Tobacco leaf curl Cuba virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_002310935.1 |
| Isolate |
Cuba |
| Release date |
2017/9/21 |
| Submitter |
Chang-Sidorchuk,L., Gonzalez-Alvarez,H., Martinez-Zubiaur,Y., Navas-Castillo,J., Fiallo-Olive,E. |
| Host |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
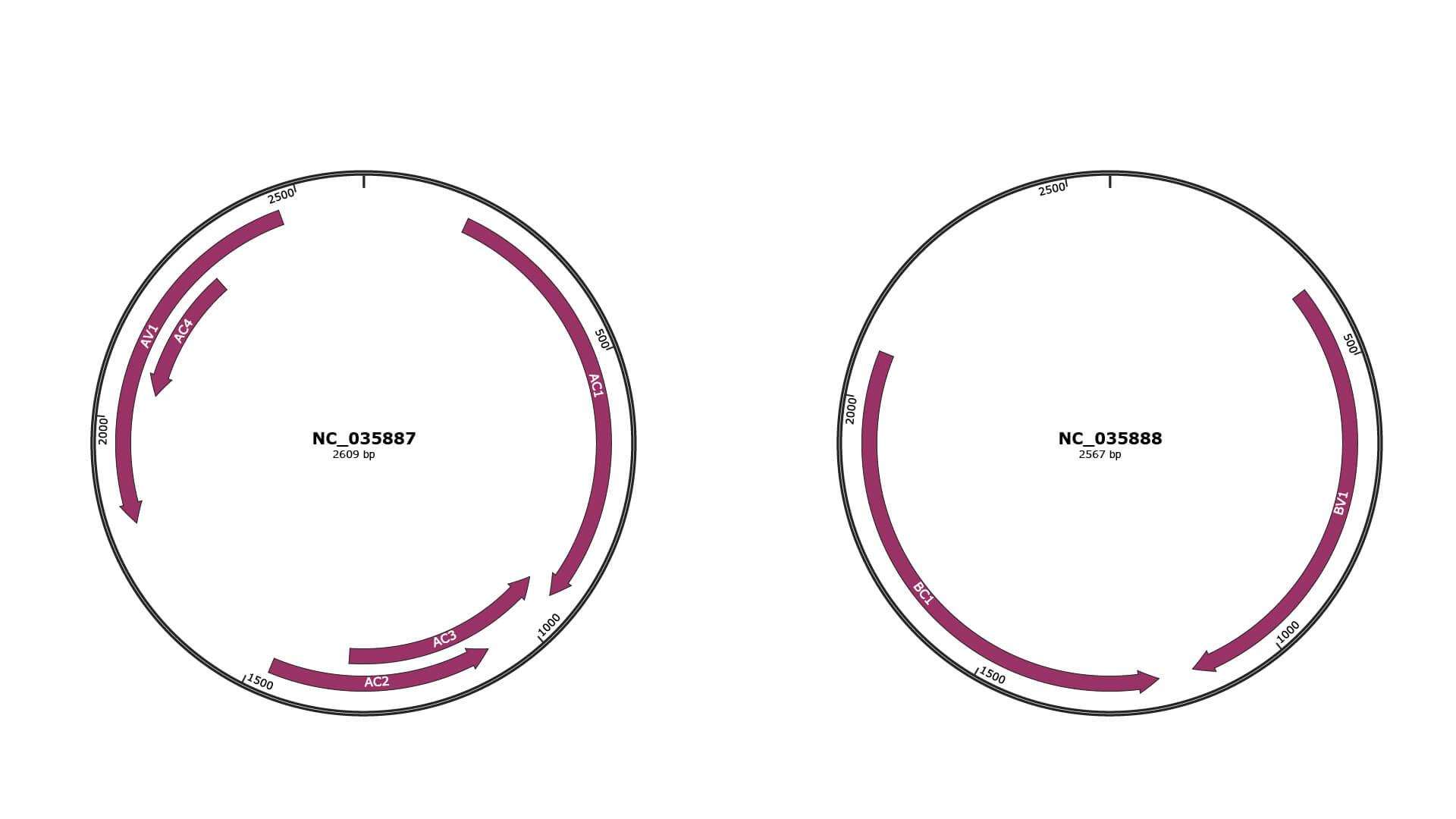
JBrowse
Genome
ACCGGATGGCCGCGCGCCCCCCCCTGGTGCCGTACACTCACGCGCGCCCCCCCTTTCTCACTCGCGTTATCGTCCAATCATATTGCGCCTACCGCGCCTATTTATTTCAAACAACTTGGGCTCCAAGTTGTTGCGCGGTTTATAAATTTTAAGTTGTTTGGGCCTGTATCTTCAGCCCAAGATGCCTAAGCGCGATGCCCCATGGCGCCCGATGGCAGGAACTTCGAAGGTAAGTCGCAATGCAAATTATTCTCCCCGTGCAGGTATTGGGCCAAGAATGAACAGGGCATCGGAATGGGTTAACAGGCCTATGTACAGGAAGCCCAGGATCTATCGGACGCTACGGACGCCCGACATTCCGAGAGGCTGTGAAGGCCCGTGCAAGGTCCAGTCCTATGAACAGCGCCACGATATCTCTCACGTGGGTAAGGTGATGTGTATATCTGATGTCACACGTGGTAATGGCATTACCCACCGTGTGGGTAAGCGTTTTTGTGTTAAGTCTGTGTACATACTAGGTAAGATATGGATGGATGAGAACATCAAGCTCAAGAACCACACGAACAGCGTTATGTTCTGGTTGGTCAGAGACCGTCGACCGTATGGGACGCCTATGGATTTTGGACAGGTGTTCAACATGTTCGACAACGAACCCAGCACTGCCACGGTTAAGAACGATCTACGTGATCGTTACCAGGTTATGCACCGGTTCTATGGTAAGGTCACAGGTGGACAGTATGCCAGCAACGAGCAGGCTATTGTCAGGCGATTCTGGAAGGTCAACAACTATGTCGTCTACAACCACCAGGAAGCTGCCAAGTACGAGAACCACACTGAGAACGCGCTGTTATTGTACATGGCATGTACACATGCCTCTAACCCCGTGTATGCAACTCTGAAGATTCGAATCTATTTTTATGATTCGATAATGAATTAATAAATTTTGAATTTTATTGAATGATTTTCCAGTACATAATTCACATACGATCTGTCCGTTGCAAAACGAACAGCTCTAATTACATTGTTAATGGAAATCACTCCTAACTGATCTAAATACATATTAACTAAATACGTAAACCTAACTAAATAAGTTGACCCAGAAGCTGTCATCGATGTCGTCCAGACTTGGAAGTTCAGGTAAGCTTTGTGGAGATGCAACGCTCTCCTCAGGTTGTGGTTGAACCGTATCTGGATGTGGTACACTCTTGTTCTGGTGTATAGCAGATCCTCTACTCTGTATATCTTGAAATATAGGGGATTTTCTATCTCCCAGATATACACGCCATTCTCCGCCTGATGTGCAGTGATGAGTTCCCCGGTGCGTAAATCCATGTCCCGTGCAGTCTATATGGAAGTATATGGAGCACCCGCACCTAAGATCAATGCGTCTCCTCCTGACTGCCCTCCTCTTGGCCTGCCTGTGTGCTATCTTGATAGAGGGAGGATGTGAGGGTGATGAAGACCGCATTCTTTAACGTCCAGTTTTTGAGAGATGTGTTTTCCTCTTTGTTGAGGAAATCTTTATAGCTGGCACCCTCACCAGGATTGCAAAGCACGATAGCTGGGATCCCACCTTTAATTTGAACTGGCTTGCCGTATTTGCAATTGGATTGCCAGTCTTTTTGTGCGCCCAAGAGCTCTTTCCAGTGCTTTAGCTTTAAATAGTGCGGTGCGACATCATCAATGACGTTATACTCCACTTCGTTTGAAAAGACACGAGCATTGAAGTCCAGGTGTCCACTGAGATAGTTATGTGGGCCTAACGCACGTGCCCACATTGTCTTCCCTGTCCTTGAATCACCTTCGACTATGAGACTTACTGGTCTTCCGGCCGCGCAGCGGAACCTCTTCCAAAATACTCATCGGCCCAGTCTTGCATCTCTTCAGGAACGTTAGTGAAAGAGGAGAGTTGAAACGGAGGGACCCATGGTTCCGGAGCCTTTTGAAAGATCCGATGAGCATTTGCTACCAAATTATGATGCTGAAGGAAAAAATGTTGAGGCTGTTCCTCTTTTATTATTTGCAGAGCTTCCTCAGCAGAGGAGGCATTCAACGCCTTGGCATATGTGTCATTAGTTGTTTGGCAGCCTCCTCTAGCACTTCTTCCGTCAATCTGGAACTTTCCCCATTCAAGTGTATCTCCGTCCTTGTCGATGTAGGACTTGACGTCGGAGCTTGATTTAGCTCCCTGTATGTTCGGATGGAAATGTGCTGACCGAGATGGGGAGACCAGATCGAAGAATCTGTTATTCGTGCAGTTGTATTTGCCCTCGAATTGTATAAGCACGTGGAGATGAGGCTTCCCATCTTGATGGAGCTCTCTGCAGATTTTGATGAACTTCTTGTTCACCGGAGTATTTAGTTTTTTTAATTGGGAAAGTGCCTCCTCTTTGGTAAGGGAACACTGTGGATAAGTAAGGAAATAGTTTTTGGCATTAGCAATTGAAGAACCCTTCCGTGGCATTTTTGTAATATGAAGGGTGTTCCCCCAATTGCTCTGGCTCCAAACTTATCTATGAATTGGGGGTACTGGGGGTACATTTATACTAGAACCCTCAATAGAACTCTCAATCGTGTGCATACGCGTGGCGGCCATCCGCTATAATATT
ACCGGATGGCCGCGCGCCCCCCCCTGGTGCCGTACACTCACGCGCGCCCCCCCCTGGTCCCGTTCTCGTACGCGCCCACTCATTGGTGTTTGGATAAGACGCTCCTTTTTTTGTAACTGCTTTAATTCAAATTAAAGCTTATTTCCTGTCTGACAATTTGAATTATTTTCTCGCGACGATGGACCATGTACTATCTCATAGACGTGGCAAAAAAAGGACCAAGCTGCTGAGTCTATTTGCGTTTACTGTTGAACCATTCATGTATATATTTGTGTTGGTGGATATGAATTTTTTTATCCTACTCAGCAGTGGATCACGTTTATATCGTTATAAACTATTATATTGTCCACCCCTTATAATCATTGGATAATGTATCCTTTGAGGAATAAACGTGGATCGTATTTTACTGCACGTCGATATTATCCACGTAATACATTTTCTAGGCGTCCATCTACTTCCAAGAAACAAGATGGGAAACGACGAGCTGTAAATACCAATAAGACGAATGACGAGCCGAAGATGTCAGCCCAACGCATACATGAGAATCAGTATGGGCCTGATTTTGTTATGGCCCATAATACTGCTATCTCGACCTTCATTAGTTACCCGGGCTTGGGTTCAACTTTACCCAACCGAAGCAGGTCCTATATTAAGTTGAAACAACTACGTTTCAAAGGGACCGTGAAGATTGAACGTGTTCAATCGGATCTGAACATGGATGGTTCTACCCCGAAGGTTGAAGGAGTCTTCTCCCTTGTTGTTGTTGTGGATCGTAAACCCCATGTTGGTCCTTCTGGCTGTCTACAATCATTTGACGAACTCTTTGGTGCAAGGATCCACAGCCATGGCAACCTCAACGTAACCTCTGCATTGAAAGATCGTTATTATATTCGACACGTTTGCAAACGTGTATTCTCAGTGGAGAAGGACACGTTGATGGTAGATGTGGAGGGATTCATTCCCCTCTCTAACAAGCGTTTCAATTGTTGGTCTACGTTCAAGGATCTTGATCGTGATTCATGCAAGGGTGTTTATGACAATATAAGCAAGAACGCCCTCTTAGTTTATTATTGTTGGATGTCGGATACGATGTCTACCGCATCTACCTTTGTATCGTTTGACCTTGATTATGTCGGTTGATCAATGAATAATGTTTAACCAAAGATGATTATCTTATTTGGACAGTGAAAAGATAACATTTATTTTAATGATTTGGCTTGAGAAGCCTGACAATTACTATTAATACATTCTTGGACAGTTGTCCTAACTAACTCGTTCAACTGGCCCATCGACATTGTTATGTTGGAACCCGCTCTTTGGGCCCCCACGATCGAAGCAGACTCTCCTGGGTCTAGAACGCTGGTTCCCAGCCTGTTTAGATGTCTATATGGATGGAGTTCGTTCTCCATCTCTGAGTCCGCGTCTGACGCGCCTGTACCTATTGTACTTCTAGAAGCCCACGACTCGCCAGGCCTAATCTCGATTGGGCCTCTTAGCCCAAGTCTTGACATTGATGCGCATCTTATGGGCTTCCTCTCCCATTTCCCATAGTCGACATGGGAGAAGTCCACGTCTTTGTCGGTGAACTGTTTGGACAGGATCTTGACTGTCGGTGCCCGGAATGGAATGTCGACCGAGTGTTTCGCCGTAGACAATTTCAGCTTGCCCTTGAACTTGGCAAAGTGGGTCCTTTGATGAACATTTGTATCGCAAACGCGATAGTACAATTTCCATGGAATTGGGTCTTTGAGTGAGAAGAACGAAGCCGAGAAATAGTGGAGATCTATGTTGCACCTGATCGGATAAGTCCAGGACGCCTGTAAGGACTCATTGTCCGTCATTCTTTTATCGTGGATCTCCACTATTACCGTCCCCGTGGCGTTGATCGGAACTTGTTGCCTGTATTCTATGACGCAGTGGTCTATCTTCATACAGCTACGACTGAGCCTAGCTGTCAACTGAGACGCCGTCGAAGGAAATTGCAGGATTATCTCAGTTAGGTCATGTGAAAGCTGGTACTCGTCCCGGTGAGACTCTATGTAGTTGAATGCGTTAGGAGGATTAACTAACTGAGAATCCATATGGAGAAATAAGGCCGCGCAGCGGAATCGATTGATGAAGATGAATCGGAAAAAAGATGACAGTCTAGCTCGTGAAGAACAGTATATACTATTCTGCAGAAGAAGAAAGAAATATATCTGGAAAACCCAGAAAATTGATGAAGATGTTGCTAGGCACTCTTTAAATCTCTCTCGAAGATGAATAGTTTTTCTGTGAAAGAGATAATTGCACTGTAAAATTATAATTCTGGGTTTTCTGGGTTTCTATTTGATGAACATATATAGGGAAAAGCAAATATTGTTAATGACTATGAATTGTGTTTGATAGTGTTTATATAGAAACCAGAGTGATGCAGTGGCATATTTGTAATATGAAGGGTGTTCCCCCAATTGATCTGGCTCCAAACTTATCTATGAATTGGGGGTACTGGGGGTACATTTATACTAGAACCCTCAATAGAACTCTCAATCGTGTGCATACACGTGGCGGCCATCCGCTATAATATT
Gene Information
|
NCBI Accession
|
YP_009428561.1
|
|
Location
|
182-937 |
|
Gene Name
|
AC1 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGCCTAAGCGCGATGCCCCATGGCGCCCGATGGCAGGAACTTCGAAGGTAAGTCGCAATGCAAATTATTCTCCCCGTGCAGGTATTGGGCCAAGAATGAACAGGGCATCGGAATGGGTTAACAGGCCTATGTACAGGAAGCCCAGGATCTATCGGACGCTACGGACGCCCGACATTCCGAGAGGCTGTGAAGGCCCGTGCAAGGTCCAGTCCTATGAACAGCGCCACGATATCTCTCACGTGGGTAAGGTGATGTGTATATCTGATGTCACACGTGGTAATGGCATTACCCACCGTGTGGGTAAGCGTTTTTGTGTTAAGTCTGTGTACATACTAGGTAAGATATGGATGGATGAGAACATCAAGCTCAAGAACCACACGAACAGCGTTATGTTCTGGTTGGTCAGAGACCGTCGACCGTATGGGACGCCTATGGATTTTGGACAGGTGTTCAACATGTTCGACAACGAACCCAGCACTGCCACGGTTAAGAACGATCTACGTGATCGTTACCAGGTTATGCACCGGTTCTATGGTAAGGTCACAGGTGGACAGTATGCCAGCAACGAGCAGGCTATTGTCAGGCGATTCTGGAAGGTCAACAACTATGTCGTCTACAACCACCAGGAAGCTGCCAAGTACGAGAACCACACTGAGAACGCGCTGTTATTGTACATGGCATGTACACATGCCTCTAACCCCGTGTATGCAACTCTGAAGATTCGAATCTATTTTTATGATTCGATAATGAATTAA |
|
Protein Sequence
|
MPKRDAPWRPMAGTSKVSRNANYSPRAGIGPRMNRASEWVNRPMYRKPRIYRTLRTPDIPRGCEGPCKVQSYEQRHDISHVGKVMCISDVTRGNGITHRVGKRFCVKSVYILGKIWMDENIKLKNHTNSVMFWLVRDRRPYGTPMDFGQVFNMFDNEPSTATVKNDLRDRYQVMHRFYGKVTGGQYASNEQAIVRRFWKVNNYVVYNHQEAAKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSIMN |
|
NCBI Accession
|
YP_009428562.1
|
|
Location
|
934-1332 |
|
Gene Name
|
AC3 |
|
Protein Name
|
REn |
|
Coding Region
|
