Tomato chlorotic mottle Guyane virus
Basic Information
Genomic Organization
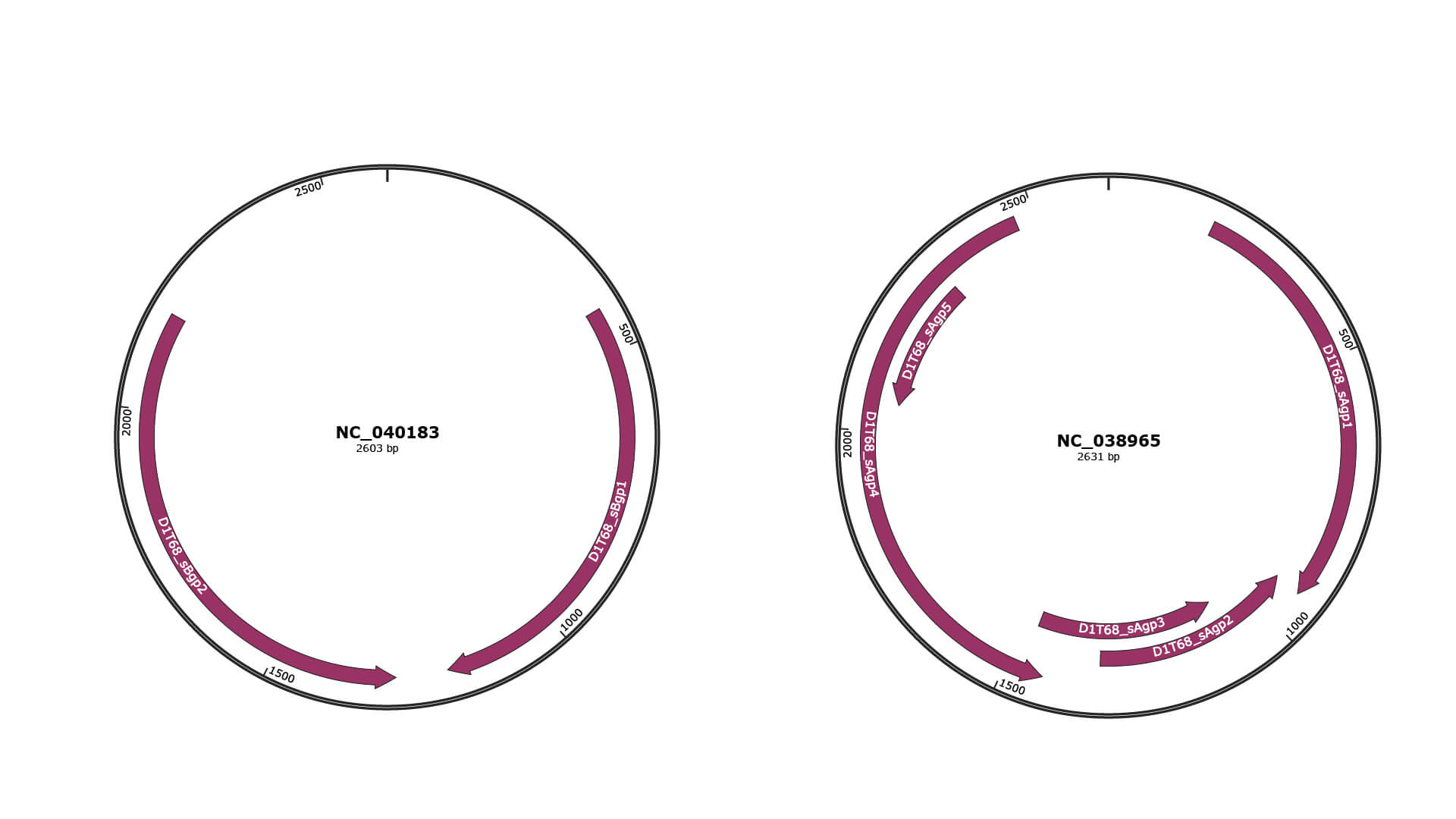
JBrowse
Genome
ACCGGATGGCCGCGCGATTTTTTCCCCCTCTGACGTGGCGCGCATCTGACCGTTCGCTCTTTCGGACAACTCGCTATTAAATCTAGTTGAGCGCATCATTTGGAGTCCGCCAATAAAAGGTTGCCACGTTACTCGGAGGCTGTTTCCCTCTCACTTCGCACCTCGCTTTATCCTTTTGTTTTTTTCGAGGTACTCTCTCATTCGTTCGATCAATTCAATTGGCTCTCCATCAAGCATTTGCATTTTGAATTAAAGTGTTATGTGACTACTTTGGGCATATTTACATTGTTATTCCGCCCTACCACAATGTACAATATGTTTGACGTGGACCAATTGAATTACACATGTTGAGGCATTTTAATTGATATGACTAATAAGTATTTTATAAATAGTAATGAATTGTGGTGATAATTAACCAGCTCAACATGTACTCTACTAGATATCGACGTGGGTTCCAATCTACTTCGCGTAGAAGCTATTTGAGGTATCCTGTTTTTAAACGATCAACTGTTGGGAAAAGGAACGATAAGAAACGTCGATCTAGTACTCAGAACCGTTCCCATGATGAGTCGAAGTTGTTACATCAGCATATCCATGAGAACCAATTTGGCGATGAATTTGTAATGGCTCATAATACAGCCATTTCTACATACGTGACATTTCCTAGTCTTGGGAAGAGTGATTCATGCCGGACTAGGTCTTATATTAAGCTCAGGCGTTTACGCTTCAAAGGCACTGTTAAGATTGAACGTGTCATCCCTGACATAAGCATGGACGGGTCAATTCCCAAGACGGATGGAGTATTCACTCTTGTTATCGTGGTTGACCGTAAACCCCATCTCAATTCATCTGGATGTCTCTTGACATTCGACGAGTTATTTGGTGCTAGGATACACAGTCATGGTAATTTGACCATCTCACCCTCGTTGAAGGACCGGTTCTACATACGGCACGTGTTGAAACGTGTGTTAGCTGTAGAGAAGGATACTACGATGGCTGATCTTGAAGGGACGACATACTTATCTAATTGGCGTTTCAATTGTTGGTCCTCATTTAAGGACCTTGATCGAGATACTTGTAATGGTGTGTATGCTAATATAAGCAAGAACGCCATATTAGTTTACTATTGCTGGATGTCGGACTGTGTGTCTAAGGCATCGACATTTGTATCATTTGACCTTGATTATATTGGATAATAATAAAATTATGTTGCATGCAAGTATAATATTTATTTTAAGCATTTATTGCATTAACGCATCCAGACCAAGTAGTACAAGCACATAAATTTATTTCAATGATTTGGGCTGAGACGGGTTACAATTATTGTTAATACATTCTTGGGCCGTAGCCTTAACTAACTCGCTTAATTGGGCCATAGACATAGTTATAGTGGACTCTGTCCTCTTCGCTCCCACCATTGAAGCAGAATCACCTGGGTCTAATGTGCTTGGGCCCAGTCTGTGTAATTCTCTGTAGGGGTGGATTGAAGAGCCCACGTCAGAGTCTGCATCGTGATGATTGGTCCCTACGGTGCTTCTGGTAGCCCATGTCTCTCCTGGTATTATAGTAATTGGGCTGTGCAGCCCATATCTAGAGGACGATGCGGACCTTATCAATTTCCTTTCCCATTTGCCATAGCCAACATGTGAGAAGTCCACGTCTTTATCCGTGAACTGTTTGGACAGTATCTTTACAGTCGGAGCCCGGAAAGGGATGTCTACGGAGTGCTTTGCCGTGGAGAGTTTCAATTTCCCTTTGAACTTGGCAAAGTGTGTCCTCTGGTGGACATTTGTGTCACTGACGCGATAGTATAACTTCCATGGGATAGGGTCTTTAAGTGAGAAGAACGAGGAAGAGAAATAGTGGAGATCTATGTTACATCTGATGGGAAATGTCCATGAAGCTTGTAAGGACTCATTTTCAGTCATCCTTTGGTCATGAATCTCCACTATGACTGCGCCAGTTGCGTTGATGGGCACCTGCTGTCTGTATTCTATGACACAATGGTCTATTTTCATGCAACTGCGACTGAGTCTGGCGCTAAGTTGAGACGCTGTGGAAGGAAATTGAAGTACTATCTCAGTTAGATCATGAGACAATTGGTACTCATCCCGTTGAGACTCTATGTAATTGAACGCTGTTGGTGGACGGACTAACTGAGACTCCATTGATGATAATTATAATATTAAGAACGGCCGCGCAGCGCACACTCTCTGAGTGATATTATTCAGACAAGCTACTGCTATGATTATACGATAGATAGAGAAAGTGATGTTAGAGAGAGTGTGAATATGATAATACTTTGAAGCATACAGGTCTATAAATAGGCACATTGTTGATTAATTCGTAATTGCAATTAAAATAAGTAGTTGTGTTAATTTTGCTTCAAAGTGATACGCAGTCGTTTTGTATAGAATGCGAAAGCTTTGTGTAGTGGCATTTTTGTAATAAAAGGCATGTCACCAATTGCTAAAGGCTTGTCACCAATTGGGGTCTCGCAAAACTGTCGTCTGCAATCGGTGAAAGGGTGACAATTTATACTAGAAGTCCCAATAGAACTCTCAATCTCCAACGTACACGTGGCGGCCATCCGTTATAATATT
ACCGGATGGCCGCGCGATTTTTTCCCATTCCGACGTGGCATTCCTTTAATTTAATTTACAGTGTTAACCTTTTGACTAGACCAATCACTTTGTGTCTGACGAGCCTAGATATTTGTGACAACTTAGTCCCCAAGTTGTTCAACAGTTATAAATTAAAGGAAACCTGCCCTGTCACTTTAATTCAAAATGCCTAAGCGCGATGCCCCGTGGCGCAATATGGCAGGTACCTCTAAGATTAGTAGGACCTCCAACTACTCTCCTCGATCTGGCCCAAAATATAATAAGGCCAATGATTGGGTTAACAGGCCCATGTACAGGAAGCCCAGGATTTATCGGGTTTTAAGAACTGCTGATGTTCCTAGAGGATGTGAAGGCCCATGTAAGGTCCAATCATTTGAACAGCGCCATGACATTGCTCATACAGGGAAGGTCATATGTGTCTCTGATGTGACTAGAGGCAATGGCATTACTCACCGTGTTGGTAAGCGTTTCTGCATCAAGTCTGTGTACATTCTGGGTAAGATCTGGATGGATGACAACATCAAACTGAAGAATCACACCAACAGCGTCATGTTCTGGCTTGTTCGAGACAGGAGACCATATGGATCTCCTATGGACTTTGGACAGATATTCAACATGTTCGACAATGAGCCCAGTACTGCTACTGTTAAGAACGATCTCCGTGATCGTTTCCAGGTGATGCACAGGTTCTACGCCAAGGTGACAGGAGGGCAGTATGCAAGCAATGAACAAGCCATTGTCAAGCGTTTCTGGAAGGTCTACAACCATGTGGTCTACAACCATCAGGAAGCTGGGAAGTACGAGAATCACACTGAGAACGCATTATTACTGTATATGGCATGTACTCATGCCTCTAATCCTGTGTATGCAACGCTTAAGATTCGGATCTATTTTTATGATTCGATATCAAATTAATAAAAATTGAATTTTATTGAGTGATTCTCCAGTACATAATTTACATATGGTTTATCTGTTGCGAAACGAACAGCTAGGATTACATTATTAAGGGAAATAACACCTAACTGGTCTAAGTACAACAAGACTAATTGTTTAAATCTAGCTAAATATGTCGTCCCAGAAGCTTGAACTGATGTCGTCCAGACTTGGAAGTTTAGGTAAGCCTTGTGAAGATCCAACCTCTTCCTGAGGTTGTGGTTGAATCGGATCTGGACGTGGTACACTCTGGTTATTGTGTAATTGAGGTCCTCTACGCGGGATATCCTGAAAAACAGGGGATTTGTTATTTCCCAAGTATATACGCCACTCTGTGCCTGACGTGCAGTGATGTGTTCCCCTGTGCGTGAATCCATGGCCGATGCAGTCAATCTTCTGATATATGGAGCAACCGCACTCTAAGTCAAAACGCCTTCGCCTAATTGCTCTTCCCCTTTTGCAAGCTCTATGCTTTGGTTTAATAGAGGGGGGTGTTGAGGAAGATGAATTTTGCATTGTGAAGCGTCCACGCTCTCAGAGATGCATTTTCCTCTTTGTCGAGGAAATCTTTATAGCTAGCCCCCTCGCCAGGATTGCAGAGCACGATTGATGGTATTCCGCCTTTAATTTGAACTGGCTTTCCGTATTTGCAGTTGGATTGCCAGTCCCTTTGGGCCCCAATTAGTTCTTTCCAGTGCTTTAACTTTAAATAATTGGGGCTGATATCATCAATGACGTTATACTCTGCATTATTTGAGTAAACCTTGGAATTGAAGTCCAGGTGTCCACTCAAATAATTATGCGACCCCAATGCACGTGCCCACATGGTTTTGCCTGTTCTTGAATCACCTTCTATGATGATACTAATAGGTCGCTCAGGCCGCGCAGCGGCACCATTTCCGAAATAGTTGTTAGTCCATTCTTGCATTTCTTGAGGAACATTAATGAATGATGACAATGGAAATGGTGCAACCCAAGGCTCTGGAGCCTTTGCAAATATACGTTCCAAGTTAGACCGAATGTTATGGTGTTGAATCACATAGTCCTTGGGTTGCTCTTCTCTTAATATAAGAAGTGCCTGATCAATGGTTTTTGCGTTTAGAACTTTTGCATATGAGTCGTTGGCTGATTGGCTACCGCCTCTAGCACTTCTTCCGTCGACCTGGAATGTTCCCCATTCAACTGTATCTCCGTCCTTATCGACGTAGGACTTGACGTCGGAACTTGATTTAGCTGCCTGAATGTTCGGATGGAAATGTGTTGACCGGGATGGGGATACCAGGTCGAATAATCTGTTATTCGTGCAGCAGAATTTGCCTTCGAATTGAAGCAGGACGTGGAGATGAGGCTGCCCATCTTCGTGAAGCTCTCTTGCAATTTTGATGAATAATTTATTTGTTGGTGTATTTATGGCTTTTAGCTGTGAGAGAGCCTCATCTTTATATAGACTGCAGTGAGGATAAGTGAGGAAATAGTTTTTGGCATTTATACGAAAGCGTTTTGGTGGTGGCATTTTGGTAATAAAGGGGATGTCACCAATTACTCAAAGGCTTGTCACCAATTGGGCTCTCGCAAAACTGTCGTCTGCAATCGGTGAAAGGGTGACAATTTATACTAGAACCCCTAATAGAACTCTCAATCTCTACCATACACGTGGCGGCCATCCGTTATAATATT
