Tomato bright yellow mottle virus
Basic Information
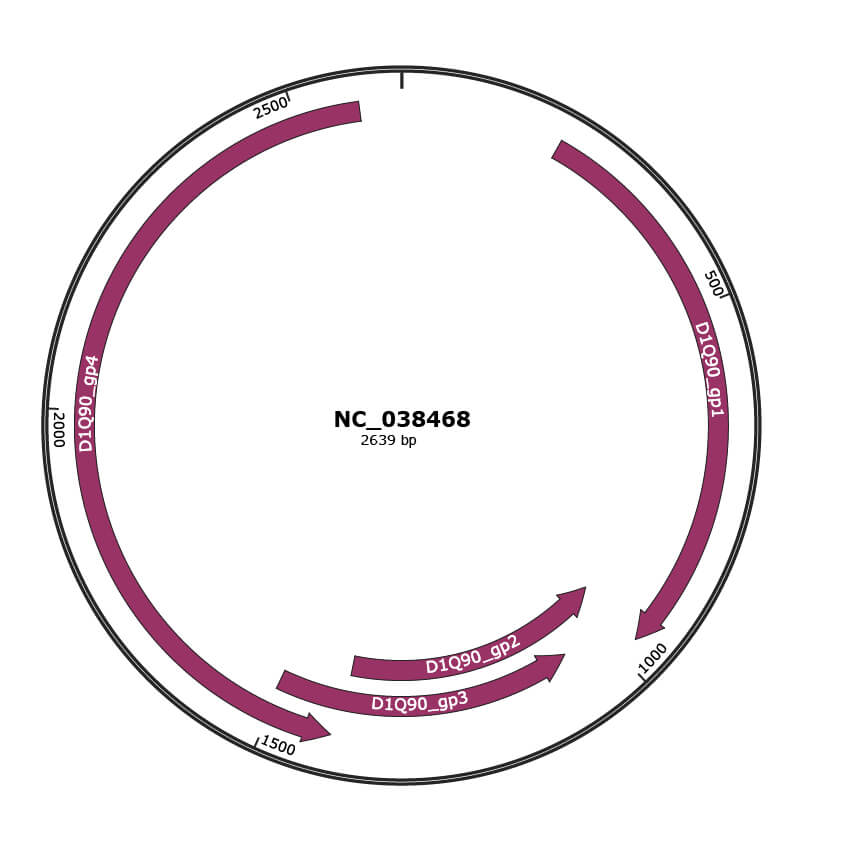
Genomic Organization
JBrowse
Genome
ACCGGGGATGGCCGCGCAATTTTTTTATGCCCCCGACCCGCTCCCGCAATTGCGCCGCACTGTCGGCCATTATTGGTGGTCCCTTTCGGATAAAGACAAATTTGACTGACCAATGAAATTCGGGCCTGGATGCCAATTTATTTTGAAATACTTGGGCGCTAAGTTGCTATAAAAAAGGCCCATTATTCCAAGGCCCAACAGGCATTAATTCGAAAATGCCGAAGCGGTATCCCCCATTCCGGACAACGGCGGGAATTTCCAAGATTTCCCGCTCTTCGAATATGTCTCCTCGTGGAGGTATCCGGCCCAAATTCGACAAGGCCGCTGAGTGGGTTAACAGGCCCATGTACAGGAAGCCCAGGATCTACCGCACGTTGCGAAGCCCAGACATCCCGAGGGGTTGTGAAGGCCCTTGCAAGGTCCAATCGTTTGAGCAGCGTCATGACGTTTCGCACGTGGGGAAGGTGTTGTGTATTTCTGATGTGACACGGGGTAATGGTATTACTCACCGTGTCGGTAAACGTTTTTGTGTTAAGTCCGTCTATATACTAGGGAAGGTTTGGATGGACGATAATATTAAGCTGAAGAACCATACGAATAGCGTATTGTTCTGGTTAGTTAGGGATAGGAGGCCGTATGGTACCCCTATGGACTTCGGCCAGGTTTTTAATATGTATGATAACGAGCCCAGTACTGCCACCGTGAAGAACGATCTCCGGGATCGTATCCAAGTTATGCACAGGTTCTCCGCGAAGGTGACAGGTGGACAGTACGCCAGCAACGAGCAGGCCGTGGTGCGACGTTTCTGGAAGGTGTACAACCACGTTGTGTACAACCACCAAGAGGCCGCGAAGTACGAAATCCACACGGAGAACGCCCTGTTATTGTACATGGCATGTACTCATGCCTCTAACCCTGTATATGCCACCCTCAAGATTCGGATCTATTTTTACGATTCGATCTTAAATTAATAAATGTTGAATTTTATTGAATGATCCTCGAGTACATGAGTTAACATACGTCCTGTCTGTTGCGAATTGAACAGATCGAATAACATAACTAAATTGAAATAACYCCAAATTTAAGAAAGTACATATTGACCAAGAATAAAAATAAATAAAAATATGTCGTCCCAGAAGCCGTAAGGGAAGTCGTCCAGACTTGGAAGTTGAGGTACGCCTTGTGGAGATCCAACGCTCTCCTGAGGTTGTGGTTGAACCGTATCTGGATGTGGTACACCGTCGTGTTGGCGTGGAGTAAAATCTCCACGTTGGTGATCTTGAAATATAGGGGATTTTGCACCTCCCAGGTATACACGCCATTCTCCGCTTGACGTCGCGTGATGCGTTCCCCTGTGCGTGAATCCATGTCCTCTGCAGTGAATGTGCAGGTAGATTGAGCATCCCGCACTAAACTAAAATTCGTCGTCTCCTGATTGCCCTCTTCTTCTTGGCAATTCTGTGCTGTGGTTTGATAGAGGGGGGAGTTGAGAAAGACGAATTTCATTGTGGAGTGTCCAGTTCTTGAGTGACAAATTCTCCTCTTTGTCGAGGAACTCTTTATAACTGGCACCCTCTCCTGGATTGCAAAGCACGATTGAGGGTATCCCACCTTTAATTTGAACCGGCTTTCCGTATTTACAATTTGACTGCCAGTCCCTTTGGGCCCCAATCAATTCTTTCCAGTGCTTCATCTTTAAGTAGTGCGGAGGGACGTCATCAATGACGTTATAATCAACTTCATTTGAATAAACCCTAGCATTGAAATCCAGGTGTCCACTCAAATAATTGTGGGACCCCAAAGCACGTGCCCACATCGTCTTGCCCGTTCTTGAATCACCCTCCACGATGATGGATACCGGTCTGAGACTATTATGAAAATCTGGCCGCGCAGCGGAAAGACGACCAAAATAATCATCCGCCCACTCTTGCATCTCGTCCGGAACGTTAGTGAAAGAGGAGAGTGGAAACGGAGGAGTCCAAGGCTCCGGAGATTTGGCGAATATCTTTTGAATATTCGCATTGATGTTATGATGTTGAACGATGAACGCCTTGGGATCTCCTGCCCGGATAATTGCAAGAGCCTCTGATGCAGATGTGGCATTGATTGCGTTGTGATAGACGTCGTCTTTATTTGTCTTAGTTCCGCCAGAAATTCTGTATTGTCCGGATTCACAATAATCACCCTCTCTGGTGATGTAATTCTTGACGGCGTTGGCGTCTTTGGCTGCCTGGATGTTTGGGTGAAAATTGGCAGACCGTCTTGGGTGAGTAAGGTCGAAAAATCTAGCATCCTTGATGTTGACTTTCCGGATATTGTATGAGACAGGGGAGGTGAGGATGCCCATCTGGTGTTCCTCTCTGGCGACCCCGATGTATGTGGGTTTGACGACTGTCCCAGTGAGGAGTTGAAGCATTTGAAGCACCTCATGTTTTTCTATATCGCACTGCGGGTACGTGAGGAAGATATTCCTTGCCTGCAGCCTAAATGTATTAGGTTGTCGTGGCATTTTTGTAAATATGTGCCAGGACTCCAGGGAGCTCTCCCAACTTCTGTGATATTTGCTGGAGTCCTGGAGTCCCATTTATACTAAAAGCCTCTTGGGACTCCAAGGGCAAAAGCGGCCATCCTATAATATT
Gene Information
|
NCBI Accession
|
YP_009506517.1
|
|
Location
|
216-971 |
|
Protein Name
|
capsid protein |
|
Coding Region
|
ATGCCGAAGCGGTATCCCCCATTCCGGACAACGGCGGGAATTTCCAAGATTTCCCGCTCTTCGAATATGTCTCCTCGTGGAGGTATCCGGCCCAAATTCGACAAGGCCGCTGAGTGGGTTAACAGGCCCATGTACAGGAAGCCCAGGATCTACCGCACGTTGCGAAGCCCAGACATCCCGAGGGGTTGTGAAGGCCCTTGCAAGGTCCAATCGTTTGAGCAGCGTCATGACGTTTCGCACGTGGGGAAGGTGTTGTGTATTTCTGATGTGACACGGGGTAATGGTATTACTCACCGTGTCGGTAAACGTTTTTGTGTTAAGTCCGTCTATATACTAGGGAAGGTTTGGATGGACGATAATATTAAGCTGAAGAACCATACGAATAGCGTATTGTTCTGGTTAGTTAGGGATAGGAGGCCGTATGGTACCCCTATGGACTTCGGCCAGGTTTTTAATATGTATGATAACGAGCCCAGTACTGCCACCGTGAAGAACGATCTCCGGGATCGTATCCAAGTTATGCACAGGTTCTCCGCGAAGGTGACAGGTGGACAGTACGCCAGCAACGAGCAGGCCGTGGTGCGACGTTTCTGGAAGGTGTACAACCACGTTGTGTACAACCACCAAGAGGCCGCGAAGTACGAAATCCACACGGAGAACGCCCTGTTATTGTACATGGCATGTACTCATGCCTCTAACCCTGTATATGCCACCCTCAAGATTCGGATCTATTTTTACGATTCGATCTTAAATTAA |