ATGGATTTACGCACCGGGGAACTCATCACTGCACATCAGGCGGAGAATGGCGTGTATATCTGGGAGATAGAAAATCCCCTATATTTCAAGATATACAGAGTAGAGGATCTGCTATACACCAGAACAAGAGTGTACCACATCCAGATACGGTTCAACCACAACCTGAGGAGAGCGTTGCATCTCCACAAAGCTTACCTGAACTTCCAAGTCTGGACGACATCGATGACAGCTTCTGGGTCAACTTATTTAGTTAGGTTTACGTATTTAGTTAATATGTATTTAGATCAGTTAGGAGTGATTTCCATTAACAATGTAATTAGAGCTGTTCGTTTTGCAACGGACAGATCGTATGTGAATTATGTACTGGAAAATCATTCAATAAAATTCAAAATTTATTAA |
|
Protein Sequence
|
MDLRTGELITAHQAENGVYIWEIENPLYFKIYRVEDLLYTRTRVYHIQIRFNHNLRRALHLHKAYLNFQVWTTSMTASGSTYLVRFTYLVNMYLDQLGVISINNVIRAVRFATDRSYVNYVLENHSIKFKIY |
|
NCBI Accession
|
YP_009428563.1
|
|
Location
|
1079-1468 |
|
Gene Name
|
AC2 |
|
Protein Name
|
TrAP |
|
Coding Region
|
ATGCGGTCTTCATCACCCTCACATCCTCCCTCTATCAAGATAGCACACAGGCAGGCCAAGAGGAGGGCAGTCAGGAGGAGACGCATTGATCTTAGGTGCGGGTGCTCCATATACTTCCATATAGACTGCACGGGACATGGATTTACGCACCGGGGAACTCATCACTGCACATCAGGCGGAGAATGGCGTGTATATCTGGGAGATAGAAAATCCCCTATATTTCAAGATATACAGAGTAGAGGATCTGCTATACACCAGAACAAGAGTGTACCACATCCAGATACGGTTCAACCACAACCTGAGGAGAGCGTTGCATCTCCACAAAGCTTACCTGAACTTCCAAGTCTGGACGACATCGATGACAGCTTCTGGGTCAACTTATTTAGTTAG |
|
Protein Sequence
|
MRSSSPSHPPSIKIAHRQAKRRAVRRRRIDLRCGCSIYFHIDCTGHGFTHRGTHHCTSGGEWRVYLGDRKSPIFQDIQSRGSAIHQNKSVPHPDTVQPQPEESVASPQSLPELPSLDDIDDSFWVNLFS |
|
NCBI Accession
|
YP_009428564.1
|
|
Location
|
1817-2464 |
|
Gene Name
|
AV1 |
|
Protein Name
|
replication protein |
|
Coding Region
|
ATGCCACGGAAGGGTTCTTCAATTGCTAATGCCAAAAACTATTTCCTTACTTATCCACAGTGTTCCCTTACCAAAGAGGAGGCACTTTCCCAATTAAAAAAACTAAATACTCCGGTGAACAAGAAGTTCATCAAAATCTGCAGAGAGCTCCATCAAGATGGGAAGCCTCATCTCCACGTGCTTATACAATTCGAGGGCAAATACAACTGCACGAATAACAGATTCTTCGATCTGGTCTCCCCATCTCGGTCAGCACATTTCCATCCGAACATACAGGGAGCTAAATCAAGCTCCGACGTCAAGTCCTACATCGACAAGGACGGAGATACACTTGAATGGGGAAAGTTCCAGATTGACGGAAGAAGTGCTAGAGGAGGCTGCCAAACAACTAATGACACATATGCCAAGGCGTTGAATGCCTCCTCTGCTGAGGAAGCTCTGCAAATAATAAAAGAGGAACAGCCTCAACATTTTTTCCTTCAGCATCATAATTTGGTAGCAAATGCTCATCGGATCTTTCAAAAGGCTCCGGAACCATGGGTCCCTCCGTTTCAACTCTCCTCTTTCACTAACGTTCCTGAAGAGATGCAAGACTGGGCCGATGAGTATTTTGGAAGAGGTTCCGCTGCGCGGCCGGAAGACCAGTAA |
