Tobacco leaf curl Dominican Republic virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_013088355.1 |
| Isolate |
Dominican Republic |
| Release date |
2021/6/1 |
| Submitter |
Maliano,M.R., Macedo,M.A., Rojas,M.R., Gilbertson,R.L. |
| Host |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
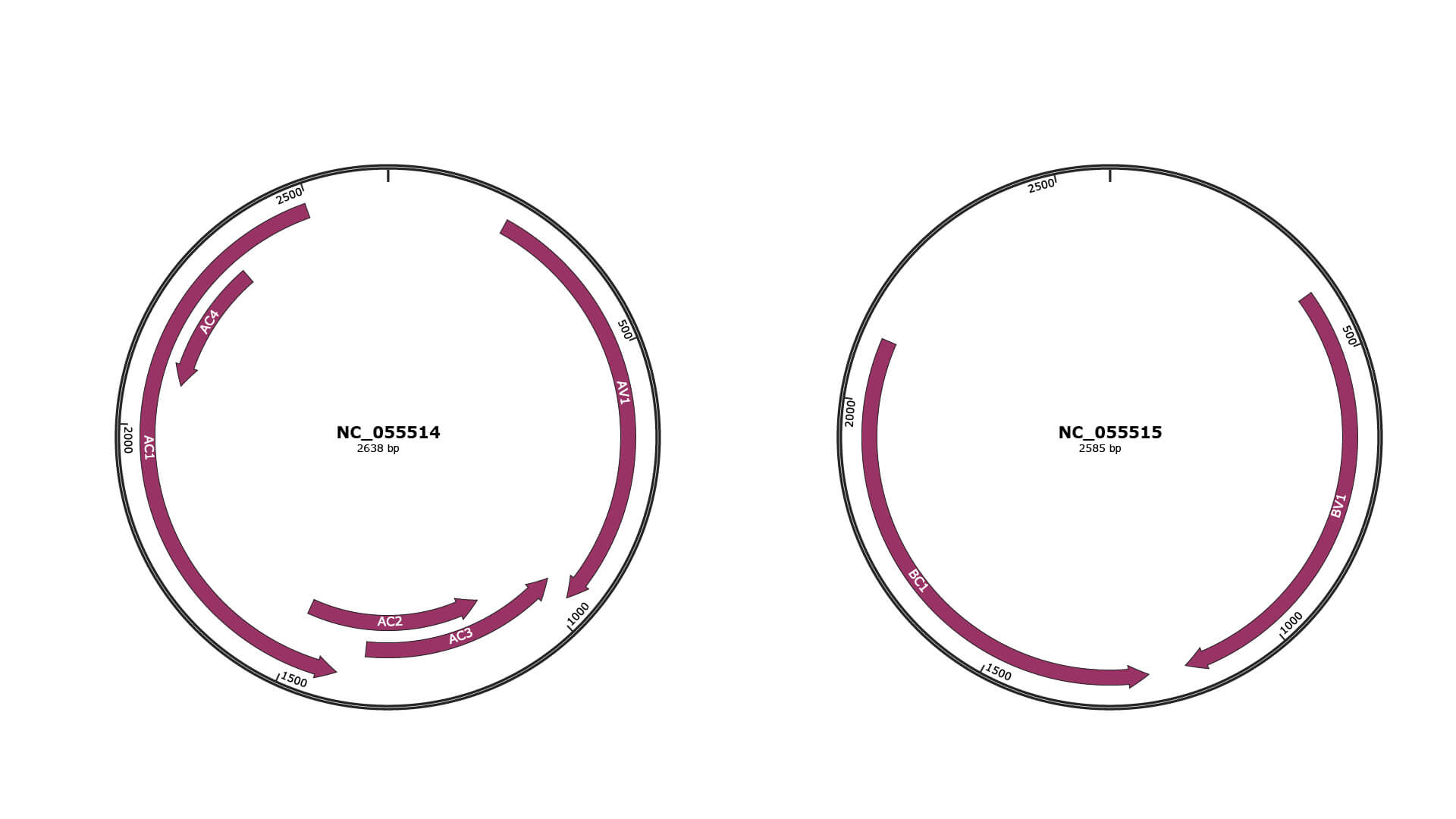
JBrowse
Genome
ACCGGATGGCCGCGCGCCCCCCCTGGTGCCGTACACTCTCACGCGCCCCCCCCTGGTGCCGTACACTCTCACGCGCCCAGATTTTTTTGACTCGCGCTTTTGACCAATCATATTGCGCCTGCCGCGCCTAGATATTTCAAACAACTTGGTCAGTAAGTTGTTGATCGGTCTATAAATGAAAAGCTGATTGGTCCCTTTTCTTTAACTCAAAATGCCTAAGCGGGATGCCCCATGGCGCTCAATGGCGGGAACATCAAAGGTCAGTCGCAATGCCAATTATTCACCCCGTTCAGGCATTGGCCCAAAATTCAACAAGGCCTCTGAGTGGGTTAACAGGCCTATGTACAGGAAGCCCAGGATATATCGGATGTTAAAGACCCCTGATGTTCCACGTGGATGTGAAGGCCCGTGTAAGGTCCAGTCCTATGAACAGCGTCACGACATCTCACACACGGGTAAGGTGATGTGTATCTCCGATGTTACACGTGGTAATGGAATCACCCACCGCGTGGGTAAGCGTTTTTGTGTTAAGTCTGTGTATATTTTAGGGAAGATTTGGATGGATGATAACATCAAGTTGAAGAACCACACGAACAGTGTTATGTTTTGGTTGGTCAGAGACCGTAGACCGTATGGAACGCCTATGGATTTCGGTCAGGTGTTCAATATGTTCGACAACGAGCCCAGTACTGCTACGGTTAAGAACGATCTACGTGATCGTTACCAGGTTATGCACCGGTTTTATGGCAAGGTCACAGGTGGACAGTATGCCAGCAACGAGCAGTCTATTGTGAGGCGATTCTGGAAGGTGAACAATTATGTGGTCTACAATCACCAAGAGGCTGGCAAGTATGACAATCATACGGAGAACGCTTTGTTATTGTACATGGCATGTACACATGCCTCTAACCCCGTGTATGCAACCTTGAAGATTCGAATCTATTTTTATGATTCGATTATGAATTAATAAAGTTTGAATTTTATTGAATGATTTTCCAATACATAGCTTACATAGGCTCTGTCCGTCGCGAACCGAACAGCTCTAATTACATTGTTAATGGAAACAACGCCCAATTGATCTAAATACAGATTAACTAAATGTCTAAACCTAATTAAATAAGTTGACCCAGAAGCTGTCATCGATGTCGTCCAGACTTGGAAGTTCAGGTACGCTTTGTGGAGATGCAACGCTCTCCTCAGGTTGTGGTTGAACCGTATCTGGATGTGGTATACCCTCGTTCTGGTGTATAGAAGGTCCTCTACGCTGTATATCCTGAAATACAGGGGATTTTCGATCTCCCAGATATATTCGCCATTCTCCGCCTGAGGTGCAGTGATGAGTTCCCCTGTGCGTGAATCCATGCCCCGTGCAGCCTATGTGGAAGTAGATGGAACACCCGCACTCTAGATCAATGCGTCTCCTCCTGATGGCCCTCCTCTTGGCTTGCCTGTGTGCCTTCTTGATAGAGGGGGGATGTGAGGGTGATGAAGATCGCATTCTTGATAGTCCAGTTCCTGAGCGATGTATTTTCCTCCTTGTCGAGGAATTCTTTATAGCTTGCACCCTCACCAGGATTGCAGAGCACGATTGATGGGATCCCCCCTTTAATTTGAACTGGCTTGCCGTACTTGCAATTTGATTGCCAGTCTTTTTGGGCCCCGATTAGCTCTTTCCAGTGCTTTAGCTTTAGATAGTGCGGTGCGACGTCATCAATGACGTTATACTCCACTTCGTTCGAAAAGACTTTGGAATTGAAGTCTAGGTGTCCACTTAAATAATTATGTGGGCCTAATGCCCGAGCCCACATTGTCTTCCCTGTCCTTGAATCACCTTCGACTATGAGACTTACTGGTCTCTCCGGCCGCGCAGCGGAACACCTTCCAAAATAATCGTCCGCCCACTCTTGCATCTCCTCCGGCACGTTAGTAAAAGAGGAGAGTTGAAACGGAGGAACCCATGGTTCCGGAGCCTTCATGAAAATCCTATCGAGATTTGCCCTTAGATTATGTTGTTGCAGAACATAATCCTTTGGTTGCTCCTCTTTTAGGATTTTAAGGGCCTCTGCAGCTGAGGAGGCATTCAATGCCTTGGCGTATGAGTCGTTAGATGTCTGGCAGCCTCCTCTAGCAGATCTACCGTCGACCTGAAATCCTCCCCATTCCAGTGTATCTCCGTCCTTCTCGACGTAGGACTTGACGTCGGAGCTTGATTTGGCTCCCTGAATGTTGGGATGGTAATGTACTGACCTGGTTGGTGAAACCAGGTCGAAGAATCTGCAATTCGTGCAGTTGAATTTCCCCTCGAACTGGAGAAGCACATGGAGGTGAGGTTCCCCATTGTCGTGAAGCTCTCTGGCGATTTTGATGTATTTTTTCTTGGATGGGGTTTGGAGTTTAAGTAATTGTTCTAGGGTTTCTTCTTTGGATAATAAACACTGGGGATATGTTATGAAATAATTTTTGGCTTTAATTGAGAAAGAACCCTTTCGTGGCATTCTTGTAAATAAGAGTGTTCCCCCGATTGGTCTGGCTTCAAAAACTCTATGCAATCGGGGGAACTGGGGGTACTTAAATATAAGAAGCCTCAATAGAACTTTCAATCTCGTTCACACACGTGGCGGCCATCCGTTATAATATT
ACCGGATGGCCGCGCGCCCCCCCTGGTGCCGTACACTCTCACGCGCCCCTCCCTGGTACTCTCCTCGCACGCGCTTCCCCATTGGTGTTTGTAAAACACGCTCCTTTTGTGTACCGCCCTTTAATTCAAATTAAAGGAAAAAGCTTCTGTCGCGCGAATTGTTTTACAATTTGAATTGTTGTCGCGCGACGATTGACTCTGACACATCGTACCCGATGATGGACGTGGCTAAATGAGGACCATGCTGCTGAGTCTATTTGCGATTATTGTTTAATCTATTACCTATATATTGGACTCGAAAGTTACATGTGTTTCATCAGACTCAGCAGTGTACGACGTATATATTGTTATTTACTAATTGTTTTGTTTATACATTATTATCATCGGATAATGTATCCTTTGAGGAACAGACGTGGATCCTACTTTACTCCACGTCGTTTTTATCGACGTAACACTGTTTTTAGGCGTCCAATTCCTTCCAGGAGACATGATGGGAAACGCCAACCTGTTAATTCCAGCAAGCCCAGTGATGAGCCCAAGATATCAGCCCAGCGGATACATGAGAATCAGTATGGGCCAGATTTTGTAATGGCCCATAATACAGCCATCTCGACCTTCATCAGTTATCCATGCTTGGGCAAGTCCGAACCCAACCGAAGCAGGTCCTACATCAAGTTGAAGCAGCTACGTTTCAAGGGAACCGTGAAGATTGAACGTGTTCAATCGGATCTGAACATGGACGGTTGTACCCCTAAAGTCGAAGGAGTCTTCTCCCTTGTCATTGTTGTGGATCGGAAACCCCACTTGGGTCCTTCTGGGTGTCTTCATACATTTGACGAGCTGTTCGGTGCTAGGATACACAGTCATGGTAACCTCAGCGTAACCCCTTCCTTGAAAGACCGTTACTACATTCGACACGTTTGCAAACGTGTACTGTCGGTGGAGAAAGACACGCTGATGGTAGACGTGGAAGGATCTATCTCCCTATCTAACAGGCGGTTCAACTGCTGGTCCACGTTTAAGGATCTTGATCGCGATTCATGCAAGGGTGTTTATGACAACATAAGCAAGAACGCCCTCTTAGTCTATTATTGTTGGATGTCCGATACCATGTCTAAGGCATCGACTTTTGTATCTTTTGATCTGGACTATGTTGGATGATCAATGAAATAAACATCTTTATTAGCCAAAGCTGATTATCTAATTTTGAAAGGAAAGTTAACATTTATTTTAACGACTTGGCTTGAGAAGCCTGACAATTATTATTAATACACTCTTGGACAGTTGTCCTGACTAGCTCATTCAACTGTCCCATTGACATTGTTATGTTGGATTCCGCTCTCTGGGCCCCCACGATCGAAGCAGACTCTCCTGGGTCTAGGACGCTGGTCCCCAGCCTATTCAGATGTCTGTATGGATGGAGTTCGTTCTCCACCTCTGAGTCCGCATCTGAGTGGCCCGTTCCTATTGTACTCCTGGAAGCCCATGATTCTCCAGGCCTTATCTCGATTGGGCCTCTCAGCCCAACCCTGGACATGGACGCGCATCTGATGGGCTTCCTTTCCCATTTCCCATAGTCGACGTGGGAGAAGTCCACATCCTTATCGGTGAACTGTTTGGACAGGATCTTGACTGTCGGTGCCCGGAATGGGATATCGACCGAGTGTTTCGCCGTCGATAGCTTCAGCTTCCCTTTGAACTTGGCGAAATGGGTCCTCTGATGAACATTCGTATCGCACACCCTGTAATAGAGCTTCCATGGAATTGGGTCCTTGAGCGAGAAGAATGAAGCCGAGAAATAGTGGAGATCTATGTTACATCTGATCGGAAATGTCCACGACGCTTGTAATGATTCGTTGTCAGTCATCCTCTTGTCGTGGATCTCCACAATTACCGACCCGGTGGCATTAATCGGCACTTGCTGTCTGTATTCTATGACGCAATGGTCTATCTTCATGCAGCTACGACTGAGTCTAGCTGTCAATTGCGACGCCGTCGAAGGAAATTGCAGTATTATCTCAGTTAGGTCATGGGAAAGCTGATACTCGTCCCGGTGAGACTCTATGTAGTTAAAGGCACTCGGAGGATTTACTAACTGAGAATCCATATGAATAAGATAGGCCGCGCAGCGGAATCGATTGCTGAAGTTGAATCGATGAAGAAGATGAATCAGGTGATGAAGAAGGTTAACAGAGATATATATTTTCTTTGCTTAAAAGAGTCCTAAGTATGTGACTATTGCGTTGGATAAGATGGAAGAAGGGGAAATTATTCAAGAATTATTGTGTTTTTGAGAAAGAAAAGAGAGTTGATGATGAATTTGAGATAGATATGAAAATGAAAGAGGGTGTATAGAAACCCAGGACTTCTGGGTTATGGGTATTTAAATAGGAAAAGTGTTTTTCGAGTTGAGAGAGGATTCATCTGTTAAGCGGTGGCGTTTTTGTAAATATGGGATGTTCCCCCGATTGGTCTGGCTTCAAAAACTCTATGCAATCGGGGGAACTGGGGGTACTTAAATATAAGAAGCCTCAATAGAACTTTCAATCTCGTTCACACACGTGGCGGCCATCCGTTATAATATT
