Sweet potato leaf curl South Carolina virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_000893435.1 |
| Isolate |
USA |
| Release date |
2015/2/22 |
| Submitter |
Zhang,S.C., Ling,K.S., Zhang,S., Ling,K.-S. |
| Host |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
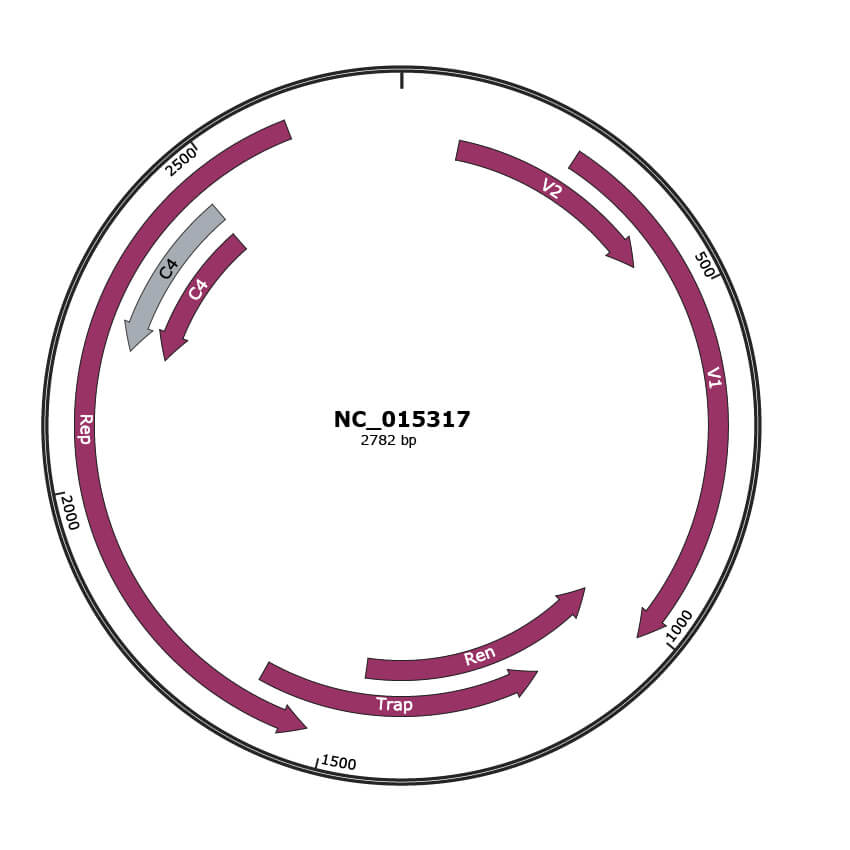
Genomic Organization
JBrowse
Genome
ACCGGTGCCCGCGCGACTTTTATTGTGGGACCCACGCGCTTTGCTTTAATTATTTAAAGGCGTTCTTGGTGCAGACTTTGTCGCCAAGAATGGATATGTGGGACCCACTTCAGAACCCACTCCCAGATACTTTATACGGTTTCCGTTGTATGCTTTCTGTAAAATACCTGCAAGGTATTTTGAAGAAATACGAACCAGGAACCCTAGGGTTCGAACTTTGTTCCGAACTCATCCGCATACTGCGTGTCAAGCAATATGGTAGGGCGAATTCCCGTTTCGCGGAGATTTCATCCCTATGGGGGGAGACCGGTAAGACGGAGGCTGAACTTCGAGACAGCTATCGTGCCCTACACTGGGAATGCTGTCCCAATTGCTGCCCGAAGCTATGTCCCGGTTTCTCGAAGCGTCCAGATGAAGAGAAGGAAGGGTGATCGCATCCCGAAGGGATGTGTTGGTCCCTGTAAGGTACAGGACTATGAGTTCAAGATGGATGTCCCACATAGTGGGACCTTTGTTTGTGTTTCTGATTTTACTAGAGGTACTGGGCTTACCCATCGTTTGGGTAAGAGGGTGTGTATTAAGTCCATGGGTATTGACGGTAAGGTCTGGATGGACGACAACGTCGCCAAGAGGGACCATACCAACATTATTACTTACTGGTTGGTCCGAGATCGGAGGCCCAATAAGGATCCTTTGACATTTGTACAGGCGTTTGCAATGTGTGATAACGAGCCCACTACTGCTAAGATCCGTATGGATCTGAGAGATAGAATGCAGGTGTTGAAGAAGTTCTCTGTTACAGTTTCAGGAGGCCCTTATAACCACAAAGAGCAGGCTTTGATTAGGAAGTTTTTTAAGGGATTGTATAATCATGTTACTTATAATCATAAGGAGGAGGCCAAATATGAGAATCATTTAGAAAATGCGTTAATGTTGTATTCTGCTAGCAGTCATGCTAGTAATCCTGTGTATCAGACCCTGCGTTGCAGGGCTTATTTTTATGATTCGCACAACAATTAATAAAGAAGTATTTTTATATCATCTTTACAATCTATTACATCGACTTCTTCAATCCATCTAACTGATTCAGGCAGATGCCTGATTACATAAACTAAATTGATAAGAGAAAAAAAACCTAAACTAGCTAAGCTATTACATATATGCCATTTAAGGCGTTGCAAAATACCAGTCCAACTGGGAATAACACCAGTCAGCTGGGTTGTTACTATTCGGAATTGGAGGAAGATCTTCTGGAATCCAATTTCCCTCCTGTTCCTGTGGTTGACTTGAAGCTGCAACTTGATGACCTTCTTTGTGTTGATGTTGTTGGTATGGACATATATCAGTCGTAGATGGAATGGAGCAGTCTGACCCACAGACATGGGATTGTTGAAGAATTCTGCTGCTCTCGTAATCTGTGCATGACTTAGTGACTCCCCGGTGCGTGAATCCATGTTGGAACTTGCAGGCGTTGGTGATGAAGGCTGAACAACCACAGCCCTTCCACACTATCCTTGTCCTTTGCTCAGGAGCCTTCCTCTTGGCCTTCTTCGCCGCTGTGTGCAGAGGTTCCTGAATGGGACACTTCCTCTTGTATCCAGAAGGGAGATTGGACATCGCAGAATATAGCGTTTGCTGTTGCCCAATTCTTGAGTGCTCCTTGCTCTGGTTTGTCTAGCCAGAGTTTAAATGAGGAACCCTCTCCTGGATTGCAGAGGAAGATAGTGGGAATTCCGCCTTTAATTTGAACTGGCTTTCCGTATTTACAGTTGGATTGCCAGTCCTTCTGGGCCCCCATGAATTCTTTAAAGTGCTTTAGGTATTGGGGGTTGACGTCATCAATGATGTTATACCAAGCACTGTTGCTATACACTTTTGGACTCAGATCTAAATGACCACACAGATAATTATGTGGACCTAAAGACCTAGCCCAAACTGTTTTACCTATCCTACTTGGGCCTTCTATTACAATACTTATGGGCCTATCTGGCCGCGCAGCGGAATCCATGACATTTTCAGCAGCCCAATCGCTGATAATGTCAGGAACATTATTGAAAGAAGAAGATAAAAAAGGTGAAGAATATACAGAAGGAGGAGGAGAAAAAATCCTATCTAAATTACCACATAAATTGTGGTATTGAAAAATAAATTTCTCAGGGAGTTTTTCCCTGATAATTTGTAAGGCAGCTTCTTTACTTCCTGAGTTTAAGGCCTCTGCTGCTGCGTCATTAGCCGTCTGCTGGCCTCCTCGAGCAGATCTGCCGTCGACCTGGAATTCACCCCATTCAATTGTGTCACCGTCCTTATCGACATAGGACTTGACATCGGAGCTGGATTTAGCTCTCTGGATATTGGGGTGAAAGTGAGCCGACCTTGATGGTGATACAAGGTCGAAGAATCTCTGATTCGTGCATTGGTAGTTCCCTTCGAACTGCAATAGCACGTGGAGATGAGGTTCCCCATTTTCATGCAGCTCTCTGCATATTTTTATGAATTTTTTGTTGGTTGGGGTGTTGAGGTTACGAAGCTGGTCGAGAGCTTCTTCTTTGGTGAGAGAGCATTGGGGATATGTGAGGAAATAGTTTTTTGCTTTTATATTAAAACGCCCGGCTCTAGGCATGTTGAAAAAGCAAATGGTGGAACACAAACTTGCTGTATGAATTGGTGGAACGGTGGACAATTTATATGTGTCCACCAAATGGCATTTTGGTAATTTGAACAACTTTAATTTGAATTCTGAAAGCCTATTGGTCCTCCGTAAAGCGGGCACCGTATTAATATT
Gene Information
|
NCBI Accession
|
YP_004339037.1
|
|
Location
|
90-431 |
|
Gene Name
|
V2 |
|
Protein Name
|
V2 |
|
Coding Region
|
