Sri Lankan cassava mosaic virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_000858725.1 |
| Isolate |
Sri Lanka:Columbo |
| Release date |
2015/2/13 |
| Submitter |
Saunders,K., Salim,N., Mali,V.R., Malathi,V.G., Briddon,R., Markham,P.G., Stanley,J. |
| Host |
|
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
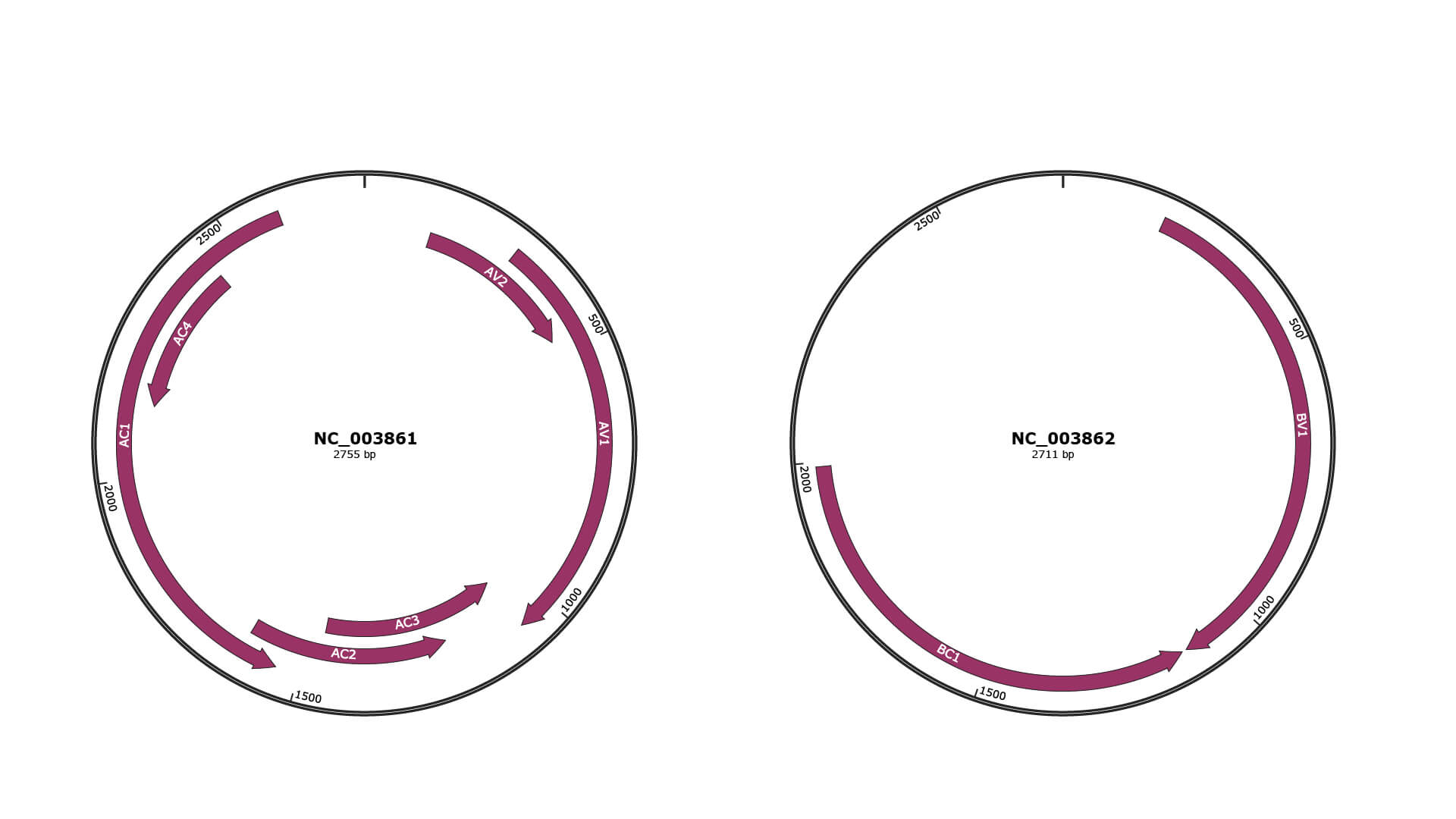
JBrowse
Genome
ACCGGATGGCCGCGCGTCCCCTCGTGGTGTGGGCCCCCCACGTGTAGATGTCCCCCAATTAGAACGCGCCTTGGAAGGCTAGTTATTTGTGGTCCCCCTATATCAACTTGCTCACCAAGTTGTTCATCCACACAATGTGGGACCCTCTATTGAACGAGTTCCCAGAATCCGTCCACGGTTTCCGGTGTATGCTCGCCGTCAAATACCTTCAGCTGGTAGAAGGTACATATTCACCAGACACTCTGGGACACGAGTTAATCAGGGATCTCATATCCGTCATCAGGGCGAAGAATTATGTCGAAGCGACCAGCAGATATAATTATTTCTACTCCAGGCTCGAAGGTTCGTCGCCGTCTGAACTTCGACAGCCCATACAGCAGCCGTGCTGCTGCCCCCACTGTCCGCGTCACAAAAAGACAGCTATGGGCAAACAGGCCCATGAATCGGAAGCCCAGGTGGTATCGGATGTATAGGAGCCCAGATGTTCCTAAGGGCTGTGAAGGCCCATGTAAGGTCCAGTCATTCGAGTCGAGACACGATGTGGTCCATATAGGTAAGGTCATGTGCATCTCTGATGTCACTCGTGGAATTGGGCTTACTCATCGGGTGGGTAAGAGATTTTGTGTTAAGTCCGTTTACATCCTGGGCAAGATATGGATGGATGAAAACATTAAGACCAAAAATCACACGAATAGCGTAATGTTCTTCCTTGTAAGGGATCGTAGGCCCGTTGATAAGCCTCAGGATTTTGGTGAAGTATTTAATATGTTTGATAATGAGCCCAGTACAGCTACTGTGAAGAACATGCATCGTGATCGCTATCAAGTTCTCAGGAAGTGGAGTGCCACTGTCACTGGTGGTCAGTATGCGAGCAAGGAGCAGGCTTTAGTCAGGCGTTTTTTTAGGGTTAATAATTATGTTGTGTATAACCAGCAAGAGGCTGGGAAATATGAGAACCATACTGAGAATGCATTAATGTTGTACATGGCGTGTACTCATGCCTCTAATCCTGTATACGCTACGTTGAAGATTAGAATCTACTTCTATGATTCAGTGAGCAATTAATAAATATTTAATTTTATTAAATTAGACTGCTCAACACGGTCAGTCCCATGGATTACATTGTACAATACATGCTCTACGGCGTTTACAACAGTATTAATACTTATAACTCCTAAGCGATCTAAGTATTTCAATACTTGGGTCTTAAATACCCTCAAGAAACGCCAGGTCTGAGGCTGTAAGGTCGTCCAGACCTTGAAATCCATCCAGCATTGGTGTAGTCCCAACGCTCTCCTCAGGTTGTGGTTGAACCGTATCTGGACGGTTATTATGTCCCACGGCATGCTGAACGGCCGGCTGTCGTGCTGGATGATCTTGAAATAGAGGGGATTTGGAACCTCCCAGATATAGACGCCATTCATCGCCTGAGCTGCAGTGATGAGTTCCCCTGTGCGTGAATCCATGGTTGTGGCAGTTTATGTGCACGTAGTACGAGCACCCGCAGTTGAGGTCTACCCTCCGTCGCCGGATGGCCTTACGCTTAGCTGCTCTGTGTTGGACCTTGATTGGAACCTGAGTAGAGCGGCTCGCTGAGGGAGATGAAGGTCGCATTCTTCAGAGCCCAAGCCTTCAATGCGATATTCTTCGCCTCGTCAAGGAATTCTTTATAGCTGGAATTGGGCCCAGGATTGCACAGGAAGATAGTGGGGATTCCCCCTTTAATTTGAACTGGTTTCCCGTACTTGGTGTTTGACTGCCAGTCCCTTTGGGCCCCCATGAATTCCTTAAAGTGCTTTAGATAATGCGGATCTACGTCATCAATTACGTTGTACCATGCATCATTGCTGTAAACCCTAGGACTCAAGTCCAGATGTCCACACAGATAGTTGTGTGGACCCAATGACCTAGCCCACATCGTTTTGCCTGTACGACTATCGCCCTCGATGACTATACTATTAGGTCTCAAAGGCCTCGCAGAGGCACCCATGACATTCTCTGACACCCACTCCTCAAGTTCATCTGGAACTTGGTCAAATGAAGAGGCTGAGAAGGGAGACACATACACCTCGGGAGGAGGTGTAAAAATCCTATCTAAATTAGCATTTAGATTATGAAATTGTAAAACATAATCCTTGGGTGCTAACTCCTTAATGACTCTAAGAGCCTCTGGCTTACTGCCTGTGTTAAGTGCTGCGGCGTAAGCGTCGTTGGCTGTCTGCTGTCCCCCTCTTGCAGATCTTCCATCGATCTGAAACTCACCCCAGTCGATGGTGTCTCCATCCTTGTCGATGTAGGACTTGACGTCTGAGCTGGACTTAGCGCTCTGTATGTTGGGGTGGAAACTGGTGCTACTGCTTGGGTGTACACAATCGAATTGCCGATTGTTTGTGATCGTGAGCTTCCCTTCGAACTGAAGCAGAGCATGGAGGTGAGGTTCCCCATTATGATGGAGTTCTCTGCAAATTTTAATAAATTTGATGTTTGTCGGAAGACTCAAGCTTCGGAAGAAGTCGAGTAAGTGTTCTTTGGTGAGAGAACACTTAGGGTATGTGAGGAATATATTTTTGGACTGAATTCGGAATCGTGGGTTTCTCATCTTTGACTCGGTCAATTGGAGACACCCCTGAGCAAGTCTCTAGTGAATTGGAGACATTATATATTGTCTCCAAATGGCATTCTCGTAATTCCCAAAAGTTACATTCAAATTTCAAATTCGAATTTGAAATCCAAAAGCGGCCATCCGTATAATATT
