Bean yellow mosaic Mexico virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_000893575.1 |
| Isolate |
Mexico |
| Release date |
2015/2/22 |
| Submitter |
Idris,A.M., Brown,J.K. |
| Host |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
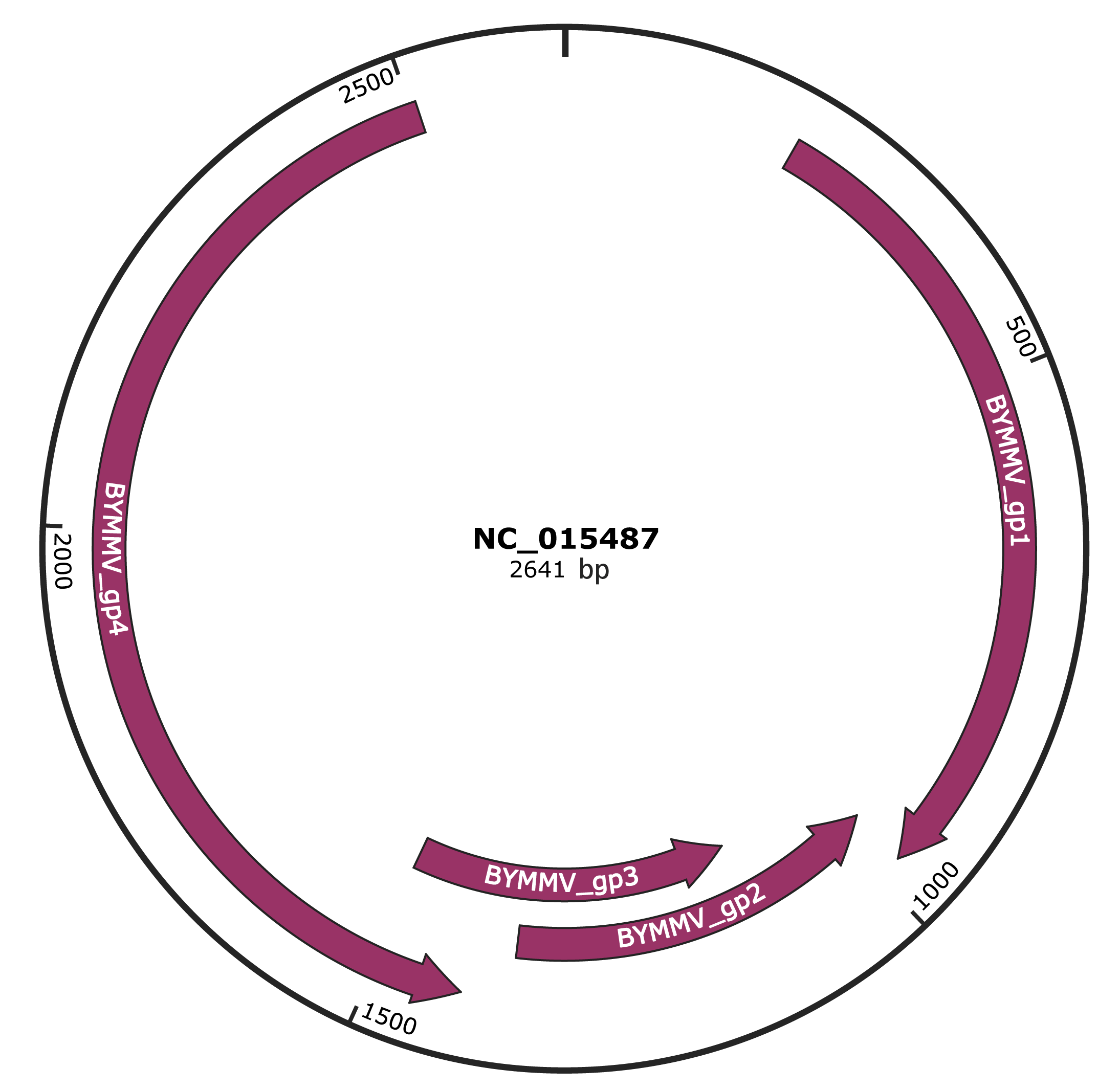
JBrowse
Genome
ACCGGATGGCCGCGCGATTTTTTTCCCCCCCACGTGGACGCTCGCGATTTTCTCCCCTCGCGCGTACCTTCCTCTTTAATTTGAATTAAAGGGTACCCGTTTTTTGGACCAATCGTTTTGCTCGCTGGCAGCTTAGATATTATTAACAACTTGGTGACCAAGTTGTTGGGTGACCGTTATAAATTAAAGAGGCTTGTGGCCCACTGACTTTAATTCAAAATGCCTAAGCGCGATCTACCATGGCGCTCGATCGCGGGAACATCGAAGGTGAGCCGCAATGTCAATTATTCCCCTCGTGGAGGAAGTGGGCCAAGAACCACCAAGGCCTCTGAATGGGTAAACAGGCCCATGTACAGGAAGCCCAGGATCTACCGGACGCTAAGGACGCCCGACGTGCCACGAGGCTGTGAAGGCCCCTGCAAGGTACAGTCTTACGAACAGCGTCATGATATCTCTCATACTGGGAAGGTGATGTGTATATCCGATGTGACACGTGGTAATGGTATTACGCACCGTGTCGGTAAACGTTTTTGTGTTAAGTCTGTGTACATATTAGGTAAAGTCTGGATGGACGAGAACATCAAGTTGAAGAACCACACGAACAGCGTCATGTTCTGGTTGGTTAGGGACCGTAGACCGTATGGAACTCCTATGGATTTCGGACAGGTGTTCAACATGTTCGACAACGAGCCTAGTACCGCTACTGTGAAGAACGATCTCCGTGATCGTTATCAGGTCATGCACAAGTTCTACGCCAAGGTTACAGGTGGACAGTATGCTAGCAACGAGCAGGCATTGGTCAAGCGTTTCTGGAAGGTGAACAATCACGTTGTGTATAACCACCAAGAAGCTGGGAAGTATGAGAATCATACGGAGAACGCTCTGTTATTGTATATGGCATGTACTCATGCCTCTAACCCTGTATATGCAACGCTTAAGATCCGGATCTACTTCTACGATTCGATCATGAATTAATAAAGTTTGAATTTTATTGAATGATTCTCGAGAACATAATTTACATACGACCTGGCTGTTGCGAAACGAACAGCTCTGATTACATTGTTAATGGAAATAACGCCTAATCTATCTAAATACATATTAACTAAGAATCTAAACCTAGCTAAATAGGTCGACCCAGAAGCTGTCGTCGATGTCGTCCAGACTTGGAAGTTCAGGTAGGCTTTGTGGAGATGCAACGCTCTCCTCAGGTTGTGGTTGAACCGTATCTGAACGTGGAACACCCTGGTTCTCGTATACAGTGGATCCTCTACTCTGTACATCCTGAAATAGAGGGGATTTTCTATCTCCCAGATATACACGCCATTCTCCGCCTGAGGTACAGTGATGAATTCCCCTGTGCGTGAATCCATGTCCCGTGCAGCCTATGTGGAAATATATGGAGCACCCGCACCGTAAATCAATCCGCCTCCTCCTGATGGCCCTCCTCTTGGCTTGCCTGTGCGCTGTCTTGATAGAGGGCGGATGTGAGGGTGATGAAGACCGCATTCTTGATGGTCCAGTTCCTCAATGATGCGTTTTCATCTTTGTTGAGGAAATCTTTATAGCTAGCACCCTCACCAGGATTGCAAAGCACGATTGATGGGATCCCGCCTTTAATTTGAACTGGCTTGCCGTACTTACAATTTGATTGCCAGTCCTTTTGGGCCCCAATCAATTCTTTCCAGTGCTTTAGCTTTAGATAGTGCGGTGCGACGTCATCAATGACGTTATACTCCACTTCGTTTTGGTACACTCGAGCATTGAAATCCAGGTGTCCACTAAGATAATTATGTGGGCCCAAAGCACGAGCCCACATTGTCTTCCCCGTTCTTGAATCACCTTCGACGATGATACTTACTGGCCTCTCCGGCCGCGCAGAGGCACCACTTCCAAAATACTGATCAGCCCATTCTTGCATCTCGTCCGGGACGTTAGTGAAGGAAGAGAGGGGAAACGGCGGAACCCACGGTTCCGGAGCCTTTGCGAAGATCCTCTCAAGGTTGGCCTTGAGATTGTGAAAATCTCTCACAAAGTCTCTAGGTTGTTCCTCCTTTAAAATTTGGAGTGCTTGTTGCACTCCGCCGGCGTTCAATGCCTTGGCGTATGAATCGTTAACAGTCTGCTTGCCTCCTCTAGCAGATCTGCCGTCGATCTGGAATTCGCCCCATTCCAGGGTATCTCCGTCCTTCTCGACATAGGACTTGACGTCGGAGCTTGATTCAGCTCCCTGATAATTTCCATGGAAATGGGATGATCTTGAAGGGGATACCAGGTCGAAGAATCTGTAATTCTGTGTTTTGAATTTCCCTTCGAACTGGATGAGCACGTGGAGATGAGGATTCCCATTTTCATGCAGCTCTCTGCAGATCTTAATATATTTCTTGTTTGTTGGGGTGTTTAATGCTAACAATTGGGAAAGTGTTTCCTCTTTGGTTAGGGAACACTGGGGATATGTGAGGAAATAGTTTTTGGCGTTAATAAGGAATTTCCTAGGAGCGGATGGCATTTTTGTAATAATGGGAGGTGAACCCAATTCAGGTCTCTCACAAAACTCTGTAGAATTGGGTCTATTGGGTTCTTATTTATACTAGAACCTCAGATAGCGCTAGTGGGGCACGTGGCGGCCATCCGCTATAATATT
Gene Information
|
NCBI Accession
|
YP_004429232.1
|
|
Location
|
220-975 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGCCTAAGCGCGATCTACCATGGCGCTCGATCGCGGGAACATCGAAGGTGAGCCGCAATGTCAATTATTCCCCTCGTGGAGGAAGTGGGCCAAGAACCACCAAGGCCTCTGAATGGGTAAACAGGCCCATGTACAGGAAGCCCAGGATCTACCGGACGCTAAGGACGCCCGACGTGCCACGAGGCTGTGAAGGCCCCTGCAAGGTACAGTCTTACGAACAGCGTCATGATATCTCTCATACTGGGAAGGTGATGTGTATATCCGATGTGACACGTGGTAATGGTATTACGCACCGTGTCGGTAAACGTTTTTGTGTTAAGTCTGTGTACATATTAGGTAAAGTCTGGATGGACGAGAACATCAAGTTGAAGAACCACACGAACAGCGTCATGTTCTGGTTGGTTAGGGACCGTAGACCGTATGGAACTCCTATGGATTTCGGACAGGTGTTCAACATGTTCGACAACGAGCCTAGTACCGCTACTGTGAAGAACGATCTCCGTGATCGTTATCAGGTCATGCACAAGTTCTACGCCAAGGTTACAGGTGGACAGTATGCTAGCAACGAGCAGGCATTGGTCAAGCGTTTCTGGAAGGTGAACAATCACGTTGTGTATAACCACCAAGAAGCTGGGAAGTATGAGAATCATACGGAGAACGCTCTGTTATTGTATATGGCATGTACTCATGCCTCTAACCCTGTATATGCAACGCTTAAGATCCGGATCTACTTCTACGATTCGATCATGAATTAA |
|
Protein Sequence
|
MPKRDLPWRSIAGTSKVSRNVNYSPRGGSGPRTTKASEWVNRPMYRKPRIYRTLRTPDVPRGCEGPCKVQSYEQRHDISHTGKVMCISDVTRGNGITHRVGKRFCVKSVYILGKVWMDENIKLKNHTNSVMFWLVRDRRPYGTPMDFGQVFNMFDNEPSTATVKNDLRDRYQVMHKFYAKVTGGQYASNEQALVKRFWKVNNHVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSIMN |
|
NCBI Accession
|
YP_004429233.1
|
|
Location
|
972-1370 |
|
Protein Name
|
REn |
|
Coding Region
|
ATGGATTCACGCACAGGGGAATTCATCACTGTACCTCAGGCGGAGAATGGCGTGTATATCTGGGAGATAGAAAATCCCCTCTATTTCAGGATGTACAGAGTAGAGGATCCACTGTATACGAGAACCAGGGTGTTCCACGTTCAGATACGGTTCAACCACAACCTGAGGAGAGCGTTGCATCTCCACAAAGCCTACCTGAACTTCCAAGTCTGGACGACATCGACGACAGCTTCTGGGTCGACCTATTTAGCTAGGTTTAGATTCTTAGTTAATATGTATTTAGATAGATTAGGCGTTATTTCCATTAACAATGTAATCAGAGCTGTTCGTTTCGCAACAGCCAGGTCGTATGTAAATTATGTTCTCGAGAATCATTCAATAAAATTCAAACTTTATTAA |
|
Protein Sequence
|
MDSRTGEFITVPQAENGVYIWEIENPLYFRMYRVEDPLYTRTRVFHVQIRFNHNLRRALHLHKAYLNFQVWTTSTTASGSTYLARFRFLVNMYLDRLGVISINNVIRAVRFATARSYVNYVLENHSIKFKLY |
|
NCBI Accession
|
YP_004429234.1
|
|
Location
|
1117-1506 |
|
Protein Name
|
TrAP |
|
Coding Region
|
ATGCGGTCTTCATCACCCTCACATCCGCCCTCTATCAAGACAGCGCACAGGCAAGCCAAGAGGAGGGCCATCAGGAGGAGGCGGATTGATTTACGGTGCGGGTGCTCCATATATTTCCACATAGGCTGCACGGGACATGGATTCACGCACAGGGGAATTCATCACTGTACCTCAGGCGGAGAATGGCGTGTATATCTGGGAGATAGAAAATCCCCTCTATTTCAGGATGTACAGAGTAGAGGATCCACTGTATACGAGAACCAGGGTGTTCCACGTTCAGATACGGTTCAACCACAACCTGAGGAGAGCGTTGCATCTCCACAAAGCCTACCTGAACTTCCAAGTCTGGACGACATCGACGACAGCTTCTGGGTCGACCTATTTAGCTAG |
