Synedrella yellow vein clearing virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_003029435.1 |
| Isolate |
India |
| Release date |
2018/8/26 |
| Submitter |
Das,S., Shivaprasad,P. |
| Host |
|
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
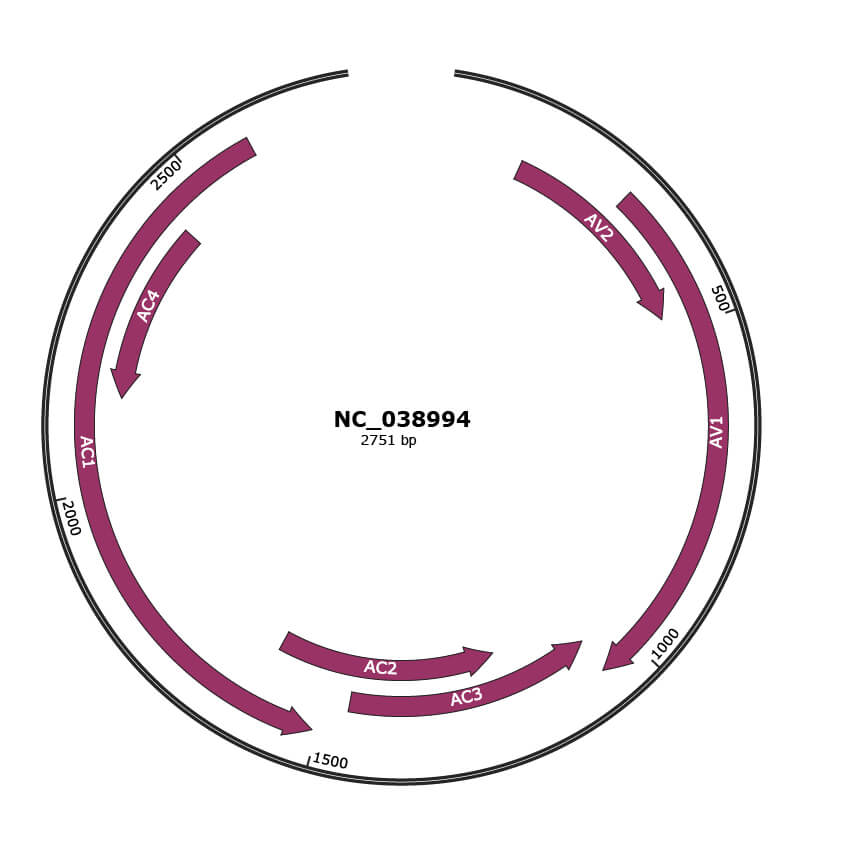
JBrowse
Genome
ACCGGATGGCCGCGATTTTTTTTTAAGTGGTCCCCAGACCACGTGGTCCAATAATAGACGCTCCTCAAAGCTTAATTAATGGTTTGTGGGCCTATAACTTGCCCACCAAGTAGTGGGATTTTGTCATAATGTGGGATCCACTTTTAAACGAGTTTCCGGATACGGTGCACGGTTTTCGGTGTATGCTTGCTGTGAAATACTTACAGCTCGTAGAGAATACGTATTCACCGGATTCATTGGGTTACGATTTAATTCGGGATTTGATATCTGTAGTTCGTGCTCGTAACTATGTCGAAGCGACCAGCAGATATAATCATTTCCACTCCCGCATCGAAGGTGCGACGCCGTCTGAACTTCGAAACCCCCTACACGAGCCGTGTTGCTGTCCCCACTGTCCGCGTCACAAAATCAAGAGCATGGGCCAATCGGCCCATGAATCGGAAACCCAGGATGTACAGAATGTACAGAAGCCCTGATGTTCCTAGAGGATGCGAAGGCCCATGTAAGGTGCAATCATTTGAGTCTAGGCACGATGTAGTCCATATAGGGAAGGTCATGTGTATTAGTGATGTCACTCGTGGAACTGGGTTGACCCATAGAGTTGGTAAGCGTTTTTGTGTTAAGTCGGTTTACGTTTTGGGTAAGATATGGATGGATGAGAACATCAAGACCAAGAATCACACGAACAGTGTCATGTTTTTTCTTGTTCGTGATCGAAGACCTGTTGATAAGCCTCAAGATTTTGGAGAGGTGTTCAATATGTTTGATAATGAGCCTAGCACTGCTACTGTTAAGAATATGCACAGAGATCGTTATCAGGTGTTGAGAAAGTGGCACGCAACTGTCACTGGTGGTCAGTATGCATCCAAGGAGCAGGCGTTAGTTAAAAAATTTGTTAAAGTTAATAATTATGTTGTGTATAACCAGCAAGAGGCTGGGAAGTATGAGAATCATTCTGAAAATGCATTAATGTTGTATATGGCGTGCACGCACGCCTCTAATCCTGTGTATGCTACGTTGAAGATACGGATCTATTTTTATGATTCGGTCACAAATTAATAAATATTGAATTTTATTGATGATAATTGTTCTACGTATACAATGTGTTGCAATAGATTCCATAATACATGATCCACTGCTCTAATTACATTGTTAATACTAATAACTCCCACATTATTTAAGTACTTGAGTACTTGTGTCCTAAATACTCTTAAGAAACGACCAGTCTGAGGCTGTGAAGTCATCCAGATCCGGAAGGTCAGAAAGCATTTGTGAATTCCCAACGCTTTCCTCAGGTTGTAATTGAACTGGATTTGGATTTTCATGATATCTTGTTTCATTGTAAATGGGCGGTTGTGGTGCTCCGTTATCTTGAAATAAAGGGGATTTTGTATCTCCCAGATATACACGCCATTCTCTGCTTGAGCTGCAGTGATGTACTCCCCTGTGCGAGAATCCATGGTTATGACAGGCTAGGGCTATGAAGTATGAGCAGCCGCACGGTAGATCAACTCTCCGTCGTCTGTTGCTCTTCTTCGCTATCCTGTGTTGGACTTTGATGGGTACCTGAGTAGAGTGGCTCTTCGAGGGTGACGAAGGTCGCATTCTTCAGAGCCCAGTTTTTAAGCGCATTGTTTTTCTCTTCATCCAGATACTCTTTATAACTTGAATTGGGTCCTGGATTGCAGAGGAAGATAGTGGGAATTCCGCCTTTAATTTGAACAGGTTTCCCGTACTTGGTGTTGCTTTGCCAGTCTCTTTGGGCCCCCATGAATTCTTTAAAGTGCTTTAGATAGTGCGGATCGACGTCATCAATGACGTTATACCACGCATTATTACTGTACACTTTCGGACTCAGATCGAGATGACCACACAAGTAGTTATGTGGTCCTAGTGACCTAGCCCACATGGTTTTTCCGGTACGACTATCACCCTCAATTACAATACTTATGGGCCTGATAGGCCGCGCAGCGGCACTGACAACGTTTTCACATGCCCACTCTTCAAGTTCTTCTGGAACTTGGTCAAAAGAAGAAGATAAAAAAGGAGAAACATAAACCTCCATTGGAGGTGTAAAAATCCTATCTAAATTAGAATTTAAATTGTGAAATTGTAAAACATAATCTTTGGGAGCTTTCTCCCTTAATATATTGAGGGCCTCAATTTTGGACCCTGAATTGATTGCCTCGGCATATGCGTCATTGGCAGATTGGCAACCTCCTCTAGCTGATCTTCCATCGACTTGGAAAACTCCATGATCAAGGATGTCTCCGTCTTTTTCCATATAGGTTTTGACGTCTGACGAACTTTTAGCTCCCTGAATGTTCGGATGGAAATGTGTTGACCGGCTTGGGGATGTGAGGTCGAAGAATCTGTTGTTTTGGCACTTGTATTTTCCTTCGAATTGGATGAGAACATGCAGGTGAGGAGTCCCATCTTCGTGAAGCTCTCTGCAGATTCTAATGAATTTTTTATTAGTTGGGGTTTGTAGGTTTAGGAATTGGGAAAGTGCCTCTTCTTTTGTAAGTGTGCACTTTGGATAAGTAAGAAAATAATTTTTGGCATTTATTTGAAAACGTTTGGGTTGAGGCATGTTGACTTGGTCAATCGGTACTCAACAAACTTGTCTATGCAATTGGGGAATGGTACTCAATATATAGGTGAGTACCAAATGGCATTATTGTAATTTGGTAAAGTGTGTTTTGAAATTCAAAACCCTCACGCTCCAAAAGCGGCCATCCGTATAATATT
Gene Information
|
NCBI Accession
|
YP_009508435.1
|
|
Location
|
129-476 |
|
Gene Name
|
AV2 |
|
Protein Name
|
pre-coat protein |
|
Coding Region
|
ATGTGGGATCCACTTTTAAACGAGTTTCCGGATACGGTGCACGGTTTTCGGTGTATGCTTGCTGTGAAATACTTACAGCTCGTAGAGAATACGTATTCACCGGATTCATTGGGTTACGATTTAATTCGGGATTTGATATCTGTAGTTCGTGCTCGTAACTATGTCGAAGCGACCAGCAGATATAATCATTTCCACTCCCGCATCGAAGGTGCGACGCCGTCTGAACTTCGAAACCCCCTACACGAGCCGTGTTGCTGTCCCCACTGTCCGCGTCACAAAATCAAGAGCATGGGCCAATCGGCCCATGAATCGGAAACCCAGGATGTACAGAATGTACAGAAGCCCTGA |
