Blainvillea yellow spot virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_000880175.1 |
| Isolate |
Brazil |
| Release date |
2015/2/22 |
| Submitter |
Castillo-Urquiza,G.P., Beserra,J.E. Jr., Bruckner,F.P., Lima,A.T., Varsani,A., Alfenas-Zerbini,P., Murilo Zerbini,F., Beserra,J.E.A. Jr., Lima,A.T.M., Zerbini,P.A., Zerbini,F.M. |
| Host |
|
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
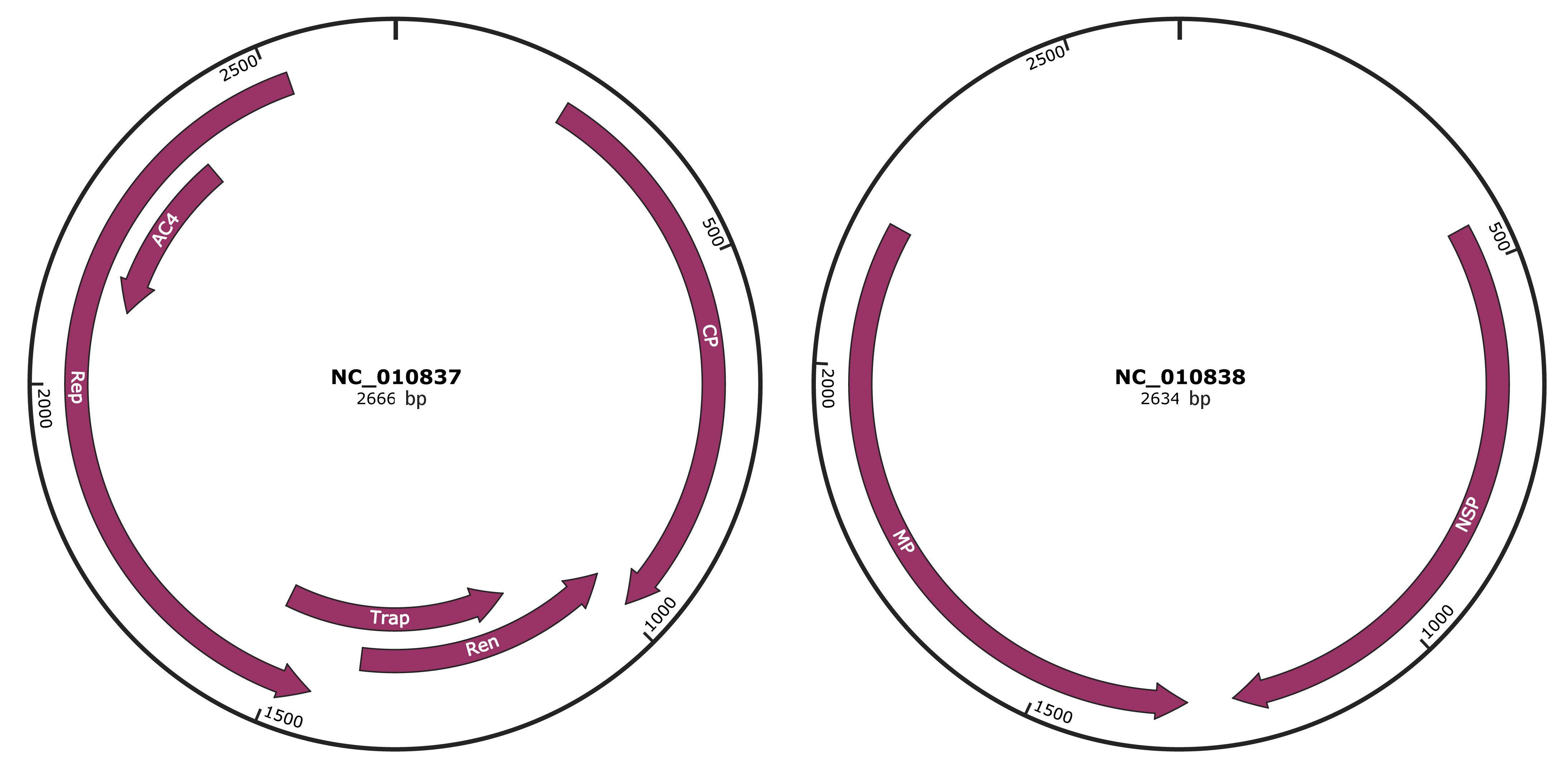
JBrowse
Genome
ACCTGAGGGCCGCCCCCGCCTGGAGACTCCCCTTTTGACGTGGCGCCCTGATGTCCATTGGATTATATTATGTTGGAGATTGGGCCGGTGTCTTTTGCCCCACCTGCTTTATTTAAAGTTGTCTAGGCCCAATCATTATGCGTTTCCCGAGCTTAGATATTATTAAAGACGTGGGCGCCAAGTTCGATAAAGGCTATAAATGGTGTGGTGACCACTTGGTCACTTTAATTCAAAATGCCTAAGCGCGATGCCCCATGGCGCCATATGACAGGGACGTCCAAAATTAGCCGGTCCGTTAATTTCTCACCTCGTTCGAGTGTTGGGCCAAGATCCAACAAGGCCAATGATTGGGTTAACAGGCCTATGTACAGGAAGCCCAAGATATATCGAATGTACAGGAACCCCGATGTTCCAAGGGGTTGTGAAGGGCCTTGTAAAGTCCAGTCTTATGAGCAACGGCATGATGTATCTCATGTTGGCAAGGTGATGTGTGTGTCGGACGTGACACGCGGCAATGGTATCACCCATCGTGTTGGGAAACGTTTTTGTGTTAAGTCCGTATATATTATAGGTAAGATATGGATGGACGAGAATATCAAGCTGAAGAACCACACCAACAGTGTTATGTTTTGGCTGGTGAGAGACCGTAGACCCTATGGAACCCCTATGGACTTTGGCCAAGTGTTTAATATGTTTGACAATGAGCCCAGTACGGCTACTGTTAAGAACGATCTTCGTGATCGTTTTCAAGTCATGCACAAGTTTTATGGCAAAGTCACTGGTGGACAGTATGCAAGTAATGAACAGGCGCTCGTTAAGCGCTTTTGGAAGGTGAACAACCATGTGGTGTACAATCATCAGGAAGCTGGGAAGTATGAGAATCACACGGAGAACGCATTATTGTTGTATATGGCATGTACTCATGCCTCTAATCCTGTGTATGCTACGTTAAAGATACGGATCTATTTTTACGATTCGATATCAAATTAATAAATTCTGAATTTTATTGAATGTTGTTCAAGTACATGATGGATATATGCTTTGTCTGTTGCAAAGCGAACTGCTCTAATTACATTGTTAATCGAAATTACACCTGAACGGTTAAGATACAACATAACTAAATACTGGAATCTATTTAAGTATGTCGTCCCAGAAGCTGTCAGGGAAGTCGTCCAGACTTGGAAGTTCAGATACGCCTTGTGGAGATCCAACGCTTTCCGCACGTTGTGGTTGAACCGGATCTGTATGTGATACACTCGAGTCGTTGTGTATCTGATGTCCTCTACTTGGTACGTCTTGAAATAGAGGGGATTTGGTGTCTCCCAGATATAGACGCCATTCTCCGCCTGAGGTGCAGTGATGAGTTCCCCTGTGCGTGAATCCATGTCCTCTGCAGTTAATATGGAGAAATATGGAACAGCCACAAACTAAATCAATTCGTCTTCTCCTAATCGCACGTTGACGTTGTTTCGCTGCTCGGTGTTGCGCTTTGATAGAGGGTGGTGTTGAGAAAGACGAATTTCGCATTGTGCTTTGTCCAGTTATTTAATCCTGAGTTTTCCTCTCTGTCTAGGAACCTTTTATAGCTGGCCCCCTCGCCAGGATTGCAAAGCACGATGCATGGGATGCCCCCTTTAATTTGAACTGGTTTACCGTATTTACAATTTGACTGCCAGTCCTTCTGGGCCCCAATTAACTCTTTCCAGTGTTTCATCTTTAAATATTTGGGGTCCACGTCATCAATAATATTGTAGTGTGCTTCGTTGGAATAGCACTTAGGGTTAAAGTCTAGGTGACCACTTAAATAATTGTGGACCCCTAAAGCACCGGCCCACATCGTCTTCCCTGTTCGAGAATCACCTTCAATTATTATACTAATAGGTCTCTCCGGCCGCGCAGCGGCACTTCTTCCGAAATAATCGTCCGCCCAAGCTTGCATCTCTTCTGGCACGTTAGTGAATGATGACAGTGGAAACGGAGGAACCCATGGCTCTGGAATTGATTTAAATATCCGTTGAGCATTTGCAACTAGGTTGTGATATTGGAGGAAGAAGTGTTGTGGCTGTTCCTCCTTTATTATATCAAGAGCCTGTTCCACGGACGATGTGTTTAACGCCTTTGAGTATGAATCGTTAGCTGTCTGTTTACCTCCTCGAGCAGATCTTCCGTCGATCTGAAAATTACCCCATTCGATGTAATCTCCGTCCTTCTCAACATATGATTTGGCGTCGGAGGATGACCTGCATGATTCGTACTTGCCATGACAAACATTGGAATTTCTTGGATGTCGTATATCGAAGAATCTGCAATTCGTGCACGTGAATTTCCCTTCGAATTGCAGCAAAGCATGGAGATGAGGCTCCCCATTTTCGTGTAACTCTCTACATACACGAATATATTTCTTGTTCGTCGGTGTATCTAATGCGAGAAGCTGAGTGAGAGCTTCTTCTTTGGGTATGGAACACTTTGGATATGTGAGGAAATAATTTTTAGACTGAATTCTAAAACGCCCAGGCTTGCTCATATTTGACTCCAAATGAGTGTCTCTCAAACCCCCCCTTGAAACTGGGCTTATAGTATTGGAGATTGGGGACAATATATATGCGAGAAGATATTTGGGTTAGATTGTGGTCCCTACACCCTTGCGGCCCTCAGTATATAATATT
ACCTGAGGGCCGCCCCCGCCAGAGACCCTGACGTGGCGCTCTCTCGTCCGCACACTGGTGTTATCTTGGAGGCTGTTTACTGGATAACCCGGTTTCCCCTCCTTTTTACCGGTTTCCTAGGTTTCCCCCTTCGTCTTTTTCAAATGACCAATATACCCCTTATCTTTATGAAAAGACGCGCCCTGCCCCGCAATCGACGTGGCGCACTGGTGACTGTTGGATTAAATTAATCGTGACTCACCACGTTAATTTTCTTTTGAATTATTGAATTGCGGGCCTCTGTACACTTTAATTTGAAATTTGAATTATTGATTGGCGTGCCTCTTTTTGACCAGTCAATCATATATATGTGGTGTACAGAGGGTGTTACGTGGATGAATATTTTACGTATGTTTTATTTGTATAACTATTTTGTGTATAACGAACGTCTTATTTAAGTTCCTATTTCATGCCCAATCTGTGTATGCTTAGTTTGAACATGTATTCTACAAAAAATAGACGAGGTCCGTCTGCCTATCGAGGAACTTATTCACGTAAACATGGTGTAAGACGTTCATATGTTTCACCACGTGTTAATGGTAGGCGTCGTGTTAGTAACCCAAACAGGTCAAGTGACGATAGCAAGATGTCACACTATCGGATTCATGAGAATCAATATGGCCCAGAGTTTGTCATGGGTAATAACACGGCTATATCTACGTTTATTACGTATCCTTCACTTGGTAAGACCGATCATTGTCGTACTAGGTCATACATTAAATTGAGACGTTTGCGATATAAGGGAACTGTTAAGATAGAACGTGTTCACACGGACGTGAACATGAATGGATTAATTCCTAAAATTGATGGAGTGTTTTCATTGGTGGTTGTTGTTGATCGCAAACCCCATCTGAGCCCATCTGGTAGTCTGTATACATTTGATGAGCTCTTTGGAGCAAGGATACATAGCCATGGTAACTTGGCCATAACCTCATCTTTGAAGGATCGTTTTTACATACGTCATGTCCTGAAACGTGTGTTATCTGTTGAGAAGGATACGACTATGATTGACCTGGAGGCAAACACATTATTGTCCAGTAGGCGTTATAACTGTTGGTCTGCTTTTATTGACCATGATCTTGATTCATGTAATGGTGTTTATGCAAACATAAGCAAGAACGCCTTATTGGTTTATTATTGTTGGATGTCGGATACTGTGTCTAAGGCATCTACTTTTGTATCATTTGATCTTGATTATATTGGATAATTAGCAACAATAATATATGTAATGATTGTAATGTACTTGAAACAATTATTCGATATTTGTTTATTTCAATGACTTTGGTTCTGATGGTGTACAATTTGTGTTAATACATTCATGTACTGTTGATCTAACAATCTCGTTTAATTCCGCTAACGAGATTGAAATGTTGGAGCGTGTTCTATCTGCTCCCGTAATCGATGCTGAGTCCCCTGGGTCTAGCACTGTTGATCCCAGTCTGTGTAATTGTCTATATGGGTGTATTTCGTTTTGTAGCTGCGAGTCCCCTGATGAGTTCGTCAGCCCAATAGTGCTTCTAGAAGCCCATGATTCTCCAGGCTTTATTTCTATTGGGACTTGCAGCCCAAATCTTGATGTCGAAGCCGTTCTAATGAGCTTCCTCTCCCAGGCGCCGTAGCCAACGTGTGAGAAATCTATATCCTTTTCCGTGAATTGCTTCGACAGTATCCTTACAGTTGGTGCCCTAAATGGAATATCTACAGAGTGTCTAGCTGTTGATAGTTTAAGCTTTCCTTTGAACTTGGCGAAATGCGTTCTCTGATGTACGTTTGTGTCCATCACTCTGTAGTATAGCTTCCATGGAATTGGATCTTTCAGGGAGAAGAACGACGACGAGAAGTAGTGTAAGTCTATGTTGCATCTGATTGGGAATGTCCATGATGCCTGTAAAGATTCATTGTCAGTCATCCTTTTGTCATGGATCTCCATTATGACTGAGCCTGTTGCGTTTATTGGCACCTGCTGCCTGTATTCGATGACGCAATGATCTATTTTCATACAGCTCCGACTAAGTTTAGCACTTATTTGCGACGCCGTTGATGGAAATTGCAGAACAATTTCTGTTAAGTCATGCGATAGCTGATATTCATCACGTTGAGATTCCACATAATTAAAAGCGCTTGGAGGAGCAACCAACTGAGAACTCATATTAAATATCCTGGCCGCGCAGCGGAATTGTTTAGCTGATTTGAACTGGCGAAGAGGATAAGATACGTTGTTTATGTGATGAAGCAATCACCAAGATGAAGAAGAAAAGTGATTTGGGTATTTTAAAATTATTGTGAATATGATGATTATGCGAATTCGATATGAGCGAAGAGGATAGAGGTCGATATATTTTGTTATGGTATTTATAGAGAAATGTGGGTTTAGTGTTTTGCCTGGATGCTGTTTATGTGAATTTTGTGCTTCAAAATTCAAGAGATAATGTGAAAATATATGGAAACCCAGAGGAGTGTCTCCAAGTGGTGTCTCTCAAATCCCCTCTTGAAACTGGGCTTATAGTATTGGAGATTGGGGACAATATATATGCGAGAAGATATTTGGGTTAGATTGTGGTCCCTACACCCTTGCGGCCCTCAGTATATAATATT
