Tomato leaf curl Japan virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_004786335.1 |
| Isolate |
Japan: Miyazaki |
| Release date |
2021/6/1 |
| Submitter |
Ueda,S., Onuki,M., Hanada,K., Takanami,Y. |
| Host |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
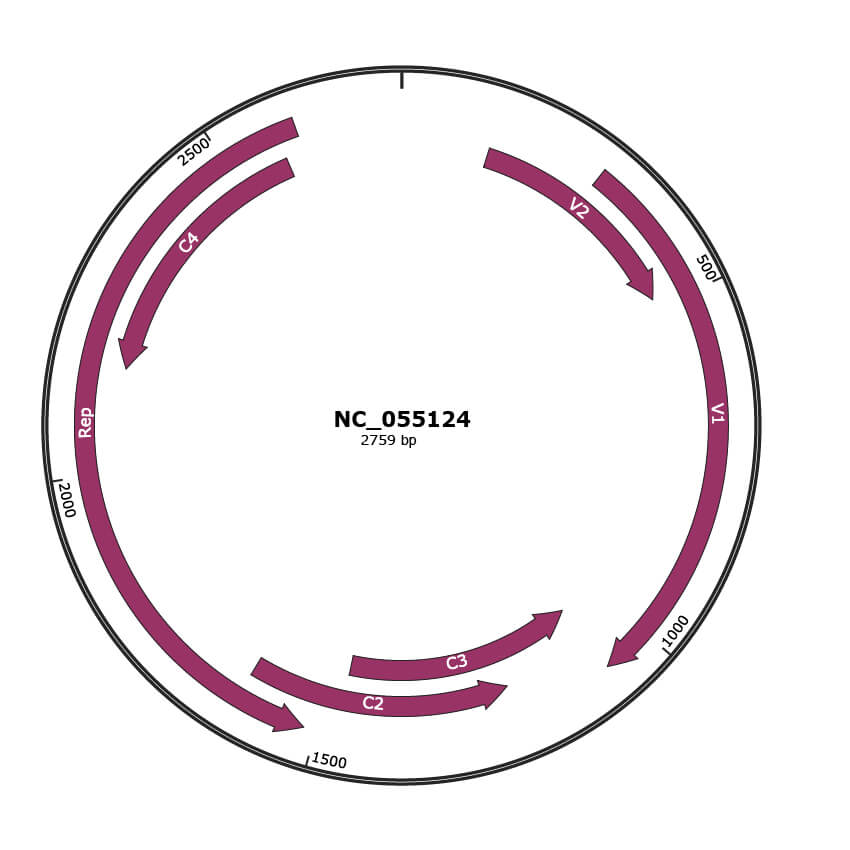
JBrowse
Genome
ACCGGATGGGCGCCCGAAATTTCGTATTGGGCCCCCCTTGTCGGCCAATGATGTTCGTGCCTTGAACGCTAGATAAGTGGATAGTGACATCACTTTTGTCTTTATATACGTCAGCCCTAATTTTAAAGGTATAACATGTGGGATCCTTTACTTAACGATTTCCCTGAAACCGTTCACGGTTTCAGGTGTATGCTAGCGGTTAAGTACCTTCTACTCGTTGAAGCTACCTACTCTCCGGATACTATAGGTTACGATCTGATTCGTGATCTTGTGGGTGTTGTTCGTGCCAAGAACTATGTCGAAGCGTCCTGCAGATATAGGAATTTTCACTCCCGTCTCCAGAGCACGACGCCGTCTGAACTTCGACAGCCCGTTGCTCAGCCGTGCGAGTGCCCCCATTGCCCTCGTCACAAACAAAAAGAGATCATGGGCTCAGAGGCCCATGTATCGGAAGCCCAAGATGTACAGAATGTACAGAAGTCCTGATATCCCCAAGGGGTGTGAAGGCCCGTGTAAGGTCCAGTCTTTCGAGAAGAAAGACGATGTTGGTCATTCTGGTAAAATGCTCTGTATTTCTGATATCACCCGTGGCAACGGACTTAATCACCGTGTTGGGAAGAGATTTGGTATAAAATCTGTTTACATTATGGGAAAGATCTGGATGGATGAGAATATTAAGCTTAAAAATCACACTAACAACGTTTTATTTTGGTTAGTTAGAGATAGACGCCCTGTTACTACCCCTTATGCATTCCAAGAGGCATTTAATATGTTTGAGATGGAACCCAGTACGGCTACTATCAAGCAGGATTTGAGAGATCGGTTGCAGGTCTTACACAAGTTCAGTGCTACTGTCACTGGTGGACAGTATGCGTCCAGGGAGCAAGCTCTTATCAAGAGATTCTGGAAGTTGAATCATCATGTCACTTACAATCATCAAGAAGCTGCTAAATATGAGAATCACACTGAAAATGCTTTGTTATTGTATATGGCTTGCACTCATGCCAGTAATCCAGTGTATGCAACATTAAAAATTAGAGTGTATTTCTATGATTCAGAACAGAATTAATAAAGTTTGAATTTTATATCAGTAAATTGTTGAACAAACTCCGTTCCTTCTAATACATCATACAATACATATTCAACTGCCCTTATTACATTGTTAATTGAAATAACACCCAAGTTATCTAAATACATCAACACATGTTCCCTAAATAAATTCAAGAAATGCGAGTTCTGATGATGTGAGAGAGTCCAAATCTTGAAAGTCAGGAAGCACTTGTGTAAATCCAGCTGAGATCGGAGGTTGTGGTTGAATTGTATCTGTACTGTGATTATGTCCTGATTCATGTTGAATGGCCGTTGGGCGTGATTCGTGATTTTGAAATATAGGGGATTTGGCACTGTCCAAGTATACGCGCCACTCTGTGCCTGAGCTGCAGTGATGGTGACCCCTGTGCGTGAATCCATAATTTGCACACCCTAAGCTAACGTATATAGAACACCCGCAGTTTAGATCAATCCTCCTCCTGCGGGGTTGTCTCTTCTTCCCTATCTTGTGCTGGACTTTGATGGGTACCTGAGTAGAGTGGGCCGTAGAGGGTGACGAAGGTTGCATTTTTAATTGCCCAGTGTTTCAAAGATGCATTCTTCTCCTCGTTTAAATACTCAGTGTATGATGACGTTGGGCCTGGATTGCAGAGGAAGATTGTTGGGATACCACCTTTAATTTGAATTGGTTTCCCGTACTTGGTGTTGCTTTGCCAGTCTCTCTGGGCCCCCATGAATTCTTTAAAGTGTTTTAGGTAGTGGGGATCCACGTCATCAATGACGTTGTACCAGGCCTCGTTGCTGTAAACCTTGGGGCTTAAGTCAAGGTGGCCGCAAAGGTAGTTATGACGTGGATGTAGAGATCTGGCCCACATAGTCTTCCCTGTCCTGCTATCCCCTTCAATCACAATACTCATGGGCCTCCACGGCCGCGCAGCGGAATCCCTGACGTTCTCGGCAGCCCATTCTTCAAGTTGCTCTGGAACTTGATCAAAGGAAGAAGATAAAAAAGGAGAAACAAATTCCTCCAACAGAGGAGCAAAAATCCTATCTAAATTACTATTTAAATTATGAAATTGTAAAATATAATCTTTGGGAGCTTTCTCCCTTAATATAGACAAGGCCGATGACTTGGACCCTGAGTTGATTGCCTCGGCATATGCGTCGTTGGCAGACTGGCAACCTCCTCTAGCTGATCTTCCATCGACTTGGAAAACTCCAAAATCAAGGATGTCCCCGTCTTTTTCCATGTAGGTCTTGACATCTGACGAGCTCTTAGCTCCCTGAATGTTCGGATGGAAATGTGCTGACCTAGTTGGGGATACGAGATCGAAGAATCGTTGATTTCGGCATGTATATTTTCCTTCGAATTGGATGAGGACGTGGAGATGAGGGCTCCCATCTTCGTGTAGTTCACGACAAATTCGGATGAATAATTTATTAGTTGGGGTTTGTAGGGCTTGTATTTGGGAGAGAGCCTCTTCTTTTGTAAGAGAGCAGTGTGGGTATGTGAGAAAATAATTCTTGGCATTTATTTTAAAACGATTTGGGGTAGGCATGTTGACTGGTCAATCGGGAGGCTCTCAATCTTTCTATGCAATTGGGGGCATTGGGGGCTTATTTATATGGTAGCCTCTAATGGCATATTTGTAATTTTGAAATTCAAATTCAAAATTCAAATTGGTAAAGCGGCCATCCCGTATAATATT
Gene Information
|
NCBI Accession
|
YP_010084308.1
|
|
Location
|
136-486 |
|
Gene Name
|
V2 |
|
Protein Name
|
V2 |
|
Coding Region
|
ATGTGGGATCCTTTACTTAACGATTTCCCTGAAACCGTTCACGGTTTCAGGTGTATGCTAGCGGTTAAGTACCTTCTACTCGTTGAAGCTACCTACTCTCCGGATACTATAGGTTACGATCTGATTCGTGATCTTGTGGGTGTTGTTCGTGCCAAGAACTATGTCGAAGCGTCCTGCAGATATAGGAATTTTCACTCCCGTCTCCAGAGCACGACGCCGTCTGAACTTCGACAGCCCGTTGCTCAGCCGTGCGAGTGCCCCCATTGCCCTCGTCACAAACAAAAAGAGATCATGGGCTCAGAGGCCCATGTATCGGAAGCCCAAGATGTACAGAATGTACAGAAGTCCTGA |
