Sweet potato golden vein Korea virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_003029275.1 |
| Isolate |
South Korea |
| Release date |
2019/6/28 |
| Submitter |
Kim,J., Kwak,H.-R., Kim,M.-K., Seo,J.-K., Kim,C.-S., Lee,G.-S., Choi,H.-S. |
| Host |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
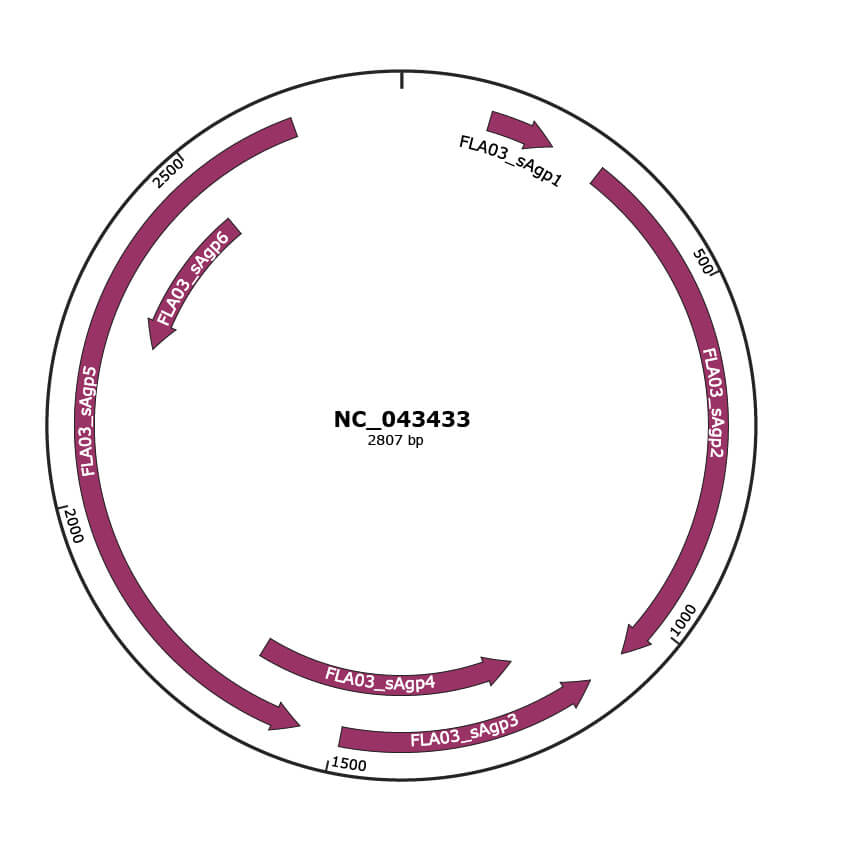
JBrowse
Genome
ACCGGTGCCCGCCGCGCCCTTTAAAAGTGGGCCCCACTAGGGAACCACGCGTCTTTTCCGTACTGTCCTTTAATGATTACTTTGCTTTATAAGGACCAATCAGGTTTCCGTGCTTGGGCGCCAAGAATGGAGCAGTTGTGGGACCCTTTGCAGAACCCACTCCCGGATACTTTATACGGTTTTAGGTGTATGCTATCCGTAAAATACTTGCAGAGTATTTGAAGAAATACGAGCCAGGAACCCTTAGGGTTTCGAGCTCTGTTCGGAGTTAATCCGTATATTCAGGGTCAGGCAGTATGACAGGGCGAATTCCCGTTTCGCGGAGATTTCATCCATATGGGGGGAGACCGGTAAGACGGAGGCTGAACTTCGAGACAGCTATCGTGCCCTACACTGGGAGTGCTGTCCCAATTGCTGCCCGAAGCTATGTCCCGGTTTCAAGAGGCGTCCGGATGAAGAGAAAGAGGGGTGACCGCATCCCGAAGGGATGTGTTGGTCCCTGTAAGGTCCAGGACTATGAGTTCAAGATGGACGTTCCCCACACGGGAACGTTTGTCTGTGTCTCGGATTTTACTAGGGGAACTGGGCTTACCCATCGCCTGGGTAAGCGTGTTTGTGTGAAGTCAATGGGTATAGATGGGAAGGTCTGGATGGATGACAATGTGGCCAAGAGAGATCACACCAATATCATCACGTATTGGTTGATTCGTGACAGAAGGCCCAATAAGGATCCGCTGAACTTTGGCCAAGTCTTCACTATGTATGACAATGAGCCCACTACTGCTAAGATCCGAATGGATCTGAGGGATAGAATGCAGGTATTGAAGAAGTTCTCTGTTACAGTTTCAGGAGGCCCATACAGTCACAAGGAGCAGGCCTTAGTTAGGAAGTTTTTTAAGGGTTTGTATAACCATGTAACTTACAATCACAAGGAAGAAGCTAAATATGAGAACCATTTAGAAAATGCATTAATGTTGTATTCTGCTAGCAGTCATGCTAGTAATCCTGTGTATCAGACCCTGCGTTGCAGGGCTTATTTTTATGATTCGCATAATAATTAATAAAGAAGCATTTTTATATCATCTGTGCAATCATTTACATCGATTTCATCTACCCATTTACATGTTTTTCGGTAGATTATCTATTACAAAATATAAATTATTTAAACTAAAAAAACCTAAGCTATCTAAATCATTACAAATACGCCATCTAAGGCGAGTTAAAATACCAATCCAACTGTGAGTAGCACCAGTCAGACGGGTTGAAATTATCCGAAACTGCAGGAATATCTTGTGAAAGCCCAGCTGCTTCCTTTCCCTGTAGTTCACCTGAAGTTGGAACTTCAGGATTGTTCTCTTCGATACGCTCTGGTGGGCGTATAAAAATTTGAGGTGAAACGGGAGGCTTGTCTTGTTCCCGGAAGAATTGTTGAACTCGATAGCTCTCATAATCTGTGCAGGACTTAGTAACTCCCCTGTGCGTGAATCCATTCTGGTACTTACATTCGTTTGTTATGAATGCAGAGCAGCCACAGCCCTTCCACACGAGCCTAGTCCTGGGCTCTGGTGCTTTCCTCTTCTTCTTCGCCGCTGCGTGTGCTGGTTCCTGCTCCGGACACTTCCTCTTGAATCCAGAAGGGGTTGTCGACATCACAGAAAACTGCGTTCTTAATAGCCCAGTTCTTAAGTGCTTCTTGTTCTGGCTTGTCCAGCCAGAATTTAAATGAAGACCCCTCTCCTGGATTGCAGAGGAAGATAGTGGGAATTCCACCTTTAATTTGAACTGGCTTTCCGTATTTACAATTGCTTTGCCAGTCCTTCTGGGCCCCCATGAACTCTTTAAAGTGCTTTAGGTATTGGGGGTTTACGTCATCAATGACGTTATACCAAGCACTATTACTATATACCTTTGGACTCAAGTCCAAATGTCCACACAGATAATTATGTGGGCCTAAAGACCGAGCCCAAACTGTTTTACCTATCCTACTTGGGCCTTCTATAACAATACTAATGGGCCTATCTGGCCGCGCAGCGGCATCCATGATGTTATCAGCTGCCCAGTCGCTGATAATGTCAGGTACATTATTGAAAGAAGAAACAGAAAAAGGAGAAGAATATACAGAAGGAGGGGGAGAAAAAATCCTATCTAAATTACTACGTAAATTATGGTATTGAAAAATAAAATCTTTAGGGAGTTTCTCCCTAATTATTTGTAAAGCTGCTTCAGCAGATCCTGCGTTTAAGGCCTCTGCGGCAGCGTCGTTAGCATTCTGCTGACCTCCTCTAGCAGACCTGCCGTCGACCTGGAATTCACCCCAGTCGATGAAATCTCCGTCCTTCTCAATGTATGACTTGACATCTGAAGAGGACTTTGCTGCCTGGAAATTTGGATGGAATTGGGAGGAGTTGTGTGGATGTTGTAGGTCGAAATGTCGTGGGTTTTTGAATTCTGCTTTCCCCCTGAACTGGATGAGAACATGGAGATGCAGAGCCCCATCTTGGTGTTTCTCCTGACTAACTCTGATAAATAGTTTATCAGAAGGACAATTAATTGCCCTTAGTTGTTCAAGAGCTTGCTCTTTAGAGAGAGAGCATTGGGGATAAGTTAAGAAAATGTTTTTAGCTTGGACTCTAAAACCTGGCTTACGTGGCATTTTGAATCGGAGGCTCTCAAAGCTCTACGGAATTGGAGGATTTGGAGGTCCATATATAGTGAGCCTCTAAATGGCATTTTGGTAATTTGAACACCTTTAATTTGAATGCTGAAATCCTATTGGTCCTTCGTAAAGCGGGCACCGTATTAATATT
Gene Information
|
NCBI Accession
