAGGAGGCAGCTAAATACGAGAATCATACTGAGAATGCTTTGTTGTTGTATATGGCATGTACTCATGCTTCTAATCCAGTGTATGCTACTCTTAAGATACGGATCTATTTCTATGATTCGATCGGTAATTAATAAATATTAAATTTTATTTCATGGTTCTCCGTAACTTGGAGTGTATTTACAAATACATCGTGTAATACATAATCAACTGCTCTAATTATTGCATTAATTGAAATGACACCTAAAGAATCTAAATACTTGAGAACTTGGGTCCTAAATACGCTTAAGAAACGACCAGTCTGAGGGCGTAAGCTCGTCCAGACCTTGAAGTTCAGAAAACACTTGTGAATCTCCAACACCTTCCTTAGGTTGTGGTTGAACCGTATCTGGATTGATATGATGTCGTGGTTCGTGTTGAATGCCCGGCTGTCGTGATTGATTATCTTGAAATAGAGGGGATTTTGTATCTCCCAGATAAACACGCCACTCTGTGCTTGAGCTGCAGTAATGAGTTCCCCGGTGCGTAAATCCATAGTTCGCACAGTTAACGTGAATATAGTATGAGCAGCCGCAGCCTAGGTCTATGCGCTTACGTCGGATGGCTCTAGTCTTCGCTATGCGGTGTTGGACCTTGATTGGTATTTGTGAACAATGGCTTGTGGAGGGAGACGAAGGTTGCATTCTTGATGGCCCAGTCTTTTAGTTGTGTATGTTTCTCCTCGTCTAGATATTCTTTATACGAGGATGTTGGTCCTGGATTGCAGAGGAAGATAGTGGGAATTCCGCCTTTAATTTGAATGGGCTTCCCGTACTTGGTGTTGCTTTGCCAGTCCCTCTGGGCCCCCATGAATTCTTTAAAATGCTTTAGATAATGCGGGTCTACGTCATCAATGACGTTGTACCACGCATCATTGCTGTACACCTTTGGACTCAGGTCAAGATGACCACACAAATAGTTGTGGGGTCCTAATGACCTGGCCCACATCGTCTTGCCGGTTCGACTATCACCCTCAATAACAATACTAATCGGTCTCCACGGCCGCGCAGCGGCATCCATGACATTCTCAGCCACCCATACTTCAAGTTCGTCCGGAACCTGATTAAAAGAAGAAGAAAGAAAAGGAGAAACATAAGGAGCCGGAGGCTCCTGAAAAATCCTATTTGCGTTAGCAGATATATTATGGAACTGTAAAAAAAAGGACTTGGGATCTTTTTCTTTAATTATTTGAAGAGCTTCTGATTTAGAAGAAGCGTTCAATGCGTCTGCATATACTTCGGCTAAATGCTGGCCCTCCCCCCTTGCACTTCTGGCATCGACCTGGAAAATTCCATCGTCAAGAAATTCCCCTCCCTTTTCAATGTAGGCTTTGACATCGGACGATGATTTAGCTCCCTGAATGTTCGGATGGAAATGTGTTGATCTGGAAGGGGAAATGAGATCGAAGAATCTCTGGTTTGTACATTGGAACTTGCCTTCGAATTGGATGAGAACATGGAGATGAGGCACCCCATCCTGATGTAGTTCTCTGCAAACCCTAATGAATTTGATATTCGTCGGGTAAGAAAGCGTTTTCAATTGGGAAAGGGCCTCTTCCTTTGTTAATGAGCATTTGGGATAGGTGATGAAATAATTTTTGGCATGTATTTGAAAACGACCTGCTCTTGGCATATTTTCTGTCGTTTTGGATTGGTGGACACTCAAAACTCCATGATAACGGTGGAATGGTGGGCAATATATATGATGTCCACCAATGGCATATGTGTAAATAGGTAGACTTCCATTTGAAATTTGTAATTTCAAAATTCCCAAAGCGGCCATCCGTATAATATT
Gene Information
|
NCBI Accession
|
YP_010086863.1
|
|
Location
|
158-514 |
|
Protein Name
|
movement protein |
|
Coding Region
|
ATGTGGGACCCACTTTTAAACGAGTTCCCAGACTCTGTTCACGGGTTCCGTTGTATGCTTGCTATTAAATATTTGCAGGCCGTGGAAGAAACTTACGAGCCCAACACACTGGGTTACGATCTAATCCGTGATCTTTTCGGTGTTATTAGGGCCCGTGATTATGTCCAAGCGACCCGGAGATATAATCATTTCCACACCCGTCTCGAAGGTTCGTCGAAGGCTGAACTTCGACAGCCCTTACACGAACCGTGCTGCTGCCCCCACTGTCCGCGTCACCAGAAGCAGAATATGGGCCAACAGGCCCATTTATCGGAAGCCCAGGATGTACAGAATGTATCGAAGCCCAGATGTCCCTAA |
|
Protein Sequence
|