Gene Information
|
NCBI Accession
|
YP_001960959.1
|
|
Location
|
235-990 |
|
Gene Name
|
CP |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGCCTAAGCGCGATGCCCCATGGCGCCATATGACAGGGACGTCCAAAATTAGCCGGTCCGTTAATTTCTCACCTCGTTCGAGTGTTGGGCCAAGATCCAACAAGGCCAATGATTGGGTTAACAGGCCTATGTACAGGAAGCCCAAGATATATCGAATGTACAGGAACCCCGATGTTCCAAGGGGTTGTGAAGGGCCTTGTAAAGTCCAGTCTTATGAGCAACGGCATGATGTATCTCATGTTGGCAAGGTGATGTGTGTGTCGGACGTGACACGCGGCAATGGTATCACCCATCGTGTTGGGAAACGTTTTTGTGTTAAGTCCGTATATATTATAGGTAAGATATGGATGGACGAGAATATCAAGCTGAAGAACCACACCAACAGTGTTATGTTTTGGCTGGTGAGAGACCGTAGACCCTATGGAACCCCTATGGACTTTGGCCAAGTGTTTAATATGTTTGACAATGAGCCCAGTACGGCTACTGTTAAGAACGATCTTCGTGATCGTTTTCAAGTCATGCACAAGTTTTATGGCAAAGTCACTGGTGGACAGTATGCAAGTAATGAACAGGCGCTCGTTAAGCGCTTTTGGAAGGTGAACAACCATGTGGTGTACAATCATCAGGAAGCTGGGAAGTATGAGAATCACACGGAGAACGCATTATTGTTGTATATGGCATGTACTCATGCCTCTAATCCTGTGTATGCTACGTTAAAGATACGGATCTATTTTTACGATTCGATATCAAATTAA |
|
Protein Sequence
|
MPKRDAPWRHMTGTSKISRSVNFSPRSSVGPRSNKANDWVNRPMYRKPKIYRMYRNPDVPRGCEGPCKVQSYEQRHDVSHVGKVMCVSDVTRGNGITHRVGKRFCVKSVYIIGKIWMDENIKLKNHTNSVMFWLVRDRRPYGTPMDFGQVFNMFDNEPSTATVKNDLRDRFQVMHKFYGKVTGGQYASNEQALVKRFWKVNNHVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSISN |
|
NCBI Accession
|
YP_001960960.1
|
|
Location
|
987-1385 |
|
Gene Name
|
Ren |
|
Protein Name
|
replication enhancer protein |
|
Coding Region
|
ATGGATTCACGCACAGGGGAACTCATCACTGCACCTCAGGCGGAGAATGGCGTCTATATCTGGGAGACACCAAATCCCCTCTATTTCAAGACGTACCAAGTAGAGGACATCAGATACACAACGACTCGAGTGTATCACATACAGATCCGGTTCAACCACAACGTGCGGAAAGCGTTGGATCTCCACAAGGCGTATCTGAACTTCCAAGTCTGGACGACTTCCCTGACAGCTTCTGGGACGACATACTTAAATAGATTCCAGTATTTAGTTATGTTGTATCTTAACCGTTCAGGTGTAATTTCGATTAACAATGTAATTAGAGCAGTTCGCTTTGCAACAGACAAAGCATATATCCATCATGTACTTGAACAACATTCAATAAAATTCAGAATTTATTAA |
|
Protein Sequence
|
MDSRTGELITAPQAENGVYIWETPNPLYFKTYQVEDIRYTTTRVYHIQIRFNHNVRKALDLHKAYLNFQVWTTSLTASGTTYLNRFQYLVMLYLNRSGVISINNVIRAVRFATDKAYIHHVLEQHSIKFRIY |
|
NCBI Accession
|
YP_001960961.1
|
|
Location
|
1132-1527 |
|
Gene Name
|
Trap |
|
Protein Name
|
trans-activating protein |
|
Coding Region
|
ATGCGAAATTCGTCTTTCTCAACACCACCCTCTATCAAAGCGCAACACCGAGCAGCGAAACAACGTCAACGTGCGATTAGGAGAAGACGAATTGATTTAGTTTGTGGCTGTTCCATATTTCTCCATATTAACTGCAGAGGACATGGATTCACGCACAGGGGAACTCATCACTGCACCTCAGGCGGAGAATGGCGTCTATATCTGGGAGACACCAAATCCCCTCTATTTCAAGACGTACCAAGTAGAGGACATCAGATACACAACGACTCGAGTGTATCACATACAGATCCGGTTCAACCACAACGTGCGGAAAGCGTTGGATCTCCACAAGGCGTATCTGAACTTCCAAGTCTGGACGACTTCCCTGACAGCTTCTGGGACGACATACTTAAATAG |
|
Protein Sequence
|
MRNSSFSTPPSIKAQHRAAKQRQRAIRRRRIDLVCGCSIFLHINCRGHGFTHRGTHHCTSGGEWRLYLGDTKSPLFQDVPSRGHQIHNDSSVSHTDPVQPQRAESVGSPQGVSELPSLDDFPDSFWDDILK |
|
NCBI Accession
|
YP_001960962.1
|
|
Location
|
1448-2524 |
|
Gene Name
|
Rep |
|
Protein Name
|
replication-associated protein |
|
Coding Region
|
ATGAGCAAGCCTGGGCGTTTTAGAATTCAGTCTAAAAATTATTTCCTCACATATCCAAAGTGTTCCATACCCAAAGAAGAAGCTCTCACTCAGCTTCTCGCATTAGATACACCGACGAACAAGAAATATATTCGTGTATGTAGAGAGTTACACGAAAATGGGGAGCCTCATCTCCATGCTTTGCTGCAATTCGAAGGGAAATTCACGTGCACGAATTGCAGATTCTTCGATATACGACATCCAAGAAATTCCAATGTTTGTCATGGCAAGTACGAATCATGCAGGTCATCCTCCGACGCCAAATCATATGTTGAGAAGGACGGAGATTACATCGAATGGGGTAATTTTCAGATCGACGGAAGATCTGCTCGAGGAGGTAAACAGACAGCTAACGATTCATACTCAAAGGCGTTAAACACATCGTCCGTGGAACAGGCTCTTGATATAATAAAGGAGGAACAGCCACAACACTTCTTCCTCCAATATCACAACCTAGTTGCAAATGCTCAACGGATATTTAAATCAATTCCAGAGCCATGGGTTCCTCCGTTTCCACTGTCATCATTCACTAACGTGCCAGAAGAGATGCAAGCTTGGGCGGACGATTATTTCGGAAGAAGTGCCGCTGCGCGGCCGGAGAGACCTATTAGTATAATAATTGAAGGTGATTCTCGAACAGGGAAGACGATGTGGGCCGGTGCTTTAGGGGTCCACAATTATTTAAGTGGTCACCTAGACTTTAACCCTAAGTGCTATTCCAACGAAGCACACTACAATATTATTGATGACGTGGACCCCAAATATTTAAAGATGAAACACTGGAAAGAGTTAATTGGGGCCCAGAAGGACTGGCAGTCAAATTGTAAATACGGTAAACCAGTTCAAATTAAAGGGGGCATCCCATGCATCGTGCTTTGCAATCCTGGCGAGGGGGCCAGCTATAAAAGGTTCCTAGACAGAGAGGAAAACTCAGGATTAAATAACTGGACAAAGCACAATGCGAAATTCGTCTTTCTCAACACCACCCTCTATCAAAGCGCAACACCGAGCAGCGAAACAACGTCAACGTGCGATTAG |
|
Protein Sequence
|
MSKPGRFRIQSKNYFLTYPKCSIPKEEALTQLLALDTPTNKKYIRVCRELHENGEPHLHALLQFEGKFTCTNCRFFDIRHPRNSNVCHGKYESCRSSSDAKSYVEKDGDYIEWGNFQIDGRSARGGKQTANDSYSKALNTSSVEQALDIIKEEQPQHFFLQYHNLVANAQRIFKSIPEPWVPPFPLSSFTNVPEEMQAWADDYFGRSAAARPERPISIIIEGDSRTGKTMWAGALGVHNYLSGHLDFNPKCYSNEAHYNIIDDVDPKYLKMKHWKELIGAQKDWQSNCKYGKPVQIKGGIPCIVLCNPGEGASYKRFLDREENSGLNNWTKHNAKFVFLNTTLYQSATPSSETTSTCD |
|
NCBI Accession
|
YP_001960963.1
|
|
Location
|
2110-2367 |
|
Gene Name
|
AC4 |
|
Protein Name
|
AC4 |
|
Coding Region
|
ATGGGGAGCCTCATCTCCATGCTTTGCTGCAATTCGAAGGGAAATTCACGTGCACGAATTGCAGATTCTTCGATATACGACATCCAAGAAATTCCAATGTTTGTCATGGCAAGTACGAATCATGCAGGTCATCCTCCGACGCCAAATCATATGTTGAGAAGGACGGAGATTACATCGAATGGGGTAATTTTCAGATCGACGGAAGATCTGCTCGAGGAGGTAAACAGACAGCTAACGATTCATACTCAAAGGCGTTAA |
|
Protein Sequence
|
MGSLISMLCCNSKGNSRARIADSSIYDIQEIPMFVMASTNHAGHPPTPNHMLRRTEITSNGVIFRSTEDLLEEVNRQLTIHTQRR |
|
NCBI Accession
|
YP_001960964.1
|
|
Location
|
449-1246 |
|
Gene Name
|
NSP |
|
Protein Name
|
nuclear shuttle protein |
|
Coding Region
|
ATGCCCAATCTGTGTATGCTTAGTTTGAACATGTATTCTACAAAAAATAGACGAGGTCCGTCTGCCTATCGAGGAACTTATTCACGTAAACATGGTGTAAGACGTTCATATGTTTCACCACGTGTTAATGGTAGGCGTCGTGTTAGTAACCCAAACAGGTCAAGTGACGATAGCAAGATGTCACACTATCGGATTCATGAGAATCAATATGGCCCAGAGTTTGTCATGGGTAATAACACGGCTATATCTACGTTTATTACGTATCCTTCACTTGGTAAGACCGATCATTGTCGTACTAGGTCATACATTAAATTGAGACGTTTGCGATATAAGGGAACTGTTAAGATAGAACGTGTTCACACGGACGTGAACATGAATGGATTAATTCCTAAAATTGATGGAGTGTTTTCATTGGTGGTTGTTGTTGATCGCAAACCCCATCTGAGCCCATCTGGTAGTCTGTATACATTTGATGAGCTCTTTGGAGCAAGGATACATAGCCATGGTAACTTGGCCATAACCTCATCTTTGAAGGATCGTTTTTACATACGTCATGTCCTGAAACGTGTGTTATCTGTTGAGAAGGATACGACTATGATTGACCTGGAGGCAAACACATTATTGTCCAGTAGGCGTTATAACTGTTGGTCTGCTTTTATTGACCATGATCTTGATTCATGTAATGGTGTTTATGCAAACATAAGCAAGAACGCCTTATTGGTTTATTATTGTTGGATGTCGGATACTGTGTCTAAGGCATCTACTTTTGTATCATTTGATCTTGATTATATTGGATAA |
