Tomato chlorotic leaf curl virus
Basic Information
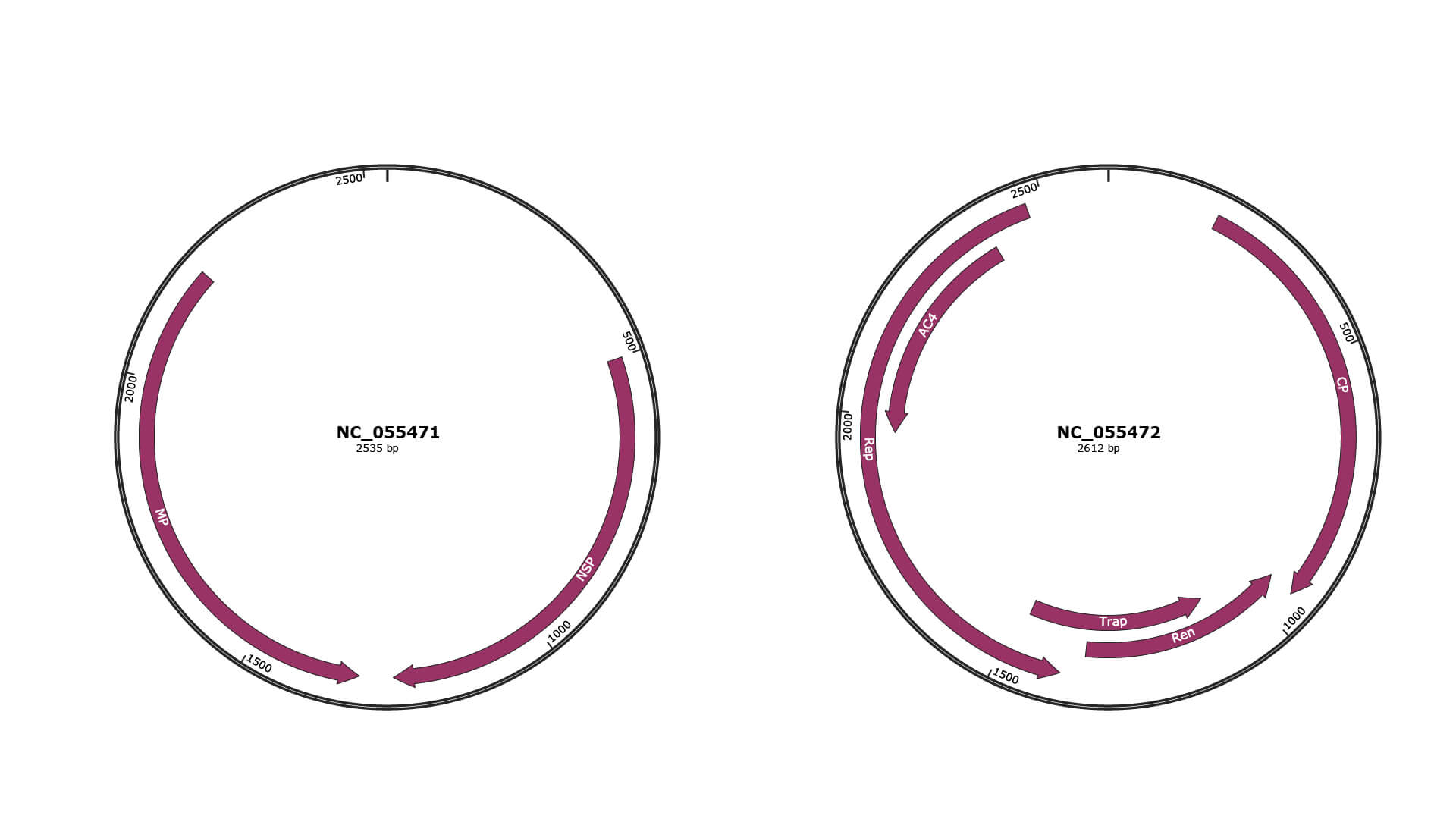
Genomic Organization
JBrowse
Genome
ACTGGATGGCCGCGCGATTTTTGGTGTCCTATACCCCCTGCGTGGCGCTTTGGTGTCCGTTAATCTCCCGTTCGCAACACGTGGCGTTGTGTTGCTCGCGCGATTATTTTGTATAAATTCAGTTGAGCGCTATTTTGAAGTCCGCGATTTTAGTTGAGCGCATTTTTTGAGTTCCACCTACCGCATGTTGACAAGTGTCCAACTATCAGCTTTGTTAGTATTCGCTTTCGTTTTTTTTTTTATAAAGATCTGTTTATGGCCTTTGGATAAAAATAAGAACGATTTGAAATTTGAATTGTAATTGCGCTATATTTTATTATGGTCCACATCCTAATATACTTCTTTTTGTGAAATTCAAATTTAATTTAATATGTCGTGGCGGAATTACAAACCAATGGCTGAGGCAAGATAATTTATTTGAAGGGTAAATGTTTATATAAAGGCCGTCTTAACGGATTATTATGATAGATATCTCATATATCTATCAGTTAAATAAGTAAAATGTATTCAAGTAAATACAAACGTGGTGGGTCTTTTAATGTCCGCCGTGGTTCTTTAAGAAATCCCACGTCTAAGCGTTATCTCTCAATGAAACGTCGATCGGGATTAGCGAATAAGTCACAAGAAAATAGTAAGATGACATCTCAACGCATTCACGAGAACCAGTTTGGACCAGAATTTGTGATGGGCCATAATTCAGCTATTTCTTCGTATATAACGTTTCCATCTGTTGGTAAGAGTGAGCCGAACCGGTCCAGGTCATATATCAAGTTAAAACGTCTACGTTTTAAAGGGACTGTAAAGGTAGAACGTGCACATGTCGACGTTAACATGGATGGATCAGCTCAGAAGATCGAGGGCGTATTTTCAATGGTAATCGTGGTCGATCGTAAACCTCATTTGGGTTCTTCAGGGCGCCTTCACACGTTCGATGAATTATTCGGTGCTAGGATTCACAGCCATGGTAACCTGGCGATATCTCCAGGCTTAAAGGACCGTTACTACATACGGCATGTTCATAAACGTGTTTTGTCTGTGGAGAAGGACAGTTTGATGGTTGATATTGAAGGAACGACATCGTTCTCTAACAGGCGTTTTAATTGTTGGTCTAGTTTTAATGACGTTGACCGTGACTCATGTAACGGTGTATACGCCAATATTAACAAGAACGCATTACTAGTATATTACTGTTGGATGTCTGATATTTCATCGAAGGCATCGACTTTTGTATCGTTTGACTTAGATTATGTCGGTTGATTGTAATGACTATATTGGGAATAATGATAATTGCAATTAAATTATTTTATTAAATAATTATTTGAGAGACTTCGTTTCTGACGGAGTACAATTGGTATTAATACATTCCTGAACAGTTGTTCTAACTAACTCGTTCAACTGGGCCATTGACATCGTTATGTTGGATTGGGCCCTCTGGTCTCCCACAATTGAGGCGGATTCTCCTGGATCTAATATCGTTGTTCCCAGCCGATTTAGTTCTCGATAAGGATGTATTTCCTCTCCGATGTCGGATCCCGCATATGAATTGTTGGGTCCAATCGTACTCCTTGAAGCCCATGACTCTCCCGGCTTTAGCTCAATTGGGCAGTGAAGCCCATATCTGGCAACCGAATTGGACCTGACTGTTTTCCTTTCCCATTTCCCGTAGCCGACGTGGCAGAAATCGACGTCTTTTTCTGTAAACTGTTTAGACAGTATCTTCACTGTAGGTGCTCGGAAAGGAATATCGACAGAGTGCTTCGCCGTCGACAACTTTAGCTTTCCCTTAAATTTGGCAAAGTGGGTCCTCTGATGAACATTTGTATCGCATACCCTGTAGTATAACTTCCATGGAATAGGATCTTTAAGTGAGAAGAACGACGATGAGAAATAATGAAGATCTATGTTACATCTAATCGGAAAAGTCCATGACGCCTGCAATGATTCGTTGTCTGTCATTCTCTTGTCATGGATCTCCACGACGACTGACCCCGTAGCGTTTATCGGAACCTGTTGCCTGAATTCGATGACGCAATGGTCTATCTTCATACAGCTACGGCTTAGTCTTGCGCTTATTTGAGACGCCGTTGATGGAAATTGTAGGATGATCTCTGTCAGATCATGAGATAGCTGATACTCATCACGCTGAGATTCGATGTAATTAAAGGCATTTGGAGGATTCATTAATTGGGATTCCATTCTGAAAAAAGGGAGCGCAGCGACAATGGGAGGGTGAAGTGAAAGAGTAAAGTTAAAAGTTGAAAAAGAAATTAGGGTTTTGATAAGGAAGATGATAGACGACGGACTGAGAGGAGATATTATTGAAAGGGTAATCTAATTAATTTGGTGATGAATATTCTCTTTAAATAGAGTTTTCGCTGAAGATGTAATGGCATTTTTGTAAATATGAATCAGGACACCAGGGGGAGCTCTCAACTTCTCTCATATTTGCTGGTGTCCTGGTGTCCCATTTATACTATAAGGCTCTTAAAGGCTCTTGGGGACACCAGGGGCAAAAGCGGCCATCCATATAATATT
ACTGGATGGCCGCGCGATTTTTGGTGTCCTATGCGCTATGGCCCGGCCCATTTGAATTAAAGATGAAATCTTTTCGCTTGGCCAATCATATTGCGTCTGGGAAGCCTAGATATCCGTTCCGATACTTAGAGCCGAAGTTTTTGATCAACGGCTATAAAATAAAGGAAGACTGGTCACAGTCTTTAATTCAGAATGCCTAAGCGGGAAGCCCCGTGGCGCCTGATGGCGGGAACAACTAAGGTTAGTCGACCTGCTGGCTATTCCACCCGTTTAGCTCCCGGCCCAAGAATAAACAAGGCCGCAGAATGGGTGAACAGGCCCATGTACAGGAAGCCCAGGATATATAGGGTTTTGAGGACACCTGATGTCCCTAGAGGGTGTGAGGGGCCTTGTAAGGTCCAGTCCTACGAGCAGCGGCATGATATCTCTCATGCCGGGAAGGTGATATGTATATCTGATGTCACACGTGGCAGTGGTATCACCCACCGTGTTGGTAAGCGTTTCTGTGTCAAGTCTGTGTACATTTTAGGCAAGATCTGGATGGACGAGAACATCAAGCTCAAGAACCACACGAACAGTGTCATGTTCTGGTTGGTCAGAGACAGACGACCGAACGGTACGCCCATGGATTTCGGACATTTATTTAACATGTTCGACAACGAGCCCAGCACCGCTACGGTCAAGAATGATCTCCGTGATCGGTTCCAGGTTTTGCACAGGTTTTATGCCAAGGTCACAGGTGGTCAATACGCCAGCAATGAACAGGCGCTGGTCAAGCGGTTCTGGAAGGTCAACAACCATGTGGTGTACAACAACCAGGAAGCCGCTCGATACGAGAATCATACGGAGAACGCCCTGTTATTGTATATGGCATGTACTCATGCCTCTAACCCTGTGTATGCAACGCTTAAGATTCGAATCTATTTCTACGATTCGATAACAAATTAATAAATTTTGAATTTTATTGAATGATTTTCAAGTACATGACTGACATACGACTTGTCTGTTGCAAAACGAACAGCTCTAATTACATTATTAATTGCGATTACCCCTAATCGGTCTAGATACAGCAAAACTAAATGTCTAAATCTATTTAAATATGTCTTCCCAGAAGCTGTCAGAGATGTCGTCCAAACTTGGAAATTCAGGAATGCCTTGTGGAGATGCAACGCTCTCCTCAGGTTGTGATTGAACCTTATCTGGAGGTGATATACTCTGGTCGTCGTGTACGGGATGTCTTCTACTCTGTACATCTTGAAATACAGGGGATTTGTTATCCCCCAGATATAGACGCCACTCTCTGCCTGATGTGCAGTGATGAGTTCCCCTGTGCGTGAATCCATAACCATGGCAATTGAGGTTTACGTATATGGTGCACCCGCAGTTCAAGTCAATCCGCCGTCGTCGGATGGCTCTCTTCTTCGCAATCCTGTGTTTGGTTTTGATAGAGGGGGGAGTTGAGGAAGATGAATTTAGCATTGTGTAGCGTCCAAGATTTTAGTGATGCATTTTCCTCTTTCTCGAGGAAATCTTTATAGCTGGCCCCCTCGCCAGGATTGCAGAGCACGATTGCTGGGATTCCTCCTTTAATTTGAACTGGCTTACCGTACTTACAATTTGACTGCCAGTCTTTTTGAGCACCAATCAGCTCCTTCCAATGCTTTAACTTTAAATAATGCGGGGTGACATCATCGATGACGTTATACTCAACTTCGTTTGAGTAAACCCTAGAATTGAAGTCCAAGTGTCCACTTAAATAATTATGTGGGCCTAAGGCACGAGCCCACATCGTCTTCCCTGTTCGAGAGTCACCCTCAACTATGATACTTACAGGTCTCTCCGGCCGCGCAGCGGCACCTCTTCCAAAATAATCATCCGCCCATTCTTGCAGCTCTTCTGGAACGTTAGTGAACGATGCGAGTGGGAACGGAGGGACCCACGGTTCTGGAGCCCTTTTGAATATCCGTTCTAGGTTAGAGCGGATGTTATGGTGTTGGACGATGTATGATTTTGGATCTCCGGCTTTGATAATGTCAAGAGCCTCTGAAACACTTCCTGCATGGACGGCGTTGTGATAGACATCGTCCTTATTGGCTTTGGTTCCCCCAGAAACCTTGTACTGTCCGGATTCACAATAGTCACCCTCTTTGGTGATGTAATTCTTGACGGCATTGGTGTCTTTGGCTGCCTGAATATTTGGGTGAAAAGTGGTTGACCGTCTGGGGTGAGTAAGGTCGAAAAATCTAGCATCCTTGATGTTGGACTTCCCGGAGAGTTGAACAAGGCAGTGGAGATGGGGGTTTCCGTCTGCGTGATCCTCTCTGGCGACCCTGATATAGGTTGGCTTGACGACTGACCATGGAAGGGTTTGAAGCATCTGAAGAGCTTCATCTTTGGTTATGTCGCACTTGGGATAAGTTAAGAAAATGTTTTTAGCTGCAAGCCTAAAAGTATTAGGTTGTCGTGGCATTTTTGTAAATATTAACCAGGACACCAGGGGGAGCTCTCAACTTCTCTCATATTTGCTGGTGTCCTGGTGTCCCATTTATACTATAAGGCTCTTAAAGGCTCTTGGGGACACCAGGGGCAAAAGCGGCCATCCATATAATATT
Gene Information
|
NCBI Accession
|
YP_010086753.1
|
|
Location
|
502-1257 |
|
Gene Name
|
NSP |
|
Protein Name
|
nuclear shuttle protein |
|
Coding Region
|
