Tomato leaf curl Liwa virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_000915295.1 |
| Isolate |
Oman:Liwa |
| Release date |
2015/2/22 |
| Submitter |
Khan,A.J., Akhtar,S., Singh,A.K., Al-Shehi,A.A., Al-Matrushi,A.M., Ammara,U., Briddon,R.W. |
| Host |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
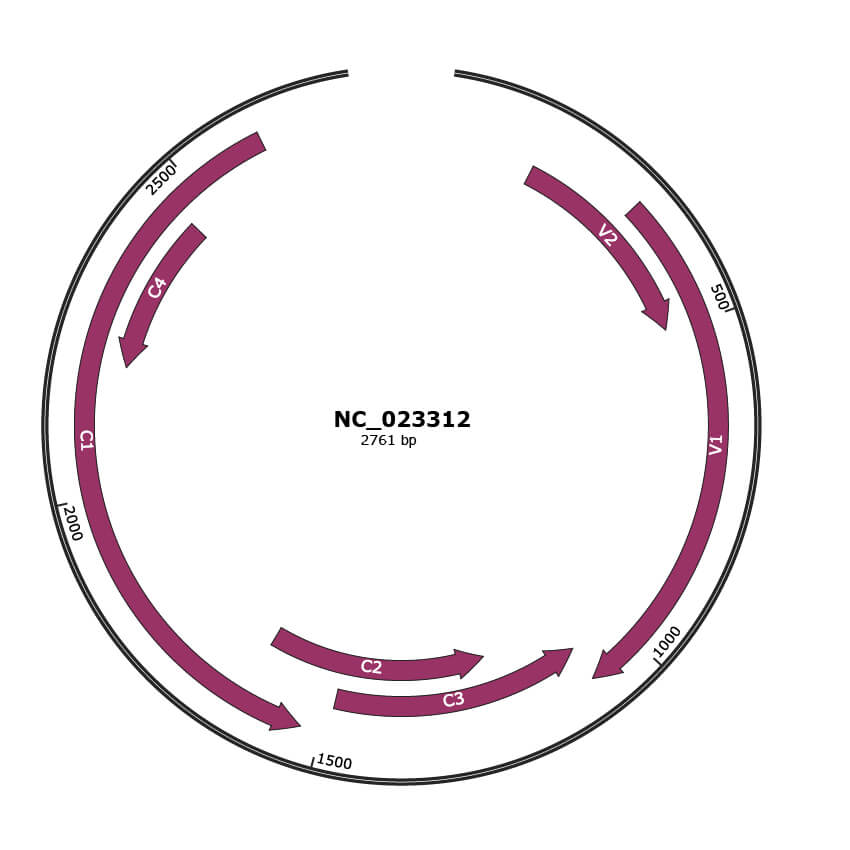
JBrowse
Genome
ACCGGATGGCCGCGATTTTTTTTACCGTGGACCCCGCGATGCACGTGCTGACAAATACATGTGGACCAATTAAAAACGTCCCTCAAAGCTTAATTGTTTCGTGGTCCCCTCTATAAACTTGGGCTCCAAGTAGTGGGCTTTTATCACAATGTGGGATCCTTTACTAAATGAGTTTCCCGAAAGTGTTCATGGGTTTAGGTGTATGTTAGCAGTGAAATATCTGCAATTAGTAGAAAATTCATATTCGCCAGACACATTAGGGTACGATTTAATCAGGGATTTAATCTCAGTTATTAGGGCTAGAAATTATGTCGAAGCGACCAGCAGATATAATCATTTCCACGCCCGCCTCGAAGGTACGCCGTCGTCTCAACTTCGACAGCCCATATGCCAGCCGTGCTGCTGCCCCCATTGTCCGCGTCACAAAGGCAAAGGCATGGGCCAACAGGCCCATGAATCGGAAGCCCAGGATGTACAGAATGTACAGAAGCCCTGATGTTCCGAGGGGATGTGAAGGCCCATGTAAAGTCCAGTCTTATGAGCAACGGGATGATATTAAGCATACTGGTATTGTTCGTTGTGTTAGTGATGTTACTCGTGGATCCGGAATTACCCACAGAGTGGGTAAGAGGTTCTGTGTTAAATCCATATATTTTTTAGGTAAAGTTTGGATGGATGAAAATATCAAGAAGCAGAATCACACTAATCAGGTCATGTTCTTCTTGGTCCGTGATAGAAGGCCCTATGGAAGCAGCCCAATGGATTTTGGGCAGGTTTTTAATATGTTCGACAACGAACCTAGCACCGCAACCGTGAAGAATGATCTCCGGGATAGGTTTCAAGTGATGAGGAAATTTCATGCTACAGTTATCGGTGGGCCCTCTGGAATGAAGGAACAGGCATTAGTTAAGAGATTTTTTAGAATTAACAGTCATGTAACTTATAATCATCAGGAGGCAGCCAAGTATGAGAATCATACTGAGAATGCTTTGTTGTTGTATATGGCATGTACTCATGCCTCTAACCCTGTGTATGCTACATTGAAGATACGTATCTATTTCTATGATTCAGTATCGAATTAATAAAGATTATATTTTATTGAATATGATTGGTTTACATATACAACGTGATCTAATACATTCCATAATACATGATCAACTGCTCTATTTACATTGTTAATACTAATTACAGCAAAATTATTAAGCACTTTGAATACTTGGGTTTTAAATACCCTTAAGAAATGACCAGTCTGAGGCTGTAAGGTCGTCCAGATTCGGTAGGTTAGAAAACATTTGTGCATCCCCAACGCTTTCCTCAGGTTGTGATTGAACCGTATCTGCACTGTGATGATGTCTTGGCTTCTCAGGAATGGCCTGTTGTGGTGCTCTGTTATCTTGAAATACAGGGGATTTGTTATCTCCCAGATAAACACGCCATTCTCTGCTTGAGCTGCAGTGATGGGTTCCCCTGTGCGTGAATCCATAGCCATGGCAACGTAATGCGATGAAATATGAACAGCCGCAATCGAGGTCAACGCGACGACGCCTGGTCCCCTTCTTGGCCAACCTGTGCTGCACTTTGATTGGAACCTGAGTAGAGTGGGCCTGTGAGGGTGATGAAGGTCGCATTCTTTAAAGCCCAATGTTTGAGTGCGGAATTCTTTTCTTCATCCAAGAACTCTTTATAGCTGGAATTGGGTCCTGGATTGCAGAGGAAGATAGCGGGAATTCCACCTTTAATTTGAACTGGCTTTCCGTATTTTGTATTTGATTGCCAGTCCCTTTGGGCCCCCATGAATTCTTTAAAGTGTTTTAGATAATGCGGGTCGACGTCATCAATGACGTTATACGAGGCATCATTGCTGTACACTTTAGGGCTAAGGTCTAAGTGACCACATAGGTAGTTATGTGGACCCAACGACCTAGCCCACATGGTCTTCCCGGTTCGACTATCACCCTCAATCACAATACTCATGGGCCTCAAAGGCCGCGCAGCGGCACCCACCACGTTCACAGAAGCCCATTCCTCAAGTTCATCAGGAACTTGATTAAAAGATGAAGACAAAAAGGGAGAAACATAAACCTCCACAGGAGGTGTAAAAATCCTATCTAAATTACATTTTAAATTATGATATTGAAAAATAAAATCTTTTGGGAGTTTTTCCCTTATTATTGATAAAGCCTCTTCAGCCGAACCTGCATTTAGGGCCTCTGCTGCTGCATCATTAGCTGTCTGTTGACCTCCTCGAGCAGATCTTCCATCGATCTGAAACTGACCCCAGTCGATGTAATCACCGTCCTTCTCGATGTAGGACTTGACATCGGAGCTGGACTTTGCTCCCTGGAAGTTTGGGTGGAATTGGGAGGAGTTATTAGGGTGAGTGACATCGAAATGTCTGGGGTTTCTGAACTTGGCTTTACCTTTGAACTGGATGAGGGCGTGGATATGCAGAGACCCATCTTGGGTGTTTTTCTTGTGACACTCTGATAAATAATTTATCAGATAGGGCAATTTATTGACTGGAAGAATTTCGAGCATGTGCTCTTTGGGTATGTGGCATTTTGGATAAGTGAGGAAAATATTTTTGGCATTTACACAAAAAGAGTTAATACGAGGCATATTGAATTGGGGACACTCAAAACTCTGAGGAATGGGGGACTCTGGGGACGCATTTATATGAAGTCCCCAAATGGCATTTTCGTAATTACGAAAGAAAATTCAAAATACTAACGCTCCAAAAAGCGGCCATCCGTATAATATT
Gene Information
|
NCBI Accession
|
YP_008997810.1
|
|
Location
|
149-496 |
|
Gene Name
|
V2 |
|
Protein Name
|
Pre-coat protein |
|
Coding Region
|