|
YP_009666107.1
|
|
Location
|
127-222 |
|
Protein Name
|
truncated V2 |
|
Coding Region
|
ATGGAGCAGTTGTGGGACCCTTTGCAGAACCCACTCCCGGATACTTTATACGGTTTTAGGTGTATGCTATCCGTAAAATACTTGCAGAGTATTTGA |
|
Protein Sequence
|
MEQLWDPLQNPLPDTLYGFRCMLSVKYLQSI |
|
NCBI Accession
|
YP_009666108.1
|
|
Location
|
297-1061 |
|
Protein Name
|
V1 |
|
Coding Region
|
ATGACAGGGCGAATTCCCGTTTCGCGGAGATTTCATCCATATGGGGGGAGACCGGTAAGACGGAGGCTGAACTTCGAGACAGCTATCGTGCCCTACACTGGGAGTGCTGTCCCAATTGCTGCCCGAAGCTATGTCCCGGTTTCAAGAGGCGTCCGGATGAAGAGAAAGAGGGGTGACCGCATCCCGAAGGGATGTGTTGGTCCCTGTAAGGTCCAGGACTATGAGTTCAAGATGGACGTTCCCCACACGGGAACGTTTGTCTGTGTCTCGGATTTTACTAGGGGAACTGGGCTTACCCATCGCCTGGGTAAGCGTGTTTGTGTGAAGTCAATGGGTATAGATGGGAAGGTCTGGATGGATGACAATGTGGCCAAGAGAGATCACACCAATATCATCACGTATTGGTTGATTCGTGACAGAAGGCCCAATAAGGATCCGCTGAACTTTGGCCAAGTCTTCACTATGTATGACAATGAGCCCACTACTGCTAAGATCCGAATGGATCTGAGGGATAGAATGCAGGTATTGAAGAAGTTCTCTGTTACAGTTTCAGGAGGCCCATACAGTCACAAGGAGCAGGCCTTAGTTAGGAAGTTTTTTAAGGGTTTGTATAACCATGTAACTTACAATCACAAGGAAGAAGCTAAATATGAGAACCATTTAGAAAATGCATTAATGTTGTATTCTGCTAGCAGTCATGCTAGTAATCCTGTGTATCAGACCCTGCGTTGCAGGGCTTATTTTTATGATTCGCATAATAATTAA |
|
Protein Sequence
|
MTGRIPVSRRFHPYGGRPVRRRLNFETAIVPYTGSAVPIAARSYVPVSRGVRMKRKRGDRIPKGCVGPCKVQDYEFKMDVPHTGTFVCVSDFTRGTGLTHRLGKRVCVKSMGIDGKVWMDDNVAKRDHTNIITYWLIRDRRPNKDPLNFGQVFTMYDNEPTTAKIRMDLRDRMQVLKKFSVTVSGGPYSHKEQALVRKFFKGLYNHVTYNHKEEAKYENHLENALMLYSASSHASNPVYQTLRCRAYFYDSHNN |
|
NCBI Accession
|
YP_009666109.1
|
|
Location
|
1119-1490 |
|
Protein Name
|
C3 |
|
Coding Region
|