|
Protein Sequence
|
MWDPLLNDFPETVHGFRCMLAVKYLLLVEATYSPDTIGYDLIRDLVGVVRAKNYVEASCRYRNFHSRLQSTTPSELRQPVAQPCECPHCPRHKQKEIMGSEAHVSEAQDVQNVQKS |
|
NCBI Accession
|
YP_010084309.1
|
|
Location
|
296-1069 |
|
Gene Name
|
V1 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGTCGAAGCGTCCTGCAGATATAGGAATTTTCACTCCCGTCTCCAGAGCACGACGCCGTCTGAACTTCGACAGCCCGTTGCTCAGCCGTGCGAGTGCCCCCATTGCCCTCGTCACAAACAAAAAGAGATCATGGGCTCAGAGGCCCATGTATCGGAAGCCCAAGATGTACAGAATGTACAGAAGTCCTGATATCCCCAAGGGGTGTGAAGGCCCGTGTAAGGTCCAGTCTTTCGAGAAGAAAGACGATGTTGGTCATTCTGGTAAAATGCTCTGTATTTCTGATATCACCCGTGGCAACGGACTTAATCACCGTGTTGGGAAGAGATTTGGTATAAAATCTGTTTACATTATGGGAAAGATCTGGATGGATGAGAATATTAAGCTTAAAAATCACACTAACAACGTTTTATTTTGGTTAGTTAGAGATAGACGCCCTGTTACTACCCCTTATGCATTCCAAGAGGCATTTAATATGTTTGAGATGGAACCCAGTACGGCTACTATCAAGCAGGATTTGAGAGATCGGTTGCAGGTCTTACACAAGTTCAGTGCTACTGTCACTGGTGGACAGTATGCGTCCAGGGAGCAAGCTCTTATCAAGAGATTCTGGAAGTTGAATCATCATGTCACTTACAATCATCAAGAAGCTGCTAAATATGAGAATCACACTGAAAATGCTTTGTTATTGTATATGGCTTGCACTCATGCCAGTAATCCAGTGTATGCAACATTAAAAATTAGAGTGTATTTCTATGATTCAGAACAGAATTAA |
|
Protein Sequence
|
MSKRPADIGIFTPVSRARRRLNFDSPLLSRASAPIALVTNKKRSWAQRPMYRKPKMYRMYRSPDIPKGCEGPCKVQSFEKKDDVGHSGKMLCISDITRGNGLNHRVGKRFGIKSVYIMGKIWMDENIKLKNHTNNVLFWLVRDRRPVTTPYAFQEAFNMFEMEPSTATIKQDLRDRLQVLHKFSATVTGGQYASREQALIKRFWKLNHHVTYNHQEAAKYENHTENALLLYMACTHASNPVYATLKIRVYFYDSEQN |
|
NCBI Accession
|
YP_010084310.1
|
|
Location
|
1066-1470 |
|
Gene Name
|
C3 |
|
Protein Name
|
C3 |
|
Coding Region
|