|
Protein Sequence
|
MWDPLLNEFPDTVHGFRCMLAVKYLQLVENTYSPDSLGYDLIRDLISVVRARNYVEATSRYNHFHSRIEGATPSELRNPLHEPCCCPHCPRHKIKSMGQSAHESETQDVQNVQKP |
|
NCBI Accession
|
YP_009508436.1
|
|
Location
|
289-1059 |
|
Gene Name
|
AV1 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGTCGAAGCGACCAGCAGATATAATCATTTCCACTCCCGCATCGAAGGTGCGACGCCGTCTGAACTTCGAAACCCCCTACACGAGCCGTGTTGCTGTCCCCACTGTCCGCGTCACAAAATCAAGAGCATGGGCCAATCGGCCCATGAATCGGAAACCCAGGATGTACAGAATGTACAGAAGCCCTGATGTTCCTAGAGGATGCGAAGGCCCATGTAAGGTGCAATCATTTGAGTCTAGGCACGATGTAGTCCATATAGGGAAGGTCATGTGTATTAGTGATGTCACTCGTGGAACTGGGTTGACCCATAGAGTTGGTAAGCGTTTTTGTGTTAAGTCGGTTTACGTTTTGGGTAAGATATGGATGGATGAGAACATCAAGACCAAGAATCACACGAACAGTGTCATGTTTTTTCTTGTTCGTGATCGAAGACCTGTTGATAAGCCTCAAGATTTTGGAGAGGTGTTCAATATGTTTGATAATGAGCCTAGCACTGCTACTGTTAAGAATATGCACAGAGATCGTTATCAGGTGTTGAGAAAGTGGCACGCAACTGTCACTGGTGGTCAGTATGCATCCAAGGAGCAGGCGTTAGTTAAAAAATTTGTTAAAGTTAATAATTATGTTGTGTATAACCAGCAAGAGGCTGGGAAGTATGAGAATCATTCTGAAAATGCATTAATGTTGTATATGGCGTGCACGCACGCCTCTAATCCTGTGTATGCTACGTTGAAGATACGGATCTATTTTTATGATTCGGTCACAAATTAA |
|
Protein Sequence
|
MSKRPADIIISTPASKVRRRLNFETPYTSRVAVPTVRVTKSRAWANRPMNRKPRMYRMYRSPDVPRGCEGPCKVQSFESRHDVVHIGKVMCISDVTRGTGLTHRVGKRFCVKSVYVLGKIWMDENIKTKNHTNSVMFFLVRDRRPVDKPQDFGEVFNMFDNEPSTATVKNMHRDRYQVLRKWHATVTGGQYASKEQALVKKFVKVNNYVVYNQQEAGKYENHSENALMLYMACTHASNPVYATLKIRIYFYDSVTN |
|
NCBI Accession
|
YP_009508437.1
|
|
Location
|
1056-1460 |
|
Gene Name
|
AC3 |
|
Protein Name
|
replication enhancer protein |
|
Coding Region
|