ACCGGATGGCCGCGTCCCCCTCTTTATGGTGGCCCCCCCCACGTTGGGATGTCCCCCTCTCACAACGCGCACTAGGAGGTTCAACATGTTAGTGGCCCCACGATGTTGTTTATAACGTCTATAACGTTTGAGACTCGAAGCATGTGATGCCACGTATGCGTTATTTGTACTTCGTCTCGAAGTTATGAGTGAGGGCCCTATGTGTGGATATCTAACCGCATATTGTGCGAATGGATTAAACGTGGCAAGATCATGCCGTTTATTGGGAACTATATTATTATGCTGTGGTCTATATATATGGGTATGTCGTGTATTGAGATCTGCACATGGTTGTTTCAGGATGAGAAGAGGTGCTTATACCCCCCGTTCTACGCCATTCCCTCGTGACCGGAGATCGTATAATGCCGGTAAGGGTAGATCCTTTCGTTCGTACCGTCGTCGTGGACCTGTTCGTCCATTAGCTCGTCGGAACCTGTTTGGTGATGACCATGCACGTGCATTCACGTATAAGACCTTATCGGAGGATCAATTTGGACCGGACTTTACCATACATAATAATAATTATAAGTCATCTTATATATCTATGCCTGCCAAAACACGTGCCCTTAGCGATAACAGGGTAGGTGATTATATCAAACTTGTAAATATATCATTTACAGGTACAGTGTGTATAAAAAACAGCCAGATGGAGTCTGACGGAAGCCCAATGTTGGGCCTGCATGGGCTGTTTACTTGTGTATTGGTCCGGGATAAGACCCCTCGTATATATTCTGCCACTGAGCCTTTGATACCTTTCCCACAGTTGTTTGGGTCCATAAACGCGAGCTATGCGGATTTGTCTATACAAGACCCATATAAGGATCGATTCACAGTTATCCGTCAGGTGTCTTACCCAGTTAATACGGAGAAGGGTGATCATATGTGTCGTTTCAAAGGCACTCGTCGTTTTGTTGGTAGATACCCTATCTGGACTAGTTTTAAAGATGATGGTGGCAGTGGAGATTCATCGGGATTATATAGTAATACGTATAAAAATGCCATACTTGTATATTATGTATGGCTCAGCGACGTATCGTCACAATTGGAAATGTATTGTAAATATGTAACTCGATATATTGGTTAATAAAAATGTTATACATTTTTGGATACATGACTTTGCATACTCGTATTTAAACACATATCTACTGTCTTGCTGATGATGTCGTTTAAGTCCTCTCGTGTGAAGTGGTTCGATCCTACTTGTGATACTGACTTTCCTGGGTCCAATGCGTCTGGGTTGAGCCGGTTTAGTTGGCTGTAAGGCCTTTCAAATGATGGCCCAGCCTCGCTCGTAACGGCCCATGGCCCGTTAAGCCCAATCTCGCTTCTAACGGCCCATGATTCATTTGGGCCTATGGAACATGGAGCATATCTCTTGGAGCGGGATCCTATTAGACTTGGGCCTTGGACCAGTTTCCTCTGCTGGGCTTTTGGACCCACTGACCAGAAATCAATGTCCCTCTCAGTGAAGGCCTTGCTCAGTATCTCGATTTTGGGAGATCTGAACTGTATGTCATTAGACTGCTTTGCAGTTGACAGCTTGAGTTTGCCCTGTATACGGCAGAAGTGGACCCCGTTGATGACGTTTGTGTCTACGACTCTGTACATAACCCTCCATGGGTTTATGTCCTTCATGGAGAAGAACGATGAAGAATAGTAGTGAAGGTTGCAATTGCATTGGACGGGAATAGTAAATTCAGCCTGTTTTGAGTCTCCGTCATGCAGTCTTTGGTCGTGAATTTCAATGATGACATGCCCTGTGGCGTTAATGGGTACCTGGTTTCTATACTCTAGGACGATGTGGTCTATTTTGCAGCAGTGACCCTTGAGGAGCGATATTTTGGTATCCAGAAGAGATGGAAAGCTTAACTTGACGTCTGTTGAGTCATTGGTTAACTCATATTCAACTCTTTCGGAACGAAGATACGCTGCATTGCTACTATTATTCTCCATTGGCCCCGCAGGGGAAATGCTTAAAAATTAAGCCCAGTGCAGAAGAAATAATTTAATGTGCATAAAGCAAAGCCCAAAGCGCAATAAATAGCTAAAGGCATATATATTATATTATTGATGAAAGGTTACAAGAGCATCCACGTGGCAGTGGATTAAATACATGAAAAGCTATACAATATATTTAAAAAAAGTGTTGACGACGTCATCTTCAACGAATGGAACCGGAAACCCTAATCCATCTCTGAGGACTCTGGTGAAGCCCTCTAGTAGTATGTCACATGTTTCCGGTGTCATGTGGTAGTAATTTTTGAGTTTGTAACCCCAATCTTCCATTTTGAAGGCCATATGTATGGCTCTATCTATTTCTGGTAACAGATCCATATCTTGTTCTTCGAATTGGAGGTAATAGGAATTTGAACCAGTCGCGATGTAAGATTGATGTCTGCTAGTAGTTTTGAATTCGACCCAGATCGAATTCTTCATAATGCGACTGGATAGTCGCACACATTTCTTGCTGTGTTGCAAGAAGGAATAGTTAGTTTGGGAAGACATAGGAAGGAGGAGAATGACTTGGTCAATTGGAGACACCCCTGAGCAAGTCTCTAGTGAATTGGAGACATTATATATTGTCTCCAAATGGCATTCTTGTAATTCCTAAAAGTTACATTCAAATTTCAAAGTCGAATTTGAAATCCAAAAGCGGCCATCCTTATAATATT
Gene Information
|
NCBI Accession
|
NP_620863.1
|
|
Location
|
135-473 |
|
Gene Name
|
AV2 |
|
Protein Name
|
AV2 protein |
|
Coding Region
|
ATGTGGGACCCTCTATTGAACGAGTTCCCAGAATCCGTCCACGGTTTCCGGTGTATGCTCGCCGTCAAATACCTTCAGCTGGTAGAAGGTACATATTCACCAGACACTCTGGGACACGAGTTAATCAGGGATCTCATATCCGTCATCAGGGCGAAGAATTATGTCGAAGCGACCAGCAGATATAATTATTTCTACTCCAGGCTCGAAGGTTCGTCGCCGTCTGAACTTCGACAGCCCATACAGCAGCCGTGCTGCTGCCCCCACTGTCCGCGTCACAAAAAGACAGCTATGGGCAAACAGGCCCATGAATCGGAAGCCCAGGTGGTATCGGATGTATAG |
|
Protein Sequence
|
MWDPLLNEFPESVHGFRCMLAVKYLQLVEGTYSPDTLGHELIRDLISVIRAKNYVEATSRYNYFYSRLEGSSPSELRQPIQQPCCCPHCPRHKKTAMGKQAHESEAQVVSDV |
|
NCBI Accession
|
NP_620864.1
|
|
Location
|
295-1065 |
|
Gene Name
|
