Tomato leaf curl Karnataka virus 2
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_004787115.1 |
| Isolate |
India: Sonipet, Hariyana |
| Release date |
2021/6/1 |
| Submitter |
Swarnalatha,S., Venkataravanappa,V., Jalali,S., Krishnareddy,M. |
| Host |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
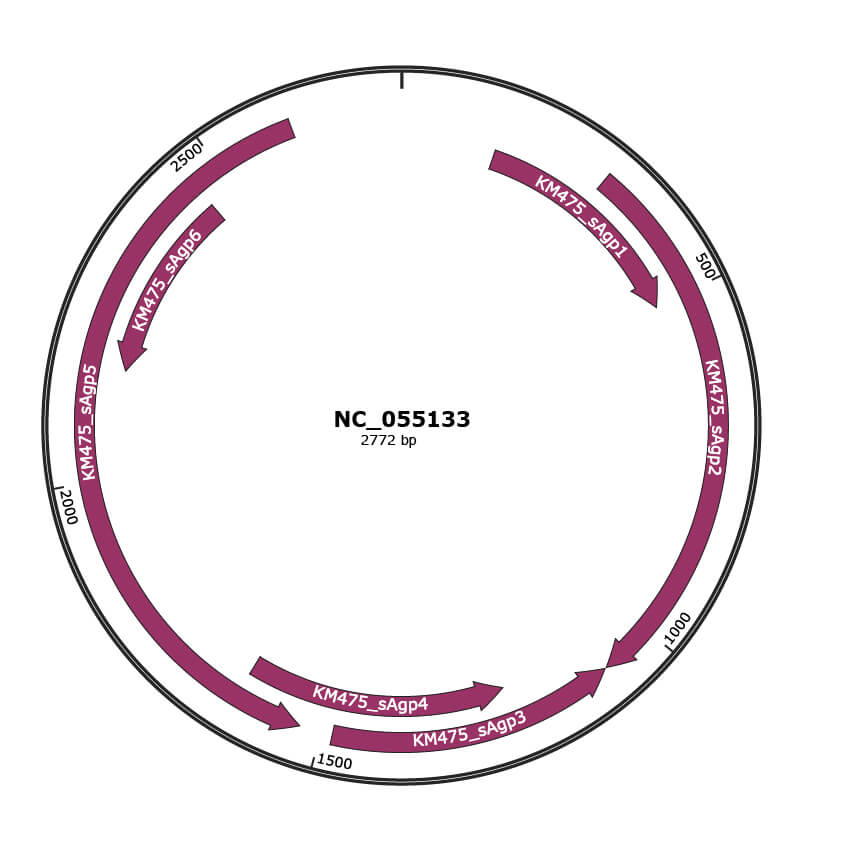
JBrowse
Genome
ACCGAATGGCCGCGCAAATTTTTACGTGGGCCCCTCAACGCATTAACTGACGAATGAAATTGCATCAATCACATGGCTTCTTCAAAGCTTAATTGTTTTGCGGACCTTTAAATATACTTGCTCACCAAGTATTGGATCCACAAACATGTGGGATCCATTATTGCACGAATTTCCAGAAAGCGTTCATGGTCTAAGGTGCATGCTAGCTGTAAAATATCTGCAAGAGATAGAAAAGAACTATTCGCCAGACACAGTCGGATACGATCTTGTCCGAGATCTCATTCTTGTTCTGCGAGCAAAGAACTATGGCGAAGCGACCAGCAGATATCATCATTTCAACGCCCGCATCGAAAGTACGCCGACGTCTCAACTTCGACAGCCCCTATGGAGCTCGTGCAGTTGTCCCCATTGCCCGCGTCACAAAAGCAAAGGCCTGGACAAACAGGCCGATGAACAGAAAACCCAGAATGTACAGAATGTACAGAAGTCCCGACGTGCCTAGGGGATGTGAAGGCCCTTGCAAGGTGCAGTCCTTTGAATCAAGGCACGATGTCTCTCATATTGGGAAAGTGATGTGCGTTAGTGATGTTACCCGAGGAACTGGACTCACACATCGCGTAGGAAAGCGATTTTGTGTGAAATCTGTCTATGTGCTGGGGAAGATATGGATGGATGAAAACATCAAGACGAAGAACCATACTAACAGTGTTATGTTTTTTTTGGTACGTGACCGTCGTCCTACAGGATCCCCCCAAGATTTTGGGGAAGTTTTTAACATGTTTGACAATGAACCGAGCACAGCAACGGTGAAGAACATGCATCGTGATCGTTATCAAGTGTTACGGAAGTGGCATGCGACTGTGACGGGAGGAACATATGCATGTAGGGAGCAAGCATTAGTTAGGAAGTTTGTTAGGGTTAATAATTATGTAGTTTATAATCAACAAGAGGCCGGCAAGTATGAGAATCATACTGAAAACGCATTAATGTTGTATATGGCCTGTACTCATGCCTCTAATCCTGTGTATGCTACTTTGAAAGTTAGGAGTTACTTCTACGATTCTGTAACAAATTAATATTAATAAATATTGAATTTTATTGAATATGATTGGTCTACATATACAACGTGATGTAATACATTCCATAATACATGATCAACTGATTTAATTACAGTGTTAATACTGATAACTCCTAAGTTATTTAAATACTTAAGAACTTGAGTCTTAAAGACCCTTAAGAAACGACCAGTCGGAGGCTGTGAGGTCATCCAGATTCGGAAGGCTAGGAAACATTTGTGTATCCCCAACGCTTTCCTCAGGTTGTGATTGAACTGTATCTGAACGGTGATGATGTCTTCCTTCATTAGGAATGGCCTGTTGTGGTGTTCTGTTATCTTGAAATACAGGGGATTTTGAATCTCCCAGATAAACACGCCATTCTGTGCTTGAGCTGCAGTGATGGGTTCCCCTGTGCGTGAATCCATGGTTGTGGCAGGCTAATGCAATGAAGTATGAACAGCCGCACGGTAGATCAACACGTCGACGTCTGGTCCCCTTCTTGGCTAGCCTGTGCTGCACTTTGATGGGAACCTGAGTACAATGGGCCTTCGAGGGTGACGAAGATCGCATTTTTTAATGCCCAGTTTTTTAGTGCAGAATTCTTATCTTCATCCAAGAACTCTTTATAGCTGGAATTTGGTCCTGGATTGCAGAGGAAGATAGTGGGAATTCCGCCTTTAATTTGAACTGGCTTCCCGTACTTTGTATTTGATTGCCAGTCCCTTTGGGCCCCCATGAATTCTTTAAAGTGCTTTAGATAGTGGGGGTCTACGTCATCAATGACGTTATACCAGGCATCATTATTGTAGACCTTTGGACTAAGGTCTAAATGACCACACAAATAATTATGTGGTCCCAGTGATCTGGCCCACATAGTCTTCCCTGTCCTACTATCACCCTCAATGACTATACTTACGGGTCTCAAAGGCCGCGCAGCGGATCTCACCACATTCTCTGCAGCCCACTCCTCAAGTTCTTCGGGAACTTGATCAAAAGATGAAGATAAAAAAGGAGAAACATAAACCTCCATTGGAGGTGTAAAAAACCTATCTAAATTAGAATTTAAATTATGAAATTGAAATAGAAAGTCTCTGGGAGCTTTCTCCTTCAGTATATTGAGGGCCTGAGCTTTGGACCCTGAGTTGATTGCCTCGGCATATGCGTCGTTGGCAGATTGGCAACCTCCTCTAGCTGATCGTCCATCGACTTGGAAAACTCCATGATCAAGGACGTCTCCGTCTTTTTCCATGTAGGATTTGACATCGCTTGAGCTCTTAGCTCCCTGAATGTTCGGATGGAAATGTGCTGACCTGGTTGGGGATGTAAGGTCGAAGAATCTATTGTTTTTGCACTGGAACTTTCCTTCGAACTGGATGAGCACATGCAAGTGAGGAGTCCCATCTTCGTGAAGCTCTCTGCAAATTCTAATAAATTTTTTGGAAGTGGGTGTTTGGAGATTTAATAATTGGGAAAGTGCCTCTTCTTTAGTTAGAGAGCACTTGAGATATGTGAGAAAATAGTTTTTCGCATTTATTCTAAAACGACTTGGCGGAGCCATAAAACTTGTCGTTTCGATCCGGTGTCTCTCAACTTTCTCTATGTAATTGGTGTCTGGAGTCCCATATATAGGTAAGACACCATATGGCAGAATTGTAATTTTGAAAAGAAAATTACTTTAATTCAAAATCCCTAAAGCGGCCATTCGTATAATATT
Gene Information
|
NCBI Accession
|
YP_010084352.1
|
|
Location
|
146-502 |
|
Protein Name
|
AV2 |
|
Coding Region
|