Gene Information
|
NCBI Accession
|
YP_009547926.1
|
|
Location
|
426-1196 |
|
Protein Name
|
nuclear shuttle protein |
|
Coding Region
|
ATGTACTCTACTAGATATCGACGTGGGTTCCAATCTACTTCGCGTAGAAGCTATTTGAGGTATCCTGTTTTTAAACGATCAACTGTTGGGAAAAGGAACGATAAGAAACGTCGATCTAGTACTCAGAACCGTTCCCATGATGAGTCGAAGTTGTTACATCAGCATATCCATGAGAACCAATTTGGCGATGAATTTGTAATGGCTCATAATACAGCCATTTCTACATACGTGACATTTCCTAGTCTTGGGAAGAGTGATTCATGCCGGACTAGGTCTTATATTAAGCTCAGGCGTTTACGCTTCAAAGGCACTGTTAAGATTGAACGTGTCATCCCTGACATAAGCATGGACGGGTCAATTCCCAAGACGGATGGAGTATTCACTCTTGTTATCGTGGTTGACCGTAAACCCCATCTCAATTCATCTGGATGTCTCTTGACATTCGACGAGTTATTTGGTGCTAGGATACACAGTCATGGTAATTTGACCATCTCACCCTCGTTGAAGGACCGGTTCTACATACGGCACGTGTTGAAACGTGTGTTAGCTGTAGAGAAGGATACTACGATGGCTGATCTTGAAGGGACGACATACTTATCTAATTGGCGTTTCAATTGTTGGTCCTCATTTAAGGACCTTGATCGAGATACTTGTAATGGTGTGTATGCTAATATAAGCAAGAACGCCATATTAGTTTACTATTGCTGGATGTCGGACTGTGTGTCTAAGGCATCGACATTTGTATCATTTGACCTTGATTATATTGGATAA |
|
Protein Sequence
|
MYSTRYRRGFQSTSRRSYLRYPVFKRSTVGKRNDKKRRSSTQNRSHDESKLLHQHIHENQFGDEFVMAHNTAISTYVTFPSLGKSDSCRTRSYIKLRRLRFKGTVKIERVIPDISMDGSIPKTDGVFTLVIVVDRKPHLNSSGCLLTFDELFGARIHSHGNLTISPSLKDRFYIRHVLKRVLAVEKDTTMADLEGTTYLSNWRFNCWSSFKDLDRDTCNGVYANISKNAILVYYCWMSDCVSKASTFVSFDLDYIG |
|
NCBI Accession
|
YP_009547927.1
|
|
Location
|
1287-2168 |
|
Protein Name
|
movement protein |
|
Coding Region
|
ATGGAGTCTCAGTTAGTCCGTCCACCAACAGCGTTCAATTACATAGAGTCTCAACGGGATGAGTACCAATTGTCTCATGATCTAACTGAGATAGTACTTCAATTTCCTTCCACAGCGTCTCAACTTAGCGCCAGACTCAGTCGCAGTTGCATGAAAATAGACCATTGTGTCATAGAATACAGACAGCAGGTGCCCATCAACGCAACTGGCGCAGTCATAGTGGAGATTCATGACCAAAGGATGACTGAAAATGAGTCCTTACAAGCTTCATGGACATTTCCCATCAGATGTAACATAGATCTCCACTATTTCTCTTCCTCGTTCTTCTCACTTAAAGACCCTATCCCATGGAAGTTATACTATCGCGTCAGTGACACAAATGTCCACCAGAGGACACACTTTGCCAAGTTCAAAGGGAAATTGAAACTCTCCACGGCAAAGCACTCCGTAGACATCCCTTTCCGGGCTCCGACTGTAAAGATACTGTCCAAACAGTTCACGGATAAAGACGTGGACTTCTCACATGTTGGCTATGGCAAATGGGAAAGGAAATTGATAAGGTCCGCATCGTCCTCTAGATATGGGCTGCACAGCCCAATTACTATAATACCAGGAGAGACATGGGCTACCAGAAGCACCGTAGGGACCAATCATCACGATGCAGACTCTGACGTGGGCTCTTCAATCCACCCCTACAGAGAATTACACAGACTGGGCCCAAGCACATTAGACCCAGGTGATTCTGCTTCAATGGTGGGAGCGAAGAGGACAGAGTCCACTATAACTATGTCTATGGCCCAATTAAGCGAGTTAGTTAAGGCTACGGCCCAAGAATGTATTAACAATAATTGTAACCCGTCTCAGCCCAAATCATTGAAATAA |
|
Protein Sequence
|
MESQLVRPPTAFNYIESQRDEYQLSHDLTEIVLQFPSTASQLSARLSRSCMKIDHCVIEYRQQVPINATGAVIVEIHDQRMTENESLQASWTFPIRCNIDLHYFSSSFFSLKDPIPWKLYYRVSDTNVHQRTHFAKFKGKLKLSTAKHSVDIPFRAPTVKILSKQFTDKDVDFSHVGYGKWERKLIRSASSSRYGLHSPITIIPGETWATRSTVGTNHHDADSDVGSSIHPYRELHRLGPSTLDPGDSASMVGAKRTESTITMSMAQLSELVKATAQECINNNCNPSQPKSLK |
|
NCBI Accession
|
YP_009508312.1
|
|
Location
|
187-936 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGCCTAAGCGCGATGCCCCGTGGCGCAATATGGCAGGTACCTCTAAGATTAGTAGGACCTCCAACTACTCTCCTCGATCTGGCCCAAAATATAATAAGGCCAATGATTGGGTTAACAGGCCCATGTACAGGAAGCCCAGGATTTATCGGGTTTTAAGAACTGCTGATGTTCCTAGAGGATGTGAAGGCCCATGTAAGGTCCAATCATTTGAACAGCGCCATGACATTGCTCATACAGGGAAGGTCATATGTGTCTCTGATGTGACTAGAGGCAATGGCATTACTCACCGTGTTGGTAAGCGTTTCTGCATCAAGTCTGTGTACATTCTGGGTAAGATCTGGATGGATGACAACATCAAACTGAAGAATCACACCAACAGCGTCATGTTCTGGCTTGTTCGAGACAGGAGACCATATGGATCTCCTATGGACTTTGGACAGATATTCAACATGTTCGACAATGAGCCCAGTACTGCTACTGTTAAGAACGATCTCCGTGATCGTTTCCAGGTGATGCACAGGTTCTACGCCAAGGTGACAGGAGGGCAGTATGCAAGCAATGAACAAGCCATTGTCAAGCGTTTCTGGAAGGTCTACAACCATGTGGTCTACAACCATCAGGAAGCTGGGAAGTACGAGAATCACACTGAGAACGCATTATTACTGTATATGGCATGTACTCATGCCTCTAATCCTGTGTATGCAACGCTTAAGATTCGGATCTATTTTTATGATTCGATATCAAATTAA |
|
Protein Sequence
|