|
Protein Sequence
|
MPRKGSSIANAKNYFLTYPQCSLTKEEALSQLKKLNTPVNKKFIKICRELHQDGKPHLHVLIQFEGKYNCTNNRFFDLVSPSRSAHFHPNIQGAKSSSDVKSYIDKDGDTLEWGKFQIDGRSARGGCQTTNDTYAKALNASSAEEALQIIKEEQPQHFFLQHHNLVANAHRIFQKAPEPWVPPFQLSSFTNVPEEMQDWADEYFGRGSAARPEDQ |
|
NCBI Accession
|
YP_009428565.1
|
|
Location
|
2050-2307 |
|
Gene Name
|
AC4 |
|
Protein Name
|
AC4 protein |
|
Coding Region
|
ATGGGAAGCCTCATCTCCACGTGCTTATACAATTCGAGGGCAAATACAACTGCACGAATAACAGATTCTTCGATCTGGTCTCCCCATCTCGGTCAGCACATTTCCATCCGAACATACAGGGAGCTAAATCAAGCTCCGACGTCAAGTCCTACATCGACAAGGACGGAGATACACTTGAATGGGGAAAGTTCCAGATTGACGGAAGAAGTGCTAGAGGAGGCTGCCAAACAACTAATGACACATATGCCAAGGCGTTGA |
|
Protein Sequence
|
MGSLISTCLYNSRANTTARITDSSIWSPHLGQHISIRTYRELNQAPTSSPTSTRTEIHLNGESSRLTEEVLEEAAKQLMTHMPRR |
|
NCBI Accession
|
YP_009428566.1
|
|
Location
|
370-1140 |
|
Gene Name
|
BV1 |
|
Protein Name
|
NSP |
|
Coding Region
|
ATGTATCCTTTGAGGAATAAACGTGGATCGTATTTTACTGCACGTCGATATTATCCACGTAATACATTTTCTAGGCGTCCATCTACTTCCAAGAAACAAGATGGGAAACGACGAGCTGTAAATACCAATAAGACGAATGACGAGCCGAAGATGTCAGCCCAACGCATACATGAGAATCAGTATGGGCCTGATTTTGTTATGGCCCATAATACTGCTATCTCGACCTTCATTAGTTACCCGGGCTTGGGTTCAACTTTACCCAACCGAAGCAGGTCCTATATTAAGTTGAAACAACTACGTTTCAAAGGGACCGTGAAGATTGAACGTGTTCAATCGGATCTGAACATGGATGGTTCTACCCCGAAGGTTGAAGGAGTCTTCTCCCTTGTTGTTGTTGTGGATCGTAAACCCCATGTTGGTCCTTCTGGCTGTCTACAATCATTTGACGAACTCTTTGGTGCAAGGATCCACAGCCATGGCAACCTCAACGTAACCTCTGCATTGAAAGATCGTTATTATATTCGACACGTTTGCAAACGTGTATTCTCAGTGGAGAAGGACACGTTGATGGTAGATGTGGAGGGATTCATTCCCCTCTCTAACAAGCGTTTCAATTGTTGGTCTACGTTCAAGGATCTTGATCGTGATTCATGCAAGGGTGTTTATGACAATATAAGCAAGAACGCCCTCTTAGTTTATTATTGTTGGATGTCGGATACGATGTCTACCGCATCTACCTTTGTATCGTTTGACCTTGATTATGTCGGTTGA |