ATGTGGGATCCATTATTGCACGAATTTCCAGAAAGCGTTCATGGTCTAAGGTGCATGCTAGCTGTAAAATATCTGCAAGAGATAGAAAAGAACTATTCGCCAGACACAGTCGGATACGATCTTGTCCGAGATCTCATTCTTGTTCTGCGAGCAAAGAACTATGGCGAAGCGACCAGCAGATATCATCATTTCAACGCCCGCATCGAAAGTACGCCGACGTCTCAACTTCGACAGCCCCTATGGAGCTCGTGCAGTTGTCCCCATTGCCCGCGTCACAAAAGCAAAGGCCTGGACAAACAGGCCGATGAACAGAAAACCCAGAATGTACAGAATGTACAGAAGTCCCGACGTGCCTAG |
|
Protein Sequence
|
MWDPLLHEFPESVHGLRCMLAVKYLQEIEKNYSPDTVGYDLVRDLILVLRAKNYGEATSRYHHFNARIESTPTSQLRQPLWSSCSCPHCPRHKSKGLDKQADEQKTQNVQNVQKSRRA |
|
NCBI Accession
|
YP_010084353.1
|
|
Location
|
306-1076 |
|
Protein Name
|
AV1 |
|
Coding Region
|
ATGGCGAAGCGACCAGCAGATATCATCATTTCAACGCCCGCATCGAAAGTACGCCGACGTCTCAACTTCGACAGCCCCTATGGAGCTCGTGCAGTTGTCCCCATTGCCCGCGTCACAAAAGCAAAGGCCTGGACAAACAGGCCGATGAACAGAAAACCCAGAATGTACAGAATGTACAGAAGTCCCGACGTGCCTAGGGGATGTGAAGGCCCTTGCAAGGTGCAGTCCTTTGAATCAAGGCACGATGTCTCTCATATTGGGAAAGTGATGTGCGTTAGTGATGTTACCCGAGGAACTGGACTCACACATCGCGTAGGAAAGCGATTTTGTGTGAAATCTGTCTATGTGCTGGGGAAGATATGGATGGATGAAAACATCAAGACGAAGAACCATACTAACAGTGTTATGTTTTTTTTGGTACGTGACCGTCGTCCTACAGGATCCCCCCAAGATTTTGGGGAAGTTTTTAACATGTTTGACAATGAACCGAGCACAGCAACGGTGAAGAACATGCATCGTGATCGTTATCAAGTGTTACGGAAGTGGCATGCGACTGTGACGGGAGGAACATATGCATGTAGGGAGCAAGCATTAGTTAGGAAGTTTGTTAGGGTTAATAATTATGTAGTTTATAATCAACAAGAGGCCGGCAAGTATGAGAATCATACTGAAAACGCATTAATGTTGTATATGGCCTGTACTCATGCCTCTAATCCTGTGTATGCTACTTTGAAAGTTAGGAGTTACTTCTACGATTCTGTAACAAATTAA |
|
Protein Sequence
|
MAKRPADIIISTPASKVRRRLNFDSPYGARAVVPIARVTKAKAWTNRPMNRKPRMYRMYRSPDVPRGCEGPCKVQSFESRHDVSHIGKVMCVSDVTRGTGLTHRVGKRFCVKSVYVLGKIWMDENIKTKNHTNSVMFFLVRDRRPTGSPQDFGEVFNMFDNEPSTATVKNMHRDRYQVLRKWHATVTGGTYACREQALVRKFVRVNNYVVYNQQEAGKYENHTENALMLYMACTHASNPVYATLKVRSYFYDSVTN |
|
NCBI Accession
|
YP_010084354.1
|
|
Location
|
1079-1483 |
|
Protein Name
|
AC3 |
|
