Tomato leaf curl Diana virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_002986995.1 |
| Isolate |
Madagascar:Diana, Namakely |
| Release date |
2018/8/26 |
| Submitter |
Lefeuvre,P., Martin,D.P., Hoareau,M., Naze,F., Becker,N., Delatte,H., Reynaud,B., Lett,J.M. |
| Host |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
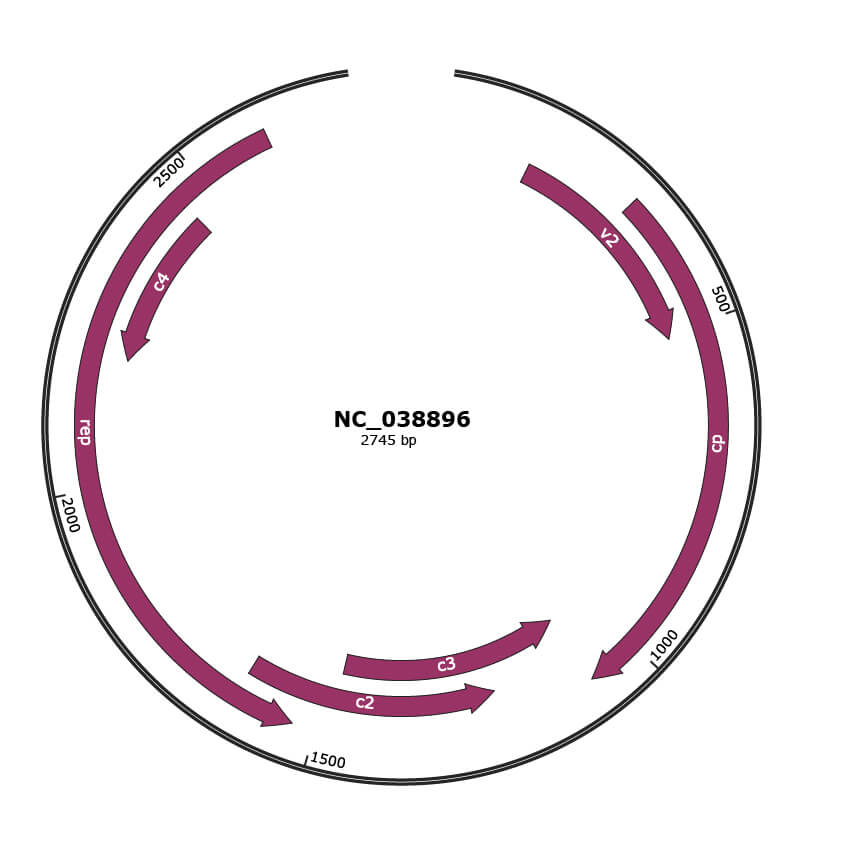
JBrowse
Genome
ACCGGTGGGCGCGAAAAAAAAAAGTGGGCCCTACCACGTGATCATGTCGCGCGAGTGCTGTCCAATCAGAACGCGCGCTCTACGCATTATAAATTAAAATTTGAAATATATACTTCCTCGCGAAGGAGTTATCCCACAAAATGTGGGATCCACTTTTAAACGAGTTTCCAGAAACCGTTCACGGTTTCCGTTGTATGCTAGCTATCAAATACCTGCAGGCGGTCAGAGAGTCTTACGATCCCAGCACACTTGGTTACGATCTTCTAAGCGATCTCATCGGAGTTGTCCGCCGTACCAATTATGTCGAAGCGACCAGCAGATATCATCATTTCCACTCCCGCCTCGAAAGTGCGTCGCCGTCTGAACTTCGACAGCCCCGTGCAGTCCTCTGCTCGTGCCCCCACTGTCCTCGTCACAAACAAACGTCGGGCCTGGACCAACAGGCCCAATTACAGAAAGCCCAGGATGTACAGAATGTATCGCAGCCCAGATGTCCCAAAGGGTTGTGAAGGCCCGTGTAAGGTCCAGTCATATGATCAGCGTGATGATGTCAAACATACTGGTATTGTTAGATGTGTGTCCGATGTCACCAAGGGTCCTGGCCTTACACACCGCATTGGAAAGCGTTTTACGATCAAGTCCATCTACATCCTGGGGAAGATATGGATGGATGAGAACATCAAGAAACAGAATCACACTAACACTGTAATGTTTTTCCTTGTCCGAGATAGAAGACCTTATGGGAACTCTCCATTGGATTTTGGTCAAGTTTTTAACATGTTTGACAACGAACCTAGCACTGCTACGGTCAAGAACGATCTCCGTGATCATTTCCAGGTGATTAGGAAGTTTACTGCTACTGTCACTGGTGGTCCTTCGGGATGTAAGGAACAAGCACTGGTTCGTCGTTTTTTTAAGATTAATAGTCAGATTGTTTACAACCATCAAGATGCTGGAAAGTTCGAAAATCATACTGAGAATGCTATCTTGTTGTACATGGCATGTACTCATGCCTCTAATCCTGTGTACGCTACTCTTAAGATACGGATATATTTCTACGATTCTGTATCGAATTAATAAATATTGAATTTTATTTCATGATTCTCCTTAACTTGGAGTGTATTGATAAGTACATCGTATAATACATGATCAATTGCTTTGATTACATTATTAATTGAAATAACCCCTAATCTATCTAAATATTTTAAAACTTGGGTCCTAAATACCCTTAAGAAAAGACCAGTCTGAGGCCGTGAGGTCGTCCAGACCCTGAAGTTGAGAAAACATTTGTGAATCCCCAGTTCTTTCCTCAAGTTGTGGTTGAACCGTATCTGGACTGATATGATGTCGTGGGGCATGTTGAACGGCCTGTTCTCGTGGTCGATAATCTTGAAATACAGGGGATTTTGTATCTCCCAGATAAACACGCCACTCTGTGCTTGAGCTGCAGTGATGAGTTCCCCGGTGCGTAAATCCATGGTTTATGCAGTTGATGTGTATATAGTATGAGCAGCCGCAGTCGAGATCTATCCTTCTACGCCTGATTGCTCTCTTCTTCGCCTCCCGATGTTGAACCTTGATTGGAACCTGAGAACAGTGGCTCGGAGAGGGTGACAAAGACCGCATTCTTTAATGCCCAGGATTTGAGATGCGTGTTCTTGTCCTCGTCTAAAAACTCTTTATACGAGGAATTTGGACCTGGATTGCATAGGAAGATTGTTGGAATGCCCCCTTTAATTTGAACTGGCTTCCCGTACTTTGTGTTGCTTTGCCAGTCCTTCTGGGCCCCCATGAACTCTTTAAAGTGTTTCAGATAATGCGGGTCGACGTCATCGATGACGTTATACCATGCGTCATTACTGAACACCTTTGGGCTTAGGTCTAAATGGCCGCACAGATAATTGTGAGGCCCAAGGCTTCTGGCCCATACAGTCTTCCCCGTCCTGCTCTCCCCTTCTACTACTATACTAATCGGCCTACTTGGCCGCGCAGCGGCATCCATGACGTTCTCCGCCGCCCATTGTTCAAGTTCTTCTGGAACTTGATCGAAAGAAGAAGACAAAAAGGGACATGAATAAGGCTCTATGGGAGCCTGAAAAATCATATCTAAATTTGATTTTAAATTATGATATTGAAAAATAAAATCTTTAGGGAGCTTCTCCCTTATAATAGCCAGAGCGGCTTCAGCGGAACCTGCGTTTAATGCGTCTGCACATGCGTCGTTAGCATTCTGGCAGCCTCCTCGAGCACTTCTGCCGTCGACCTGGAATTCTCCCCATTCCAGTGTGTCTCCGTCCTTGTCGATGTAGGACTTGACATCGGAGCTGGATTTAGCTCCCTGAATGTTCGGATGGAAATGTGCTGACCTGGTTGGGGAAACCAGGTCGAAGAATCGCTGATTCTGGCACTTGTATTTTCCCTCGAACTGGATAAGCACATGGAGATGAGGTTCCCCATTCTCGTGTAGTTCCCTGCAGATCTTGATGTATTTCTTATTGACGGGTGTATTTAGGTTTTGCAATTGGGAAAGTGCTTCCTCTTTGGTGAGGGAGCATTGTGGATAAGTGAGAAAATAATTTTTGCAATTTATCAGGAATCGCTTTGGAGGAGCCATTTGACTTGGTCAATCGGGTCTCATTGCATCTCCCCGGTATATGAGGTCCTCTTTTATAGTGAGACCCAAATGGCATTATGGTAAAAACTCCAATAAATTTGAACCCCCATAGCGCCCACCGTTTTAATATT
Gene Information
|
NCBI Accession
|
YP_009508185.1
|
|
Location
|
141-509 |
|
Gene Name
|
v2 |
|
Protein Name
|
V2 protein |
|
Coding Region
|