ATGGATTCTCGCACAGGGGAGTACATCACTGCAGCTCAAGCAGAGAATGGCGTGTATATCTGGGAGATACAAAATCCCCTTTATTTCAAGATAACGGAGCACCACAACCGCCCATTTACAATGAAACAAGATATCATGAAAATCCAAATCCAGTTCAATTACAACCTGAGGAAAGCGTTGGGAATTCACAAATGCTTTCTGACCTTCCGGATCTGGATGACTTCACAGCCTCAGACTGGTCGTTTCTTAAGAGTATTTAGGACACAAGTACTCAAGTACTTAAATAATGTGGGAGTTATTAGTATTAACAATGTAATTAGAGCAGTGGATCATGTATTATGGAATCTATTGCAACACATTGTATACGTAGAACAATTATCATCAATAAAATTCAATATTTATTAA |
|
Protein Sequence
|
MDSRTGEYITAAQAENGVYIWEIQNPLYFKITEHHNRPFTMKQDIMKIQIQFNYNLRKALGIHKCFLTFRIWMTSQPQTGRFLRVFRTQVLKYLNNVGVISINNVIRAVDHVLWNLLQHIVYVEQLSSIKFNIY |
|
NCBI Accession
|
YP_009508438.1
|
|
Location
|
1201-1605 |
|
Gene Name
|
AC2 |
|
Protein Name
|
transcriptional activator protein |
|
Coding Region
|
ATGCGACCTTCGTCACCCTCGAAGAGCCACTCTACTCAGGTACCCATCAAAGTCCAACACAGGATAGCGAAGAAGAGCAACAGACGACGGAGAGTTGATCTACCGTGCGGCTGCTCATACTTCATAGCCCTAGCCTGTCATAACCATGGATTCTCGCACAGGGGAGTACATCACTGCAGCTCAAGCAGAGAATGGCGTGTATATCTGGGAGATACAAAATCCCCTTTATTTCAAGATAACGGAGCACCACAACCGCCCATTTACAATGAAACAAGATATCATGAAAATCCAAATCCAGTTCAATTACAACCTGAGGAAAGCGTTGGGAATTCACAAATGCTTTCTGACCTTCCGGATCTGGATGACTTCACAGCCTCAGACTGGTCGTTTCTTAAGAGTATTTAG |
|
Protein Sequence
|
MRPSSPSKSHSTQVPIKVQHRIAKKSNRRRRVDLPCGCSYFIALACHNHGFSHRGVHHCSSSREWRVYLGDTKSPLFQDNGAPQPPIYNETRYHENPNPVQLQPEESVGNSQMLSDLPDLDDFTASDWSFLKSI |
|
NCBI Accession
|
YP_009508439.1
|
|
Location
|
1508-2593 |
|
Gene Name
|
AC1 |
|
Protein Name
|
replication associated protein |
|
Coding Region
|
ATGCCTCAACCCAAACGTTTTCAAATAAATGCCAAAAATTATTTTCTTACTTATCCAAAGTGCACACTTACAAAAGAAGAGGCACTTTCCCAATTCCTAAACCTACAAACCCCAACTAATAAAAAATTCATTAGAATCTGCAGAGAGCTTCACGAAGATGGGACTCCTCACCTGCATGTTCTCATCCAATTCGAAGGAAAATACAAGTGCCAAAACAACAGATTCTTCGACCTCACATCCCCAAGCCGGTCAACACATTTCCATCCGAACATTCAGGGAGCTAAAAGTTCGTCAGACGTCAAAACCTATATGGAAAAAGACGGAGACATCCTTGATCATGGAGTTTTCCAAGTCGATGGAAGATCAGCTAGAGGAGGTTGCCAATCTGCCAATGACGCATATGCCGAGGCAATCAATTCAGGGTCCAAAATTGAGGCCCTCAATATATTAAGGGAGAAAGCTCCCAAAGATTATGTTTTACAATTTCACAATTTAAATTCTAATTTAGATAGGATTTTTACACCTCCAATGGAGGTTTATGTTTCTCCTTTTTTATCTTCTTCTTTTGACCAAGTTCCAGAAGAACTTGAAGAGTGGGCATGTGAAAACGTTGTCAGTGCCGCTGCGCGGCCTATCAGGCCCATAAGTATTGTAATTGAGGGTGATAGTCGTACCGGAAAAACCATGTGGGCTAGGTCACTAGGACCACATAACTACTTGTGTGGTCATCTCGATCTGAGTCCGAAAGTGTACAGTAATAATGCGTGGTATAACGTCATTGATGACGTCGATCCGCACTATCTAAAGCACTTTAAAGAATTCATGGGGGCCCAAAGAGACTGGCAAAGCAACACCAAGTACGGGAAACCTGTTCAAATTAAAGGCGGAATTCCCACTATCTTCCTCTGCAATCCAGGACCCAATTCAAGTTATAAAGAGTATCTGGATGAAGAGAAAAACAATGCGCTTAAAAACTGGGCTCTGAAGAATGCGACCTTCGTCACCCTCGAAGAGCCACTCTACTCAGGTACCCATCAAAGTCCAACACAGGATAGCGAAGAAGAGCAACAGACGACGGAGAGTTGA |
|
Protein Sequence
|
MPQPKRFQINAKNYFLTYPKCTLTKEEALSQFLNLQTPTNKKFIRICRELHEDGTPHLHVLIQFEGKYKCQNNRFFDLTSPSRSTHFHPNIQGAKSSSDVKTYMEKDGDILDHGVFQVDGRSARGGCQSANDAYAEAINSGSKIEALNILREKAPKDYVLQFHNLNSNLDRIFTPPMEVYVSPFLSSSFDQVPEELEEWACENVVSAAARPIRPISIVIEGDSRTGKTMWARSLGPHNYLCGHLDLSPKVYSNNAWYNVIDDVDPHYLKHFKEFMGAQRDWQSNTKYGKPVQIKGGIPTIFLCNPGPNSSYKEYLDEEKNNALKNWALKNATFVTLEEPLYSGTHQSPTQDSEEEQQTTES |
|
NCBI Accession
|
YP_009508440.1
|
|
Location
|
2143-2436 |
|
Gene Name
|
AC4 |
|
Protein Name
|
AC4 |
|
Coding Region
|
ATGGGACTCCTCACCTGCATGTTCTCATCCAATTCGAAGGAAAATACAAGTGCCAAAACAACAGATTCTTCGACCTCACATCCCCAAGCCGGTCAACACATTTCCATCCGAACATTCAGGGAGCTAAAAGTTCGTCAGACGTCAAAACCTATATGGAAAAAGACGGAGACATCCTTGATCATGGAGTTTTCCAAGTCGATGGAAGATCAGCTAGAGGAGGTTGCCAATCTGCCAATGACGCATATGCCGAGGCAATCAATTCAGGGTCCAAAATTGAGGCCCTCAATATATTAA |
|
Protein Sequence
|
MGLLTCMFSSNSKENTSAKTTDSSTSHPQAGQHISIRTFRELKVRQTSKPIWKKTETSLIMEFSKSMEDQLEEVANLPMTHMPRQSIQGPKLRPSIY |