|
Protein Sequence
|
MRSSSPSHPPSIKTAHRQAKRRAIRRRRIDLRCGCSIYFHIGCTGHGFTHRGIHHCTSGGEWRVYLGDRKSPLFQDVQSRGSTVYENQGVPRSDTVQPQPEESVASPQSLPELPSLDDIDDSFWVDLFS |
|
NCBI Accession
|
YP_004429235.1
|
|
Location
|
1418-2506 |
|
Protein Name
|
Rep |
|
Coding Region
|
ATGCCATCCGCTCCTAGGAAATTCCTTATTAACGCCAAAAACTATTTCCTCACATATCCCCAGTGTTCCCTAACCAAAGAGGAAACACTTTCCCAATTGTTAGCATTAAACACCCCAACAAACAAGAAATATATTAAGATCTGCAGAGAGCTGCATGAAAATGGGAATCCTCATCTCCACGTGCTCATCCAGTTCGAAGGGAAATTCAAAACACAGAATTACAGATTCTTCGACCTGGTATCCCCTTCAAGATCATCCCATTTCCATGGAAATTATCAGGGAGCTGAATCAAGCTCCGACGTCAAGTCCTATGTCGAGAAGGACGGAGATACCCTGGAATGGGGCGAATTCCAGATCGACGGCAGATCTGCTAGAGGAGGCAAGCAGACTGTTAACGATTCATACGCCAAGGCATTGAACGCCGGCGGAGTGCAACAAGCACTCCAAATTTTAAAGGAGGAACAACCTAGAGACTTTGTGAGAGATTTTCACAATCTCAAGGCCAACCTTGAGAGGATCTTCGCAAAGGCTCCGGAACCGTGGGTTCCGCCGTTTCCCCTCTCTTCCTTCACTAACGTCCCGGACGAGATGCAAGAATGGGCTGATCAGTATTTTGGAAGTGGTGCCTCTGCGCGGCCGGAGAGGCCAGTAAGTATCATCGTCGAAGGTGATTCAAGAACGGGGAAGACAATGTGGGCTCGTGCTTTGGGCCCACATAATTATCTTAGTGGACACCTGGATTTCAATGCTCGAGTGTACCAAAACGAAGTGGAGTATAACGTCATTGATGACGTCGCACCGCACTATCTAAAGCTAAAGCACTGGAAAGAATTGATTGGGGCCCAAAAGGACTGGCAATCAAATTGTAAGTACGGCAAGCCAGTTCAAATTAAAGGCGGGATCCCATCAATCGTGCTTTGCAATCCTGGTGAGGGTGCTAGCTATAAAGATTTCCTCAACAAAGATGAAAACGCATCATTGAGGAACTGGACCATCAAGAATGCGGTCTTCATCACCCTCACATCCGCCCTCTATCAAGACAGCGCACAGGCAAGCCAAGAGGAGGGCCATCAGGAGGAGGCGGATTGA |
|
Protein Sequence
|
MPSAPRKFLINAKNYFLTYPQCSLTKEETLSQLLALNTPTNKKYIKICRELHENGNPHLHVLIQFEGKFKTQNYRFFDLVSPSRSSHFHGNYQGAESSSDVKSYVEKDGDTLEWGEFQIDGRSARGGKQTVNDSYAKALNAGGVQQALQILKEEQPRDFVRDFHNLKANLERIFAKAPEPWVPPFPLSSFTNVPDEMQEWADQYFGSGASARPERPVSIIVEGDSRTGKTMWARALGPHNYLSGHLDFNARVYQNEVEYNVIDDVAPHYLKLKHWKELIGAQKDWQSNCKYGKPVQIKGGIPSIVLCNPGEGASYKDFLNKDENASLRNWTIKNAVFITLTSALYQDSAQASQEEGHQEEAD |