ATGTGGGATCCACTTTTAAACGAGTTTCCAGAAACCGTTCACGGTTTCCGTTGTATGCTAGCTATCAAATACCTGCAGGCGGTCAGAGAGTCTTACGATCCCAGCACACTTGGTTACGATCTTCTAAGCGATCTCATCGGAGTTGTCCGCCGTACCAATTATGTCGAAGCGACCAGCAGATATCATCATTTCCACTCCCGCCTCGAAAGTGCGTCGCCGTCTGAACTTCGACAGCCCCGTGCAGTCCTCTGCTCGTGCCCCCACTGTCCTCGTCACAAACAAACGTCGGGCCTGGACCAACAGGCCCAATTACAGAAAGCCCAGGATGTACAGAATGTATCGCAGCCCAGATGTCCCAAAGGGTTGTGA |
|
Protein Sequence
|
MWDPLLNEFPETVHGFRCMLAIKYLQAVRESYDPSTLGYDLLSDLIGVVRRTNYVEATSRYHHFHSRLESASPSELRQPRAVLCSCPHCPRHKQTSGLDQQAQLQKAQDVQNVSQPRCPKGL |
|
NCBI Accession
|
YP_009508186.1
|
|
Location
|
301-1077 |
|
Gene Name
|
cp |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGTCGAAGCGACCAGCAGATATCATCATTTCCACTCCCGCCTCGAAAGTGCGTCGCCGTCTGAACTTCGACAGCCCCGTGCAGTCCTCTGCTCGTGCCCCCACTGTCCTCGTCACAAACAAACGTCGGGCCTGGACCAACAGGCCCAATTACAGAAAGCCCAGGATGTACAGAATGTATCGCAGCCCAGATGTCCCAAAGGGTTGTGAAGGCCCGTGTAAGGTCCAGTCATATGATCAGCGTGATGATGTCAAACATACTGGTATTGTTAGATGTGTGTCCGATGTCACCAAGGGTCCTGGCCTTACACACCGCATTGGAAAGCGTTTTACGATCAAGTCCATCTACATCCTGGGGAAGATATGGATGGATGAGAACATCAAGAAACAGAATCACACTAACACTGTAATGTTTTTCCTTGTCCGAGATAGAAGACCTTATGGGAACTCTCCATTGGATTTTGGTCAAGTTTTTAACATGTTTGACAACGAACCTAGCACTGCTACGGTCAAGAACGATCTCCGTGATCATTTCCAGGTGATTAGGAAGTTTACTGCTACTGTCACTGGTGGTCCTTCGGGATGTAAGGAACAAGCACTGGTTCGTCGTTTTTTTAAGATTAATAGTCAGATTGTTTACAACCATCAAGATGCTGGAAAGTTCGAAAATCATACTGAGAATGCTATCTTGTTGTACATGGCATGTACTCATGCCTCTAATCCTGTGTACGCTACTCTTAAGATACGGATATATTTCTACGATTCTGTATCGAATTAA |
|
Protein Sequence
|
MSKRPADIIISTPASKVRRRLNFDSPVQSSARAPTVLVTNKRRAWTNRPNYRKPRMYRMYRSPDVPKGCEGPCKVQSYDQRDDVKHTGIVRCVSDVTKGPGLTHRIGKRFTIKSIYILGKIWMDENIKKQNHTNTVMFFLVRDRRPYGNSPLDFGQVFNMFDNEPSTATVKNDLRDHFQVIRKFTATVTGGPSGCKEQALVRRFFKINSQIVYNHQDAGKFENHTENAILLYMACTHASNPVYATLKIRIYFYDSVSN |
|
NCBI Accession
|
YP_009508187.1
|
|
Location
|
1074-1478 |
|
Gene Name
|
c3 |
|
Protein Name
|
C3 protein |