MPKRDAPWRNMAGTSKISRTSNYSPRSGPKYNKANDWVNRPMYRKPRIYRVLRTADVPRGCEGPCKVQSFEQRHDIAHTGKVICVSDVTRGNGITHRVGKRFCIKSVYILGKIWMDDNIKLKNHTNSVMFWLVRDRRPYGSPMDFGQIFNMFDNEPSTATVKNDLRDRFQVMHRFYAKVTGGQYASNEQAIVKRFWKVYNHVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSISN |
|
NCBI Accession
|
YP_009508313.1
|
|
Location
|
933-1331 |
|
Protein Name
|
replication enhancer protein |
|
Coding Region
|
ATGGATTCACGCACAGGGGAACACATCACTGCACGTCAGGCACAGAGTGGCGTATATACTTGGGAAATAACAAATCCCCTGTTTTTCAGGATATCCCGCGTAGAGGACCTCAATTACACAATAACCAGAGTGTACCACGTCCAGATCCGATTCAACCACAACCTCAGGAAGAGGTTGGATCTTCACAAGGCTTACCTAAACTTCCAAGTCTGGACGACATCAGTTCAAGCTTCTGGGACGACATATTTAGCTAGATTTAAACAATTAGTCTTGTTGTACTTAGACCAGTTAGGTGTTATTTCCCTTAATAATGTAATCCTAGCTGTTCGTTTCGCAACAGATAAACCATATGTAAATTATGTACTGGAGAATCACTCAATAAAATTCAATTTTTATTAA |
|
Protein Sequence
|
MDSRTGEHITARQAQSGVYTWEITNPLFFRISRVEDLNYTITRVYHVQIRFNHNLRKRLDLHKAYLNFQVWTTSVQASGTTYLARFKQLVLLYLDQLGVISLNNVILAVRFATDKPYVNYVLENHSIKFNFY |
|
NCBI Accession
|
YP_009508314.1
|
|
Location
|
1078-1470 |
|
Protein Name
|
transcriptional activator protein |
|
Coding Region
|
ATGCAAAATTCATCTTCCTCAACACCCCCCTCTATTAAACCAAAGCATAGAGCTTGCAAAAGGGGAAGAGCAATTAGGCGAAGGCGTTTTGACTTAGAGTGCGGTTGCTCCATATATCAGAAGATTGACTGCATCGGCCATGGATTCACGCACAGGGGAACACATCACTGCACGTCAGGCACAGAGTGGCGTATATACTTGGGAAATAACAAATCCCCTGTTTTTCAGGATATCCCGCGTAGAGGACCTCAATTACACAATAACCAGAGTGTACCACGTCCAGATCCGATTCAACCACAACCTCAGGAAGAGGTTGGATCTTCACAAGGCTTACCTAAACTTCCAAGTCTGGACGACATCAGTTCAAGCTTCTGGGACGACATATTTAGCTAG |
|
Protein Sequence
|
MQNSSSSTPPSIKPKHRACKRGRAIRRRRFDLECGCSIYQKIDCIGHGFTHRGTHHCTSGTEWRIYLGNNKSPVFQDIPRRGPQLHNNQSVPRPDPIQPQPQEEVGSSQGLPKLPSLDDISSSFWDDIFS |
|
NCBI Accession
|
YP_009508315.1
|
|
Location
|
1433-2467 |
|
Protein Name
|
replication-associated protein |
|
Coding Region
|