Coding Region
|
ATGGATTCACGCACAGGGGAACCCATCACTGCAGCTCAAGCACAGAATGGCGTGTTTATCTGGGAGATTCAAAATCCCCTGTATTTCAAGATAACAGAACACCACAACAGGCCATTCCTAATGAAGGAAGACATCATCACCGTTCAGATACAGTTCAATCACAACCTGAGGAAAGCGTTGGGGATACACAAATGTTTCCTAGCCTTCCGAATCTGGATGACCTCACAGCCTCCGACTGGTCGTTTCTTAAGGGTCTTTAAGACTCAAGTTCTTAAGTATTTAAATAACTTAGGAGTTATCAGTATTAACACTGTAATTAAATCAGTTGATCATGTATTATGGAATGTATTACATCACGTTGTATATGTAGACCAATCATATTCAATAAAATTCAATATTTATTAA |
|
Protein Sequence
|
MDSRTGEPITAAQAQNGVFIWEIQNPLYFKITEHHNRPFLMKEDIITVQIQFNHNLRKALGIHKCFLAFRIWMTSQPPTGRFLRVFKTQVLKYLNNLGVISINTVIKSVDHVLWNVLHHVVYVDQSYSIKFNIY |
|
NCBI Accession
|
YP_010084355.1
|
|
Location
|
1224-1628 |
|
Protein Name
|
AC2 |
|
Coding Region
|
ATGCGATCTTCGTCACCCTCGAAGGCCCATTGTACTCAGGTTCCCATCAAAGTGCAGCACAGGCTAGCCAAGAAGGGGACCAGACGTCGACGTGTTGATCTACCGTGCGGCTGTTCATACTTCATTGCATTAGCCTGCCACAACCATGGATTCACGCACAGGGGAACCCATCACTGCAGCTCAAGCACAGAATGGCGTGTTTATCTGGGAGATTCAAAATCCCCTGTATTTCAAGATAACAGAACACCACAACAGGCCATTCCTAATGAAGGAAGACATCATCACCGTTCAGATACAGTTCAATCACAACCTGAGGAAAGCGTTGGGGATACACAAATGTTTCCTAGCCTTCCGAATCTGGATGACCTCACAGCCTCCGACTGGTCGTTTCTTAAGGGTCTTTAA |
|
Protein Sequence
|
MRSSSPSKAHCTQVPIKVQHRLAKKGTRRRRVDLPCGCSYFIALACHNHGFTHRGTHHCSSSTEWRVYLGDSKSPVFQDNRTPQQAIPNEGRHHHRSDTVQSQPEESVGDTQMFPSLPNLDDLTASDWSFLKGL |
|
NCBI Accession
|
YP_010084356.1
|
|
Location
|
1531-2616 |
|
Protein Name
|
AC1 |
|
Coding Region
|
ATGGCTCCGCCAAGTCGTTTTAGAATAAATGCGAAAAACTATTTTCTCACATATCTCAAGTGCTCTCTAACTAAAGAAGAGGCACTTTCCCAATTATTAAATCTCCAAACACCCACTTCCAAAAAATTTATTAGAATTTGCAGAGAGCTTCACGAAGATGGGACTCCTCACTTGCATGTGCTCATCCAGTTCGAAGGAAAGTTCCAGTGCAAAAACAATAGATTCTTCGACCTTACATCCCCAACCAGGTCAGCACATTTCCATCCGAACATTCAGGGAGCTAAGAGCTCAAGCGATGTCAAATCCTACATGGAAAAAGACGGAGACGTCCTTGATCATGGAGTTTTCCAAGTCGATGGACGATCAGCTAGAGGAGGTTGCCAATCTGCCAACGACGCATATGCCGAGGCAATCAACTCAGGGTCCAAAGCTCAGGCCCTCAATATACTGAAGGAGAAAGCTCCCAGAGACTTTCTATTTCAATTTCATAATTTAAATTCTAATTTAGATAGGTTTTTTACACCTCCAATGGAGGTTTATGTTTCTCCTTTTTTATCTTCATCTTTTGATCAAGTTCCCGAAGAACTTGAGGAGTGGGCTGCAGAGAATGTGGTGAGATCCGCTGCGCGGCCTTTGAGACCCGTAAGTATAGTCATTGAGGGTGATAGTAGGACAGGGAAGACTATGTGGGCCAGATCACTGGGACCACATAATTATTTGTGTGGTCATTTAGACCTTAGTCCAAAGGTCTACAATAATGATGCCTGGTATAACGTCATTGATGACGTAGACCCCCACTATCTAAAGCACTTTAAAGAATTCATGGGGGCCCAAAGGGACTGGCAATCAAATACAAAGTACGGGAAGCCAGTTCAAATTAAAGGCGGAATTCCCACTATCTTCCTCTGCAATCCAGGACCAAATTCCAGCTATAAAGAGTTCTTGGATGAAGATAAGAATTCTGCACTAAAAAACTGGGCATTAAAAAATGCGATCTTCGTCACCCTCGAAGGCCCATTGTACTCAGGTTCCCATCAAAGTGCAGCACAGGCTAGCCAAGAAGGGGACCAGACGTCGACGTGTTGA |
|
Protein Sequence
|
MAPPSRFRINAKNYFLTYLKCSLTKEEALSQLLNLQTPTSKKFIRICRELHEDGTPHLHVLIQFEGKFQCKNNRFFDLTSPTRSAHFHPNIQGAKSSSDVKSYMEKDGDVLDHGVFQVDGRSARGGCQSANDAYAEAINSGSKAQALNILKEKAPRDFLFQFHNLNSNLDRFFTPPMEVYVSPFLSSSFDQVPEELEEWAAENVVRSAARPLRPVSIVIEGDSRTGKTMWARSLGPHNYLCGHLDLSPKVYNNDAWYNVIDDVDPHYLKHFKEFMGAQRDWQSNTKYGKPVQIKGGIPTIFLCNPGPNSSYKEFLDEDKNSALKNWALKNAIFVTLEGPLYSGSHQSAAQASQEGDQTSTC |
|
NCBI Accession
|
YP_010084357.1
|
|
Location
|
2166-2459 |
|
Protein Name
|
AC4 |
|
Coding Region
|
ATGGGACTCCTCACTTGCATGTGCTCATCCAGTTCGAAGGAAAGTTCCAGTGCAAAAACAATAGATTCTTCGACCTTACATCCCCAACCAGGTCAGCACATTTCCATCCGAACATTCAGGGAGCTAAGAGCTCAAGCGATGTCAAATCCTACATGGAAAAAGACGGAGACGTCCTTGATCATGGAGTTTTCCAAGTCGATGGACGATCAGCTAGAGGAGGTTGCCAATCTGCCAACGACGCATATGCCGAGGCAATCAACTCAGGGTCCAAAGCTCAGGCCCTCAATATACTGA |
|
Protein Sequence
|
MGLLTCMCSSSSKESSSAKTIDSSTLHPQPGQHISIRTFRELRAQAMSNPTWKKTETSLIMEFSKSMDDQLEEVANLPTTHMPRQSTQGPKLRPSIY |