MWDPLLNEFPDSVHGFRCMLAIKYLQAVEETYEPNTLGYDLIRDLFGVIRARDYVQATRRYNHFHTRLEGSSKAELRQPLHEPCCCPHCPRHQKQNMGQQAHLSEAQDVQNVSKPRCP |
|
NCBI Accession
|
YP_010086864.1
|
|
Location
|
318-1091 |
|
Protein Name
|
capsid protein |
|
Coding Region
|
ATGTCCAAGCGACCCGGAGATATAATCATTTCCACACCCGTCTCGAAGGTTCGTCGAAGGCTGAACTTCGACAGCCCTTACACGAACCGTGCTGCTGCCCCCACTGTCCGCGTCACCAGAAGCAGAATATGGGCCAACAGGCCCATTTATCGGAAGCCCAGGATGTACAGAATGTATCGAAGCCCAGATGTCCCTAAGGGCTGTGAAGGCCCATGTAAGGTCCAATCGTATGAGCAGAGGGATGATGTCAAGCATACCGGTATTGTTCGTTGTGTTAGTGATGTTACCCGTGGGTCGGGTATTACTCATAGAGTTGGCAAGAGGTTTTGTGTTAAGTCTATATACATTTTAGGTAAGATCTGGATGGATGATAATATCAAAAAGCAGAATCATACTAATCAGGTTATGTTTTTCCTTGTTCGTGATAGAAGGCCCTATGGCTTGTCCCCAATGGATTTTGGACAGGTGTTCAACATGTTTGATAATGAGCCCAGTACAGCTACCGTGAAGAATGATTTGAGAGACAGATATCAGGTCATGAGGAAATTTCATGCAACTGTTGTTGGTGGGCCCTCAGGGATGAAGGAACAGGCATTAGTTAAGAGATTTTTTAGGATTAATAGCCACGTAACATATAATCATCAGGAGGCAGCTAAATACGAGAATCATACTGAGAATGCTTTGTTGTTGTATATGGCATGTACTCATGCTTCTAATCCAGTGTATGCTACTCTTAAGATACGGATCTATTTCTATGATTCGATCGGTAATTAA |
|
Protein Sequence
|
MSKRPGDIIISTPVSKVRRRLNFDSPYTNRAAAPTVRVTRSRIWANRPIYRKPRMYRMYRSPDVPKGCEGPCKVQSYEQRDDVKHTGIVRCVSDVTRGSGITHRVGKRFCVKSIYILGKIWMDDNIKKQNHTNQVMFFLVRDRRPYGLSPMDFGQVFNMFDNEPSTATVKNDLRDRYQVMRKFHATVVGGPSGMKEQALVKRFFRINSHVTYNHQEAAKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSIGN |
|
NCBI Accession
|
YP_010086865.1
|
|
Location
|
1088-1492 |
|
Protein Name
|
replication enhancer protein |
|
Coding Region
|
ATGGATTTACGCACCGGGGAACTCATTACTGCAGCTCAAGCACAGAGTGGCGTGTTTATCTGGGAGATACAAAATCCCCTCTATTTCAAGATAATCAATCACGACAGCCGGGCATTCAACACGAACCACGACATCATATCAATCCAGATACGGTTCAACCACAACCTAAGGAAGGTGTTGGAGATTCACAAGTGTTTTCTGAACTTCAAGGTCTGGACGAGCTTACGCCCTCAGACTGGTCGTTTCTTAAGCGTATTTAGGACCCAAGTTCTCAAGTATTTAGATTCTTTAGGTGTCATTTCAATTAATGCAATAATTAGAGCAGTTGATTATGTATTACACGATGTATTTGTAAATACACTCCAAGTTACGGAGAACCATGAAATAAAATTTAATATTTATTAA |
|
Protein Sequence
|
MDLRTGELITAAQAQSGVFIWEIQNPLYFKIINHDSRAFNTNHDIISIQIRFNHNLRKVLEIHKCFLNFKVWTSLRPQTGRFLSVFRTQVLKYLDSLGVISINAIIRAVDYVLHDVFVNTLQVTENHEIKFNIY |
|
NCBI Accession
|
YP_010086866.1
|
|
Location
|
1233-1640 |
|
Protein Name
|
transcriptional activator protein |
|
Coding Region
|
ATGCAACCTTCGTCTCCCTCCACAAGCCATTGTTCACAAATACCAATCAAGGTCCAACACCGCATAGCGAAGACTAGAGCCATCCGACGTAAGCGCATAGACCTAGGCTGCGGCTGCTCATACTATATTCACGTTAACTGTGCGAACTATGGATTTACGCACCGGGGAACTCATTACTGCAGCTCAAGCACAGAGTGGCGTGTTTATCTGGGAGATACAAAATCCCCTCTATTTCAAGATAATCAATCACGACAGCCGGGCATTCAACACGAACCACGACATCATATCAATCCAGATACGGTTCAACCACAACCTAAGGAAGGTGTTGGAGATTCACAAGTGTTTTCTGAACTTCAAGGTCTGGACGAGCTTACGCCCTCAGACTGGTCGTTTCTTAAGCGTATTTAG |