|
Coding Region
|
ATGGATTTACGCACCGGGGAACTCATCACTGCAGCTCAAGCACAGAGTGGCGTGTTTATCTGGGAGATACAAAATCCCCTGTATTTCAAGATTATCGACCACGAGAACAGGCCGTTCAACATGCCCCACGACATCATATCAGTCCAGATACGGTTCAACCACAACTTGAGGAAAGAACTGGGGATTCACAAATGTTTTCTCAACTTCAGGGTCTGGACGACCTCACGGCCTCAGACTGGTCTTTTCTTAAGGGTATTTAGGACCCAAGTTTTAAAATATTTAGATAGATTAGGGGTTATTTCAATTAATAATGTAATCAAAGCAATTGATCATGTATTATACGATGTACTTATCAATACACTCCAAGTTAAGGAGAATCATGAAATAAAATTCAATATTTATTAA |
|
Protein Sequence
|
MDLRTGELITAAQAQSGVFIWEIQNPLYFKIIDHENRPFNMPHDIISVQIRFNHNLRKELGIHKCFLNFRVWTTSRPQTGLFLRVFRTQVLKYLDRLGVISINNVIKAIDHVLYDVLINTLQVKENHEIKFNIY |
|
NCBI Accession
|
YP_009508188.1
|
|
Location
|
1219-1626 |
|
Gene Name
|
c2 |
|
Protein Name
|
C2 protein |
|
Coding Region
|
ATGCGGTCTTTGTCACCCTCTCCGAGCCACTGTTCTCAGGTTCCAATCAAGGTTCAACATCGGGAGGCGAAGAAGAGAGCAATCAGGCGTAGAAGGATAGATCTCGACTGCGGCTGCTCATACTATATACACATCAACTGCATAAACCATGGATTTACGCACCGGGGAACTCATCACTGCAGCTCAAGCACAGAGTGGCGTGTTTATCTGGGAGATACAAAATCCCCTGTATTTCAAGATTATCGACCACGAGAACAGGCCGTTCAACATGCCCCACGACATCATATCAGTCCAGATACGGTTCAACCACAACTTGAGGAAAGAACTGGGGATTCACAAATGTTTTCTCAACTTCAGGGTCTGGACGACCTCACGGCCTCAGACTGGTCTTTTCTTAAGGGTATTTAG |
|
Protein Sequence
|
MRSLSPSPSHCSQVPIKVQHREAKKRAIRRRRIDLDCGCSYYIHINCINHGFTHRGTHHCSSSTEWRVYLGDTKSPVFQDYRPREQAVQHAPRHHISPDTVQPQLEERTGDSQMFSQLQGLDDLTASDWSFLKGI |
|
NCBI Accession
|
YP_009508189.1
|
|
Location
|
1535-2614 |
|
Gene Name
|
rep |
|
Protein Name
|
replication associated protein |
|
Coding Region
|
ATGGCTCCTCCAAAGCGATTCCTGATAAATTGCAAAAATTATTTTCTCACTTATCCACAATGCTCCCTCACCAAAGAGGAAGCACTTTCCCAATTGCAAAACCTAAATACACCCGTCAATAAGAAATACATCAAGATCTGCAGGGAACTACACGAGAATGGGGAACCTCATCTCCATGTGCTTATCCAGTTCGAGGGAAAATACAAGTGCCAGAATCAGCGATTCTTCGACCTGGTTTCCCCAACCAGGTCAGCACATTTCCATCCGAACATTCAGGGAGCTAAATCCAGCTCCGATGTCAAGTCCTACATCGACAAGGACGGAGACACACTGGAATGGGGAGAATTCCAGGTCGACGGCAGAAGTGCTCGAGGAGGCTGCCAGAATGCTAACGACGCATGTGCAGACGCATTAAACGCAGGTTCCGCTGAAGCCGCTCTGGCTATTATAAGGGAGAAGCTCCCTAAAGATTTTATTTTTCAATATCATAATTTAAAATCAAATTTAGATATGATTTTTCAGGCTCCCATAGAGCCTTATTCATGTCCCTTTTTGTCTTCTTCTTTCGATCAAGTTCCAGAAGAACTTGAACAATGGGCGGCGGAGAACGTCATGGATGCCGCTGCGCGGCCAAGTAGGCCGATTAGTATAGTAGTAGAAGGGGAGAGCAGGACGGGGAAGACTGTATGGGCCAGAAGCCTTGGGCCTCACAATTATCTGTGCGGCCATTTAGACCTAAGCCCAAAGGTGTTCAGTAATGACGCATGGTATAACGTCATCGATGACGTCGACCCGCATTATCTGAAACACTTTAAAGAGTTCATGGGGGCCCAGAAGGACTGGCAAAGCAACACAAAGTACGGGAAGCCAGTTCAAATTAAAGGGGGCATTCCAACAATCTTCCTATGCAATCCAGGTCCAAATTCCTCGTATAAAGAGTTTTTAGACGAGGACAAGAACACGCATCTCAAATCCTGGGCATTAAAGAATGCGGTCTTTGTCACCCTCTCCGAGCCACTGTTCTCAGGTTCCAATCAAGGTTCAACATCGGGAGGCGAAGAAGAGAGCAATCAGGCGTAG |
|
Protein Sequence
|
MAPPKRFLINCKNYFLTYPQCSLTKEEALSQLQNLNTPVNKKYIKICRELHENGEPHLHVLIQFEGKYKCQNQRFFDLVSPTRSAHFHPNIQGAKSSSDVKSYIDKDGDTLEWGEFQVDGRSARGGCQNANDACADALNAGSAEAALAIIREKLPKDFIFQYHNLKSNLDMIFQAPIEPYSCPFLSSSFDQVPEELEQWAAENVMDAAARPSRPISIVVEGESRTGKTVWARSLGPHNYLCGHLDLSPKVFSNDAWYNVIDDVDPHYLKHFKEFMGAQKDWQSNTKYGKPVQIKGGIPTIFLCNPGPNSSYKEFLDEDKNTHLKSWALKNAVFVTLSEPLFSGSNQGSTSGGEEESNQA |
|
NCBI Accession
|
YP_009508190.1
|
|
Location
|
2200-2457 |
|
Gene Name
|
c4 |
|
Protein Name
|
C4 protein |
|
Coding Region
|
ATGGGGAACCTCATCTCCATGTGCTTATCCAGTTCGAGGGAAAATACAAGTGCCAGAATCAGCGATTCTTCGACCTGGTTTCCCCAACCAGGTCAGCACATTTCCATCCGAACATTCAGGGAGCTAAATCCAGCTCCGATGTCAAGTCCTACATCGACAAGGACGGAGACACACTGGAATGGGGAGAATTCCAGGTCGACGGCAGAAGTGCTCGAGGAGGCTGCCAGAATGCTAACGACGCATGTGCAGACGCATTAA |
|
Protein Sequence
|
MGNLISMCLSSSRENTSARISDSSTWFPQPGQHISIRTFRELNPAPMSSPTSTRTETHWNGENSRSTAEVLEEAARMLTTHVQTH |