Tomato interveinal chlorosis virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_002823985.1 |
| Isolate |
Brazil: Pernambuco |
| Release date |
2018/8/25 |
| Submitter |
Albuquerque,L.C., Varsani,A., Fernandes,F.R., Pinheiro,B., Martin,D.P., de Tarso Oliveira Ferreira,P., Lemos,T.O., Inoue-Nagata,A.K., Martins,D.P., Ferreira,P.T.O. |
| Host |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
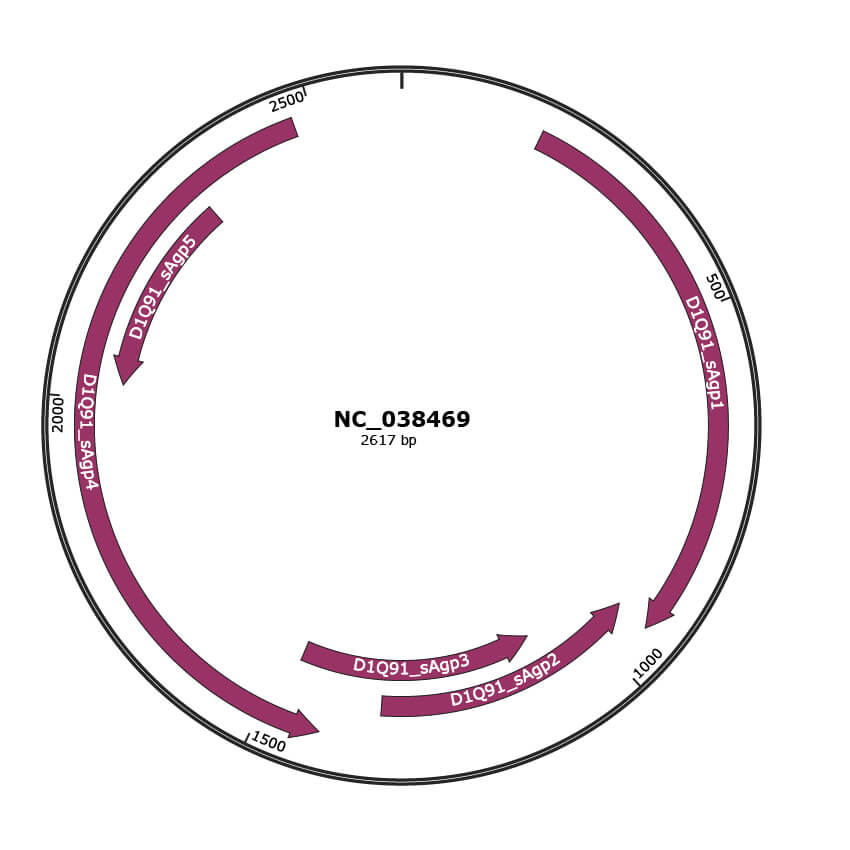
JBrowse
Genome
ACCGGATGGCCGCGAAAAATTTTGGACTTGGGCCGCTTTAGTTGGGCCCGCTCTCTTTATTGAATGAAAGTAATGTGTGGCCCAACCATATTACGTCTGACGAGTTAAGATATTTGTAACGACTTAGCGCCCAAGTTTAGCAACGGCTATATATTGAACGTGCAATTGTCAGTAACTTTAATTCAAAATGCCTAAGCGCGATGCCCCATGGCGCCACATGGCAGGTACGTCTAAGATTAGCCGGGTCGCTAATTATTCTCCTCGTGCAGGAGTTGGGCCACGATCCAACAAGGCCTCTGAATGGGTTAACAGGCCTATGTACAGGAAGCCCAGGATATATCGGATGTACAGGACCCCCGATGTTCCAAGAGGCTGTGAAGGCCCATGTAAAGTCCAGTCGTATGAGCAGCGTCACGATATATCCCATGTTGGTAAGGTGATGTGCGTCTCCGACGTGACAAGAGGTAATGGTATTACCCACCGTGTAGGGAAGCGTTTTTGTGTTAAGTCCGTTTATATTTTAGGTAAGGTATGGATGGACGAGAATATCAAGTTGAAGAACCACACCAACAGTGTTATGTTCTGGCTGGTCAGAGACCGTAGACCCTATGGGACTCCTATGGACTTCGGCCAAGTTTTTAACATGTTTGACAATGAGCCCAGTACTGCCACGGTCAAGAACGATCTTCGTGATCGTTACCAAGTTATGCATAAATTCTATGCTAAGGTGACAGGTGGACAATACGCAAGCAATGAACAAGCGCTGGTCAAGCGTTTCTGGAGGGTCAACAATCACGTGGTGTACAATCATCAAGAAGCCGGGAAATACGAGAATCATACGGAGAACGCACTATTATTGTATATGGCATGTACTCATGCCTCGAACCCTGTGTATGCGACTTTAAAAATTCGGATCTATTTCTATGATTCGATAATAAATTAATAAATGTTGAATTTTATTGAATGATTCTCTAGTACATCATGAACATATGATTTGTCTGTTGCGAAACGAACAGCTCTAATTACATTATTAACTGAAATAACGCCTAATTGATCTAGATACAACTGAACAAGAAATTTAAATCTACTTAAATATCTCATCCCAGAAGCTCTCAGGGATGTCGTCCAAACTTGGAAGTTGAGATAAGCCTTGTGGAGACCCAACACTCTCCGCAGGTTGTGGTTGAACCGTATCTGGACGTGGTAGACTCTCGTCCTCGTGTAGAGTAGGTCCTCCACATTGTACATCTTGAAATATAGGGGATTTGATATCTCCCAGGTATACACGCCATTCTCTGCCTGATGTGCAGTGATGAGTTCCCCTGTGCGTGAATCCATGCCCTGCGCAGTGGATGTGAACGTATATGGAGCACCCGCACTGTAGATCAATTCGTCTTCGTCGTGTTGCCCTCTTTCTTTTAGCTGCCCGATGTTGAACTTTGATAGAGGGGGGAGTTGAGAAAGACGAATTGCGCATTGTGCTTTGTCCAATTATTTAATGCTGAGTTTTCCTCTTTGTCGAGGAAAGATTTATAACTGGCCCCCTCGCCAGGATTGCAAAGCACGATGCATGGGATACCTCCTTTAATTTGAACTGGCTTTCCGTATTTGCAGTTTGATTGCCAGTCCCTTTGGGCCCCGATAAGTTCTTTCCAGTGCTTTAACTTTAGATAGTGCGGTGCGACATCATCAATGACGTTATACTGCACATCGTTTGAATACACCTTTGAATTGAAATCGAGGTGACCGCTCAAGTAATTGTGGGACCCTAATGCACGTGCCCACATGGTCTTCCCTGTCCTTGAATCACCCTCGATTATTATACTGATAGGCCTCTCCGGCCGCGCAGCGGCATCCCTTCCGAAATAGTCATGTGCCCAAGATTGCATCTCGACAGGCACGTTAGTGAACGACGAGAGGGGAAACGGAGGAACCCACGGTTCTGGAGCCTTTGCAAATATACGCTCTAAATTCGAACGAATATTATGATGCTGAAGAACATAATCTTTTGGCTGTTCCTCCTTTAATATATTGAGGGCCTCCATGACTGATCCTGCGTTAAGAACCTTGGCATACGTGTCGTTGGCAGATTGCTGACCTCCTCTAGCTGATCTTCCATCGATCTGGAAAACTCCATGATCAACGAAGTCTCCGTCTTTCTCCACGTATGCCTTGACATCTGACGAGCTCTTAGCTGCCTGAATGTTCGGATGGAAATGTGCTGACCTTGTTGGGGATACAAGGTCGAACAATCGTTCGTTCGTGCACTGGTATTTTCCTTCGAACTGTATGAGGACGTGCAGATGAGGTTGCCCATCTTCGTGTAATTCTCTCGCAACACGAACGAATAGTTTATTGACTGGTATTGTTAAGGCTAAGAGTTGGGAAAGTGCTTCTTCTTTCGAAAGAGAACACTTAGGATAAGTGAGGAAATAGTTTTTGGCATTTAAACGAAATCGTTTCGGGAGTGGCATATTTGTAAATAAGAGCTTGTACACCGATTGGGAGCTCTCACAAAGTCCGAATGAATCGGTGTATTGGTGTACAATATATACTAGAACCCTCAATAGAACTTTCAATCTCGATCGAACACGTGGCGGCCATCCGTTATAATATT
Gene Information
|
NCBI Accession
|
YP_009506521.1
|
|
Location
|
188-943 |
|
Protein Name
|
V1 |
|
Coding Region
|
ATGCCTAAGCGCGATGCCCCATGGCGCCACATGGCAGGTACGTCTAAGATTAGCCGGGTCGCTAATTATTCTCCTCGTGCAGGAGTTGGGCCACGATCCAACAAGGCCTCTGAATGGGTTAACAGGCCTATGTACAGGAAGCCCAGGATATATCGGATGTACAGGACCCCCGATGTTCCAAGAGGCTGTGAAGGCCCATGTAAAGTCCAGTCGTATGAGCAGCGTCACGATATATCCCATGTTGGTAAGGTGATGTGCGTCTCCGACGTGACAAGAGGTAATGGTATTACCCACCGTGTAGGGAAGCGTTTTTGTGTTAAGTCCGTTTATATTTTAGGTAAGGTATGGATGGACGAGAATATCAAGTTGAAGAACCACACCAACAGTGTTATGTTCTGGCTGGTCAGAGACCGTAGACCCTATGGGACTCCTATGGACTTCGGCCAAGTTTTTAACATGTTTGACAATGAGCCCAGTACTGCCACGGTCAAGAACGATCTTCGTGATCGTTACCAAGTTATGCATAAATTCTATGCTAAGGTGACAGGTGGACAATACGCAAGCAATGAACAAGCGCTGGTCAAGCGTTTCTGGAGGGTCAACAATCACGTGGTGTACAATCATCAAGAAGCCGGGAAATACGAGAATCATACGGAGAACGCACTATTATTGTATATGGCATGTACTCATGCCTCGAACCCTGTGTATGCGACTTTAAAAATTCGGATCTATTTCTATGATTCGATAATAAATTAA |