ATGCCACCACCAAAACGCTTTCGTATAAATGCCAAAAACTATTTCCTCACTTATCCTCACTGCAGTCTATATAAAGATGAGGCTCTCTCACAGCTAAAAGCCATAAATACACCAACAAATAAATTATTCATCAAAATTGCAAGAGAGCTTCACGAAGATGGGCAGCCTCATCTCCACGTCCTGCTTCAATTCGAAGGCAAATTCTGCTGCACGAATAACAGATTATTCGACCTGGTATCCCCATCCCGGTCAACACATTTCCATCCGAACATTCAGGCAGCTAAATCAAGTTCCGACGTCAAGTCCTACGTCGATAAGGACGGAGATACAGTTGAATGGGGAACATTCCAGGTCGACGGAAGAAGTGCTAGAGGCGGTAGCCAATCAGCCAACGACTCATATGCAAAAGTTCTAAACGCAAAAACCATTGATCAGGCACTTCTTATATTAAGAGAAGAGCAACCCAAGGACTATGTGATTCAACACCATAACATTCGGTCTAACTTGGAACGTATATTTGCAAAGGCTCCAGAGCCTTGGGTTGCACCATTTCCATTGTCATCATTCATTAATGTTCCTCAAGAAATGCAAGAATGGACTAACAACTATTTCGGAAATGGTGCCGCTGCGCGGCCTGAGCGACCTATTAGTATCATCATAGAAGGTGATTCAAGAACAGGCAAAACCATGTGGGCACGTGCATTGGGGTCGCATAATTATTTGAGTGGACACCTGGACTTCAATTCCAAGGTTTACTCAAATAATGCAGAGTATAACGTCATTGATGATATCAGCCCCAATTATTTAAAGTTAAAGCACTGGAAAGAACTAATTGGGGCCCAAAGGGACTGGCAATCCAACTGCAAATACGGAAAGCCAGTTCAAATTAAAGGCGGAATACCATCAATCGTGCTCTGCAATCCTGGCGAGGGGGCTAGCTATAAAGATTTCCTCGACAAAGAGGAAAATGCATCTCTGAGAGCGTGGACGCTTCACAATGCAAAATTCATCTTCCTCAACACCCCCCTCTATTAA |
|
Protein Sequence
|
MPPPKRFRINAKNYFLTYPHCSLYKDEALSQLKAINTPTNKLFIKIARELHEDGQPHLHVLLQFEGKFCCTNNRLFDLVSPSRSTHFHPNIQAAKSSSDVKSYVDKDGDTVEWGTFQVDGRSARGGSQSANDSYAKVLNAKTIDQALLILREEQPKDYVIQHHNIRSNLERIFAKAPEPWVAPFPLSSFINVPQEMQEWTNNYFGNGAAARPERPISIIIEGDSRTGKTMWARALGSHNYLSGHLDFNSKVYSNNAEYNVIDDISPNYLKLKHWKELIGAQRDWQSNCKYGKPVQIKGGIPSIVLCNPGEGASYKDFLDKEENASLRAWTLHNAKFIFLNTPLY |
|
NCBI Accession
|
YP_009508316.1
|
|
Location
|
2053-2310 |
|
Protein Name
|
AC4 protein |
|
Coding Region
|
ATGGGCAGCCTCATCTCCACGTCCTGCTTCAATTCGAAGGCAAATTCTGCTGCACGAATAACAGATTATTCGACCTGGTATCCCCATCCCGGTCAACACATTTCCATCCGAACATTCAGGCAGCTAAATCAAGTTCCGACGTCAAGTCCTACGTCGATAAGGACGGAGATACAGTTGAATGGGGAACATTCCAGGTCGACGGAAGAAGTGCTAGAGGCGGTAGCCAATCAGCCAACGACTCATATGCAAAAGTTCTAA |
|
Protein Sequence
|
MGSLISTSCFNSKANSAARITDYSTWYPHPGQHISIRTFRQLNQVPTSSPTSIRTEIQLNGEHSRSTEEVLEAVANQPTTHMQKF |