ATGTGGGATCCTTTACTAAATGAGTTTCCCGAAAGTGTTCATGGGTTTAGGTGTATGTTAGCAGTGAAATATCTGCAATTAGTAGAAAATTCATATTCGCCAGACACATTAGGGTACGATTTAATCAGGGATTTAATCTCAGTTATTAGGGCTAGAAATTATGTCGAAGCGACCAGCAGATATAATCATTTCCACGCCCGCCTCGAAGGTACGCCGTCGTCTCAACTTCGACAGCCCATATGCCAGCCGTGCTGCTGCCCCCATTGTCCGCGTCACAAAGGCAAAGGCATGGGCCAACAGGCCCATGAATCGGAAGCCCAGGATGTACAGAATGTACAGAAGCCCTGA |
|
Protein Sequence
|
MWDPLLNEFPESVHGFRCMLAVKYLQLVENSYSPDTLGYDLIRDLISVIRARNYVEATSRYNHFHARLEGTPSSQLRQPICQPCCCPHCPRHKGKGMGQQAHESEAQDVQNVQKP |
|
NCBI Accession
|
YP_008997811.1
|
|
Location
|
309-1082 |
|
Gene Name
|
V1 |
|
Protein Name
|
Coat protein (CP) |
|
Coding Region
|
ATGTCGAAGCGACCAGCAGATATAATCATTTCCACGCCCGCCTCGAAGGTACGCCGTCGTCTCAACTTCGACAGCCCATATGCCAGCCGTGCTGCTGCCCCCATTGTCCGCGTCACAAAGGCAAAGGCATGGGCCAACAGGCCCATGAATCGGAAGCCCAGGATGTACAGAATGTACAGAAGCCCTGATGTTCCGAGGGGATGTGAAGGCCCATGTAAAGTCCAGTCTTATGAGCAACGGGATGATATTAAGCATACTGGTATTGTTCGTTGTGTTAGTGATGTTACTCGTGGATCCGGAATTACCCACAGAGTGGGTAAGAGGTTCTGTGTTAAATCCATATATTTTTTAGGTAAAGTTTGGATGGATGAAAATATCAAGAAGCAGAATCACACTAATCAGGTCATGTTCTTCTTGGTCCGTGATAGAAGGCCCTATGGAAGCAGCCCAATGGATTTTGGGCAGGTTTTTAATATGTTCGACAACGAACCTAGCACCGCAACCGTGAAGAATGATCTCCGGGATAGGTTTCAAGTGATGAGGAAATTTCATGCTACAGTTATCGGTGGGCCCTCTGGAATGAAGGAACAGGCATTAGTTAAGAGATTTTTTAGAATTAACAGTCATGTAACTTATAATCATCAGGAGGCAGCCAAGTATGAGAATCATACTGAGAATGCTTTGTTGTTGTATATGGCATGTACTCATGCCTCTAACCCTGTGTATGCTACATTGAAGATACGTATCTATTTCTATGATTCAGTATCGAATTAA |
|
Protein Sequence
|
MSKRPADIIISTPASKVRRRLNFDSPYASRAAAPIVRVTKAKAWANRPMNRKPRMYRMYRSPDVPRGCEGPCKVQSYEQRDDIKHTGIVRCVSDVTRGSGITHRVGKRFCVKSIYFLGKVWMDENIKKQNHTNQVMFFLVRDRRPYGSSPMDFGQVFNMFDNEPSTATVKNDLRDRFQVMRKFHATVIGGPSGMKEQALVKRFFRINSHVTYNHQEAAKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSVSN |
|
NCBI Accession
|
YP_008997812.1
|
|
Location
|
1079-1489 |
|
Gene Name
|
C3 |
|
Protein Name
|
replication enhancer protein (REn) |
|
Coding Region
|