|
Protein Sequence
|
MYPLRNKRGSYFTARRYYPRNTFSRRPSTSKKQDGKRRAVNTNKTNDEPKMSAQRIHENQYGPDFVMAHNTAISTFISYPGLGSTLPNRSRSYIKLKQLRFKGTVKIERVQSDLNMDGSTPKVEGVFSLVVVVDRKPHVGPSGCLQSFDELFGARIHSHGNLNVTSALKDRYYIRHVCKRVFSVEKDTLMVDVEGFIPLSNKRFNCWSTFKDLDRDSCKGVYDNISKNALLVYYCWMSDTMSTASTFVSFDLDYVG |
|
NCBI Accession
|
YP_009428567.1
|
|
Location
|
1200-2081 |
|
Gene Name
|
BC1 |
|
Protein Name
|
MP |
|
Coding Region
|
ATGGATTCTCAGTTAGTTAATCCTCCTAACGCATTCAACTACATAGAGTCTCACCGGGACGAGTACCAGCTTTCACATGACCTAACTGAGATAATCCTGCAATTTCCTTCGACGGCGTCTCAGTTGACAGCTAGGCTCAGTCGTAGCTGTATGAAGATAGACCACTGCGTCATAGAATACAGGCAACAAGTTCCGATCAACGCCACGGGGACGGTAATAGTGGAGATCCACGATAAAAGAATGACGGACAATGAGTCCTTACAGGCGTCCTGGACTTATCCGATCAGGTGCAACATAGATCTCCACTATTTCTCGGCTTCGTTCTTCTCACTCAAAGACCCAATTCCATGGAAATTGTACTATCGCGTTTGCGATACAAATGTTCATCAAAGGACCCACTTTGCCAAGTTCAAGGGCAAGCTGAAATTGTCTACGGCGAAACACTCGGTCGACATTCCATTCCGGGCACCGACAGTCAAGATCCTGTCCAAACAGTTCACCGACAAAGACGTGGACTTCTCCCATGTCGACTATGGGAAATGGGAGAGGAAGCCCATAAGATGCGCATCAATGTCAAGACTTGGGCTAAGAGGCCCAATCGAGATTAGGCCTGGCGAGTCGTGGGCTTCTAGAAGTACAATAGGTACAGGCGCGTCAGACGCGGACTCAGAGATGGAGAACGAACTCCATCCATATAGACATCTAAACAGGCTGGGAACCAGCGTTCTAGACCCAGGAGAGTCTGCTTCGATCGTGGGGGCCCAAAGAGCGGGTTCCAACATAACAATGTCGATGGGCCAGTTGAACGAGTTAGTTAGGACAACTGTCCAAGAATGTATTAATAGTAATTGTCAGGCTTCTCAAGCCAAATCATTAAAATAA |
|
Protein Sequence
|
MDSQLVNPPNAFNYIESHRDEYQLSHDLTEIILQFPSTASQLTARLSRSCMKIDHCVIEYRQQVPINATGTVIVEIHDKRMTDNESLQASWTYPIRCNIDLHYFSASFFSLKDPIPWKLYYRVCDTNVHQRTHFAKFKGKLKLSTAKHSVDIPFRAPTVKILSKQFTDKDVDFSHVDYGKWERKPIRCASMSRLGLRGPIEIRPGESWASRSTIGTGASDADSEMENELHPYRHLNRLGTSVLDPGESASIVGAQRAGSNITMSMGQLNELVRTTVQECINSNCQASQAKSLK |