Tomato common mosaic virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_000879555.1 |
| Isolate |
Brazil |
| Release date |
2015/2/22 |
| Submitter |
Castillo-Urquiza,G.P., Beserra,J.E. Jr., Bruckner,F.P., Lima,A.T., Varsani,A., Alfenas-Zerbini,P., Murilo Zerbini,F., Beserra,J.E.A. Jr., Lima,A.T.M., Zerbini,P.A., Zerbini,F.M. |
| Host |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
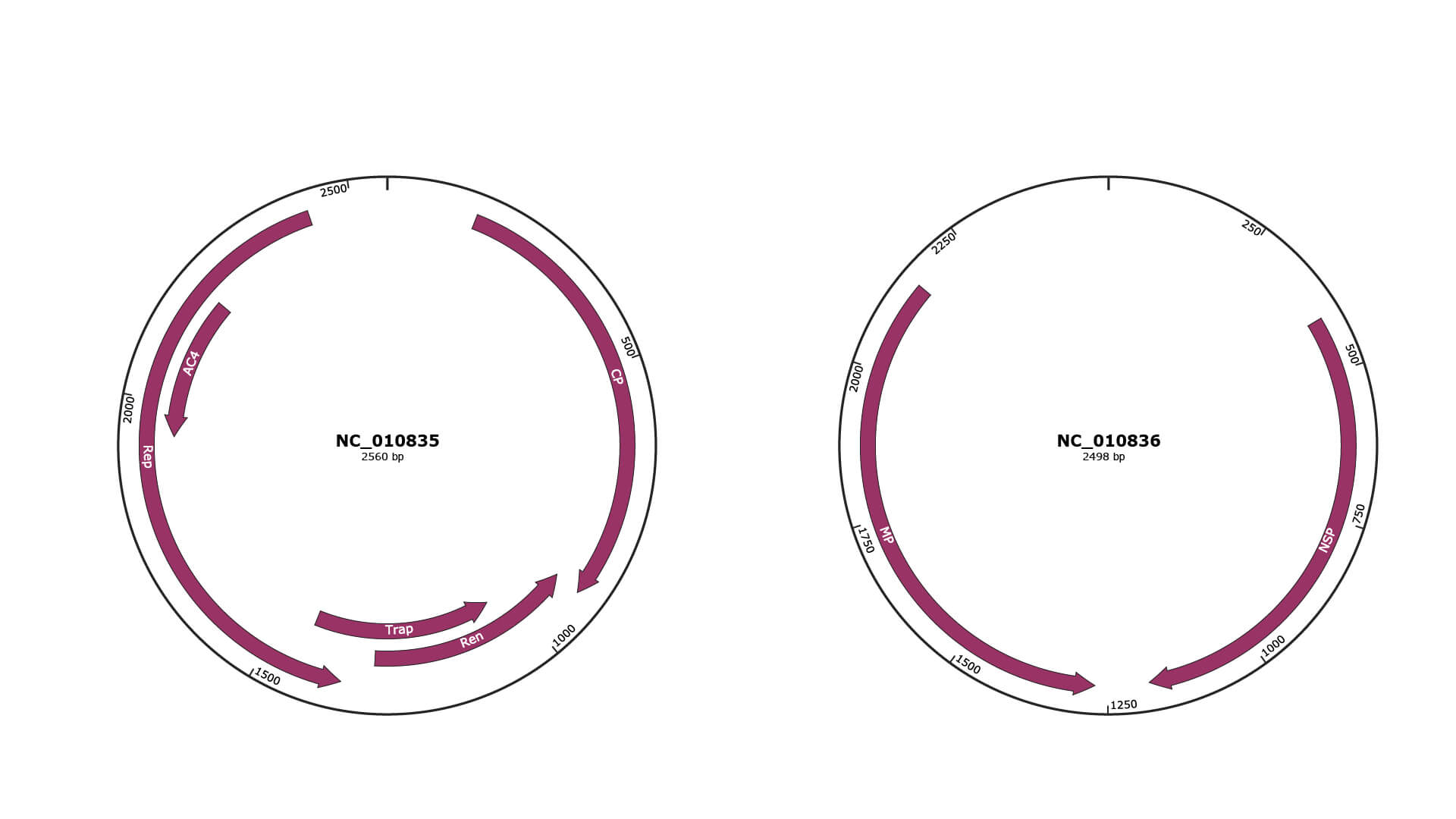
JBrowse
Genome
ACTGGATGGCCGCGCAAAAATTTGGACTTGGGCCGCTTTTTCTGGCCCAATTAGAACAGGCCTGACGAGCTTAGATATTTGTAACAACTTAGAGCCCAAGTTGTATAACGGCTATAAATTGAATCTCTATGTTATTTGAACTTTAATTTGAAATGCCTAAGCGCGATGCCCCATGGCCCCACAGGGCACCTTCGACGAAGATTAGCCGTTCAGCTAATTTCTCCCCTCGTTCGGGAACTGGGCCTGGGCCTAGCAAAGCCGCTGAATGGGTGAATAGGCCCATGTACAGGAAGCCCAGGATATACAGAACTATGAGAACGCCCGACGTTCCTAGAGGCTGTGAAGGCCCATGTAAGGTCCAGTCCTACGAGCAACGCCACGATATTTCCCATACTGGGAAGGTGATGTGCATATCAGACGTCACACGTGGCAACGGAATTACCCACCGTGTCGGTAAGCGTTTCTGCGTTAAGTCTGTGTATATTCTAGGAAAGATTTGGATGGACGAGAACATCAAGTTGAAAAACCATACGAACAGTGCTATGTTCTGGTTGGTCAGAGACCGAAGACCATATGGCACCCCTATGGATTTTGGCCAAGTGTTCAACATGTTTGACAACGAGCCCAGCACTGCAACCGTGAAGAACGATCTACGTGATCGTTTCCAGGTTATGCATAAGTTCTATGCCAAGGTCACGGGTGGACAATATGCTAGCAATGAGCAGGCGCTGGTCAAGCGGTTCTGGAGGGTCAACAATCATGTGGTCTACAATCATCAAGAAGCCGGGAAGTATGAGAATCACACGGAGAACGCGCTGTTATTGTATATGGCATGTACTCATGCCTCTAACCCTGTATATGCAACTTTAAAAATTCGGATCTATTTTTATGATTCGATAACAAATTAATATAATTTAAATTTTATTGAATGATTTTCAAGTACAGCATTTACATATGATCTGTCTGTTGCAAAGCGAACAGCTCTAATTACATTATTAACTGAAATGACTCCTAACTGATCAATATACAACATTACTAAATATTTAAATCTATTTAAGTAAGTCGTCCCAGAAGCTGTCAGGGATGTCGTCCAGACTTGGAAGTTGAGAAATGCCTTGTGGAGACCCAGTGCTCTCCTCAGGTTGTGGTTGAACCTTATTTGGACATGGTACACTCTGGTCCTGGTGTACCGGATGTCCTCTACTTGGTACATCTTGAAATAAAGGGGATTTGTTAGCTCCCATATATAGACGCCATTCTCTGCCTGACGCACAGTGATGCGTTCCCCTGTGCGTGAATCCATAGTTACTGCAGTTGAGGTTGACGTACAAAGAGCAGCCACAGTTTAGGTCTATCCTTCTACGTCGAGGTGCTCTCTTCGCAATCCTGTGCCGTAGTTTGATAGAGGGGGGAGTTGAGGATGATGAATTTAGCATTATGGAGTGTCCACGACTTGAGAGATGCGTTTTCCTCTTTGGCTAGGAAATCTTTATAGCTGGCCCCCTCTCCAGGATTGCAGAGCACGATTGATGGGATACCCCCTTTAATTTGAACTGGCTTTCCGTACTTACAATTTGATTGCCAATCTATTTGGGCCCCAATCAATTCTTTCCAGTGCTTTAACTTTAAGTAATGCGGAGAGACGTCATCAATGACGTTATACAGTACATCGTTTGAGTAAACCCTAGAATTGAAATCCAGGTGTCCACTTAGATAGTTATGTGGGCCAAGTGCACGCGCCCACATCGTCTTCCCCGTCCGACTATTACCCTCGATGACAATACTTATAGGTCTGATAGGCCGCGCAGCTGCATCCCTTCCAAAATAATCATCAGCCCATTCTTGCATCTCGTCGGGCACGTTAGTGAATGAGGAGAGGGGAAACGGAGGAACCCACGGTGCCGGAGCTTTTTGGAAGATCCTCTCTAGATTAGCCTTCACATTGTGATAGTTGACGAGGAAAGTCTTGGGGTCTCCGGCCCTGATAATGTCGAGAGCCTCTCCCGGAGAAGATGCATTGACGGCGTTGTGGTACACGTCGTCTTTATTTGCCTTTGTTCCCCCAGACACCTTGTACTGTCCGGATTCACAATAATCACCTTCTTTGGTGATGTAATTCTTGACTGCATTGGTGTCTTTGGCTGCCTGAACATTTGGGTGAAATCCGGTAGACCGTCTGGGGTGAGTGAGGTCGAAAAACCTAACATCCTTGATATTCGATTTTCCGGAGAGTTGGACAAGACAGTGAAGATGGGGGAATCCGTCGGAGTGTTCCTCTCTGGCGACTCGTATATATGTGGGTTTGACGACTGACCATGGAAGAGATTGAAGCATTTGAAGAGCTTCATCTTTTGGTATATCGCACTGTGGATATGTGAGAAATATGTTTCTCGCCGTTAATCTGAATATATTAGGGTTCCGTGGCATTTTTGTAAATATAGGTGAGGACACCAGGGATTGCTCTCAACTTCTGTGCTATTTGCTGGTGTCCTGGTGTCCCATTTATACTAGAACTCTCTAGGGTAATCTCAGGGGCAAAAGCGGCCATCCATATAATATT
ACTGGATGGCCGCGCGATGTCCGTCCTCTCGCTAAATCCTGACCCTCCACGTGGCTATTCTATTTAATTTAGCGAGAATTTGAGGTCCGCAAATGAGTTGAGCGCTTATTTTGAGTTCCGCTAACGGAAGGCTGCCACGTGCACATATCTATTACCGTTAAATATAATATGATAAGCGGAACTTTATTCGTACGATGACAACTGTATTGCACTGACATTGTATTATTCATATTTCTGCCGAAATATTAATCTACATGGTCAATATATTATTTTTGACTATCGTACAGGATATGCTAGGTGTACCAATTAAATGTGGACTTCATTAACAAATTAACGTTAACTACAATAAGTTGGTCTATATAAGTCGGCTGTTATTAATTTCGACTTTTGTCCACAGTTAATTTATTAATATGTATTTCTCTAAAAATAAGCGTAGTTGGGCGTCTACTAATCGACGTCTATCCTCACGATATTTTACCTCTAAAAGGTCAATTAGCTTGTTACGTAATGATGGTAAACGTCGAGTGGATATTTCTAGCAAATTCCAGGAAGAAATTAAGATGTCGTCGCATCGAATACATGAAACACAATATGGGCCTGAATTTGTATTAGGTAATAATTCGGCGATATCCACATTTATTACGTATCCTTGTCTTGGCAAGACAGAGCCCAGTCGTACGAGGTCATATATCAAATTAAAACGCCTGCGTTTTAACGGCACTGTTAAAATTGAACGTGCACATACAGATGTGAATATGAATGGGATACCTCCCAAGATTGATGGAGTATTTACTATTGTCGTTGTTATCGATCGAAAACCGCACTTGACCTCTGCTGGTGGTCTCTATACATTCGACGAGCTGTTTGGTGCTAGGATTCACAGTCATGGAAATTTGGCAATAACTCCATTGTTAAAGGATCGTTTTTACATCCGTCATGTCGTCAAACGTGTGTTGTCCGTGGAGAAGGATACGACTATGATTGATCTTGATGGGACGACAACATTGTCTAATAGGCGCTATAACTGTTGGGCTAATTTTAGGGACCTTGATCATGACTCATGTAATGGTATTTATGCAAATATTTGCAAGAACGCCATATTAGTCTATTATTGTTGGATGTCTGATACAGTGTCCAAGGCATCTACATTTGTGTCATTTGACCTAGATTATGTTGGATAAATTTATATATAAATTTGCATTTTAATTTGTCATTAAGCAACATATAATAAGACATTGTTGAACAATTTGCTATTAACTATAAATTATAATTTATTTCAAAGACTTTGGTTCCGAAGGTGTACAATTGGTGTTAATACATTCTTGGACAGTTGTCCTAACAATATCATTTAACTGGGCTAACGACAATGTAATGTTAGACTGCGTCCTTTGTGCCGCAACGATTGAAGCTGATTCACCTGGGTCGAGAAATGTTGTGCCCAATCTGTTTAGGTCCCTATATGGATTGAGATCGTTGCTCTTTTCGGAGTCCATACAAGAGTTGCTAATACCAACTGTACTTCTGGAGGCCCATGATTCTCCAGCCTTAATTTCTATTGGGCCCGAAGGCCCAAAATTGTTAGTCGAAGCACATCTGACTAATTTTCTCTCCCATTTTCCGAACCCAACATGAGCAAAGTCGATATCCTTGTCTGAAAACTGCTTCGACAATATCTTCACTGTGGGTGCCCGGAAAGGGATATCTACAGAGTGTTTAGCTGTGGATAGTTTTAACTTGCCCTTGAATTTTGCGAAATGTGTTCTTTGATGTACGTTTGTATCGCTAACCCTGTAGTATAGTTTCCATGGAATGGGGTCTTTAAGCGAGAAGAAAGACGCTGAGAAATAATGTAAGTCTATGTTACATCTAAGAGGGAAAGTCCATGACGCCTGCAATGACTCGTTGTCTGTCATTCGTTTGTCATGAATTTCAACTATGACAGACCCAGTTGCATTTATAGGCACTTGCTGTCTGTATTCAATGACACAATGGTCGATTTTCATACAGCTGCGACTAAGTTTAGCACTTATTTGAGATGCCGTAGAAGGAAATTGTAGAACAATTTCAGTCAAGTCATGAGACAGCTGATATTCATCCCGGTGTGATTCAACATAATTAAAAGCATTTGGAGGAACAACTAACTGAGAATTCATTATAAAGAAAAATGGCTGCGCAGCTGAAAGCAAATGAAATCGATAAGCAAAAAATGAATAAACAACAGGATAGTTAAAGATGAAGATAGATAGTCTGCGCTGTATGTGTCTATGTTGTAAGGAAGATTAACAAGTAATTTATTATAAGATGTTATACACGCTTCTATTTATAAGCAACAACATGTAATAAGTATTTAATATGAAAATGGCATTTTGGTAAATAAGGTAGAGGACACCAGGGATTGCTCTCAACTTCTGTGCTATTTGCTGGTGTCCTGGTGTCCCATTTATACTAGAACCCTCTAGGTTAATCTCAGGGGCAAAAGCGGACATCCATATAATATT
Gene Information
|
NCBI Accession
|
YP_001960952.1
|
|
Location
|
153-908 |
|
Gene Name
|
CP |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGCCTAAGCGCGATGCCCCATGGCCCCACAGGGCACCTTCGACGAAGATTAGCCGTTCAGCTAATTTCTCCCCTCGTTCGGGAACTGGGCCTGGGCCTAGCAAAGCCGCTGAATGGGTGAATAGGCCCATGTACAGGAAGCCCAGGATATACAGAACTATGAGAACGCCCGACGTTCCTAGAGGCTGTGAAGGCCCATGTAAGGTCCAGTCCTACGAGCAACGCCACGATATTTCCCATACTGGGAAGGTGATGTGCATATCAGACGTCACACGTGGCAACGGAATTACCCACCGTGTCGGTAAGCGTTTCTGCGTTAAGTCTGTGTATATTCTAGGAAAGATTTGGATGGACGAGAACATCAAGTTGAAAAACCATACGAACAGTGCTATGTTCTGGTTGGTCAGAGACCGAAGACCATATGGCACCCCTATGGATTTTGGCCAAGTGTTCAACATGTTTGACAACGAGCCCAGCACTGCAACCGTGAAGAACGATCTACGTGATCGTTTCCAGGTTATGCATAAGTTCTATGCCAAGGTCACGGGTGGACAATATGCTAGCAATGAGCAGGCGCTGGTCAAGCGGTTCTGGAGGGTCAACAATCATGTGGTCTACAATCATCAAGAAGCCGGGAAGTATGAGAATCACACGGAGAACGCGCTGTTATTGTATATGGCATGTACTCATGCCTCTAACCCTGTATATGCAACTTTAAAAATTCGGATCTATTTTTATGATTCGATAACAAATTAA |
|
Protein Sequence
|
MPKRDAPWPHRAPSTKISRSANFSPRSGTGPGPSKAAEWVNRPMYRKPRIYRTMRTPDVPRGCEGPCKVQSYEQRHDISHTGKVMCISDVTRGNGITHRVGKRFCVKSVYILGKIWMDENIKLKNHTNSAMFWLVRDRRPYGTPMDFGQVFNMFDNEPSTATVKNDLRDRFQVMHKFYAKVTGGQYASNEQALVKRFWRVNNHVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSITN |
|
NCBI Accession
|
YP_001960953.1
|
|
Location
|
905-1303 |
|
Gene Name
|
Ren |
|
Protein Name
|
replication enhancer protein |
|
Coding Region
|
ATGGATTCACGCACAGGGGAACGCATCACTGTGCGTCAGGCAGAGAATGGCGTCTATATATGGGAGCTAACAAATCCCCTTTATTTCAAGATGTACCAAGTAGAGGACATCCGGTACACCAGGACCAGAGTGTACCATGTCCAAATAAGGTTCAACCACAACCTGAGGAGAGCACTGGGTCTCCACAAGGCATTTCTCAACTTCCAAGTCTGGACGACATCCCTGACAGCTTCTGGGACGACTTACTTAAATAGATTTAAATATTTAGTAATGTTGTATATTGATCAGTTAGGAGTCATTTCAGTTAATAATGTAATTAGAGCTGTTCGCTTTGCAACAGACAGATCATATGTAAATGCTGTACTTGAAAATCATTCAATAAAATTTAAATTATATTAA |
|
Protein Sequence
|
