Tomato leaf curl Madagascar virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_000857385.1 |
| Isolate |
Madagascar:Morondova,2001 |
| Release date |
2015/2/13 |
| Submitter |
Delatte,H., Martin,D.P., Naze,F., Goldbach,R., Reynaud,B., Peterschmitt,M., Lett,J.M. |
| Host |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
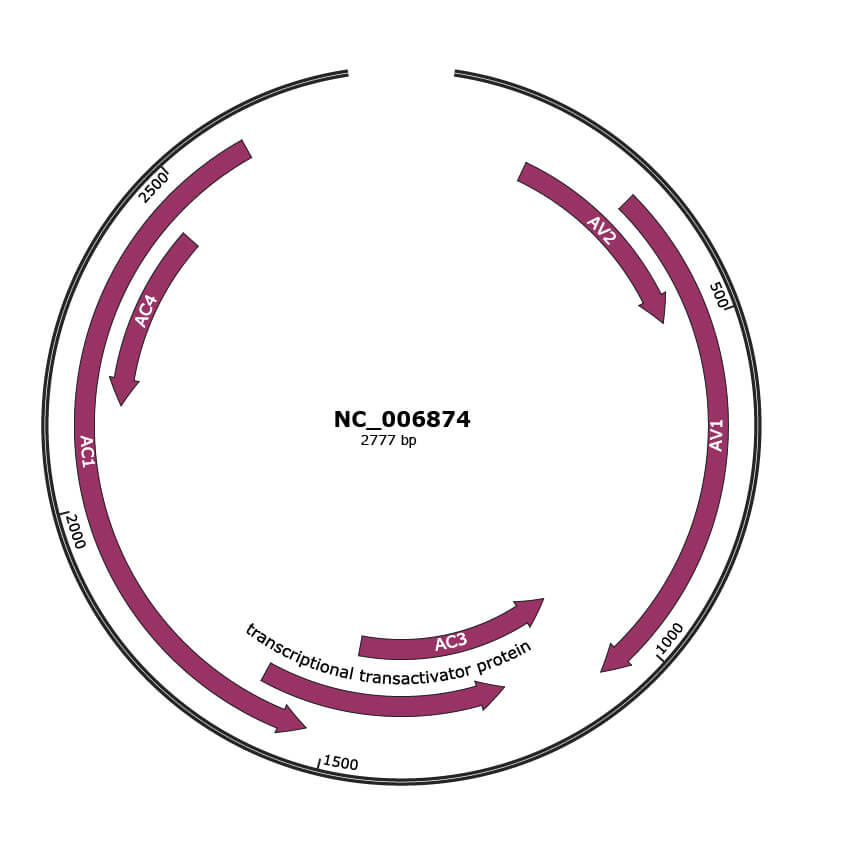
JBrowse
Genome
ACCGGATGGCCGCGCCCCCGAAAAAGAAGTGGTCCCCCCCACTATACTATGTCGTCCAATGAAATTGTGTCCTGGAAGGTTATTTATTGGGTTTTGTCCTTATATACTTGGCCGCTAAGTTTGTGGGCCTGTCACAATGTGGGATCCATTGTTAAATGAGTTCCCTGATTCTGTTCATGGTTTTCGTTGTATGCTTGCTGTAAAATATTTGCAGGCCGTTGAGGAAACGTATGAGCCCAACACTTTGGGCCACGATTTAATTCGCGATCTTATCTCTGTTATTAGGGCTCGTGACTATGTCGAAGCGACCCGGCGATATAATCATTTCCACGCCCGTCTCGAAGGTTCGTCGAAGGCTGAACTTCGACAGCCCATATACCAACCGTGTTGCTGTCCCCATTGCCCCCGCCACAAACAGGCGTCGGTCATGGACTTACCGGCCCATGTACCGAAAGCCCAGGATGTACAGAATGTACAGAAGCCCTGATGTTCCTAAGGGCTGTGAAGGCCCATGTAAGGTCCAGTCATTTGAGCAAAGGGATGATGTGAAGCATACGGGTATTGCTCGCTGTGTTAGCGATGTGACGCGTGGTTCGGGTATCACTCATAGGGTTGGTAAGAGATTTTGTATTAAGTCCATTTACATTTTAGGTAAAGTATGGATGGATGAAAATATAAAGAAGCAGAATCACACGAACAACGTGATGTTCTTCTTGGTCCGAGATCGCAGGCCCAGTGGATCAGCGCCCATGGACTTTGGGCAGGTGTTTAACATGTTTGACAATGAGCCCAGTACTGCGACTGTGAAGAATGATTTGCGAGATAGGTTACAGGTTTTGCGCAAGTTTCATGCTACCGTTGTTGGTGGTCCTTCTGGGATGAAGGAACAGGCTTTAGTTAAGAGATTTTATAGGATTAATAATCATGTAGTTTATAATCACCAGGAGGCAGCGAAGTATGAAAATCATACTGAGAATGCGTTGTTGTTGTATATGGCTTGTACTCATTATTCCAATCCCGTGTACGCTACATTGAAAATACGCATCTATTTCTATGATGCAGTGACAAATTAATAAATATTAAATTTTATTTCATGATCCTCCAAAACCTGGAGTGTATTTACAAGTACATCATACAATACATGATCAACTGCCCTAATTACAGTATTAATTGAAATAACACCTAATCTATCTAAATATCTGAGGACCTGAATTCTAAATACCCTTAAGAAACGACCAGTCTGAGGCCGTAAGGTCGTCCAGACCTTGAAGTTGAGAAAACATTTGTGAATCCCCAGTTCCTTCCTGAGGTTGTGGTTGAATCTTATCTGGATGTTGATGATGTCGTGGTTCATGTTGAATGGCCTTATTTCGTGGCTGGTGATCGTGAAATAGAGGGGATTGTTTATCTCCCAGATAAACACGCCATTCTGTGCCTGAGGAGCAGTGATGAGTTCCCCTGTGCGTGAATCCATGGTTGGAGCAGTCGATGTGGAGATAATATGAGCAGCCGCAGTCTAGGTCAACCCGTTTACGCCGTATGGTTCTCTTCTTCGCTATACGGTGTTGGACCTTGATTGGCACTTGTGAACAATGGCTCGTGGAGGGTGACGAAGGTCGCATTCTTAATTGCCCACTGCTTGAGTGCTGCGTTCCTTTCCTCGTCCAGAAATTCTTTATAGGACGACGTTGGGCCTGGATTGCATAGGAAGATTGTGGGAATTCCGCCTTTAATTTGAATTGGCTTCCCGTACTTTGTGTTGCTTTGCCAGTCCCTCTGCGCTCCCATAAATTCCTTAAAGTGCTTTAGATAATGCGGGTCTACGTCATCAATGACGTTGTACCACGCATCATTGCTGTACACCTTTGGGCTGAGATCAAGATGGCCACATAAATAGTTATGTGGTCCCAATGACCTGGCCCACATTGTCTTTCCGGTACGACTATCACCCTCGATTACAATACTATTCGGTCTCCACGGCCGCGCAGCGGCATCCATCACGTTCTCACTCACCCACTCTTCAAGTTCTTCCGGAACTTGATTAAAAGAAGAAGATAAAAAAGGAGAAACATAAGGAGCCGGAGGCTCCTGAAAAATCCTATCTAAATTACTATTTAAATTATGAAATTGTAAAACAAAATCCTTAGGGGCTAATTCCTTAATGACTCTAAGAGCCTCTGACTTACTGCCTGCGTTAAGAGCTGCGGCGTAAGCGTCATTGGCTGATTGTTGCCCTCCCCTTGCAGATCTGCCATCAATTTGAAATTCTCCCCATTCGATGGTGTCTCCGTCCTTGTCGATATAGGACTTGACGTCGGAGCTGGATTTAGCTCCCTGAATGTTCGGATGGAAATGTGCTGACCTGGTTGGGGATACCAGGTCGAAGAATCTCTGATTCGTGCACTGGTACTTACCTTCGAATTGGATAAGCACATGGAGGTGAGGTTCCCCATTCTCGTGAAGCTCTCTGCAAATTTTGATGAACAGTTTATTTACTGGGGTTTGTAGGGATTGTATTTGGGAAAGTGTTTCCTCTTTGGTGAGAGAGCACTTTGGATAAGTGAGGAAATAATTTTTTGCGCAAATTTTAAATCGACGTAGAGGAGCCATTTAGTCAATGTACTCCGATTGACCACTAATTCATTTGCTGTCTGCAATCGGAGTATTGGTGGCCAATATATAGGTGTACTCCAAATGGCATTATGGTAAATAGCTAAAGTTTTTTAATTTTGAAATTCAAAATTTGAAATTCTAAAAGCGGCCATCCGTATAATATT
Gene Information
|
NCBI Accession
|
YP_213931.1
|
|
Location
|
137-487 |
|
Gene Name
|
AV2 |
|
Protein Name
|
putative AV2 protein |
|
Coding Region
|