|
Protein Sequence
|
MPKRYPPFRTTAGISKISRSSNMSPRGGIRPKFDKAAEWVNRPMYRKPRIYRTLRSPDIPRGCEGPCKVQSFEQRHDVSHVGKVLCISDVTRGNGITHRVGKRFCVKSVYILGKVWMDDNIKLKNHTNSVLFWLVRDRRPYGTPMDFGQVFNMYDNEPSTATVKNDLRDRIQVMHRFSAKVTGGQYASNEQAVVRRFWKVYNHVVYNHQEAAKYEIHTENALLLYMACTHASNPVYATLKIRIYFYDSILN |
|
NCBI Accession
|
YP_009506518.1
|
|
Location
|
963-1403 |
|
Protein Name
|
AL3 |
|
Coding Region
|
ATGCTCAATCTACCTGCACATTCACTGCAGAGGACATGGATTCACGCACAGGGGAACGCATCACGCGACGTCAAGCGGAGAATGGCGTGTATACCTGGGAGGTGCAAAATCCCCTATATTTCAAGATCACCAACGTGGAGATTTTACTCCACGCCAACACGACGGTGTACCACATCCAGATACGGTTCAACCACAACCTCAGGAGAGCGTTGGATCTCCACAAGGCGTACCTCAACTTCCAAGTCTGGACGACTTCCCTTACGGCTTCTGGGACGACATATTTTTATTTATTTTTATTCTTGGTCAATATGTACTTTCTTAAATTTGGRGTTATTTCAATTTAGTTATGTTATTCGATCTGTTCAATTCGCAACAGACAGGACGTATGTTAACTCATGTACTCGAGGATCATTCAATAAAATTCAACATTTATTAATTTAA |
|
Protein Sequence
|
MLNLPAHSLQRTWIHAQGNASRDVKRRMACIPGRCKIPYISRSPTWRFYSTPTRRCTTSRYGSTTTSGERWISTRRTSTSKSGRLPLRLLGRHIFIYFYSWSICTFLNLXLFQFSYVIRSVQFATDRTYVNSCTRGSFNKIQHLLI |
|
NCBI Accession
|
YP_009506519.1
|
|
Location
|
1060-1506 |
|
Protein Name
|
AL2 |
|
Coding Region
|
ATGAAATTCGTCTTTCTCAACTCCCCCCTCTATCAAACCACAGCACAGAATTGCCAAGAAGAAGAGGGCAATCAGGAGACGACGAATTTTAGTTTAGTGCGGGATGCTCAATCTACCTGCACATTCACTGCAGAGGACATGGATTCACGCACAGGGGAACGCATCACGCGACGTCAAGCGGAGAATGGCGTGTATACCTGGGAGGTGCAAAATCCCCTATATTTCAAGATCACCAACGTGGAGATTTTACTCCACGCCAACACGACGGTGTACCACATCCAGATACGGTTCAACCACAACCTCAGGAGAGCGTTGGATCTCCACAAGGCGTACCTCAACTTCCAAGTCTGGACGACTTCCCTTACGGCTTCTGGGACGACATATTTTTATTTATTTTTATTCTTGGTCAATATGTACTTTCTTAAATTTGGRGTTATTTCAATTTAG |
|
Protein Sequence
|