ATGTATTCAAGTAAATACAAACGTGGTGGGTCTTTTAATGTCCGCCGTGGTTCTTTAAGAAATCCCACGTCTAAGCGTTATCTCTCAATGAAACGTCGATCGGGATTAGCGAATAAGTCACAAGAAAATAGTAAGATGACATCTCAACGCATTCACGAGAACCAGTTTGGACCAGAATTTGTGATGGGCCATAATTCAGCTATTTCTTCGTATATAACGTTTCCATCTGTTGGTAAGAGTGAGCCGAACCGGTCCAGGTCATATATCAAGTTAAAACGTCTACGTTTTAAAGGGACTGTAAAGGTAGAACGTGCACATGTCGACGTTAACATGGATGGATCAGCTCAGAAGATCGAGGGCGTATTTTCAATGGTAATCGTGGTCGATCGTAAACCTCATTTGGGTTCTTCAGGGCGCCTTCACACGTTCGATGAATTATTCGGTGCTAGGATTCACAGCCATGGTAACCTGGCGATATCTCCAGGCTTAAAGGACCGTTACTACATACGGCATGTTCATAAACGTGTTTTGTCTGTGGAGAAGGACAGTTTGATGGTTGATATTGAAGGAACGACATCGTTCTCTAACAGGCGTTTTAATTGTTGGTCTAGTTTTAATGACGTTGACCGTGACTCATGTAACGGTGTATACGCCAATATTAACAAGAACGCATTACTAGTATATTACTGTTGGATGTCTGATATTTCATCGAAGGCATCGACTTTTGTATCGTTTGACTTAGATTATGTCGGTTGA |
|
Protein Sequence
|
MYSSKYKRGGSFNVRRGSLRNPTSKRYLSMKRRSGLANKSQENSKMTSQRIHENQFGPEFVMGHNSAISSYITFPSVGKSEPNRSRSYIKLKRLRFKGTVKVERAHVDVNMDGSAQKIEGVFSMVIVVDRKPHLGSSGRLHTFDELFGARIHSHGNLAISPGLKDRYYIRHVHKRVLSVEKDSLMVDIEGTTSFSNRRFNCWSSFNDVDRDSCNGVYANINKNALLVYYCWMSDISSKASTFVSFDLDYVG |
|
NCBI Accession
|
YP_010086754.1
|
|
Location
|
1315-2196 |
|
Gene Name
|
MP |
|
Protein Name
|
movement protein |
|
Coding Region
|
ATGGAATCCCAATTAATGAATCCTCCAAATGCCTTTAATTACATCGAATCTCAGCGTGATGAGTATCAGCTATCTCATGATCTGACAGAGATCATCCTACAATTTCCATCAACGGCGTCTCAAATAAGCGCAAGACTAAGCCGTAGCTGTATGAAGATAGACCATTGCGTCATCGAATTCAGGCAACAGGTTCCGATAAACGCTACGGGGTCAGTCGTCGTGGAGATCCATGACAAGAGAATGACAGACAACGAATCATTGCAGGCGTCATGGACTTTTCCGATTAGATGTAACATAGATCTTCATTATTTCTCATCGTCGTTCTTCTCACTTAAAGATCCTATTCCATGGAAGTTATACTACAGGGTATGCGATACAAATGTTCATCAGAGGACCCACTTTGCCAAATTTAAGGGAAAGCTAAAGTTGTCGACGGCGAAGCACTCTGTCGATATTCCTTTCCGAGCACCTACAGTGAAGATACTGTCTAAACAGTTTACAGAAAAAGACGTCGATTTCTGCCACGTCGGCTACGGGAAATGGGAAAGGAAAACAGTCAGGTCCAATTCGGTTGCCAGATATGGGCTTCACTGCCCAATTGAGCTAAAGCCGGGAGAGTCATGGGCTTCAAGGAGTACGATTGGACCCAACAATTCATATGCGGGATCCGACATCGGAGAGGAAATACATCCTTATCGAGAACTAAATCGGCTGGGAACAACGATATTAGATCCAGGAGAATCCGCCTCAATTGTGGGAGACCAGAGGGCCCAATCCAACATAACGATGTCAATGGCCCAGTTGAACGAGTTAGTTAGAACAACTGTTCAGGAATGTATTAATACCAATTGTACTCCGTCAGAAACGAAGTCTCTCAAATAA |