ATGTGGGATCCATTGTTAAATGAGTTCCCTGATTCTGTTCATGGTTTTCGTTGTATGCTTGCTGTAAAATATTTGCAGGCCGTTGAGGAAACGTATGAGCCCAACACTTTGGGCCACGATTTAATTCGCGATCTTATCTCTGTTATTAGGGCTCGTGACTATGTCGAAGCGACCCGGCGATATAATCATTTCCACGCCCGTCTCGAAGGTTCGTCGAAGGCTGAACTTCGACAGCCCATATACCAACCGTGTTGCTGTCCCCATTGCCCCCGCCACAAACAGGCGTCGGTCATGGACTTACCGGCCCATGTACCGAAAGCCCAGGATGTACAGAATGTACAGAAGCCCTGA |
|
Protein Sequence
|
MWDPLLNEFPDSVHGFRCMLAVKYLQAVEETYEPNTLGHDLIRDLISVIRARDYVEATRRYNHFHARLEGSSKAELRQPIYQPCCCPHCPRHKQASVMDLPAHVPKAQDVQNVQKP |
|
NCBI Accession
|
YP_213932.1
|
|
Location
|
297-1073 |
|
Gene Name
|
AV1 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGTCGAAGCGACCCGGCGATATAATCATTTCCACGCCCGTCTCGAAGGTTCGTCGAAGGCTGAACTTCGACAGCCCATATACCAACCGTGTTGCTGTCCCCATTGCCCCCGCCACAAACAGGCGTCGGTCATGGACTTACCGGCCCATGTACCGAAAGCCCAGGATGTACAGAATGTACAGAAGCCCTGATGTTCCTAAGGGCTGTGAAGGCCCATGTAAGGTCCAGTCATTTGAGCAAAGGGATGATGTGAAGCATACGGGTATTGCTCGCTGTGTTAGCGATGTGACGCGTGGTTCGGGTATCACTCATAGGGTTGGTAAGAGATTTTGTATTAAGTCCATTTACATTTTAGGTAAAGTATGGATGGATGAAAATATAAAGAAGCAGAATCACACGAACAACGTGATGTTCTTCTTGGTCCGAGATCGCAGGCCCAGTGGATCAGCGCCCATGGACTTTGGGCAGGTGTTTAACATGTTTGACAATGAGCCCAGTACTGCGACTGTGAAGAATGATTTGCGAGATAGGTTACAGGTTTTGCGCAAGTTTCATGCTACCGTTGTTGGTGGTCCTTCTGGGATGAAGGAACAGGCTTTAGTTAAGAGATTTTATAGGATTAATAATCATGTAGTTTATAATCACCAGGAGGCAGCGAAGTATGAAAATCATACTGAGAATGCGTTGTTGTTGTATATGGCTTGTACTCATTATTCCAATCCCGTGTACGCTACATTGAAAATACGCATCTATTTCTATGATGCAGTGACAAATTAA |
|
Protein Sequence
|
MSKRPGDIIISTPVSKVRRRLNFDSPYTNRVAVPIAPATNRRRSWTYRPMYRKPRMYRMYRSPDVPKGCEGPCKVQSFEQRDDVKHTGIARCVSDVTRGSGITHRVGKRFCIKSIYILGKVWMDENIKKQNHTNNVMFFLVRDRRPSGSAPMDFGQVFNMFDNEPSTATVKNDLRDRLQVLRKFHATVVGGPSGMKEQALVKRFYRINNHVVYNHQEAAKYENHTENALLLYMACTHYSNPVYATLKIRIYFYDAVTN |
|
NCBI Accession
|
YP_213933.1
|
|
Location
|
1070-1474 |
|
Gene Name
|
AC3 |
|
Protein Name
|
replication enhancer protein |
|
Coding Region
|