MDSRTGERITVRQAENGVYIWELTNPLYFKMYQVEDIRYTRTRVYHVQIRFNHNLRRALGLHKAFLNFQVWTTSLTASGTTYLNRFKYLVMLYIDQLGVISVNNVIRAVRFATDRSYVNAVLENHSIKFKLY |
|
NCBI Accession
|
YP_001960954.1
|
|
Location
|
1050-1436 |
|
Gene Name
|
Trap |
|
Protein Name
|
trans-activating protein |
|
Coding Region
|
ATGCTAAATTCATCATCCTCAACTCCCCCCTCTATCAAACTACGGCACAGGATTGCGAAGAGAGCACCTCGACGTAGAAGGATAGACCTAAACTGTGGCTGCTCTTTGTACGTCAACCTCAACTGCAGTAACTATGGATTCACGCACAGGGGAACGCATCACTGTGCGTCAGGCAGAGAATGGCGTCTATATATGGGAGCTAACAAATCCCCTTTATTTCAAGATGTACCAAGTAGAGGACATCCGGTACACCAGGACCAGAGTGTACCATGTCCAAATAAGGTTCAACCACAACCTGAGGAGAGCACTGGGTCTCCACAAGGCATTTCTCAACTTCCAAGTCTGGACGACATCCCTGACAGCTTCTGGGACGACTTACTTAAATAG |
|
Protein Sequence
|
MLNSSSSTPPSIKLRHRIAKRAPRRRRIDLNCGCSLYVNLNCSNYGFTHRGTHHCASGREWRLYMGANKSPLFQDVPSRGHPVHQDQSVPCPNKVQPQPEESTGSPQGISQLPSLDDIPDSFWDDLLK |
|
NCBI Accession
|
YP_001960955.1
|
|
Location
|
1360-2427 |
|
Gene Name
|
Rep |
|
Protein Name
|
replication-associated protein |
|
Coding Region
|
ATGCCACGGAACCCTAATATATTCAGATTAACGGCGAGAAACATATTTCTCACATATCCACAGTGCGATATACCAAAAGATGAAGCTCTTCAAATGCTTCAATCTCTTCCATGGTCAGTCGTCAAACCCACATATATACGAGTCGCCAGAGAGGAACACTCCGACGGATTCCCCCATCTTCACTGTCTTGTCCAACTCTCCGGAAAATCGAATATCAAGGATGTTAGGTTTTTCGACCTCACTCACCCCAGACGGTCTACCGGATTTCACCCAAATGTTCAGGCAGCCAAAGACACCAATGCAGTCAAGAATTACATCACCAAAGAAGGTGATTATTGTGAATCCGGACAGTACAAGGTGTCTGGGGGAACAAAGGCAAATAAAGACGACGTGTACCACAACGCCGTCAATGCATCTTCTCCGGGAGAGGCTCTCGACATTATCAGGGCCGGAGACCCCAAGACTTTCCTCGTCAACTATCACAATGTGAAGGCTAATCTAGAGAGGATCTTCCAAAAAGCTCCGGCACCGTGGGTTCCTCCGTTTCCCCTCTCCTCATTCACTAACGTGCCCGACGAGATGCAAGAATGGGCTGATGATTATTTTGGAAGGGATGCAGCTGCGCGGCCTATCAGACCTATAAGTATTGTCATCGAGGGTAATAGTCGGACGGGGAAGACGATGTGGGCGCGTGCACTTGGCCCACATAACTATCTAAGTGGACACCTGGATTTCAATTCTAGGGTTTACTCAAACGATGTACTGTATAACGTCATTGATGACGTCTCTCCGCATTACTTAAAGTTAAAGCACTGGAAAGAATTGATTGGGGCCCAAATAGATTGGCAATCAAATTGTAAGTACGGAAAGCCAGTTCAAATTAAAGGGGGTATCCCATCAATCGTGCTCTGCAATCCTGGAGAGGGGGCCAGCTATAAAGATTTCCTAGCCAAAGAGGAAAACGCATCTCTCAAGTCGTGGACACTCCATAATGCTAAATTCATCATCCTCAACTCCCCCCTCTATCAAACTACGGCACAGGATTGCGAAGAGAGCACCTCGACGTAG |