ATGGCTATGGATTCACGCACAGGGGAACCCATCACTGCAGCTCAAGCAGAGAATGGCGTGTTTATCTGGGAGATAACAAATCCCCTGTATTTCAAGATAACAGAGCACCACAACAGGCCATTCCTGAGAAGCCAAGACATCATCACAGTGCAGATACGGTTCAATCACAACCTGAGGAAAGCGTTGGGGATGCACAAATGTTTTCTAACCTACCGAATCTGGACGACCTTACAGCCTCAGACTGGTCATTTCTTAAGGGTATTTAAAACCCAAGTATTCAAAGTGCTTAATAATTTTGCTGTAATTAGTATTAACAATGTAAATAGAGCAGTTGATCATGTATTATGGAATGTATTAGATCACGTTGTATATGTAAACCAATCATATTCAATAAAATATAATCTTTATTAA |
|
Protein Sequence
|
MAMDSRTGEPITAAQAENGVFIWEITNPLYFKITEHHNRPFLRSQDIITVQIRFNHNLRKALGMHKCFLTYRIWTTLQPQTGHFLRVFKTQVFKVLNNFAVISINNVNRAVDHVLWNVLDHVVYVNQSYSIKYNLY |
|
NCBI Accession
|
YP_008997813.1
|
|
Location
|
1224-1628 |
|
Gene Name
|
C2 |
|
Protein Name
|
transcription activation protein (TrAP) |
|
Coding Region
|
ATGCGACCTTCATCACCCTCACAGGCCCACTCTACTCAGGTTCCAATCAAAGTGCAGCACAGGTTGGCCAAGAAGGGGACCAGGCGTCGTCGCGTTGACCTCGATTGCGGCTGTTCATATTTCATCGCATTACGTTGCCATGGCTATGGATTCACGCACAGGGGAACCCATCACTGCAGCTCAAGCAGAGAATGGCGTGTTTATCTGGGAGATAACAAATCCCCTGTATTTCAAGATAACAGAGCACCACAACAGGCCATTCCTGAGAAGCCAAGACATCATCACAGTGCAGATACGGTTCAATCACAACCTGAGGAAAGCGTTGGGGATGCACAAATGTTTTCTAACCTACCGAATCTGGACGACCTTACAGCCTCAGACTGGTCATTTCTTAAGGGTATTTAA |
|
Protein Sequence
|
MRPSSPSQAHSTQVPIKVQHRLAKKGTRRRRVDLDCGCSYFIALRCHGYGFTHRGTHHCSSSREWRVYLGDNKSPVFQDNRAPQQAIPEKPRHHHSADTVQSQPEESVGDAQMFSNLPNLDDLTASDWSFLKGI |
|
NCBI Accession
|
YP_008997814.1
|
|
Location
|
1531-2619 |
|
Gene Name
|
C1 |
|
Protein Name
|
replication initiation protein (Rep) |
|
Coding Region
|
ATGCCTCGTATTAACTCTTTTTGTGTAAATGCCAAAAATATTTTCCTCACTTATCCAAAATGCCACATACCCAAAGAGCACATGCTCGAAATTCTTCCAGTCAATAAATTGCCCTATCTGATAAATTATTTATCAGAGTGTCACAAGAAAAACACCCAAGATGGGTCTCTGCATATCCACGCCCTCATCCAGTTCAAAGGTAAAGCCAAGTTCAGAAACCCCAGACATTTCGATGTCACTCACCCTAATAACTCCTCCCAATTCCACCCAAACTTCCAGGGAGCAAAGTCCAGCTCCGATGTCAAGTCCTACATCGAGAAGGACGGTGATTACATCGACTGGGGTCAGTTTCAGATCGATGGAAGATCTGCTCGAGGAGGTCAACAGACAGCTAATGATGCAGCAGCAGAGGCCCTAAATGCAGGTTCGGCTGAAGAGGCTTTATCAATAATAAGGGAAAAACTCCCAAAAGATTTTATTTTTCAATATCATAATTTAAAATGTAATTTAGATAGGATTTTTACACCTCCTGTGGAGGTTTATGTTTCTCCCTTTTTGTCTTCATCTTTTAATCAAGTTCCTGATGAACTTGAGGAATGGGCTTCTGTGAACGTGGTGGGTGCCGCTGCGCGGCCTTTGAGGCCCATGAGTATTGTGATTGAGGGTGATAGTCGAACCGGGAAGACCATGTGGGCTAGGTCGTTGGGTCCACATAACTACCTATGTGGTCACTTAGACCTTAGCCCTAAAGTGTACAGCAATGATGCCTCGTATAACGTCATTGATGACGTCGACCCGCATTATCTAAAACACTTTAAAGAATTCATGGGGGCCCAAAGGGACTGGCAATCAAATACAAAATACGGAAAGCCAGTTCAAATTAAAGGTGGAATTCCCGCTATCTTCCTCTGCAATCCAGGACCCAATTCCAGCTATAAAGAGTTCTTGGATGAAGAAAAGAATTCCGCACTCAAACATTGGGCTTTAAAGAATGCGACCTTCATCACCCTCACAGGCCCACTCTACTCAGGTTCCAATCAAAGTGCAGCACAGGTTGGCCAAGAAGGGGACCAGGCGTCGTCGCGTTGA |
|
Protein Sequence
|
MPRINSFCVNAKNIFLTYPKCHIPKEHMLEILPVNKLPYLINYLSECHKKNTQDGSLHIHALIQFKGKAKFRNPRHFDVTHPNNSSQFHPNFQGAKSSSDVKSYIEKDGDYIDWGQFQIDGRSARGGQQTANDAAAEALNAGSAEEALSIIREKLPKDFIFQYHNLKCNLDRIFTPPVEVYVSPFLSSSFNQVPDELEEWASVNVVGAAARPLRPMSIVIEGDSRTGKTMWARSLGPHNYLCGHLDLSPKVYSNDASYNVIDDVDPHYLKHFKEFMGAQRDWQSNTKYGKPVQIKGGIPAIFLCNPGPNSSYKEFLDEEKNSALKHWALKNATFITLTGPLYSGSNQSAAQVGQEGDQASSR |
|
NCBI Accession
|
YP_008997815.1
|
|
Location
|
2202-2459 |
|
Gene Name
|
C4 |
|
Protein Name
|
C4 protein |
|
Coding Region
|
ATGGGTCTCTGCATATCCACGCCCTCATCCAGTTCAAAGGTAAAGCCAAGTTCAGAAACCCCAGACATTTCGATGTCACTCACCCTAATAACTCCTCCCAATTCCACCCAAACTTCCAGGGAGCAAAGTCCAGCTCCGATGTCAAGTCCTACATCGAGAAGGACGGTGATTACATCGACTGGGGTCAGTTTCAGATCGATGGAAGATCTGCTCGAGGAGGTCAACAGACAGCTAATGATGCAGCAGCAGAGGCCCTAA |
|
Protein Sequence
|
MGLCISTPSSSSKVKPSSETPDISMSLTLITPPNSTQTSREQSPAPMSSPTSRRTVITSTGVSFRSMEDLLEEVNRQLMMQQQRP |