Tomato leaf curl Ghana virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_000874905.1 |
| Isolate |
Ghana:Akumadan |
| Release date |
2015/2/13 |
| Submitter |
Osei,M.K., Akromah,R., Shih,S.L., Lee,L.M., Green,S.K. |
| Host |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
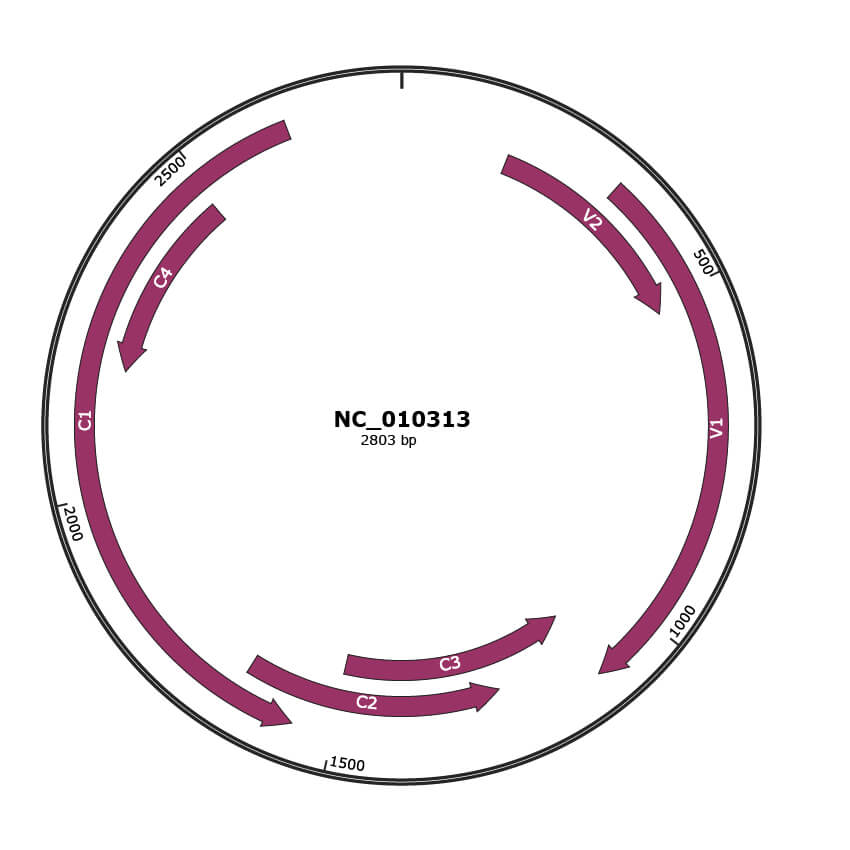
JBrowse
Genome
ACCGGATGGCCGCGATTTTTTTTCCACTACACGCTCCAAAGCAAAAGTAAAGTAATCAATGGTCCCCACGCACTAGTTTATGTTGGCCAATCAGAATGAGGCCCGAAAGCTTCGTTGTTTTCCCGCTTGTCCTTATATACTTGCGCACTAAGTTGTAATAATTGCACTATGTGGGACCCTTTATTGAATGAGTTCCCAGACTCAGTCCATGGGTTTCGTTGTATGCTGGCTATAAAATATCTGCAGCTCTTAGAAGAGGAGTACGAGCCCAATACTTTGGGCCACGATTTAGTTAGAGATCTCATTTCTGTCATTAGGGCTAAAAATTATGTCGAAGCGTCCCGGCGATATAATAATTTCCACGCCCGTCTCGAAGGTGCGTCGACGGCTGAACTTCGACAGCCCCTACGCCAGCCGTGCAGTTGTCCCCACTGTCCGAGGCATAAGCAAGCGTCGTTCGTGGACGTACGGGCCCATGTACCGAAAGCCCAGAATGTATCGGATGTACAAAAGCCCTGATGTGCCCCGTGGATGTGAAGGCCCGTGTAAGATACAGTCATTTGAGCAAAGGGATGATGTTAAGCATGTTGGTATAGTTCGTTGTGTTAGTGATGTGACCCGTGGGTCCGGTCTGACTCATAGAGTAGGGAAGAGATTTTGCATTAAGTCTATTTACATTTTAGGTAAAGTTTGGATGGACGAAAACATCAAAAAGCAGAATCATACTAACAATGTTATGTTTTTCTTAGTTCGTGATAGAAGGCCTTATGGCAGTCCTAGTGATTTCGGGCAGATTTTTAACATGTTCGACAACGAGCCGAGTACAGCTACAATCAAGAATGATCTCAGAGACCGCTATCAAGTGCTTCGTAAATTCAGTGCAACTGTTATTGGTGGTCCCTCTGGATGCAAGGAACAGGCTTTGGTGAAGAGATTTTTTAAGGTTAACAATCATGTTGTGTATAACCATCAGGAGGAGGCTAAATATGCCAACCATACTGAGAATGCTTTGTTGTTGTATATGGCTTGTACTCATGCTTCGAATCCCGTGTATGCTACTCTAAAAATACGCATCTATTTCTACGATGCAGTTACGAATTAATAAATATTAAATTTTATTTCATGTTGTTCTAATACACAATTTGTACCTTCAAGTACGTTGTACAATACATGATCAACTGCTCTAATAATTGCATTAATTGAAATTACACCCAAATTATCTAAATATTTAAACACTTGAACTCTAAATACCCTTAAGAAACGACCAGTCTGAGGGCGTAAGCTCGTCCAAACTTTGAAGTTCAGAAAACACTTGTGAATCCCCAACGCCTTCCGCAGGTTGTGGTTGAACCTGATTTGAACTGTGATTATGTCGTGTTGGTAGTTGAACGGTCTCTCGTCGTGGTTGGTTATCTTGAAATACAGGGGATTTTGTATCTCCCAGATAAAAACGCCACTCTGTGCTTGAGCTGCAGTGATGAGTTCCCCGGTGCGTAAATCCATTATTGGCGCAGTTGATGTGTATGAAGACTGAACACCCGCACTCTAGGTCCACCCTTTTACGCCTCACTACTTTCTTCTTCGCGATGCGGTGCTGGACTTTGATTGGCACTTGTGTACAATGGCTCGTGGAGGGTGATGAAGATCGCATTTTTTATTGCCCATGCTTTCAATGGTGCATTTTTCACTTCGTCTAGAAACTCTTTATATGATGATGTCGGGCCTGGATTGCAGAGGAAGATAGTGGGAATTCCACCTTTAATTTGAATGGGCTTCCCGTATTTGGTGTTGCTTTGCCAGTCCCTTTGGGCCCCCATGAACTCTTTAAAGTGTTTGAGATAGTGGGGATCGACGTCATCAATGACGTTATACCAAGCATCATTTGAATACACCTTTGGACTCAGGTCTAGATGGCCACACAAGTAATTGTGTGGACCTAATGACCTGGCCCACATTGTCTTGCCTGTACGACTATCACCTTCAATAACTATATTAACCGGTCTCCAAGGCCGCGCAGCGGCATCCATTACATTCTCGGAAACCCACTCTTCAAGTTCTTCCGGAACTTGATTAAAAGAAGAAGATAAAAAGGGAGAAACATAAGGAGCTGGAGGCTCCTGAAAAATCCTATCTAAATTACTATTTAAATTATGAAATTGCAAGACAAAATCTTTTGGAGCTAACTCCTTTACAATTCTAAGAGCTTCTGCCTTACTTCCTGCGTTAAGCGCCTGGGCGTAAGCGTCATTGGCAGATTGTTGTCCTCCTCTTGCCGATCTTCCGTCGATCTGAAACTCTCCCCATTCAAGGGTGTCTCCGTCTTTATCGATATAGGACTTGACGTCGGAGCTGGATTTAGCTCCCTGAATGTTTGGATGGAAATGTGCTGACCGGGTCGGGGATACCAAGTCGAAGAATCTGTTATTTTGGCATTTGTATTTCCCCTCGAATTGAATGAGCGCATGCAGATGAGGTTCCCCATTTTCATGCAGTTCTCTGCAGATTTTGATATATTTTTTGTTTGTGGGTGTTTGGAGATTTTGAAGAAGGGAAAGTGCCTCTTCTTTAGTTAGAGAGCATTGTGGATAAGTTAGAAAATAATTTTTGGCATTTATAAGAAACTTACGTGGAGGAGCCATTTAGTCAGAGGACCTGATTGACCAGCTCTTCTATATCAAATGAATCGGGGAATGGGTCTCTATATATACTGAGGACCCTAATGGCATTATTGTAATTATGAAAAGATTTTACTTTAATTCGAATTTCAAATTCGAATACCCAAAGCGGCCATCCGTATAATATT
Gene Information
|
NCBI Accession
|
YP_001661650.1
|
|
Location
|
169-519 |
|
Gene Name
|
V2 |
|
Protein Name
|
pre-coat protein |
|
Coding Region
|