Gene Information
|
NCBI Accession
|
YP_010087209.1
|
|
Location
|
212-967 |
|
Gene Name
|
AV1 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGCCTAAGCGGGATGCCCCATGGCGCTCAATGGCGGGAACATCAAAGGTCAGTCGCAATGCCAATTATTCACCCCGTTCAGGCATTGGCCCAAAATTCAACAAGGCCTCTGAGTGGGTTAACAGGCCTATGTACAGGAAGCCCAGGATATATCGGATGTTAAAGACCCCTGATGTTCCACGTGGATGTGAAGGCCCGTGTAAGGTCCAGTCCTATGAACAGCGTCACGACATCTCACACACGGGTAAGGTGATGTGTATCTCCGATGTTACACGTGGTAATGGAATCACCCACCGCGTGGGTAAGCGTTTTTGTGTTAAGTCTGTGTATATTTTAGGGAAGATTTGGATGGATGATAACATCAAGTTGAAGAACCACACGAACAGTGTTATGTTTTGGTTGGTCAGAGACCGTAGACCGTATGGAACGCCTATGGATTTCGGTCAGGTGTTCAATATGTTCGACAACGAGCCCAGTACTGCTACGGTTAAGAACGATCTACGTGATCGTTACCAGGTTATGCACCGGTTTTATGGCAAGGTCACAGGTGGACAGTATGCCAGCAACGAGCAGTCTATTGTGAGGCGATTCTGGAAGGTGAACAATTATGTGGTCTACAATCACCAAGAGGCTGGCAAGTATGACAATCATACGGAGAACGCTTTGTTATTGTACATGGCATGTACACATGCCTCTAACCCCGTGTATGCAACCTTGAAGATTCGAATCTATTTTTATGATTCGATTATGAATTAA |
|
Protein Sequence
|
MPKRDAPWRSMAGTSKVSRNANYSPRSGIGPKFNKASEWVNRPMYRKPRIYRMLKTPDVPRGCEGPCKVQSYEQRHDISHTGKVMCISDVTRGNGITHRVGKRFCVKSVYILGKIWMDDNIKLKNHTNSVMFWLVRDRRPYGTPMDFGQVFNMFDNEPSTATVKNDLRDRYQVMHRFYGKVTGGQYASNEQSIVRRFWKVNNYVVYNHQEAGKYDNHTENALLLYMACTHASNPVYATLKIRIYFYDSIMN |
|
NCBI Accession
|
YP_010087210.1
|
|
Location
|
964-1362 |
|
Gene Name
|
AC3 |
|
Protein Name
|
replication enhancer protein |
|
Coding Region
|
ATGGATTCACGCACAGGGGAACTCATCACTGCACCTCAGGCGGAGAATGGCGAATATATCTGGGAGATCGAAAATCCCCTGTATTTCAGGATATACAGCGTAGAGGACCTTCTATACACCAGAACGAGGGTATACCACATCCAGATACGGTTCAACCACAACCTGAGGAGAGCGTTGCATCTCCACAAAGCGTACCTGAACTTCCAAGTCTGGACGACATCGATGACAGCTTCTGGGTCAACTTATTTAATTAGGTTTAGACATTTAGTTAATCTGTATTTAGATCAATTGGGCGTTGTTTCCATTAACAATGTAATTAGAGCTGTTCGGTTCGCGACGGACAGAGCCTATGTAAGCTATGTATTGGAAAATCATTCAATAAAATTCAAACTTTATTAA |
|