|
Protein Sequence
|
MESQLMNPPNAFNYIESQRDEYQLSHDLTEIILQFPSTASQISARLSRSCMKIDHCVIEFRQQVPINATGSVVVEIHDKRMTDNESLQASWTFPIRCNIDLHYFSSSFFSLKDPIPWKLYYRVCDTNVHQRTHFAKFKGKLKLSTAKHSVDIPFRAPTVKILSKQFTEKDVDFCHVGYGKWERKTVRSNSVARYGLHCPIELKPGESWASRSTIGPNNSYAGSDIGEEIHPYRELNRLGTTILDPGESASIVGDQRAQSNITMSMAQLNELVRTTVQECINTNCTPSETKSLK |
|
NCBI Accession
|
YP_010086755.1
|
|
Location
|
193-948 |
|
Gene Name
|
CP |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGCCTAAGCGGGAAGCCCCGTGGCGCCTGATGGCGGGAACAACTAAGGTTAGTCGACCTGCTGGCTATTCCACCCGTTTAGCTCCCGGCCCAAGAATAAACAAGGCCGCAGAATGGGTGAACAGGCCCATGTACAGGAAGCCCAGGATATATAGGGTTTTGAGGACACCTGATGTCCCTAGAGGGTGTGAGGGGCCTTGTAAGGTCCAGTCCTACGAGCAGCGGCATGATATCTCTCATGCCGGGAAGGTGATATGTATATCTGATGTCACACGTGGCAGTGGTATCACCCACCGTGTTGGTAAGCGTTTCTGTGTCAAGTCTGTGTACATTTTAGGCAAGATCTGGATGGACGAGAACATCAAGCTCAAGAACCACACGAACAGTGTCATGTTCTGGTTGGTCAGAGACAGACGACCGAACGGTACGCCCATGGATTTCGGACATTTATTTAACATGTTCGACAACGAGCCCAGCACCGCTACGGTCAAGAATGATCTCCGTGATCGGTTCCAGGTTTTGCACAGGTTTTATGCCAAGGTCACAGGTGGTCAATACGCCAGCAATGAACAGGCGCTGGTCAAGCGGTTCTGGAAGGTCAACAACCATGTGGTGTACAACAACCAGGAAGCCGCTCGATACGAGAATCATACGGAGAACGCCCTGTTATTGTATATGGCATGTACTCATGCCTCTAACCCTGTGTATGCAACGCTTAAGATTCGAATCTATTTCTACGATTCGATAACAAATTAA |
|
Protein Sequence
|
MPKREAPWRLMAGTTKVSRPAGYSTRLAPGPRINKAAEWVNRPMYRKPRIYRVLRTPDVPRGCEGPCKVQSYEQRHDISHAGKVICISDVTRGSGITHRVGKRFCVKSVYILGKIWMDENIKLKNHTNSVMFWLVRDRRPNGTPMDFGHLFNMFDNEPSTATVKNDLRDRFQVLHRFYAKVTGGQYASNEQALVKRFWKVNNHVVYNNQEAARYENHTENALLLYMACTHASNPVYATLKIRIYFYDSITN |
|
NCBI Accession
|
YP_010086756.1
|
|
Location
|
945-1349 |
|
Gene Name
|
Ren |
|
Protein Name
|
