Tomato chino La Paz virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_000842645.1 |
| Isolate |
Mexico: Baja California Sur, La Paz |
| Release date |
2015/2/12 |
| Submitter |
Holguin-Pena,R.J., Vazquez-Juarez,R., Rivera-Bustamante,R.F. |
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
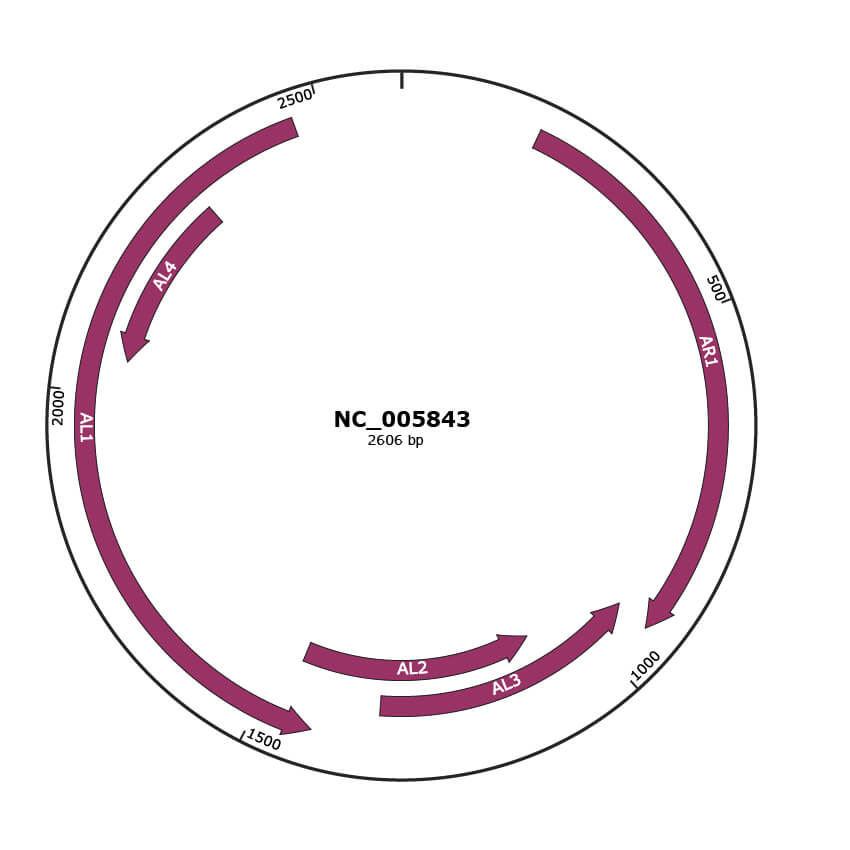
JBrowse
Genome
ACCGGATGGCCGCGCCTTTTTTGACCCGGCCCATCTTCGGAAATTTCGTAGAAATTTCATAGATAAAATTAGCCAATCAGTGCACGCGTGTGCGGTCTAATTATTAATAACTTGGCGACTAAGTCGTTTTCTGGTCTATAAATTTGTCGTTATGTGTGTGGTCCAGATATACATATTTTGAAAATGCCTAAGCGGGATGCCCCATGGCGTTTAATGTCGGGTACTCCTAAGGTTAGTCGCTCCTCTAATTATGTCCCTCCTGATGGATTGGGCCGTAAATTTGATAAATCATCTGCTTGGGCCAACAGGCCCATGTACAGAAAGCCCAGGATATATCGGACCGTAAGGTCTGCCGATGTTCCTCGAGGCTGTGAAGGGCCTTGCAAGATTCAGTCGTTTGAGCAGCGTCACGATATATCTCATACTGGAAAGGTGATGTGTATCTCCGATGTTACTCGCGGTAATGGCATTACCCATCGGGTTGGTAAACGTTTCTGCGTGAAGTCCGTGTATATATTAGGGAAGATCTGGATGGACGATAACATCAAGCTCAAGAACCACACTAACAGCGTTATGTTCTGGTTAGTTAGGGATAGGAGGCCCAGCGGAACGGCTATGGATTTTGGTCACCTCTTCAACATGTTTGACAATGAGCCTAGTACTGCCACTGTGAAGAACGATCTTAGAGATCGTTTCCAAGTGCTGCACAGGTTTCATGCGAAGGTGACTGGTGGTCAGTATGCAAGCAATGAGCAGACGTTGGTGAAGCGTTTTCGGCGGGTGAATCAGCGTGTAACATATAATAATCAGGAGGCAGCTCGGTATGAAAACCATACGGAGAACGCCTTAATGTTGTACATGGCATGTACTCATGCCTCTAACCCTGTGTATGCTACTCTTAAGATCCGGATCTATTTTTATGATTCGGTGTTAAATTAATAAATTTTGAATTTTATTGAATAATTCTCAAGTACATGATTTACATACCATCTGTCTGTTGCGAAGCGAACAGCTCTAATTACATTATTAATGCAAATAACGCCTAATCTATCTAAATACAATAAGACTAAATATTTAAATCTACTTAAGTAAGTCGTCCCAGAAGCTCGAACTGATGTCGTCCAGATTTGGTAGTTGAGGTACGCTTTGTGTAGACTCAACGCCTTCCTGAGGTTGTGGTTGAACCTTATTTGGATGTGGTAAATCCTGCTGTTGGTGTAAATTGGGTCCTCTGTTTTGATTATCGTGAAATAGAGGGGATTTGGTACCTCCCAGATAAAAACGGAATTCTCTGCCTGTTCCACAGTGATGCTCTCCCCGGTGCGTGAATCCATTGTTGGCGCAGTCGATGTGTTGGTAGAATGAGCAGCCACAGTTTAGGTCTATTCTCTTGCGACGAATCCTGGACTTTGCAATCTTGTGCTTAGGCTTGATAGAGGGTGGAGTTGAGGAAGATGAATTTTGCATTGTGGAGGGTCCAAGCTTTTAGTGCTGCATTTTCCTCTTTTTCAAGGGAACATTTATAGCTGGCTCCCTCTCCTGGATTGCAGAGCACGATTGATGGTATCCCACCTTTAATTTGAACTGGCTTCCCGTATTTGCAGTTGGACTGCCAGTCCTTTTGGGCCCCAATCAGCTCTTTCCAATGTTTCATCTTTAAATATTGCGGAGTGACGTCATCAATGACGTTGTACTCCACATCATTTGAGTAAACCCTAGGATTGAAATCCAAGTGTCCACTCAAATAATTATGTGGTCCTAAAGCACGAGCCCACATCGTCTTTCCTGTCCTCGAATCACCCTCGATGATTATACTAATAGGTCTCTCCGGCCGCGCAGCGGCACCCCTACCAAAATAATCATCAGCCCACTCTTGCATCTCGTCCGGAACGTTCGTGAAGGAGGAGAGTGGAAACGGAGGAACCCATGGTTCCGGAGCCTTAGCGAATATCCTGTCTAAGTTACTAGACAGGTTGTGATATTGAAAAAGAAACTCTTTGGGGAGCTTCTCTTTAATAATTCGCATGGCTTCTTCTTTCGAGGACGCATTTAGGGCCTCTGCGGCAGCGTCGTTAGCTGTTTGCTGACCTCCTCTAGCAGATCTTCCGTCGATCTGGAATTCTCCCCATTCCAATGTATCTCCATCCTTGTCGATGTAGGACTTGACGTCGGAGCTTGATTTAGCTCCCTGAATGTTCGGATGGAAATGTGCTGACCTGGTTGGGGATACCAGGTCGAACTGTCTTTGATTCGTGATTTGGATTTTCCCTTCGAACTGCATAAGCACGTGGAGATGATGTTCCCCATTTTCGTGCAGTTCTCTGCAGATCTTGATGTATTTTTTGTTAGAAGGAAGTTGTATGGACAGTAGTTGATCTAGGGCTTCTTCTTTTGTAAGAGGACATTGGGGGTATGTTAGGAAGATATTTTTTGCTTGAAGGCGAAAACGTTTAGGTGGTGGCATTTTTGTAATTAATAGATGTACTCCGATTGCCTCTTCTTACAAAAGTCTATATGAATTGGAGTATTGGAGTACAATATATACTAGAAGGTCCTATAGAACTTTCAATCGTATCCGCTCACGTGGCGGCCATCCGTTTAATATT
Gene Information
|
NCBI Accession
|
YP_006428.1
|
|
Location
|
184-939 |
|
Gene Name
|
AR1 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGCCTAAGCGGGATGCCCCATGGCGTTTAATGTCGGGTACTCCTAAGGTTAGTCGCTCCTCTAATTATGTCCCTCCTGATGGATTGGGCCGTAAATTTGATAAATCATCTGCTTGGGCCAACAGGCCCATGTACAGAAAGCCCAGGATATATCGGACCGTAAGGTCTGCCGATGTTCCTCGAGGCTGTGAAGGGCCTTGCAAGATTCAGTCGTTTGAGCAGCGTCACGATATATCTCATACTGGAAAGGTGATGTGTATCTCCGATGTTACTCGCGGTAATGGCATTACCCATCGGGTTGGTAAACGTTTCTGCGTGAAGTCCGTGTATATATTAGGGAAGATCTGGATGGACGATAACATCAAGCTCAAGAACCACACTAACAGCGTTATGTTCTGGTTAGTTAGGGATAGGAGGCCCAGCGGAACGGCTATGGATTTTGGTCACCTCTTCAACATGTTTGACAATGAGCCTAGTACTGCCACTGTGAAGAACGATCTTAGAGATCGTTTCCAAGTGCTGCACAGGTTTCATGCGAAGGTGACTGGTGGTCAGTATGCAAGCAATGAGCAGACGTTGGTGAAGCGTTTTCGGCGGGTGAATCAGCGTGTAACATATAATAATCAGGAGGCAGCTCGGTATGAAAACCATACGGAGAACGCCTTAATGTTGTACATGGCATGTACTCATGCCTCTAACCCTGTGTATGCTACTCTTAAGATCCGGATCTATTTTTATGATTCGGTGTTAAATTAA |