ATGTGGGACCCTTTATTGAATGAGTTCCCAGACTCAGTCCATGGGTTTCGTTGTATGCTGGCTATAAAATATCTGCAGCTCTTAGAAGAGGAGTACGAGCCCAATACTTTGGGCCACGATTTAGTTAGAGATCTCATTTCTGTCATTAGGGCTAAAAATTATGTCGAAGCGTCCCGGCGATATAATAATTTCCACGCCCGTCTCGAAGGTGCGTCGACGGCTGAACTTCGACAGCCCCTACGCCAGCCGTGCAGTTGTCCCCACTGTCCGAGGCATAAGCAAGCGTCGTTCGTGGACGTACGGGCCCATGTACCGAAAGCCCAGAATGTATCGGATGTACAAAAGCCCTGA |
|
Protein Sequence
|
MWDPLLNEFPDSVHGFRCMLAIKYLQLLEEEYEPNTLGHDLVRDLISVIRAKNYVEASRRYNNFHARLEGASTAELRQPLRQPCSCPHCPRHKQASFVDVRAHVPKAQNVSDVQKP |
|
NCBI Accession
|
YP_001661651.1
|
|
Location
|
329-1102 |
|
Gene Name
|
V1 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGTCGAAGCGTCCCGGCGATATAATAATTTCCACGCCCGTCTCGAAGGTGCGTCGACGGCTGAACTTCGACAGCCCCTACGCCAGCCGTGCAGTTGTCCCCACTGTCCGAGGCATAAGCAAGCGTCGTTCGTGGACGTACGGGCCCATGTACCGAAAGCCCAGAATGTATCGGATGTACAAAAGCCCTGATGTGCCCCGTGGATGTGAAGGCCCGTGTAAGATACAGTCATTTGAGCAAAGGGATGATGTTAAGCATGTTGGTATAGTTCGTTGTGTTAGTGATGTGACCCGTGGGTCCGGTCTGACTCATAGAGTAGGGAAGAGATTTTGCATTAAGTCTATTTACATTTTAGGTAAAGTTTGGATGGACGAAAACATCAAAAAGCAGAATCATACTAACAATGTTATGTTTTTCTTAGTTCGTGATAGAAGGCCTTATGGCAGTCCTAGTGATTTCGGGCAGATTTTTAACATGTTCGACAACGAGCCGAGTACAGCTACAATCAAGAATGATCTCAGAGACCGCTATCAAGTGCTTCGTAAATTCAGTGCAACTGTTATTGGTGGTCCCTCTGGATGCAAGGAACAGGCTTTGGTGAAGAGATTTTTTAAGGTTAACAATCATGTTGTGTATAACCATCAGGAGGAGGCTAAATATGCCAACCATACTGAGAATGCTTTGTTGTTGTATATGGCTTGTACTCATGCTTCGAATCCCGTGTATGCTACTCTAAAAATACGCATCTATTTCTACGATGCAGTTACGAATTAA |
|
Protein Sequence
|
MSKRPGDIIISTPVSKVRRRLNFDSPYASRAVVPTVRGISKRRSWTYGPMYRKPRMYRMYKSPDVPRGCEGPCKIQSFEQRDDVKHVGIVRCVSDVTRGSGLTHRVGKRFCIKSIYILGKVWMDENIKKQNHTNNVMFFLVRDRRPYGSPSDFGQIFNMFDNEPSTATIKNDLRDRYQVLRKFSATVIGGPSGCKEQALVKRFFKVNNHVVYNHQEEAKYANHTENALLLYMACTHASNPVYATLKIRIYFYDAVTN |
|
NCBI Accession
|
YP_001661652.1
|
|
Location
|
1099-1503 |
|
Gene Name
|
C3 |
|
Protein Name
|
replication enhancement protein |
|
Coding Region
|