|
Protein Sequence
|
MPRNPNIFRLTARNIFLTYPQCDIPKDEALQMLQSLPWSVVKPTYIRVAREEHSDGFPHLHCLVQLSGKSNIKDVRFFDLTHPRRSTGFHPNVQAAKDTNAVKNYITKEGDYCESGQYKVSGGTKANKDDVYHNAVNASSPGEALDIIRAGDPKTFLVNYHNVKANLERIFQKAPAPWVPPFPLSSFTNVPDEMQEWADDYFGRDAAARPIRPISIVIEGNSRTGKTMWARALGPHNYLSGHLDFNSRVYSNDVLYNVIDDVSPHYLKLKHWKELIGAQIDWQSNCKYGKPVQIKGGIPSIVLCNPGEGASYKDFLAKEENASLKSWTLHNAKFIILNSPLYQTTAQDCEESTST |
|
NCBI Accession
|
YP_001960956.1
|
|
Location
|
1938-2207 |
|
Gene Name
|
AC4 |
|
Protein Name
|
AC4 |
|
Coding Region
|
ATGTTAGGTTTTTCGACCTCACTCACCCCAGACGGTCTACCGGATTTCACCCAAATGTTCAGGCAGCCAAAGACACCAATGCAGTCAAGAATTACATCACCAAAGAAGGTGATTATTGTGAATCCGGACAGTACAAGGTGTCTGGGGGAACAAAGGCAAATAAAGACGACGTGTACCACAACGCCGTCAATGCATCTTCTCCGGGAGAGGCTCTCGACATTATCAGGGCCGGAGACCCCAAGACTTTCCTCGTCAACTATCACAATGTGA |
|
Protein Sequence
|
MLGFSTSLTPDGLPDFTQMFRQPKTPMQSRITSPKKVIIVNPDSTRCLGEQRQIKTTCTTTPSMHLLRERLSTLSGPETPRLSSSTITM |
|
NCBI Accession
|
YP_001960957.1
|
|
Location
|
411-1181 |
|
Gene Name
|
NSP |
|
Protein Name
|
nuclear shuttle protein |
|
Coding Region
|
ATGTATTTCTCTAAAAATAAGCGTAGTTGGGCGTCTACTAATCGACGTCTATCCTCACGATATTTTACCTCTAAAAGGTCAATTAGCTTGTTACGTAATGATGGTAAACGTCGAGTGGATATTTCTAGCAAATTCCAGGAAGAAATTAAGATGTCGTCGCATCGAATACATGAAACACAATATGGGCCTGAATTTGTATTAGGTAATAATTCGGCGATATCCACATTTATTACGTATCCTTGTCTTGGCAAGACAGAGCCCAGTCGTACGAGGTCATATATCAAATTAAAACGCCTGCGTTTTAACGGCACTGTTAAAATTGAACGTGCACATACAGATGTGAATATGAATGGGATACCTCCCAAGATTGATGGAGTATTTACTATTGTCGTTGTTATCGATCGAAAACCGCACTTGACCTCTGCTGGTGGTCTCTATACATTCGACGAGCTGTTTGGTGCTAGGATTCACAGTCATGGAAATTTGGCAATAACTCCATTGTTAAAGGATCGTTTTTACATCCGTCATGTCGTCAAACGTGTGTTGTCCGTGGAGAAGGATACGACTATGATTGATCTTGATGGGACGACAACATTGTCTAATAGGCGCTATAACTGTTGGGCTAATTTTAGGGACCTTGATCATGACTCATGTAATGGTATTTATGCAAATATTTGCAAGAACGCCATATTAGTCTATTATTGTTGGATGTCTGATACAGTGTCCAAGGCATCTACATTTGTGTCATTTGACCTAGATTATGTTGGATAA |