Protein Sequence
|
MDSRTGELITAPQAENGEYIWEIENPLYFRIYSVEDLLYTRTRVYHIQIRFNHNLRRALHLHKAYLNFQVWTTSMTASGSTYLIRFRHLVNLYLDQLGVVSINNVIRAVRFATDRAYVSYVLENHSIKFKLY |
|
NCBI Accession
|
YP_010087211.1
|
|
Location
|
1109-1498 |
|
Gene Name
|
AC2 |
|
Protein Name
|
transactivator protein |
|
Coding Region
|
ATGCGATCTTCATCACCCTCACATCCCCCCTCTATCAAGAAGGCACACAGGCAAGCCAAGAGGAGGGCCATCAGGAGGAGACGCATTGATCTAGAGTGCGGGTGTTCCATCTACTTCCACATAGGCTGCACGGGGCATGGATTCACGCACAGGGGAACTCATCACTGCACCTCAGGCGGAGAATGGCGAATATATCTGGGAGATCGAAAATCCCCTGTATTTCAGGATATACAGCGTAGAGGACCTTCTATACACCAGAACGAGGGTATACCACATCCAGATACGGTTCAACCACAACCTGAGGAGAGCGTTGCATCTCCACAAAGCGTACCTGAACTTCCAAGTCTGGACGACATCGATGACAGCTTCTGGGTCAACTTATTTAATTAG |
|
Protein Sequence
|
MRSSSPSHPPSIKKAHRQAKRRAIRRRRIDLECGCSIYFHIGCTGHGFTHRGTHHCTSGGEWRIYLGDRKSPVFQDIQRRGPSIHQNEGIPHPDTVQPQPEESVASPQSVPELPSLDDIDDSFWVNLFN |
|
NCBI Accession
|
YP_010087212.1
|
|
Location
|
1410-2495 |
|
Gene Name
|
AC1 |
|
Protein Name
|
replication-associated protein |
|
Coding Region
|
ATGCCACGAAAGGGTTCTTTCTCAATTAAAGCCAAAAATTATTTCATAACATATCCCCAGTGTTTATTATCCAAAGAAGAAACCCTAGAACAATTACTTAAACTCCAAACCCCATCCAAGAAAAAATACATCAAAATCGCCAGAGAGCTTCACGACAATGGGGAACCTCACCTCCATGTGCTTCTCCAGTTCGAGGGGAAATTCAACTGCACGAATTGCAGATTCTTCGACCTGGTTTCACCAACCAGGTCAGTACATTACCATCCCAACATTCAGGGAGCCAAATCAAGCTCCGACGTCAAGTCCTACGTCGAGAAGGACGGAGATACACTGGAATGGGGAGGATTTCAGGTCGACGGTAGATCTGCTAGAGGAGGCTGCCAGACATCTAACGACTCATACGCCAAGGCATTGAATGCCTCCTCAGCTGCAGAGGCCCTTAAAATCCTAAAAGAGGAGCAACCAAAGGATTATGTTCTGCAACAACATAATCTAAGGGCAAATCTCGATAGGATTTTCATGAAGGCTCCGGAACCATGGGTTCCTCCGTTTCAACTCTCCTCTTTTACTAACGTGCCGGAGGAGATGCAAGAGTGGGCGGACGATTATTTTGGAAGGTGTTCCGCTGCGCGGCCGGAGAGACCAGTAAGTCTCATAGTCGAAGGTGATTCAAGGACAGGGAAGACAATGTGGGCTCGGGCATTAGGCCCACATAATTATTTAAGTGGACACCTAGACTTCAATTCCAAAGTCTTTTCGAACGAAGTGGAGTATAACGTCATTGATGACGTCGCACCGCACTATCTAAAGCTAAAGCACTGGAAAGAGCTAATCGGGGCCCAAAAAGACTGGCAATCAAATTGCAAGTACGGCAAGCCAGTTCAAATTAAAGGGGGGATCCCATCAATCGTGCTCTGCAATCCTGGTGAGGGTGCAAGCTATAAAGAATTCCTCGACAAGGAGGAAAATACATCGCTCAGGAACTGGACTATCAAGAATGCGATCTTCATCACCCTCACATCCCCCCTCTATCAAGAAGGCACACAGGCAAGCCAAGAGGAGGGCCATCAGGAGGAGACGCATTGA |