ATGGATTTACGCACCGGGGAACTCATCACTGCAGCTCAAGCACAGAGTGGCGTTTTTATCTGGGAGATACAAAATCCCCTGTATTTCAAGATAACCAACCACGACGAGAGACCGTTCAACTACCAACACGACATAATCACAGTTCAAATCAGGTTCAACCACAACCTGCGGAAGGCGTTGGGGATTCACAAGTGTTTTCTGAACTTCAAAGTTTGGACGAGCTTACGCCCTCAGACTGGTCGTTTCTTAAGGGTATTTAGAGTTCAAGTGTTTAAATATTTAGATAATTTGGGTGTAATTTCAATTAATGCAATTATTAGAGCAGTTGATCATGTATTGTACAACGTACTTGAAGGTACAAATTGTGTATTAGAACAACATGAAATAAAATTTAATATTTATTAA |
|
Protein Sequence
|
MDLRTGELITAAQAQSGVFIWEIQNPLYFKITNHDERPFNYQHDIITVQIRFNHNLRKALGIHKCFLNFKVWTSLRPQTGRFLRVFRVQVFKYLDNLGVISINAIIRAVDHVLYNVLEGTNCVLEQHEIKFNIY |
|
NCBI Accession
|
YP_001661653.1
|
|
Location
|
1244-1651 |
|
Gene Name
|
C2 |
|
Protein Name
|
transcriptional activation protein |
|
Coding Region
|
ATGCGATCTTCATCACCCTCCACGAGCCATTGTACACAAGTGCCAATCAAAGTCCAGCACCGCATCGCGAAGAAGAAAGTAGTGAGGCGTAAAAGGGTGGACCTAGAGTGCGGGTGTTCAGTCTTCATACACATCAACTGCGCCAATAATGGATTTACGCACCGGGGAACTCATCACTGCAGCTCAAGCACAGAGTGGCGTTTTTATCTGGGAGATACAAAATCCCCTGTATTTCAAGATAACCAACCACGACGAGAGACCGTTCAACTACCAACACGACATAATCACAGTTCAAATCAGGTTCAACCACAACCTGCGGAAGGCGTTGGGGATTCACAAGTGTTTTCTGAACTTCAAAGTTTGGACGAGCTTACGCCCTCAGACTGGTCGTTTCTTAAGGGTATTTAG |
|
Protein Sequence
|
MRSSSPSTSHCTQVPIKVQHRIAKKKVVRRKRVDLECGCSVFIHINCANNGFTHRGTHHCSSSTEWRFYLGDTKSPVFQDNQPRRETVQLPTRHNHSSNQVQPQPAEGVGDSQVFSELQSLDELTPSDWSFLKGI |
|
NCBI Accession
|
YP_001661654.1
|
|
Location
|
1560-2639 |
|
Gene Name
|
C1 |
|
Protein Name
|
replication-associated protein |
|
Coding Region
|
ATGGCTCCTCCACGTAAGTTTCTTATAAATGCCAAAAATTATTTTCTAACTTATCCACAATGCTCTCTAACTAAAGAAGAGGCACTTTCCCTTCTTCAAAATCTCCAAACACCCACAAACAAAAAATATATCAAAATCTGCAGAGAACTGCATGAAAATGGGGAACCTCATCTGCATGCGCTCATTCAATTCGAGGGGAAATACAAATGCCAAAATAACAGATTCTTCGACTTGGTATCCCCGACCCGGTCAGCACATTTCCATCCAAACATTCAGGGAGCTAAATCCAGCTCCGACGTCAAGTCCTATATCGATAAAGACGGAGACACCCTTGAATGGGGAGAGTTTCAGATCGACGGAAGATCGGCAAGAGGAGGACAACAATCTGCCAATGACGCTTACGCCCAGGCGCTTAACGCAGGAAGTAAGGCAGAAGCTCTTAGAATTGTAAAGGAGTTAGCTCCAAAAGATTTTGTCTTGCAATTTCATAATTTAAATAGTAATTTAGATAGGATTTTTCAGGAGCCTCCAGCTCCTTATGTTTCTCCCTTTTTATCTTCTTCTTTTAATCAAGTTCCGGAAGAACTTGAAGAGTGGGTTTCCGAGAATGTAATGGATGCCGCTGCGCGGCCTTGGAGACCGGTTAATATAGTTATTGAAGGTGATAGTCGTACAGGCAAGACAATGTGGGCCAGGTCATTAGGTCCACACAATTACTTGTGTGGCCATCTAGACCTGAGTCCAAAGGTGTATTCAAATGATGCTTGGTATAACGTCATTGATGACGTCGATCCCCACTATCTCAAACACTTTAAAGAGTTCATGGGGGCCCAAAGGGACTGGCAAAGCAACACCAAATACGGGAAGCCCATTCAAATTAAAGGTGGAATTCCCACTATCTTCCTCTGCAATCCAGGCCCGACATCATCATATAAAGAGTTTCTAGACGAAGTGAAAAATGCACCATTGAAAGCATGGGCAATAAAAAATGCGATCTTCATCACCCTCCACGAGCCATTGTACACAAGTGCCAATCAAAGTCCAGCACCGCATCGCGAAGAAGAAAGTAGTGAGGCGTAA |
|
Protein Sequence
|
MAPPRKFLINAKNYFLTYPQCSLTKEEALSLLQNLQTPTNKKYIKICRELHENGEPHLHALIQFEGKYKCQNNRFFDLVSPTRSAHFHPNIQGAKSSSDVKSYIDKDGDTLEWGEFQIDGRSARGGQQSANDAYAQALNAGSKAEALRIVKELAPKDFVLQFHNLNSNLDRIFQEPPAPYVSPFLSSSFNQVPEELEEWVSENVMDAAARPWRPVNIVIEGDSRTGKTMWARSLGPHNYLCGHLDLSPKVYSNDAWYNVIDDVDPHYLKHFKEFMGAQRDWQSNTKYGKPIQIKGGIPTIFLCNPGPTSSYKEFLDEVKNAPLKAWAIKNAIFITLHEPLYTSANQSPAPHREEESSEA |
|
NCBI Accession
|
YP_001661655.1
|
|
Location
|
2189-2488 |
|
Gene Name
|
C4 |
|
Protein Name
|
C4 protein |
|
Coding Region
|
ATGAAAATGGGGAACCTCATCTGCATGCGCTCATTCAATTCGAGGGGAAATACAAATGCCAAAATAACAGATTCTTCGACTTGGTATCCCCGACCCGGTCAGCACATTTCCATCCAAACATTCAGGGAGCTAAATCCAGCTCCGACGTCAAGTCCTATATCGATAAAGACGGAGACACCCTTGAATGGGGAGAGTTTCAGATCGACGGAAGATCGGCAAGAGGAGGACAACAATCTGCCAATGACGCTTACGCCCAGGCGCTTAACGCAGGAAGTAAGGCAGAAGCTCTTAGAATTGTAA |
|
Protein Sequence
|
MKMGNLICMRSFNSRGNTNAKITDSSTWYPRPGQHISIQTFRELNPAPTSSPISIKTETPLNGESFRSTEDRQEEDNNLPMTLTPRRLTQEVRQKLLEL |