|
Protein Sequence
|
MYFSKNKRSWASTNRRLSSRYFTSKRSISLLRNDGKRRVDISSKFQEEIKMSSHRIHETQYGPEFVLGNNSAISTFITYPCLGKTEPSRTRSYIKLKRLRFNGTVKIERAHTDVNMNGIPPKIDGVFTIVVVIDRKPHLTSAGGLYTFDELFGARIHSHGNLAITPLLKDRFYIRHVVKRVLSVEKDTTMIDLDGTTTLSNRRYNCWANFRDLDHDSCNGIYANICKNAILVYYCWMSDTVSKASTFVSFDLDYVG |
|
NCBI Accession
|
YP_001960958.1
|
|
Location
|
1272-2153 |
|
Gene Name
|
MP |
|
Protein Name
|
movement protein |
|
Coding Region
|
ATGAATTCTCAGTTAGTTGTTCCTCCAAATGCTTTTAATTATGTTGAATCACACCGGGATGAATATCAGCTGTCTCATGACTTGACTGAAATTGTTCTACAATTTCCTTCTACGGCATCTCAAATAAGTGCTAAACTTAGTCGCAGCTGTATGAAAATCGACCATTGTGTCATTGAATACAGACAGCAAGTGCCTATAAATGCAACTGGGTCTGTCATAGTTGAAATTCATGACAAACGAATGACAGACAACGAGTCATTGCAGGCGTCATGGACTTTCCCTCTTAGATGTAACATAGACTTACATTATTTCTCAGCGTCTTTCTTCTCGCTTAAAGACCCCATTCCATGGAAACTATACTACAGGGTTAGCGATACAAACGTACATCAAAGAACACATTTCGCAAAATTCAAGGGCAAGTTAAAACTATCCACAGCTAAACACTCTGTAGATATCCCTTTCCGGGCACCCACAGTGAAGATATTGTCGAAGCAGTTTTCAGACAAGGATATCGACTTTGCTCATGTTGGGTTCGGAAAATGGGAGAGAAAATTAGTCAGATGTGCTTCGACTAACAATTTTGGGCCTTCGGGCCCAATAGAAATTAAGGCTGGAGAATCATGGGCCTCCAGAAGTACAGTTGGTATTAGCAACTCTTGTATGGACTCCGAAAAGAGCAACGATCTCAATCCATATAGGGACCTAAACAGATTGGGCACAACATTTCTCGACCCAGGTGAATCAGCTTCAATCGTTGCGGCACAAAGGACGCAGTCTAACATTACATTGTCGTTAGCCCAGTTAAATGATATTGTTAGGACAACTGTCCAAGAATGTATTAACACCAATTGTACACCTTCGGAACCAAAGTCTTTGAAATAA |
|
Protein Sequence
|
MNSQLVVPPNAFNYVESHRDEYQLSHDLTEIVLQFPSTASQISAKLSRSCMKIDHCVIEYRQQVPINATGSVIVEIHDKRMTDNESLQASWTFPLRCNIDLHYFSASFFSLKDPIPWKLYYRVSDTNVHQRTHFAKFKGKLKLSTAKHSVDIPFRAPTVKILSKQFSDKDIDFAHVGFGKWERKLVRCASTNNFGPSGPIEIKAGESWASRSTVGISNSCMDSEKSNDLNPYRDLNRLGTTFLDPGESASIVAAQRTQSNITLSLAQLNDIVRTTVQECINTNCTPSEPKSLK |