MKFVFLNSPLYQTTAQNCQEEEGNQETTNFSLVRDAQSTCTFTAEDMDSRTGERITRRQAENGVYTWEVQNPLYFKITNVEILLHANTTVYHIQIRFNHNLRRALDLHKAYLNFQVWTTSLTASGTTYFYLFLFLVNMYFLKFGVISI |
|
NCBI Accession
|
YP_009506520.1
|
|
Location
|
1415-2584 |
|
Protein Name
|
AL1 |
|
Coding Region
|
ATGGGACTCCAGGACTCCAGCAAATATCACAGAAGTTGGGAGAGCTCCCTGGAGTCCTGGCACATATTTACAAAAATGCCACGACAACCTAATACATTTAGGCTGCAGGCAAGGAATATCTTCCTCACGTACCCGCAGTGCGATATAGAAAAACATGAGGTGCTTCAAATGCTTCAACTCCTCACTGGGACAGTCGTCAAACCCACATACATCGGGGTCGCCAGAGAGGAACACCAGATGGGCATCCTCACCTCCCCTGTCTCATACAATATCCGGAAAGTCAACATCAAGGATGCTAGATTTTTCGACCTTACTCACCCAAGACGGTCTGCCAATTTTCACCCAAACATCCAGGCAGCCAAAGACGCCAACGCCGTCAAGAATTACATCACCAGAGAGGGTGATTATTGTGAATCCGGACAATACAGAATTTCTGGCGGAACTAAGACAAATAAAGACGACGTCTATCACAACGCAATCAATGCCACATCTGCATCAGAGGCTCTTGCAATTATCCGGGCAGGAGATCCCAAGGCGTTCATCGTTCAACATCATAACATCAATGCGAATATTCAAAAGATATTCGCCAAATCTCCGGAGCCTTGGACTCCTCCGTTTCCACTCTCCTCTTTCACTAACGTTCCGGACGAGATGCAAGAGTGGGCGGATGATTATTTTGGTCGTCTTTCCGCTGCGCGGCCAGATTTTCATAATAGTCTCAGACCGGTATCCATCATCGTGGAGGGTGATTCAAGAACGGGCAAGACGATGTGGGCACGTGCTTTGGGGTCCCACAATTATTTGAGTGGACACCTGGATTTCAATGCTAGGGTTTATTCAAATGAAGTTGATTATAACGTCATTGATGACGTCCCTCCGCACTACTTAAAGATGAAGCACTGGAAAGAATTGATTGGGGCCCAAAGGGACTGGCAGTCAAATTGTAAATACGGAAAGCCGGTTCAAATTAAAGGTGGGATACCCTCAATCGTGCTTTGCAATCCAGGAGAGGGTGCCAGTTATAAAGAGTTCCTCGACAAAGAGGAGAATTTGTCACTCAAGAACTGGACACTCCACAATGAAATTCGTCTTTCTCAACTCCCCCCTCTATCAAACCACAGCACAGAATTGCCAAGAAGAAGAGGGCAATCAGGAGACGACGAATTTTAG |
|
Protein Sequence
|
MGLQDSSKYHRSWESSLESWHIFTKMPRQPNTFRLQARNIFLTYPQCDIEKHEVLQMLQLLTGTVVKPTYIGVAREEHQMGILTSPVSYNIRKVNIKDARFFDLTHPRRSANFHPNIQAAKDANAVKNYITREGDYCESGQYRISGGTKTNKDDVYHNAINATSASEALAIIRAGDPKAFIVQHHNINANIQKIFAKSPEPWTPPFPLSSFTNVPDEMQEWADDYFGRLSAARPDFHNSLRPVSIIVEGDSRTGKTMWARALGSHNYLSGHLDFNARVYSNEVDYNVIDDVPPHYLKMKHWKELIGAQRDWQSNCKYGKPVQIKGGIPSIVLCNPGEGASYKEFLDKEENLSLKNWTLHNEIRLSQLPPLSNHSTELPRRRGQSGDDEF |