replication enhancer protein |
|
Coding Region
|
ATGGTTATGGATTCACGCACAGGGGAACTCATCACTGCACATCAGGCAGAGAGTGGCGTCTATATCTGGGGGATAACAAATCCCCTGTATTTCAAGATGTACAGAGTAGAAGACATCCCGTACACGACGACCAGAGTATATCACCTCCAGATAAGGTTCAATCACAACCTGAGGAGAGCGTTGCATCTCCACAAGGCATTCCTGAATTTCCAAGTTTGGACGACATCTCTGACAGCTTCTGGGAAGACATATTTAAATAGATTTAGACATTTAGTTTTGCTGTATCTAGACCGATTAGGGGTAATCGCAATTAATAATGTAATTAGAGCTGTTCGTTTTGCAACAGACAAGTCGTATGTCAGTCATGTACTTGAAAATCATTCAATAAAATTCAAAATTTATTAA |
|
Protein Sequence
|
MVMDSRTGELITAHQAESGVYIWGITNPLYFKMYRVEDIPYTTTRVYHLQIRFNHNLRRALHLHKAFLNFQVWTTSLTASGKTYLNRFRHLVLLYLDRLGVIAINNVIRAVRFATDKSYVSHVLENHSIKFKIY |
|
NCBI Accession
|
YP_010086757.1
|
|
Location
|
1090-1479 |
|
Gene Name
|
Trap |
|
Protein Name
|
trans-activating protein |
|
Coding Region
|
ATGCTAAATTCATCTTCCTCAACTCCCCCCTCTATCAAAACCAAACACAGGATTGCGAAGAAGAGAGCCATCCGACGACGGCGGATTGACTTGAACTGCGGGTGCACCATATACGTAAACCTCAATTGCCATGGTTATGGATTCACGCACAGGGGAACTCATCACTGCACATCAGGCAGAGAGTGGCGTCTATATCTGGGGGATAACAAATCCCCTGTATTTCAAGATGTACAGAGTAGAAGACATCCCGTACACGACGACCAGAGTATATCACCTCCAGATAAGGTTCAATCACAACCTGAGGAGAGCGTTGCATCTCCACAAGGCATTCCTGAATTTCCAAGTTTGGACGACATCTCTGACAGCTTCTGGGAAGACATATTTAAATAG |
|
Protein Sequence
|
MLNSSSSTPPSIKTKHRIAKKRAIRRRRIDLNCGCTIYVNLNCHGYGFTHRGTHHCTSGREWRLYLGDNKSPVFQDVQSRRHPVHDDQSISPPDKVQSQPEESVASPQGIPEFPSLDDISDSFWEDIFK |
|
NCBI Accession
|
YP_010086758.1
|
|
Location
|
1391-2470 |
|
Gene Name
|
Rep |
|
Protein Name
|
replication-associated protein |
|
Coding Region
|
ATGCCACGACAACCTAATACTTTTAGGCTTGCAGCTAAAAACATTTTCTTAACTTATCCCAAGTGCGACATAACCAAAGATGAAGCTCTTCAGATGCTTCAAACCCTTCCATGGTCAGTCGTCAAGCCAACCTATATCAGGGTCGCCAGAGAGGATCACGCAGACGGAAACCCCCATCTCCACTGCCTTGTTCAACTCTCCGGGAAGTCCAACATCAAGGATGCTAGATTTTTCGACCTTACTCACCCCAGACGGTCAACCACTTTTCACCCAAATATTCAGGCAGCCAAAGACACCAATGCCGTCAAGAATTACATCACCAAAGAGGGTGACTATTGTGAATCCGGACAGTACAAGGTTTCTGGGGGAACCAAAGCCAATAAGGACGATGTCTATCACAACGCCGTCCATGCAGGAAGTGTTTCAGAGGCTCTTGACATTATCAAAGCCGGAGATCCAAAATCATACATCGTCCAACACCATAACATCCGCTCTAACCTAGAACGGATATTCAAAAGGGCTCCAGAACCGTGGGTCCCTCCGTTCCCACTCGCATCGTTCACTAACGTTCCAGAAGAGCTGCAAGAATGGGCGGATGATTATTTTGGAAGAGGTGCCGCTGCGCGGCCGGAGAGACCTGTAAGTATCATAGTTGAGGGTGACTCTCGAACAGGGAAGACGATGTGGGCTCGTGCCTTAGGCCCACATAATTATTTAAGTGGACACTTGGACTTCAATTCTAGGGTTTACTCAAACGAAGTTGAGTATAACGTCATCGATGATGTCACCCCGCATTATTTAAAGTTAAAGCATTGGAAGGAGCTGATTGGTGCTCAAAAAGACTGGCAGTCAAATTGTAAGTACGGTAAGCCAGTTCAAATTAAAGGAGGAATCCCAGCAATCGTGCTCTGCAATCCTGGCGAGGGGGCCAGCTATAAAGATTTCCTCGAGAAAGAGGAAAATGCATCACTAAAATCTTGGACGCTACACAATGCTAAATTCATCTTCCTCAACTCCCCCCTCTATCAAAACCAAACACAGGATTGCGAAGAAGAGAGCCATCCGACGACGGCGGATTGA |
|
Protein Sequence
|
MPRQPNTFRLAAKNIFLTYPKCDITKDEALQMLQTLPWSVVKPTYIRVAREDHADGNPHLHCLVQLSGKSNIKDARFFDLTHPRRSTTFHPNIQAAKDTNAVKNYITKEGDYCESGQYKVSGGTKANKDDVYHNAVHAGSVSEALDIIKAGDPKSYIVQHHNIRSNLERIFKRAPEPWVPPFPLASFTNVPEELQEWADDYFGRGAAARPERPVSIIVEGDSRTGKTMWARALGPHNYLSGHLDFNSRVYSNEVEYNVIDDVTPHYLKLKHWKELIGAQKDWQSNCKYGKPVQIKGGIPAIVLCNPGEGASYKDFLEKEENASLKSWTLHNAKFIFLNSPLYQNQTQDCEEESHPTTAD |
|
NCBI Accession
|
YP_010086759.1
|
|
Location
|
1969-2391 |
|
Gene Name
|
AC4 |
|
Protein Name
|
AC4 protein |
|
Coding Region
|
ATGAAGCTCTTCAGATGCTTCAAACCCTTCCATGGTCAGTCGTCAAGCCAACCTATATCAGGGTCGCCAGAGAGGATCACGCAGACGGAAACCCCCATCTCCACTGCCTTGTTCAACTCTCCGGGAAGTCCAACATCAAGGATGCTAGATTTTTCGACCTTACTCACCCCAGACGGTCAACCACTTTTCACCCAAATATTCAGGCAGCCAAAGACACCAATGCCGTCAAGAATTACATCACCAAAGAGGGTGACTATTGTGAATCCGGACAGTACAAGGTTTCTGGGGGAACCAAAGCCAATAAGGACGATGTCTATCACAACGCCGTCCATGCAGGAAGTGTTTCAGAGGCTCTTGACATTATCAAAGCCGGAGATCCAAAATCATACATCGTCCAACACCATAACATCCGCTCTAACCTAG |
|
Protein Sequence
|
MKLFRCFKPFHGQSSSQPISGSPERITQTETPISTALFNSPGSPTSRMLDFSTLLTPDGQPLFTQIFRQPKTPMPSRITSPKRVTIVNPDSTRFLGEPKPIRTMSITTPSMQEVFQRLLTLSKPEIQNHTSSNTITSALT |