ATGGATTCACGCACAGGGGAACTCATCACTGCTCCTCAGGCACAGAATGGCGTGTTTATCTGGGAGATAAACAATCCCCTCTATTTCACGATCACCAGCCACGAAATAAGGCCATTCAACATGAACCACGACATCATCAACATCCAGATAAGATTCAACCACAACCTCAGGAAGGAACTGGGGATTCACAAATGTTTTCTCAACTTCAAGGTCTGGACGACCTTACGGCCTCAGACTGGTCGTTTCTTAAGGGTATTTAGAATTCAGGTCCTCAGATATTTAGATAGATTAGGTGTTATTTCAATTAATACTGTAATTAGGGCAGTTGATCATGTATTGTATGATGTACTTGTAAATACACTCCAGGTTTTGGAGGATCATGAAATAAAATTTAATATTTATTAA |
|
Protein Sequence
|
MDSRTGELITAPQAQNGVFIWEINNPLYFTITSHEIRPFNMNHDIINIQIRFNHNLRKELGIHKCFLNFKVWTTLRPQTGRFLRVFRIQVLRYLDRLGVISINTVIRAVDHVLYDVLVNTLQVLEDHEIKFNIY |
|
NCBI Accession
|
YP_213934.1
|
|
Location
|
1215-1622 |
|
Gene Name
|
transcriptional transactivator protein |
|
Protein Name
|
AC2 |
|
Coding Region
|
ATGCGACCTTCGTCACCCTCCACGAGCCATTGTTCACAAGTGCCAATCAAGGTCCAACACCGTATAGCGAAGAAGAGAACCATACGGCGTAAACGGGTTGACCTAGACTGCGGCTGCTCATATTATCTCCACATCGACTGCTCCAACCATGGATTCACGCACAGGGGAACTCATCACTGCTCCTCAGGCACAGAATGGCGTGTTTATCTGGGAGATAAACAATCCCCTCTATTTCACGATCACCAGCCACGAAATAAGGCCATTCAACATGAACCACGACATCATCAACATCCAGATAAGATTCAACCACAACCTCAGGAAGGAACTGGGGATTCACAAATGTTTTCTCAACTTCAAGGTCTGGACGACCTTACGGCCTCAGACTGGTCGTTTCTTAAGGGTATTTAG |
|
Protein Sequence
|
MRPSSPSTSHCSQVPIKVQHRIAKKRTIRRKRVDLDCGCSYYLHIDCSNHGFTHRGTHHCSSGTEWRVYLGDKQSPLFHDHQPRNKAIQHEPRHHQHPDKIQPQPQEGTGDSQMFSQLQGLDDLTASDWSFLKGI |
|
NCBI Accession
|
YP_213935.1
|
|
Location
|
1531-2610 |
|
Gene Name
|
AC1 |
|
Protein Name
|
replication-associated protein |
|
Coding Region
|
ATGGCTCCTCTACGTCGATTTAAAATTTGCGCAAAAAATTATTTCCTCACTTATCCAAAGTGCTCTCTCACCAAAGAGGAAACACTTTCCCAAATACAATCCCTACAAACCCCAGTAAATAAACTGTTCATCAAAATTTGCAGAGAGCTTCACGAGAATGGGGAACCTCACCTCCATGTGCTTATCCAATTCGAAGGTAAGTACCAGTGCACGAATCAGAGATTCTTCGACCTGGTATCCCCAACCAGGTCAGCACATTTCCATCCGAACATTCAGGGAGCTAAATCCAGCTCCGACGTCAAGTCCTATATCGACAAGGACGGAGACACCATCGAATGGGGAGAATTTCAAATTGATGGCAGATCTGCAAGGGGAGGGCAACAATCAGCCAATGACGCTTACGCCGCAGCTCTTAACGCAGGCAGTAAGTCAGAGGCTCTTAGAGTCATTAAGGAATTAGCCCCTAAGGATTTTGTTTTACAATTTCATAATTTAAATAGTAATTTAGATAGGATTTTTCAGGAGCCTCCGGCTCCTTATGTTTCTCCTTTTTTATCTTCTTCTTTTAATCAAGTTCCGGAAGAACTTGAAGAGTGGGTGAGTGAGAACGTGATGGATGCCGCTGCGCGGCCGTGGAGACCGAATAGTATTGTAATCGAGGGTGATAGTCGTACCGGAAAGACAATGTGGGCCAGGTCATTGGGACCACATAACTATTTATGTGGCCATCTTGATCTCAGCCCAAAGGTGTACAGCAATGATGCGTGGTACAACGTCATTGATGACGTAGACCCGCATTATCTAAAGCACTTTAAGGAATTTATGGGAGCGCAGAGGGACTGGCAAAGCAACACAAAGTACGGGAAGCCAATTCAAATTAAAGGCGGAATTCCCACAATCTTCCTATGCAATCCAGGCCCAACGTCGTCCTATAAAGAATTTCTGGACGAGGAAAGGAACGCAGCACTCAAGCAGTGGGCAATTAAGAATGCGACCTTCGTCACCCTCCACGAGCCATTGTTCACAAGTGCCAATCAAGGTCCAACACCGTATAGCGAAGAAGAGAACCATACGGCGTAA |
|
Protein Sequence
|
MAPLRRFKICAKNYFLTYPKCSLTKEETLSQIQSLQTPVNKLFIKICRELHENGEPHLHVLIQFEGKYQCTNQRFFDLVSPTRSAHFHPNIQGAKSSSDVKSYIDKDGDTIEWGEFQIDGRSARGGQQSANDAYAAALNAGSKSEALRVIKELAPKDFVLQFHNLNSNLDRIFQEPPAPYVSPFLSSSFNQVPEELEEWVSENVMDAAARPWRPNSIVIEGDSRTGKTMWARSLGPHNYLCGHLDLSPKVYSNDAWYNVIDDVDPHYLKHFKEFMGAQRDWQSNTKYGKPIQIKGGIPTIFLCNPGPTSSYKEFLDEERNAALKQWAIKNATFVTLHEPLFTSANQGPTPYSEEENHTA |
|
NCBI Accession
|
YP_213936.1
|
|
Location
|
2151-2453 |
|
Gene Name
|
AC4 |
|
Protein Name
|
putative AC4 protein |
|
Coding Region
|
ATGGGGAACCTCACCTCCATGTGCTTATCCAATTCGAAGGTAAGTACCAGTGCACGAATCAGAGATTCTTCGACCTGGTATCCCCAACCAGGTCAGCACATTTCCATCCGAACATTCAGGGAGCTAAATCCAGCTCCGACGTCAAGTCCTATATCGACAAGGACGGAGACACCATCGAATGGGGAGAATTTCAAATTGATGGCAGATCTGCAAGGGGAGGGCAACAATCAGCCAATGACGCTTACGCCGCAGCTCTTAACGCAGGCAGTAAGTCAGAGGCTCTTAGAGTCATTAAGGAATTAG |
|
Protein Sequence
|
MGNLTSMCLSNSKVSTSARIRDSSTWYPQPGQHISIRTFRELNPAPTSSPISTRTETPSNGENFKLMADLQGEGNNQPMTLTPQLLTQAVSQRLLESLRN |