|
Protein Sequence
|
MPNLCMLSLNMYSTKNRRGPSAYRGTYSRKHGVRRSYVSPRVNGRRRVSNPNRSSDDSKMSHYRIHENQYGPEFVMGNNTAISTFITYPSLGKTDHCRTRSYIKLRRLRYKGTVKIERVHTDVNMNGLIPKIDGVFSLVVVVDRKPHLSPSGSLYTFDELFGARIHSHGNLAITSSLKDRFYIRHVLKRVLSVEKDTTMIDLEANTLLSSRRYNCWSAFIDHDLDSCNGVYANISKNALLVYYCWMSDTVSKASTFVSFDLDYIG |
|
NCBI Accession
|
YP_001960965.1
|
|
Location
|
1307-2188 |
|
Gene Name
|
MP |
|
Protein Name
|
movement protein |
|
Coding Region
|
ATGAGTTCTCAGTTGGTTGCTCCTCCAAGCGCTTTTAATTATGTGGAATCTCAACGTGATGAATATCAGCTATCGCATGACTTAACAGAAATTGTTCTGCAATTTCCATCAACGGCGTCGCAAATAAGTGCTAAACTTAGTCGGAGCTGTATGAAAATAGATCATTGCGTCATCGAATACAGGCAGCAGGTGCCAATAAACGCAACAGGCTCAGTCATAATGGAGATCCATGACAAAAGGATGACTGACAATGAATCTTTACAGGCATCATGGACATTCCCAATCAGATGCAACATAGACTTACACTACTTCTCGTCGTCGTTCTTCTCCCTGAAAGATCCAATTCCATGGAAGCTATACTACAGAGTGATGGACACAAACGTACATCAGAGAACGCATTTCGCCAAGTTCAAAGGAAAGCTTAAACTATCAACAGCTAGACACTCTGTAGATATTCCATTTAGGGCACCAACTGTAAGGATACTGTCGAAGCAATTCACGGAAAAGGATATAGATTTCTCACACGTTGGCTACGGCGCCTGGGAGAGGAAGCTCATTAGAACGGCTTCGACATCAAGATTTGGGCTGCAAGTCCCAATAGAAATAAAGCCTGGAGAATCATGGGCTTCTAGAAGCACTATTGGGCTGACGAACTCATCAGGGGACTCGCAGCTACAAAACGAAATACACCCATATAGACAATTACACAGACTGGGATCAACAGTGCTAGACCCAGGGGACTCAGCATCGATTACGGGAGCAGATAGAACACGCTCCAACATTTCAATCTCGTTAGCGGAATTAAACGAGATTGTTAGATCAACAGTACATGAATGTATTAACACAAATTGTACACCATCAGAACCAAAGTCATTGAAATAA |
|
Protein Sequence
|
MSSQLVAPPSAFNYVESQRDEYQLSHDLTEIVLQFPSTASQISAKLSRSCMKIDHCVIEYRQQVPINATGSVIMEIHDKRMTDNESLQASWTFPIRCNIDLHYFSSSFFSLKDPIPWKLYYRVMDTNVHQRTHFAKFKGKLKLSTARHSVDIPFRAPTVRILSKQFTEKDIDFSHVGYGAWERKLIRTASTSRFGLQVPIEIKPGESWASRSTIGLTNSSGDSQLQNEIHPYRQLHRLGSTVLDPGDSASITGADRTRSNISISLAELNEIVRSTVHECINTNCTPSEPKSLK |