ATGGATTCACGCACAGGGGAGTTACTAAGTCCTGCACAGATTATGAGAGCTATCGAGTTCAACAATTCTTCCGGGAACAAGACAAGCCTCCCGTTTCACCTCAAATTTTTATACGCCCACCAGAGCGTATCGAAGAGAACAATCCTGAAGTTCCAACTTCAGGTGAACTACAGGGAAAGGAAGCAGCTGGGCTTTCACAAGATATTCCTGCAGTTTCGGATAATTTCAACCCGTCTGACTGGTGCTACTCACAGTTGGATTGGTATTTTAACTCGCCTTAGATGGCGTATTTGTAATGATTTAGATAGCTTAGGTTTTTTTAGTTTAAATAATTTATATTTTGTAATAGATAATCTACCGAAAAACATGTAA |
|
Protein Sequence
|
MDSRTGELLSPAQIMRAIEFNNSSGNKTSLPFHLKFLYAHQSVSKRTILKFQLQVNYRERKQLGFHKIFLQFRIISTRLTGATHSWIGILTRLRWRICNDLDSLGFFSLNNLYFVIDNLPKNM |
|
NCBI Accession
|
YP_009666110.1
|
|
Location
|
1210-1650 |
|
Protein Name
|
C2 |
|
Coding Region
|
ATGTCGACAACCCCTTCTGGATTCAAGAGGAAGTGTCCGGAGCAGGAACCAGCACACGCAGCGGCGAAGAAGAAGAGGAAAGCACCAGAGCCCAGGACTAGGCTCGTGTGGAAGGGCTGTGGCTGCTCTGCATTCATAACAAACGAATGTAAGTACCAGAATGGATTCACGCACAGGGGAGTTACTAAGTCCTGCACAGATTATGAGAGCTATCGAGTTCAACAATTCTTCCGGGAACAAGACAAGCCTCCCGTTTCACCTCAAATTTTTATACGCCCACCAGAGCGTATCGAAGAGAACAATCCTGAAGTTCCAACTTCAGGTGAACTACAGGGAAAGGAAGCAGCTGGGCTTTCACAAGATATTCCTGCAGTTTCGGATAATTTCAACCCGTCTGACTGGTGCTACTCACAGTTGGATTGGTATTTTAACTCGCCTTAG |
|
Protein Sequence
|
MSTTPSGFKRKCPEQEPAHAAAKKKRKAPEPRTRLVWKGCGCSAFITNECKYQNGFTHRGVTKSCTDYESYRVQQFFREQDKPPVSPQIFIRPPERIEENNPEVPTSGELQGKEAAGLSQDIPAVSDNFNPSDWCYSQLDWYFNSP |
|
NCBI Accession
|
YP_009666111.1
|
|
Location
|
1550-2653 |
|
Protein Name
|
C1 |
|
Coding Region
|
ATGCCACGTAAGCCAGGTTTTAGAGTCCAAGCTAAAAACATTTTCTTAACTTATCCCCAATGCTCTCTCTCTAAAGAGCAAGCTCTTGAACAACTAAGGGCAATTAATTGTCCTTCTGATAAACTATTTATCAGAGTTAGTCAGGAGAAACACCAAGATGGGGCTCTGCATCTCCATGTTCTCATCCAGTTCAGGGGGAAAGCAGAATTCAAAAACCCACGACATTTCGACCTACAACATCCACACAACTCCTCCCAATTCCATCCAAATTTCCAGGCAGCAAAGTCCTCTTCAGATGTCAAGTCATACATTGAGAAGGACGGAGATTTCATCGACTGGGGTGAATTCCAGGTCGACGGCAGGTCTGCTAGAGGAGGTCAGCAGAATGCTAACGACGCTGCCGCAGAGGCCTTAAACGCAGGATCTGCTGAAGCAGCTTTACAAATAATTAGGGAGAAACTCCCTAAAGATTTTATTTTTCAATACCATAATTTACGTAGTAATTTAGATAGGATTTTTTCTCCCCCTCCTTCTGTATATTCTTCTCCTTTTTCTGTTTCTTCTTTCAATAATGTACCTGACATTATCAGCGACTGGGCAGCTGATAACATCATGGATGCCGCTGCGCGGCCAGATAGGCCCATTAGTATTGTTATAGAAGGCCCAAGTAGGATAGGTAAAACAGTTTGGGCTCGGTCTTTAGGCCCACATAATTATCTGTGTGGACATTTGGACTTGAGTCCAAAGGTATATAGTAATAGTGCTTGGTATAACGTCATTGATGACGTAAACCCCCAATACCTAAAGCACTTTAAAGAGTTCATGGGGGCCCAGAAGGACTGGCAAAGCAATTGTAAATACGGAAAGCCAGTTCAAATTAAAGGTGGAATTCCCACTATCTTCCTCTGCAATCCAGGAGAGGGGTCTTCATTTAAATTCTGGCTGGACAAGCCAGAACAAGAAGCACTTAAGAACTGGGCTATTAAGAACGCAGTTTTCTGTGATGTCGACAACCCCTTCTGGATTCAAGAGGAAGTGTCCGGAGCAGGAACCAGCACACGCAGCGGCGAAGAAGAAGAGGAAAGCACCAGAGCCCAGGACTAG |
|
Protein Sequence
|
MPRKPGFRVQAKNIFLTYPQCSLSKEQALEQLRAINCPSDKLFIRVSQEKHQDGALHLHVLIQFRGKAEFKNPRHFDLQHPHNSSQFHPNFQAAKSSSDVKSYIEKDGDFIDWGEFQVDGRSARGGQQNANDAAAEALNAGSAEAALQIIREKLPKDFIFQYHNLRSNLDRIFSPPPSVYSSPFSVSSFNNVPDIISDWAADNIMDAAARPDRPISIVIEGPSRIGKTVWARSLGPHNYLCGHLDLSPKVYSNSAWYNVIDDVNPQYLKHFKEFMGAQKDWQSNCKYGKPVQIKGGIPTIFLCNPGEGSSFKFWLDKPEQEALKNWAIKNAVFCDVDNPFWIQEEVSGAGTSTRSGEEEEESTRAQD |
|
NCBI Accession
|
YP_009666112.1
|
|
Location
|
2239-2496 |
|
Protein Name
|
C4 |
|
Coding Region
|
ATGGGGCTCTGCATCTCCATGTTCTCATCCAGTTCAGGGGGAAAGCAGAATTCAAAAACCCACGACATTTCGACCTACAACATCCACACAACTCCTCCCAATTCCATCCAAATTTCCAGGCAGCAAAGTCCTCTTCAGATGTCAAGTCATACATTGAGAAGGACGGAGATTTCATCGACTGGGGTGAATTCCAGGTCGACGGCAGGTCTGCTAGAGGAGGTCAGCAGAATGCTAACGACGCTGCCGCAGAGGCCTTAA |
|
Protein Sequence
|
MGLCISMFSSSSGGKQNSKTHDISTYNIHTTPPNSIQISRQQSPLQMSSHTLRRTEISSTGVNSRSTAGLLEEVSRMLTTLPQRP |