Sweet potato leaf curl Hubei virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_013088085.1 |
| Isolate |
China |
| Release date |
2021/6/1 |
| Submitter |
Wang,Y., Zhang,Z., Qiao,Q., Qin,Y., Zhang,D., Wang,S., Tian,Y., Zhao,F. |
| Host |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
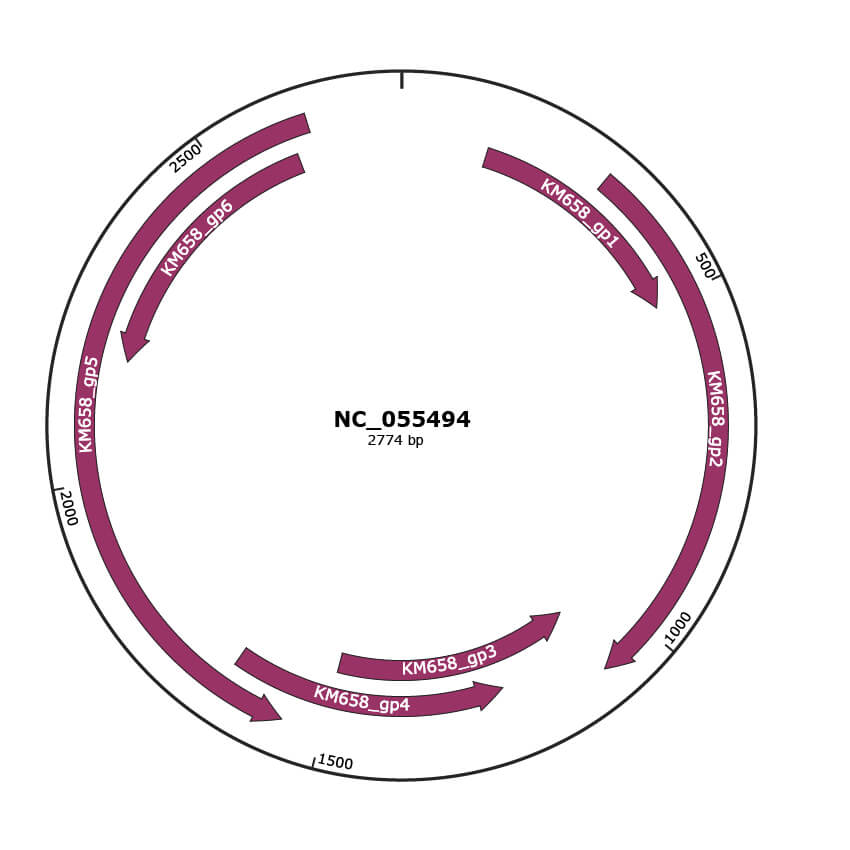
JBrowse
Genome
ACCGGATGGCCGCGCCCGCTTTTATGTGGGCCCCAACCACGTGAAAAAAGAAAAAGAATGAATAATTGTGGACCCCACAATTTGGAGATAAGGTTAAAAGCATCCATTCAGATTGCAATCCTTGGTCATCAAGGATGGAGCAGTCATTGTGGGACCCTCTCACTCATCCTTTACCAGAAACCCTTCACGGGTTTAGGTGTATGCTTTCGTTAAAGTATATGTCCAATATACGTGACAAATACGAGCCGGGTACGTTAGGGCACGAATTAGCCGTTCTGCTAATTCGATCTCTTAGGGGAAAGAATTATGTCAGATCGACTTCGAGTTACGAGGAGGTATGCGCCTTACTCTCGGAGACCGCAGGCAGCTCGCCGTCTAAACTTCACGACAGACATCGTCCCGTATGTGGGGAATGCTGCCCCGCTTGCTGCAGCAACGTACGTTCCAGTTCCTGTGAAGGCAAGGAAGCGGACCTCTCGAAAGAGAGGCGATTGGATTCCTAGGGGCTGTGTTGGCCCCTGTAAGGTTCAGGATTATGAGTTCAAGATGGATGTTCCTCACGGGGGGACCTTTGTTTGTGTTTCTGATTTTACTCGTGGTACTGGTCTTACTCATCGTCTGGGCAAGCGTGTTTGTATTAAGTCTATGGGGTTTTCTGGAAAGGTTTGGATGGATGACAACATCGCTAAGAAGGATCATACGAATATAATTACGTTTTGGTTAGTTAGGGATCGGCGTCCTAACAAGGACCCGCTCACGTTTAGTCAGTTGTTTCACATGTTTGATAACGAACCCTTGACAGCCAAGGTTCGTACCGATCTTCGTGATCGGTTTCAGGTGTTGCGTACGTTTTCTGTTACGGTTAGTGGTGGTCCTTATGCCCATAAGGAGCAGGCTCAGGTTAGGCGTTTCTTCAAGGGTCTTAACAACCATGTGATTTACAATCACAAGGAGGAGGCGAAGTATGAGAATCAGTTAGAGAATGCTATGCTTGTGTACTCTGCTAGCAGTCATGCTAGCAATCCTGTGTATCAATCTTTAAGAGTTCGAGCATATTTTTATGACTCGCATATGAATTAATATAAAAGTGTTTGTATTGAATCCTTACAATCTATTACATCAATGTCATGTATCCAGCTTACATTTTTCAATTGCCAGATTGCCATGACTAAAGTACTCAAACTTAAAAAACCTATGCTAGCTAAGTTATCACAAATTCGCCATTTAAGGCGAGAAATCAAGCTGTGAATAACAAAATTGGGATGCCCATGAATAATCCGGAATTGGAGAAAGATCTTCTGGTACCCTATGCTCCTCCTTGGGCTGTGGTTCAGTTGAAGCTGAACCTTCATGATCTGTTTCCCGCTGCTTGACGTGTGTATGTACATCACACGCAGGTGGAATGGTGCAGTCCGACCCGCACTCATGGGATTGCTGTCGAATTCGACAGCTCTCCCAGTCTGTACAAGACTTAGTAACGCCCCTGTGCGTGAATCCATGGATGAACTTGCAGTCTGGGCTAATGAAGGCTGTGCACCCGCAGCCGAACCAGGTTATCCTAGTCCTCGGTTCCCTGTACTTCCTCTTCTGGGGTGCTGGTGGAGGGGACAGACTCCTTTCTGTACAGGTTCTCTTCAATGGAGTAGAATATTGCATTCTTATGTGTCCACTGGTAGAGACCGAAGTTCTCTGCCTTCTCAAGATAAGACTTATAAGAAGCGCCTTCTCCTGGATTGCAGAGTACGATTGCTGGGATTCCGCCTTTAATTTGAACTGGCTTTCCGTATTTACAGTTAGATTGCCAGTCCTTCTGGGCCCCTATTAGCTCCTTAAAGTGCTTTAGGTAATGCGGGTTGACGTCATCAATGACGTTATACCACGCATCATTACTGTACACCTTAGGAGAAAGATCCAGATGACCGCATAAGTAATTATGCGGTCCCAAAGAGCGAGCCCAAACTGTTTTGCCCAATCTACTTGGGCCTTCTAATATCAAGCTCATGGGCCTCTCCGGCCGCGCAGCGGGATCCTTCACATTATTGTTGGCCCAGTCCAACAACACACGAGGTAAAACAAACGAAGAAGAAGGGAAAGGATGTACATATGTTTCTGGGGGAGGAGCAAAAATGCGTTCATAATTTGCACTCAAATTATGAAATTGAAGAGTAAAATCCCTTGGTGCTAACTCCCGTATAATTCTGAGAGCCTCTGACTTACTGCCTGCGTTAAGAGCTGCGGCGTAAGCGTCATTGGCTGATTGTTGTCCTCCCCTTGCAGATCGTCCATCAATCTGGAATTCGCCCCATTCAATTGTGTCTCCATCCTTATCGATGTAGGACTTGACGTCGGAACTGGATTTAGCTCCCTGAATGTTTGGATGGAAATGTGCTGACCTGGTAGGGGAGACCAGATCGAAGAATCTGTTATTTTTGCATTGGAATTTCCCCTCGAACTGAAGAAGCACGTGGAGATGAGGGCTCCCATCTTCGTGAAGCTCTCTACAGATTTTGATGAATTTTTTATTAACTGGGGTTTGGATGTTTTGGATTTGCTGTAGTGCTTCTTCTTTGGATAGAGAACACTGAGGATATGTAAGAAAATAATTCTTAGCATTTATGCGAAAACGATTAGGTGTAGGCATTTTGACTTGGTCAATCGGTGTCTCTCGCTCACCTTTGCTCTGGCAATTGGTGTCTGGTGTCCCATTTATACTCGTTGTGTCTAAAATTCGAAATTCGAATTTGAGCTCCAAAAGCGGCCATCCGTATAATATT
Gene Information
|
NCBI Accession
|
YP_010086848.1
|
|
Location
|
135-503 |
|
Protein Name
|
AV2 |
|
Coding Region
|
ATGGAGCAGTCATTGTGGGACCCTCTCACTCATCCTTTACCAGAAACCCTTCACGGGTTTAGGTGTATGCTTTCGTTAAAGTATATGTCCAATATACGTGACAAATACGAGCCGGGTACGTTAGGGCACGAATTAGCCGTTCTGCTAATTCGATCTCTTAGGGGAAAGAATTATGTCAGATCGACTTCGAGTTACGAGGAGGTATGCGCCTTACTCTCGGAGACCGCAGGCAGCTCGCCGTCTAAACTTCACGACAGACATCGTCCCGTATGTGGGGAATGCTGCCCCGCTTGCTGCAGCAACGTACGTTCCAGTTCCTGTGAAGGCAAGGAAGCGGACCTCTCGAAAGAGAGGCGATTGGATTCCTAG |