|
Protein Sequence
|
MPRKGSFSIKAKNYFITYPQCLLSKEETLEQLLKLQTPSKKKYIKIARELHDNGEPHLHVLLQFEGKFNCTNCRFFDLVSPTRSVHYHPNIQGAKSSSDVKSYVEKDGDTLEWGGFQVDGRSARGGCQTSNDSYAKALNASSAAEALKILKEEQPKDYVLQQHNLRANLDRIFMKAPEPWVPPFQLSSFTNVPEEMQEWADDYFGRCSAARPERPVSLIVEGDSRTGKTMWARALGPHNYLSGHLDFNSKVFSNEVEYNVIDDVAPHYLKLKHWKELIGAQKDWQSNCKYGKPVQIKGGIPSIVLCNPGEGASYKEFLDKEENTSLRNWTIKNAIFITLTSPLYQEGTQASQEEGHQEETH |
|
NCBI Accession
|
YP_010087213.1
|
|
Location
|
2081-2338 |
|
Gene Name
|
AC4 |
|
Protein Name
|
AC4 |
|
Coding Region
|
ATGGGGAACCTCACCTCCATGTGCTTCTCCAGTTCGAGGGGAAATTCAACTGCACGAATTGCAGATTCTTCGACCTGGTTTCACCAACCAGGTCAGTACATTACCATCCCAACATTCAGGGAGCCAAATCAAGCTCCGACGTCAAGTCCTACGTCGAGAAGGACGGAGATACACTGGAATGGGGAGGATTTCAGGTCGACGGTAGATCTGCTAGAGGAGGCTGCCAGACATCTAACGACTCATACGCCAAGGCATTGA |
|
Protein Sequence
|
MGNLTSMCFSSSRGNSTARIADSSTWFHQPGQYITIPTFREPNQAPTSSPTSRRTEIHWNGEDFRSTVDLLEEAARHLTTHTPRH |
|
NCBI Accession
|
YP_010087214.1
|
|
Location
|
391-1161 |
|
Gene Name
|
BV1 |
|
Protein Name
|
nuclear shuttle protein |
|
Coding Region
|
ATGTATCCTTTGAGGAACAGACGTGGATCCTACTTTACTCCACGTCGTTTTTATCGACGTAACACTGTTTTTAGGCGTCCAATTCCTTCCAGGAGACATGATGGGAAACGCCAACCTGTTAATTCCAGCAAGCCCAGTGATGAGCCCAAGATATCAGCCCAGCGGATACATGAGAATCAGTATGGGCCAGATTTTGTAATGGCCCATAATACAGCCATCTCGACCTTCATCAGTTATCCATGCTTGGGCAAGTCCGAACCCAACCGAAGCAGGTCCTACATCAAGTTGAAGCAGCTACGTTTCAAGGGAACCGTGAAGATTGAACGTGTTCAATCGGATCTGAACATGGACGGTTGTACCCCTAAAGTCGAAGGAGTCTTCTCCCTTGTCATTGTTGTGGATCGGAAACCCCACTTGGGTCCTTCTGGGTGTCTTCATACATTTGACGAGCTGTTCGGTGCTAGGATACACAGTCATGGTAACCTCAGCGTAACCCCTTCCTTGAAAGACCGTTACTACATTCGACACGTTTGCAAACGTGTACTGTCGGTGGAGAAAGACACGCTGATGGTAGACGTGGAAGGATCTATCTCCCTATCTAACAGGCGGTTCAACTGCTGGTCCACGTTTAAGGATCTTGATCGCGATTCATGCAAGGGTGTTTATGACAACATAAGCAAGAACGCCCTCTTAGTCTATTATTGTTGGATGTCCGATACCATGTCTAAGGCATCGACTTTTGTATCTTTTGATCTGGACTATGTTGGATGA |