|
Protein Sequence
|
MPKRDAPWRHMAGTSKISRVANYSPRAGVGPRSNKASEWVNRPMYRKPRIYRMYRTPDVPRGCEGPCKVQSYEQRHDISHVGKVMCVSDVTRGNGITHRVGKRFCVKSVYILGKVWMDENIKLKNHTNSVMFWLVRDRRPYGTPMDFGQVFNMFDNEPSTATVKNDLRDRYQVMHKFYAKVTGGQYASNEQALVKRFWRVNNHVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSIIN |
|
NCBI Accession
|
YP_009506522.1
|
|
Location
|
940-1338 |
|
Protein Name
|
C3 |
|
Coding Region
|
ATGGATTCACGCACAGGGGAACTCATCACTGCACATCAGGCAGAGAATGGCGTGTATACCTGGGAGATATCAAATCCCCTATATTTCAAGATGTACAATGTGGAGGACCTACTCTACACGAGGACGAGAGTCTACCACGTCCAGATACGGTTCAACCACAACCTGCGGAGAGTGTTGGGTCTCCACAAGGCTTATCTCAACTTCCAAGTTTGGACGACATCCCTGAGAGCTTCTGGGATGAGATATTTAAGTAGATTTAAATTTCTTGTTCAGTTGTATCTAGATCAATTAGGCGTTATTTCAGTTAATAATGTAATTAGAGCTGTTCGTTTCGCAACAGACAAATCATATGTTCATGATGTACTAGAGAATCATTCAATAAAATTCAACATTTATTAA |
|
Protein Sequence
|
MDSRTGELITAHQAENGVYTWEISNPLYFKMYNVEDLLYTRTRVYHVQIRFNHNLRRVLGLHKAYLNFQVWTTSLRASGMRYLSRFKFLVQLYLDQLGVISVNNVIRAVRFATDKSYVHDVLENHSIKFNIY |
|
NCBI Accession
|
YP_009506523.1
|
|
Location
|
1085-1477 |
|
Protein Name
|
C2 |
|
Coding Region
|
ATGCGCAATTCGTCTTTCTCAACTCCCCCCTCTATCAAAGTTCAACATCGGGCAGCTAAAAGAAAGAGGGCAACACGACGAAGACGAATTGATCTACAGTGCGGGTGCTCCATATACGTTCACATCCACTGCGCAGGGCATGGATTCACGCACAGGGGAACTCATCACTGCACATCAGGCAGAGAATGGCGTGTATACCTGGGAGATATCAAATCCCCTATATTTCAAGATGTACAATGTGGAGGACCTACTCTACACGAGGACGAGAGTCTACCACGTCCAGATACGGTTCAACCACAACCTGCGGAGAGTGTTGGGTCTCCACAAGGCTTATCTCAACTTCCAAGTTTGGACGACATCCCTGAGAGCTTCTGGGATGAGATATTTAAGTAG |
|
Protein Sequence
|
MRNSSFSTPPSIKVQHRAAKRKRATRRRRIDLQCGCSIYVHIHCAGHGFTHRGTHHCTSGREWRVYLGDIKSPIFQDVQCGGPTLHEDESLPRPDTVQPQPAESVGSPQGLSQLPSLDDIPESFWDEIFK |
|
NCBI Accession
|
YP_009506524.1
|
|
Location
|
1419-2474 |
|
Protein Name
|
C1 |
|
Coding Region
|