|
Protein Sequence
|
MEQSLWDPLTHPLPETLHGFRCMLSLKYMSNIRDKYEPGTLGHELAVLLIRSLRGKNYVRSTSSYEEVCALLSETAGSSPSKLHDRHRPVCGECCPACCSNVRSSSCEGKEADLSKERRLDS |
|
NCBI Accession
|
YP_010086849.1
|
|
Location
|
307-1080 |
|
Protein Name
|
AV1 |
|
Coding Region
|
ATGTCAGATCGACTTCGAGTTACGAGGAGGTATGCGCCTTACTCTCGGAGACCGCAGGCAGCTCGCCGTCTAAACTTCACGACAGACATCGTCCCGTATGTGGGGAATGCTGCCCCGCTTGCTGCAGCAACGTACGTTCCAGTTCCTGTGAAGGCAAGGAAGCGGACCTCTCGAAAGAGAGGCGATTGGATTCCTAGGGGCTGTGTTGGCCCCTGTAAGGTTCAGGATTATGAGTTCAAGATGGATGTTCCTCACGGGGGGACCTTTGTTTGTGTTTCTGATTTTACTCGTGGTACTGGTCTTACTCATCGTCTGGGCAAGCGTGTTTGTATTAAGTCTATGGGGTTTTCTGGAAAGGTTTGGATGGATGACAACATCGCTAAGAAGGATCATACGAATATAATTACGTTTTGGTTAGTTAGGGATCGGCGTCCTAACAAGGACCCGCTCACGTTTAGTCAGTTGTTTCACATGTTTGATAACGAACCCTTGACAGCCAAGGTTCGTACCGATCTTCGTGATCGGTTTCAGGTGTTGCGTACGTTTTCTGTTACGGTTAGTGGTGGTCCTTATGCCCATAAGGAGCAGGCTCAGGTTAGGCGTTTCTTCAAGGGTCTTAACAACCATGTGATTTACAATCACAAGGAGGAGGCGAAGTATGAGAATCAGTTAGAGAATGCTATGCTTGTGTACTCTGCTAGCAGTCATGCTAGCAATCCTGTGTATCAATCTTTAAGAGTTCGAGCATATTTTTATGACTCGCATATGAATTAA |
|
Protein Sequence
|
MSDRLRVTRRYAPYSRRPQAARRLNFTTDIVPYVGNAAPLAAATYVPVPVKARKRTSRKRGDWIPRGCVGPCKVQDYEFKMDVPHGGTFVCVSDFTRGTGLTHRLGKRVCIKSMGFSGKVWMDDNIAKKDHTNIITFWLVRDRRPNKDPLTFSQLFHMFDNEPLTAKVRTDLRDRFQVLRTFSVTVSGGPYAHKEQAQVRRFFKGLNNHVIYNHKEEAKYENQLENAMLVYSASSHASNPVYQSLRVRAYFYDSHMN |
|
NCBI Accession
|
YP_010086850.1
|
|
Location
|
1077-1499 |
|
Protein Name
|
AC3 |
|
Coding Region
|