|
Protein Sequence
|
MYPLRNRRGSYFTPRRFYRRNTVFRRPIPSRRHDGKRQPVNSSKPSDEPKISAQRIHENQYGPDFVMAHNTAISTFISYPCLGKSEPNRSRSYIKLKQLRFKGTVKIERVQSDLNMDGCTPKVEGVFSLVIVVDRKPHLGPSGCLHTFDELFGARIHSHGNLSVTPSLKDRYYIRHVCKRVLSVEKDTLMVDVEGSISLSNRRFNCWSTFKDLDRDSCKGVYDNISKNALLVYYCWMSDTMSKASTFVSFDLDYVG |
|
NCBI Accession
|
YP_010087215.1
|
|
Location
|
1226-2107 |
|
Gene Name
|
BC1 |
|
Protein Name
|
movement protein |
|
Coding Region
|
ATGGATTCTCAGTTAGTAAATCCTCCGAGTGCCTTTAACTACATAGAGTCTCACCGGGACGAGTATCAGCTTTCCCATGACCTAACTGAGATAATACTGCAATTTCCTTCGACGGCGTCGCAATTGACAGCTAGACTCAGTCGTAGCTGCATGAAGATAGACCATTGCGTCATAGAATACAGACAGCAAGTGCCGATTAATGCCACCGGGTCGGTAATTGTGGAGATCCACGACAAGAGGATGACTGACAACGAATCATTACAAGCGTCGTGGACATTTCCGATCAGATGTAACATAGATCTCCACTATTTCTCGGCTTCATTCTTCTCGCTCAAGGACCCAATTCCATGGAAGCTCTATTACAGGGTGTGCGATACGAATGTTCATCAGAGGACCCATTTCGCCAAGTTCAAAGGGAAGCTGAAGCTATCGACGGCGAAACACTCGGTCGATATCCCATTCCGGGCACCGACAGTCAAGATCCTGTCCAAACAGTTCACCGATAAGGATGTGGACTTCTCCCACGTCGACTATGGGAAATGGGAAAGGAAGCCCATCAGATGCGCGTCCATGTCCAGGGTTGGGCTGAGAGGCCCAATCGAGATAAGGCCTGGAGAATCATGGGCTTCCAGGAGTACAATAGGAACGGGCCACTCAGATGCGGACTCAGAGGTGGAGAACGAACTCCATCCATACAGACATCTGAATAGGCTGGGGACCAGCGTCCTAGACCCAGGAGAGTCTGCTTCGATCGTGGGGGCCCAGAGAGCGGAATCCAACATAACAATGTCAATGGGACAGTTGAATGAGCTAGTCAGGACAACTGTCCAAGAGTGTATTAATAATAATTGTCAGGCTTCTCAAGCCAAGTCGTTAAAATAA |
|
Protein Sequence
|
MDSQLVNPPSAFNYIESHRDEYQLSHDLTEIILQFPSTASQLTARLSRSCMKIDHCVIEYRQQVPINATGSVIVEIHDKRMTDNESLQASWTFPIRCNIDLHYFSASFFSLKDPIPWKLYYRVCDTNVHQRTHFAKFKGKLKLSTAKHSVDIPFRAPTVKILSKQFTDKDVDFSHVDYGKWERKPIRCASMSRVGLRGPIEIRPGESWASRSTIGTGHSDADSEVENELHPYRHLNRLGTSVLDPGESASIVGAQRAESNITMSMGQLNELVRTTVQECINNNCQASQAKSLK |