ATGGATATGTGGGACCCACTTCAGAACCCACTCCCAGATACTTTATACGGTTTCCGTTGTATGCTTTCTGTAAAATACCTGCAAGGTATTTTGAAGAAATACGAACCAGGAACCCTAGGGTTCGAACTTTGTTCCGAACTCATCCGCATACTGCGTGTCAAGCAATATGGTAGGGCGAATTCCCGTTTCGCGGAGATTTCATCCCTATGGGGGGAGACCGGTAAGACGGAGGCTGAACTTCGAGACAGCTATCGTGCCCTACACTGGGAATGCTGTCCCAATTGCTGCCCGAAGCTATGTCCCGGTTTCTCGAAGCGTCCAGATGAAGAGAAGGAAGGGTGA |
|
Protein Sequence
|
MDMWDPLQNPLPDTLYGFRCMLSVKYLQGILKKYEPGTLGFELCSELIRILRVKQYGRANSRFAEISSLWGETGKTEAELRDSYRALHWECCPNCCPKLCPGFSKRPDEEKEG |
|
NCBI Accession
|
YP_004339038.1
|
|
Location
|
256-1020 |
|
Gene Name
|
V1 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGGTAGGGCGAATTCCCGTTTCGCGGAGATTTCATCCCTATGGGGGGAGACCGGTAAGACGGAGGCTGAACTTCGAGACAGCTATCGTGCCCTACACTGGGAATGCTGTCCCAATTGCTGCCCGAAGCTATGTCCCGGTTTCTCGAAGCGTCCAGATGAAGAGAAGGAAGGGTGATCGCATCCCGAAGGGATGTGTTGGTCCCTGTAAGGTACAGGACTATGAGTTCAAGATGGATGTCCCACATAGTGGGACCTTTGTTTGTGTTTCTGATTTTACTAGAGGTACTGGGCTTACCCATCGTTTGGGTAAGAGGGTGTGTATTAAGTCCATGGGTATTGACGGTAAGGTCTGGATGGACGACAACGTCGCCAAGAGGGACCATACCAACATTATTACTTACTGGTTGGTCCGAGATCGGAGGCCCAATAAGGATCCTTTGACATTTGTACAGGCGTTTGCAATGTGTGATAACGAGCCCACTACTGCTAAGATCCGTATGGATCTGAGAGATAGAATGCAGGTGTTGAAGAAGTTCTCTGTTACAGTTTCAGGAGGCCCTTATAACCACAAAGAGCAGGCTTTGATTAGGAAGTTTTTTAAGGGATTGTATAATCATGTTACTTATAATCATAAGGAGGAGGCCAAATATGAGAATCATTTAGAAAATGCGTTAATGTTGTATTCTGCTAGCAGTCATGCTAGTAATCCTGTGTATCAGACCCTGCGTTGCAGGGCTTATTTTTATGATTCGCACAACAATTAA |
|
Protein Sequence
|
MVGRIPVSRRFHPYGGRPVRRRLNFETAIVPYTGNAVPIAARSYVPVSRSVQMKRRKGDRIPKGCVGPCKVQDYEFKMDVPHSGTFVCVSDFTRGTGLTHRLGKRVCIKSMGIDGKVWMDDNVAKRDHTNIITYWLVRDRRPNKDPLTFVQAFAMCDNEPTTAKIRMDLRDRMQVLKKFSVTVSGGPYNHKEQALIRKFFKGLYNHVTYNHKEEAKYENHLENALMLYSASSHASNPVYQTLRCRAYFYDSHNN |
|
NCBI Accession
|
YP_004339039.1
|
|
Location
|
1017-1454 |
|
Gene Name
|
Ren |
|
Protein Name
|
replication enhancer protein |
|
Coding Region
|
ATGGATTCACGCACCGGGGAGTCACTAAGTCATGCACAGATTACGAGAGCAGCAGAATTCTTCAACAATCCCATGTCTGTGGGTCAGACTGCTCCATTCCATCTACGACTGATATATGTCCATACCAACAACATCAACACAAAGAAGGTCATCAAGTTGCAGCTTCAAGTCAACCACAGGAACAGGAGGGAAATTGGATTCCAGAAGATCTTCCTCCAATTCCGAATAGTAACAACCCAGCTGACTGGTGTTATTCCCAGTTGGACTGGTATTTTGCAACGCCTTAAATGGCATATATGTAATAGCTTAGCTAGTTTAGGTTTTTTTTCTCTTATCAATTTAGTTTATGTAATCAGGCATCTGCCTGAATCAGTTAGATGGATTGAAGAAGTCGATGTAATAGATTGTAAAGATGATATAAAAATACTTCTTTATTAA |
|
Protein Sequence
|
MDSRTGESLSHAQITRAAEFFNNPMSVGQTAPFHLRLIYVHTNNINTKKVIKLQLQVNHRNRREIGFQKIFLQFRIVTTQLTGVIPSWTGILQRLKWHICNSLASLGFFSLINLVYVIRHLPESVRWIEEVDVIDCKDDIKILLY |
|
NCBI Accession
|
YP_004339040.1
|
|
Location
|
1168-1617 |
|
Gene Name
|
Trap |
|
Protein Name
|
trans-activating protein |
|
Coding Region
|
ATGTCCAATCTCCCTTCTGGATACAAGAGGAAGTGTCCCATTCAGGAACCTCTGCACACAGCGGCGAAGAAGGCCAAGAGGAAGGCTCCTGAGCAAAGGACAAGGATAGTGTGGAAGGGCTGTGGTTGTTCAGCCTTCATCACCAACGCCTGCAAGTTCCAACATGGATTCACGCACCGGGGAGTCACTAAGTCATGCACAGATTACGAGAGCAGCAGAATTCTTCAACAATCCCATGTCTGTGGGTCAGACTGCTCCATTCCATCTACGACTGATATATGTCCATACCAACAACATCAACACAAAGAAGGTCATCAAGTTGCAGCTTCAAGTCAACCACAGGAACAGGAGGGAAATTGGATTCCAGAAGATCTTCCTCCAATTCCGAATAGTAACAACCCAGCTGACTGGTGTTATTCCCAGTTGGACTGGTATTTTGCAACGCCTTAA |
|
Protein Sequence
|
MSNLPSGYKRKCPIQEPLHTAAKKAKRKAPEQRTRIVWKGCGCSAFITNACKFQHGFTHRGVTKSCTDYESSRILQQSHVCGSDCSIPSTTDICPYQQHQHKEGHQVAASSQPQEQEGNWIPEDLPPIPNSNNPADWCYSQLDWYFATP |
|
NCBI Accession
|
YP_004339041.1
|
|
Location
|
1526-2620 |
|
Gene Name
|
Rep |
|
Protein Name
|
replication-associated protein |
|
Coding Region
|
ATGCCTAGAGCCGGGCGTTTTAATATAAAAGCAAAAAACTATTTCCTCACATATCCCCAATGCTCTCTCACCAAAGAAGAAGCTCTCGACCAGCTTCGTAACCTCAACACCCCAACCAACAAAAAATTCATAAAAATATGCAGAGAGCTGCATGAAAATGGGGAACCTCATCTCCACGTGCTATTGCAGTTCGAAGGGAACTACCAATGCACGAATCAGAGATTCTTCGACCTTGTATCACCATCAAGGTCGGCTCACTTTCACCCCAATATCCAGAGAGCTAAATCCAGCTCCGATGTCAAGTCCTATGTCGATAAGGACGGTGACACAATTGAATGGGGTGAATTCCAGGTCGACGGCAGATCTGCTCGAGGAGGCCAGCAGACGGCTAATGACGCAGCAGCAGAGGCCTTAAACTCAGGAAGTAAAGAAGCTGCCTTACAAATTATCAGGGAAAAACTCCCTGAGAAATTTATTTTTCAATACCACAATTTATGTGGTAATTTAGATAGGATTTTTTCTCCTCCTCCTTCTGTATATTCTTCACCTTTTTTATCTTCTTCTTTCAATAATGTTCCTGACATTATCAGCGATTGGGCTGCTGAAAATGTCATGGATTCCGCTGCGCGGCCAGATAGGCCCATAAGTATTGTAATAGAAGGCCCAAGTAGGATAGGTAAAACAGTTTGGGCTAGGTCTTTAGGTCCACATAATTATCTGTGTGGTCATTTAGATCTGAGTCCAAAAGTGTATAGCAACAGTGCTTGGTATAACATCATTGATGACGTCAACCCCCAATACCTAAAGCACTTTAAAGAATTCATGGGGGCCCAGAAGGACTGGCAATCCAACTGTAAATACGGAAAGCCAGTTCAAATTAAAGGCGGAATTCCCACTATCTTCCTCTGCAATCCAGGAGAGGGTTCCTCATTTAAACTCTGGCTAGACAAACCAGAGCAAGGAGCACTCAAGAATTGGGCAACAGCAAACGCTATATTCTGCGATGTCCAATCTCCCTTCTGGATACAAGAGGAAGTGTCCCATTCAGGAACCTCTGCACACAGCGGCGAAGAAGGCCAAGAGGAAGGCTCCTGA |
|
Protein Sequence
|
MPRAGRFNIKAKNYFLTYPQCSLTKEEALDQLRNLNTPTNKKFIKICRELHENGEPHLHVLLQFEGNYQCTNQRFFDLVSPSRSAHFHPNIQRAKSSSDVKSYVDKDGDTIEWGEFQVDGRSARGGQQTANDAAAEALNSGSKEAALQIIREKLPEKFIFQYHNLCGNLDRIFSPPPSVYSSPFLSSSFNNVPDIISDWAAENVMDSAARPDRPISIVIEGPSRIGKTVWARSLGPHNYLCGHLDLSPKVYSNSAWYNIIDDVNPQYLKHFKEFMGAQKDWQSNCKYGKPVQIKGGIPTIFLCNPGEGSSFKLWLDKPEQGALKNWATANAIFCDVQSPFWIQEEVSHSGTSAHSGEEGQEEGS |
|
NCBI Accession
|
YP_004339042.1
|
|
Location
|
2206-2463 |
|
Gene Name
|
C4 |
|
Protein Name
|
C4 |
|
Coding Region
|
ATGGGGAACCTCATCTCCACGTGCTATTGCAGTTCGAAGGGAACTACCAATGCACGAATCAGAGATTCTTCGACCTTGTATCACCATCAAGGTCGGCTCACTTTCACCCCAATATCCAGAGAGCTAAATCCAGCTCCGATGTCAAGTCCTATGTCGATAAGGACGGTGACACAATTGAATGGGGTGAATTCCAGGTCGACGGCAGATCTGCTCGAGGAGGCCAGCAGACGGCTAATGACGCAGCAGCAGAGGCCTTAA |
|
Protein Sequence
|
MGNLISTCYCSSKGTTNARIRDSSTLYHHQGRLTFTPISRELNPAPMSSPMSIRTVTQLNGVNSRSTADLLEEASRRLMTQQQRP |