ATGGATTCACGCACAGGGGCGTTACTAAGTCTTGTACAGACTGGGAGAGCTGTCGAATTCGACAGCAATCCCATGAGTGCGGGTCGGACTGCACCATTCCACCTGCGTGTGATGTACATACACACGTCAAGCAGCGGGAAACAGATCATGAAGGTTCAGCTTCAACTGAACCACAGCCCAAGGAGGAGCATAGGGTACCAGAAGATCTTTCTCCAATTCCGGATTATTCATGGGCATCCCAATTTTGTTATTCACAGCTTGATTTCTCGCCTTAAATGGCGAATTTGTGATAACTTAGCTAGCATAGGTTTTTTAAGTTTGAGTACTTTAGTCATGGCAATCTGGCAATTGAAAAATGTAAGCTGGATACATGACATTGATGTAATAGATTGTAAGGATTCAATACAAACACTTTTATATTAA |
|
Protein Sequence
|
MDSRTGALLSLVQTGRAVEFDSNPMSAGRTAPFHLRVMYIHTSSSGKQIMKVQLQLNHSPRRSIGYQKIFLQFRIIHGHPNFVIHSLISRLKWRICDNLASIGFLSLSTLVMAIWQLKNVSWIHDIDVIDCKDSIQTLLY |
|
NCBI Accession
|
YP_010086851.1
|
|
Location
|
1225-1656 |
|
Protein Name
|
AC2 |
|
Coding Region
|
ATGCAATATTCTACTCCATTGAAGAGAACCTGTACAGAAAGGAGTCTGTCCCCTCCACCAGCACCCCAGAAGAGGAAGTACAGGGAACCGAGGACTAGGATAACCTGGTTCGGCTGCGGGTGCACAGCCTTCATTAGCCCAGACTGCAAGTTCATCCATGGATTCACGCACAGGGGCGTTACTAAGTCTTGTACAGACTGGGAGAGCTGTCGAATTCGACAGCAATCCCATGAGTGCGGGTCGGACTGCACCATTCCACCTGCGTGTGATGTACATACACACGTCAAGCAGCGGGAAACAGATCATGAAGGTTCAGCTTCAACTGAACCACAGCCCAAGGAGGAGCATAGGGTACCAGAAGATCTTTCTCCAATTCCGGATTATTCATGGGCATCCCAATTTTGTTATTCACAGCTTGATTTCTCGCCTTAA |
|
Protein Sequence
|
MQYSTPLKRTCTERSLSPPPAPQKRKYREPRTRITWFGCGCTAFISPDCKFIHGFTHRGVTKSCTDWESCRIRQQSHECGSDCTIPPACDVHTHVKQRETDHEGSASTEPQPKEEHRVPEDLSPIPDYSWASQFCYSQLDFSP |
|
NCBI Accession
|
YP_010086852.1
|
|
Location
|
1559-2641 |
|
Protein Name
|
AC1 |
|
Coding Region
|
ATGCCTACACCTAATCGTTTTCGCATAAATGCTAAGAATTATTTTCTTACATATCCTCAGTGTTCTCTATCCAAAGAAGAAGCACTACAGCAAATCCAAAACATCCAAACCCCAGTTAATAAAAAATTCATCAAAATCTGTAGAGAGCTTCACGAAGATGGGAGCCCTCATCTCCACGTGCTTCTTCAGTTCGAGGGGAAATTCCAATGCAAAAATAACAGATTCTTCGATCTGGTCTCCCCTACCAGGTCAGCACATTTCCATCCAAACATTCAGGGAGCTAAATCCAGTTCCGACGTCAAGTCCTACATCGATAAGGATGGAGACACAATTGAATGGGGCGAATTCCAGATTGATGGACGATCTGCAAGGGGAGGACAACAATCAGCCAATGACGCTTACGCCGCAGCTCTTAACGCAGGCAGTAAGTCAGAGGCTCTCAGAATTATACGGGAGTTAGCACCAAGGGATTTTACTCTTCAATTTCATAATTTGAGTGCAAATTATGAACGCATTTTTGCTCCTCCCCCAGAAACATATGTACATCCTTTCCCTTCTTCTTCGTTTGTTTTACCTCGTGTGTTGTTGGACTGGGCCAACAATAATGTGAAGGATCCCGCTGCGCGGCCGGAGAGGCCCATGAGCTTGATATTAGAAGGCCCAAGTAGATTGGGCAAAACAGTTTGGGCTCGCTCTTTGGGACCGCATAATTACTTATGCGGTCATCTGGATCTTTCTCCTAAGGTGTACAGTAATGATGCGTGGTATAACGTCATTGATGACGTCAACCCGCATTACCTAAAGCACTTTAAGGAGCTAATAGGGGCCCAGAAGGACTGGCAATCTAACTGTAAATACGGAAAGCCAGTTCAAATTAAAGGCGGAATCCCAGCAATCGTACTCTGCAATCCAGGAGAAGGCGCTTCTTATAAGTCTTATCTTGAGAAGGCAGAGAACTTCGGTCTCTACCAGTGGACACATAAGAATGCAATATTCTACTCCATTGAAGAGAACCTGTACAGAAAGGAGTCTGTCCCCTCCACCAGCACCCCAGAAGAGGAAGTACAGGGAACCGAGGACTAG |
|
Protein Sequence
|
MPTPNRFRINAKNYFLTYPQCSLSKEEALQQIQNIQTPVNKKFIKICRELHEDGSPHLHVLLQFEGKFQCKNNRFFDLVSPTRSAHFHPNIQGAKSSSDVKSYIDKDGDTIEWGEFQIDGRSARGGQQSANDAYAAALNAGSKSEALRIIRELAPRDFTLQFHNLSANYERIFAPPPETYVHPFPSSSFVLPRVLLDWANNNVKDPAARPERPMSLILEGPSRLGKTVWARSLGPHNYLCGHLDLSPKVYSNDAWYNVIDDVNPHYLKHFKELIGAQKDWQSNCKYGKPVQIKGGIPAIVLCNPGEGASYKSYLEKAENFGLYQWTHKNAIFYSIEENLYRKESVPSTSTPEEEVQGTED |
|
NCBI Accession
|
YP_010086853.1
|
|
Location
|
2182-2613 |
|
Protein Name
|
AC4 |
|
Coding Region
|
ATGCTAAGAATTATTTTCTTACATATCCTCAGTGTTCTCTATCCAAAGAAGAAGCACTACAGCAAATCCAAAACATCCAAACCCCAGTTAATAAAAAATTCATCAAAATCTGTAGAGAGCTTCACGAAGATGGGAGCCCTCATCTCCACGTGCTTCTTCAGTTCGAGGGGAAATTCCAATGCAAAAATAACAGATTCTTCGATCTGGTCTCCCCTACCAGGTCAGCACATTTCCATCCAAACATTCAGGGAGCTAAATCCAGTTCCGACGTCAAGTCCTACATCGATAAGGATGGAGACACAATTGAATGGGGCGAATTCCAGATTGATGGACGATCTGCAAGGGGAGGACAACAATCAGCCAATGACGCTTACGCCGCAGCTCTTAACGCAGGCAGTAAGTCAGAGGCTCTCAGAATTATACGGGAGTTAG |
|
Protein Sequence
|
MLRIIFLHILSVLYPKKKHYSKSKTSKPQLIKNSSKSVESFTKMGALISTCFFSSRGNSNAKITDSSIWSPLPGQHISIQTFRELNPVPTSSPTSIRMETQLNGANSRLMDDLQGEDNNQPMTLTPQLLTQAVSQRLSELYGS |