ATGGATTCACGCACAGGGGTCACCATCACTGCAGCTCAGGCACAGAGTGGCGCGTATACTTGGACAGTGCCAAATCCCCTATATTTCAAAATCACGAATCACGCCCAACGGCCATTCAACATGAATCAGGACATAATCACAGTACAGATACAATTCAACCACAACCTCCGATCTCAGCTGGATTTACACAAGTGCTTCCTGACTTTCAAGATTTGGACTCTCTCACATCATCAGAACTCGCATTTCTTGAATTTATTTAGGGAACATGTGTTGATGTATTTAGATAACTTGGGTGTTATTTCAATTAACAATGTAATAAGGGCAGTTGAATATGTATTGTATGATGTATTAGAAGGAACGGAGTTTGTTCAACAATTTACTGATATAAAATTCAAACTTTATTAA |
|
Protein Sequence
|
MDSRTGVTITAAQAQSGAYTWTVPNPLYFKITNHAQRPFNMNQDIITVQIQFNHNLRSQLDLHKCFLTFKIWTLSHHQNSHFLNLFREHVLMYLDNLGVISINNVIRAVEYVLYDVLEGTEFVQQFTDIKFKLY |
|
NCBI Accession
|
YP_010084311.1
|
|
Location
|
1211-1618 |
|
Gene Name
|
C2 |
|
Protein Name
|
C2 |
|
Coding Region
|
ATGCAACCTTCGTCACCCTCTACGGCCCACTCTACTCAGGTACCCATCAAAGTCCAGCACAAGATAGGGAAGAAGAGACAACCCCGCAGGAGGAGGATTGATCTAAACTGCGGGTGTTCTATATACGTTAGCTTAGGGTGTGCAAATTATGGATTCACGCACAGGGGTCACCATCACTGCAGCTCAGGCACAGAGTGGCGCGTATACTTGGACAGTGCCAAATCCCCTATATTTCAAAATCACGAATCACGCCCAACGGCCATTCAACATGAATCAGGACATAATCACAGTACAGATACAATTCAACCACAACCTCCGATCTCAGCTGGATTTACACAAGTGCTTCCTGACTTTCAAGATTTGGACTCTCTCACATCATCAGAACTCGCATTTCTTGAATTTATTTAG |
|
Protein Sequence
|
MQPSSPSTAHSTQVPIKVQHKIGKKRQPRRRRIDLNCGCSIYVSLGCANYGFTHRGHHHCSSGTEWRVYLDSAKSPIFQNHESRPTAIQHESGHNHSTDTIQPQPPISAGFTQVLPDFQDLDSLTSSELAFLEFI |
|
NCBI Accession
|
YP_010084312.1
|
|
Location
|
1518-2609 |
|
Gene Name
|
Rep |
|
Protein Name
|
replication-associated protein |
|
Coding Region
|
ATGCCTACCCCAAATCGTTTTAAAATAAATGCCAAGAATTATTTTCTCACATACCCACACTGCTCTCTTACAAAAGAAGAGGCTCTCTCCCAAATACAAGCCCTACAAACCCCAACTAATAAATTATTCATCCGAATTTGTCGTGAACTACACGAAGATGGGAGCCCTCATCTCCACGTCCTCATCCAATTCGAAGGAAAATATACATGCCGAAATCAACGATTCTTCGATCTCGTATCCCCAACTAGGTCAGCACATTTCCATCCGAACATTCAGGGAGCTAAGAGCTCGTCAGATGTCAAGACCTACATGGAAAAAGACGGGGACATCCTTGATTTTGGAGTTTTCCAAGTCGATGGAAGATCAGCTAGAGGAGGTTGCCAGTCTGCCAACGACGCATATGCCGAGGCAATCAACTCAGGGTCCAAGTCATCGGCCTTGTCTATATTAAGGGAGAAAGCTCCCAAAGATTATATTTTACAATTTCATAATTTAAATAGTAATTTAGATAGGATTTTTGCTCCTCTGTTGGAGGAATTTGTTTCTCCTTTTTTATCTTCTTCCTTTGATCAAGTTCCAGAGCAACTTGAAGAATGGGCTGCCGAGAACGTCAGGGATTCCGCTGCGCGGCCGTGGAGGCCCATGAGTATTGTGATTGAAGGGGATAGCAGGACAGGGAAGACTATGTGGGCCAGATCTCTACATCCACGTCATAACTACCTTTGCGGCCACCTTGACTTAAGCCCCAAGGTTTACAGCAACGAGGCCTGGTACAACGTCATTGATGACGTGGATCCCCACTACCTAAAACACTTTAAAGAATTCATGGGGGCCCAGAGAGACTGGCAAAGCAACACCAAGTACGGGAAACCAATTCAAATTAAAGGTGGTATCCCAACAATCTTCCTCTGCAATCCAGGCCCAACGTCATCATACACTGAGTATTTAAACGAGGAGAAGAATGCATCTTTGAAACACTGGGCAATTAAAAATGCAACCTTCGTCACCCTCTACGGCCCACTCTACTCAGGTACCCATCAAAGTCCAGCACAAGATAGGGAAGAAGAGACAACCCCGCAGGAGGAGGATTGA |
|
Protein Sequence
|
MPTPNRFKINAKNYFLTYPHCSLTKEEALSQIQALQTPTNKLFIRICRELHEDGSPHLHVLIQFEGKYTCRNQRFFDLVSPTRSAHFHPNIQGAKSSSDVKTYMEKDGDILDFGVFQVDGRSARGGCQSANDAYAEAINSGSKSSALSILREKAPKDYILQFHNLNSNLDRIFAPLLEEFVSPFLSSSFDQVPEQLEEWAAENVRDSAARPWRPMSIVIEGDSRTGKTMWARSLHPRHNYLCGHLDLSPKVYSNEAWYNVIDDVDPHYLKHFKEFMGAQRDWQSNTKYGKPIQIKGGIPTIFLCNPGPTSSYTEYLNEEKNASLKHWAIKNATFVTLYGPLYSGTHQSPAQDREEETTPQEED |
|
NCBI Accession
|
YP_010084313.1
|
|
Location
|
2159-2581 |
|
Gene Name
|
C4 |
|
Protein Name
|
C4 |
|
Coding Region
|
ATGCCAAGAATTATTTTCTCACATACCCACACTGCTCTCTTACAAAAGAAGAGGCTCTCTCCCAAATACAAGCCCTACAAACCCCAACTAATAAATTATTCATCCGAATTTGTCGTGAACTACACGAAGATGGGAGCCCTCATCTCCACGTCCTCATCCAATTCGAAGGAAAATATACATGCCGAAATCAACGATTCTTCGATCTCGTATCCCCAACTAGGTCAGCACATTTCCATCCGAACATTCAGGGAGCTAAGAGCTCGTCAGATGTCAAGACCTACATGGAAAAAGACGGGGACATCCTTGATTTTGGAGTTTTCCAAGTCGATGGAAGATCAGCTAGAGGAGGTTGCCAGTCTGCCAACGACGCATATGCCGAGGCAATCAACTCAGGGTCCAAGTCATCGGCCTTGTCTATATTAA |
|
Protein Sequence
|
MPRIIFSHTHTALLQKKRLSPKYKPYKPQLINYSSEFVVNYTKMGALISTSSSNSKENIHAEINDSSISYPQLGQHISIRTFRELRARQMSRPTWKKTGTSLILEFSKSMEDQLEEVASLPTTHMPRQSTQGPSHRPCLY |