|
Protein Sequence
|
MQPSSPSTSHCSQIPIKVQHRIAKTRAIRRKRIDLGCGCSYYIHVNCANYGFTHRGTHYCSSSTEWRVYLGDTKSPLFQDNQSRQPGIQHEPRHHINPDTVQPQPKEGVGDSQVFSELQGLDELTPSDWSFLKRI |
|
NCBI Accession
|
YP_010086867.1
|
|
Location
|
1564-2628 |
|
Protein Name
|
replication associated protein |
|
Coding Region
|
ATGCCAAGAGCAGGTCGTTTTCAAATACATGCCAAAAATTATTTCATCACCTATCCCAAATGCTCATTAACAAAGGAAGAGGCCCTTTCCCAATTGAAAACGCTTTCTTACCCGACGAATATCAAATTCATTAGGGTTTGCAGAGAACTACATCAGGATGGGGTGCCTCATCTCCATGTTCTCATCCAATTCGAAGGCAAGTTCCAATGTACAAACCAGAGATTCTTCGATCTCATTTCCCCTTCCAGATCAACACATTTCCATCCGAACATTCAGGGAGCTAAATCATCGTCCGATGTCAAAGCCTACATTGAAAAGGGAGGGGAATTTCTTGACGATGGAATTTTCCAGGTCGATGCCAGAAGTGCAAGGGGGGAGGGCCAGCATTTAGCCGAAGTATATGCAGACGCATTGAACGCTTCTTCTAAATCAGAAGCTCTTCAAATAATTAAAGAAAAAGATCCCAAGTCCTTTTTTTTACAGTTCCATAATATATCTGCTAACGCAAATAGGATTTTTCAGGAGCCTCCGGCTCCTTATGTTTCTCCTTTTCTTTCTTCTTCTTTTAATCAGGTTCCGGACGAACTTGAAGTATGGGTGGCTGAGAATGTCATGGATGCCGCTGCGCGGCCGTGGAGACCGATTAGTATTGTTATTGAGGGTGATAGTCGAACCGGCAAGACGATGTGGGCCAGGTCATTAGGACCCCACAACTATTTGTGTGGTCATCTTGACCTGAGTCCAAAGGTGTACAGCAATGATGCGTGGTACAACGTCATTGATGACGTAGACCCGCATTATCTAAAGCATTTTAAAGAATTCATGGGGGCCCAGAGGGACTGGCAAAGCAACACCAAGTACGGGAAGCCCATTCAAATTAAAGGCGGAATTCCCACTATCTTCCTCTGCAATCCAGGACCAACATCCTCGTATAAAGAATATCTAGACGAGGAGAAACATACACAACTAAAAGACTGGGCCATCAAGAATGCAACCTTCGTCTCCCTCCACAAGCCATTGTTCACAAATACCAATCAAGGTCCAACACCGCATAGCGAAGACTAG |
|
Protein Sequence
|
MPRAGRFQIHAKNYFITYPKCSLTKEEALSQLKTLSYPTNIKFIRVCRELHQDGVPHLHVLIQFEGKFQCTNQRFFDLISPSRSTHFHPNIQGAKSSSDVKAYIEKGGEFLDDGIFQVDARSARGEGQHLAEVYADALNASSKSEALQIIKEKDPKSFFLQFHNISANANRIFQEPPAPYVSPFLSSSFNQVPDELEVWVAENVMDAAARPWRPISIVIEGDSRTGKTMWARSLGPHNYLCGHLDLSPKVYSNDAWYNVIDDVDPHYLKHFKEFMGAQRDWQSNTKYGKPIQIKGGIPTIFLCNPGPTSSYKEYLDEEKHTQLKDWAIKNATFVSLHKPLFTNTNQGPTPHSED |
|
NCBI Accession
|
YP_010086868.1
|
|
Location
|
2238-2471 |
|
Protein Name
|
C4 protein |
|
Coding Region
|
ATGGGGTGCCTCATCTCCATGTTCTCATCCAATTCGAAGGCAAGTTCCAATGTACAAACCAGAGATTCTTCGATCTCATTTCCCCTTCCAGATCAACACATTTCCATCCGAACATTCAGGGAGCTAAATCATCGTCCGATGTCAAAGCCTACATTGAAAAGGGAGGGGAATTTCTTGACGATGGAATTTTCCAGGTCGATGCCAGAAGTGCAAGGGGGGAGGGCCAGCATTTAG |
|
Protein Sequence
|
MGCLISMFSSNSKASSNVQTRDSSISFPLPDQHISIRTFRELNHRPMSKPTLKREGNFLTMEFSRSMPEVQGGRASI |