|
Protein Sequence
|
MPKRDAPWRLMSGTPKVSRSSNYVPPDGLGRKFDKSSAWANRPMYRKPRIYRTVRSADVPRGCEGPCKIQSFEQRHDISHTGKVMCISDVTRGNGITHRVGKRFCVKSVYILGKIWMDDNIKLKNHTNSVMFWLVRDRRPSGTAMDFGHLFNMFDNEPSTATVKNDLRDRFQVLHRFHAKVTGGQYASNEQTLVKRFRRVNQRVTYNNQEAARYENHTENALMLYMACTHASNPVYATLKIRIYFYDSVLN |
|
NCBI Accession
|
YP_006429.1
|
|
Location
|
936-1334 |
|
Gene Name
|
AL3 |
|
Protein Name
|
replication enhancer protein |
|
Coding Region
|
ATGGATTCACGCACCGGGGAGAGCATCACTGTGGAACAGGCAGAGAATTCCGTTTTTATCTGGGAGGTACCAAATCCCCTCTATTTCACGATAATCAAAACAGAGGACCCAATTTACACCAACAGCAGGATTTACCACATCCAAATAAGGTTCAACCACAACCTCAGGAAGGCGTTGAGTCTACACAAAGCGTACCTCAACTACCAAATCTGGACGACATCAGTTCGAGCTTCTGGGACGACTTACTTAAGTAGATTTAAATATTTAGTCTTATTGTATTTAGATAGATTAGGCGTTATTTGCATTAATAATGTAATTAGAGCTGTTCGCTTCGCAACAGACAGATGGTATGTAAATCATGTACTTGAGAATTATTCAATAAAATTCAAAATTTATTAA |
|
Protein Sequence
|
MDSRTGESITVEQAENSVFIWEVPNPLYFTIIKTEDPIYTNSRIYHIQIRFNHNLRKALSLHKAYLNYQIWTTSVRASGTTYLSRFKYLVLLYLDRLGVICINNVIRAVRFATDRWYVNHVLENYSIKFKIY |
|
NCBI Accession
|
YP_006430.1
|
|
Location
|
1081-1467 |
|
Gene Name
|
AL2 |
|
Protein Name
|
transcription activator protein |
|
Coding Region
|
ATGCAAAATTCATCTTCCTCAACTCCACCCTCTATCAAGCCTAAGCACAAGATTGCAAAGTCCAGGATTCGTCGCAAGAGAATAGACCTAAACTGTGGCTGCTCATTCTACCAACACATCGACTGCGCCAACAATGGATTCACGCACCGGGGAGAGCATCACTGTGGAACAGGCAGAGAATTCCGTTTTTATCTGGGAGGTACCAAATCCCCTCTATTTCACGATAATCAAAACAGAGGACCCAATTTACACCAACAGCAGGATTTACCACATCCAAATAAGGTTCAACCACAACCTCAGGAAGGCGTTGAGTCTACACAAAGCGTACCTCAACTACCAAATCTGGACGACATCAGTTCGAGCTTCTGGGACGACTTACTTAAGTAG |
|
Protein Sequence
|
MQNSSSSTPPSIKPKHKIAKSRIRRKRIDLNCGCSFYQHIDCANNGFTHRGEHHCGTGREFRFYLGGTKSPLFHDNQNRGPNLHQQQDLPHPNKVQPQPQEGVESTQSVPQLPNLDDISSSFWDDLLK |
|
NCBI Accession
|
YP_006431.1
|
|
Location
|
1424-2464 |
|
Gene Name
|
AL1 |
|
Protein Name
|
replication protein |
|
Coding Region
|