ATGCCACTCCCGAAACGATTTCGTTTAAATGCCAAAAACTATTTCCTCACTTATCCTAAGTGTTCTCTTTCGAAAGAAGAAGCACTTTCCCAACTCTTAGCCTTAACAATACCAGTCAATAAACTATTCGTTCGTGTTGCGAGAGAATTACACGAAGATGGGCAACCTCATCTGCACGTCCTCATACAGTTCGAAGGAAAATACCAGTGCACGAACGAACGATTGTTCGACCTTGTATCCCCAACAAGGTCAGCACATTTCCATCCGAACATTCAGGCAGCTAAGAGCTCGTCAGATGTCAAGGCATACGTGGAGAAAGACGGAGACTTCGTTGATCATGGAGTTTTCCAGATCGATGGAAGATCAGCTAGAGGAGGTCAGCAATCTGCCAACGACACGTATGCCAAGGTTCTTAACGCAGGATCAGTCATGGAGGCCCTCAATATATTAAAGGAGGAACAGCCAAAAGATTATGTTCTTCAGCATCATAATATTCGTTCGAATTTAGAGCGTATATTTGCAAAGGCTCCAGAACCGTGGGTTCCTCCGTTTCCCCTCTCGTCGTTCACTAACGTGCCTGTCGAGATGCAATCTTGGGCACATGACTATTTCGGAAGGGATGCCGCTGCGCGGCCGGAGAGGCCTATCAGTATAATAATCGAGGGTGATTCAAGGACAGGGAAGACCATGTGGGCACGTGCATTAGGGTCCCACAATTACTTGAGCGGTCACCTCGATTTCAATTCAAAGGTGTATTCAAACGATGTGCAGTATAACGTCATTGATGATGTCGCACCGCACTATCTAAAGTTAAAGCACTGGAAAGAACTTATCGGGGCCCAAAGGGACTGGCAATCAAACTGCAAATACGGAAAGCCAGTTCAAATTAAAGGAGGTATCCCATGCATCGTGCTTTGCAATCCTGGCGAGGGGGCCAGTTATAAATCTTTCCTCGACAAAGAGGAAAACTCAGCATTAAATAATTGGACAAAGCACAATGCGCAATTCGTCTTTCTCAACTCCCCCCTCTATCAAAGTTCAACATCGGGCAGCTAA |
|
Protein Sequence
|
MPLPKRFRLNAKNYFLTYPKCSLSKEEALSQLLALTIPVNKLFVRVARELHEDGQPHLHVLIQFEGKYQCTNERLFDLVSPTRSAHFHPNIQAAKSSSDVKAYVEKDGDFVDHGVFQIDGRSARGGQQSANDTYAKVLNAGSVMEALNILKEEQPKDYVLQHHNIRSNLERIFAKAPEPWVPPFPLSSFTNVPVEMQSWAHDYFGRDAAARPERPISIIIEGDSRTGKTMWARALGSHNYLSGHLDFNSKVYSNDVQYNVIDDVAPHYLKLKHWKELIGAQRDWQSNCKYGKPVQIKGGIPCIVLCNPGEGASYKSFLDKEENSALNNWTKHNAQFVFLNSPLYQSSTSGS |
|
NCBI Accession
|
YP_009506525.1
|
|
Location
|
2024-2317 |
|
Protein Name
|
C4 |
|
Coding Region
|
ATGGGCAACCTCATCTGCACGTCCTCATACAGTTCGAAGGAAAATACCAGTGCACGAACGAACGATTGTTCGACCTTGTATCCCCAACAAGGTCAGCACATTTCCATCCGAACATTCAGGCAGCTAAGAGCTCGTCAGATGTCAAGGCATACGTGGAGAAAGACGGAGACTTCGTTGATCATGGAGTTTTCCAGATCGATGGAAGATCAGCTAGAGGAGGTCAGCAATCTGCCAACGACACGTATGCCAAGGTTCTTAACGCAGGATCAGTCATGGAGGCCCTCAATATATTAA |
|
Protein Sequence
|
MGNLICTSSYSSKENTSARTNDCSTLYPQQGQHISIRTFRQLRARQMSRHTWRKTETSLIMEFSRSMEDQLEEVSNLPTTRMPRFLTQDQSWRPSIY |