ATGCCACCACCTAAACGTTTTCGCCTTCAAGCAAAAAATATCTTCCTAACATACCCCCAATGTCCTCTTACAAAAGAAGAAGCCCTAGATCAACTACTGTCCATACAACTTCCTTCTAACAAAAAATACATCAAGATCTGCAGAGAACTGCACGAAAATGGGGAACATCATCTCCACGTGCTTATGCAGTTCGAAGGGAAAATCCAAATCACGAATCAAAGACAGTTCGACCTGGTATCCCCAACCAGGTCAGCACATTTCCATCCGAACATTCAGGGAGCTAAATCAAGCTCCGACGTCAAGTCCTACATCGACAAGGATGGAGATACATTGGAATGGGGAGAATTCCAGATCGACGGAAGATCTGCTAGAGGAGGTCAGCAAACAGCTAACGACGCTGCCGCAGAGGCCCTAAATGCGTCCTCGAAAGAAGAAGCCATGCGAATTATTAAAGAGAAGCTCCCCAAAGAGTTTCTTTTTCAATATCACAACCTGTCTAGTAACTTAGACAGGATATTCGCTAAGGCTCCGGAACCATGGGTTCCTCCGTTTCCACTCTCCTCCTTCACGAACGTTCCGGACGAGATGCAAGAGTGGGCTGATGATTATTTTGGTAGGGGTGCCGCTGCGCGGCCGGAGAGACCTATTAGTATAATCATCGAGGGTGATTCGAGGACAGGAAAGACGATGTGGGCTCGTGCTTTAGGACCACATAATTATTTGAGTGGACACTTGGATTTCAATCCTAGGGTTTACTCAAATGATGTGGAGTACAACGTCATTGATGACGTCACTCCGCAATATTTAAAGATGAAACATTGGAAAGAGCTGATTGGGGCCCAAAAGGACTGGCAGTCCAACTGCAAATACGGGAAGCCAGTTCAAATTAAAGGTGGGATACCATCAATCGTGCTCTGCAATCCAGGAGAGGGAGCCAGCTATAAATGTTCCCTTGAAAAAGAGGAAAATGCAGCACTAAAAGCTTGGACCCTCCACAATGCAAAATTCATCTTCCTCAACTCCACCCTCTATCAAGCCTAA |
|
Protein Sequence
|
MPPPKRFRLQAKNIFLTYPQCPLTKEEALDQLLSIQLPSNKKYIKICRELHENGEHHLHVLMQFEGKIQITNQRQFDLVSPTRSAHFHPNIQGAKSSSDVKSYIDKDGDTLEWGEFQIDGRSARGGQQTANDAAAEALNASSKEEAMRIIKEKLPKEFLFQYHNLSSNLDRIFAKAPEPWVPPFPLSSFTNVPDEMQEWADDYFGRGAAARPERPISIIIEGDSRTGKTMWARALGPHNYLSGHLDFNPRVYSNDVEYNVIDDVTPQYLKMKHWKELIGAQKDWQSNCKYGKPVQIKGGIPSIVLCNPGEGASYKCSLEKEENAALKAWTLHNAKFIFLNSTLYQA |
|
NCBI Accession
|
YP_006432.1
|
|
Location
|
2050-2307 |
|
Gene Name
|
AL4 |
|
Protein Name
|
AL4 protein |
|
Coding Region
|
ATGGGGAACATCATCTCCACGTGCTTATGCAGTTCGAAGGGAAAATCCAAATCACGAATCAAAGACAGTTCGACCTGGTATCCCCAACCAGGTCAGCACATTTCCATCCGAACATTCAGGGAGCTAAATCAAGCTCCGACGTCAAGTCCTACATCGACAAGGATGGAGATACATTGGAATGGGGAGAATTCCAGATCGACGGAAGATCTGCTAGAGGAGGTCAGCAAACAGCTAACGACGCTGCCGCAGAGGCCCTAA |
|
Protein Sequence
|
MGNIISTCLCSSKGKSKSRIKDSSTWYPQPGQHISIRTFRELNQAPTSSPTSTRMEIHWNGENSRSTEDLLEEVSKQLTTLPQRP |