AV1 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGTCGAAGCGACCAGCAGATATAATTATTTCTACTCCAGGCTCGAAGGTTCGTCGCCGTCTGAACTTCGACAGCCCATACAGCAGCCGTGCTGCTGCCCCCACTGTCCGCGTCACAAAAAGACAGCTATGGGCAAACAGGCCCATGAATCGGAAGCCCAGGTGGTATCGGATGTATAGGAGCCCAGATGTTCCTAAGGGCTGTGAAGGCCCATGTAAGGTCCAGTCATTCGAGTCGAGACACGATGTGGTCCATATAGGTAAGGTCATGTGCATCTCTGATGTCACTCGTGGAATTGGGCTTACTCATCGGGTGGGTAAGAGATTTTGTGTTAAGTCCGTTTACATCCTGGGCAAGATATGGATGGATGAAAACATTAAGACCAAAAATCACACGAATAGCGTAATGTTCTTCCTTGTAAGGGATCGTAGGCCCGTTGATAAGCCTCAGGATTTTGGTGAAGTATTTAATATGTTTGATAATGAGCCCAGTACAGCTACTGTGAAGAACATGCATCGTGATCGCTATCAAGTTCTCAGGAAGTGGAGTGCCACTGTCACTGGTGGTCAGTATGCGAGCAAGGAGCAGGCTTTAGTCAGGCGTTTTTTTAGGGTTAATAATTATGTTGTGTATAACCAGCAAGAGGCTGGGAAATATGAGAACCATACTGAGAATGCATTAATGTTGTACATGGCGTGTACTCATGCCTCTAATCCTGTATACGCTACGTTGAAGATTAGAATCTACTTCTATGATTCAGTGAGCAATTAA |
|
Protein Sequence
|
MSKRPADIIISTPGSKVRRRLNFDSPYSSRAAAPTVRVTKRQLWANRPMNRKPRWYRMYRSPDVPKGCEGPCKVQSFESRHDVVHIGKVMCISDVTRGIGLTHRVGKRFCVKSVYILGKIWMDENIKTKNHTNSVMFFLVRDRRPVDKPQDFGEVFNMFDNEPSTATVKNMHRDRYQVLRKWSATVTGGQYASKEQALVRRFFRVNNYVVYNQQEAGKYENHTENALMLYMACTHASNPVYATLKIRIYFYDSVSN |
|
NCBI Accession
|
NP_620865.1
|
|
Location
|
1062-1466 |
|
Gene Name
|
AC3 |
|
Protein Name
|
replication enhancer protein |
|
Coding Region
|
ATGGATTCACGCACAGGGGAACTCATCACTGCAGCTCAGGCGATGAATGGCGTCTATATCTGGGAGGTTCCAAATCCCCTCTATTTCAAGATCATCCAGCACGACAGCCGGCCGTTCAGCATGCCGTGGGACATAATAACCGTCCAGATACGGTTCAACCACAACCTGAGGAGAGCGTTGGGACTACACCAATGCTGGATGGATTTCAAGGTCTGGACGACCTTACAGCCTCAGACCTGGCGTTTCTTGAGGGTATTTAAGACCCAAGTATTGAAATACTTAGATCGCTTAGGAGTTATAAGTATTAATACTGTTGTAAACGCCGTAGAGCATGTATTGTACAATGTAATCCATGGGACTGACCGTGTTGAGCAGTCTAATTTAATAAAATTAAATATTTATTAA |
|
Protein Sequence
|
MDSRTGELITAAQAMNGVYIWEVPNPLYFKIIQHDSRPFSMPWDIITVQIRFNHNLRRALGLHQCWMDFKVWTTLQPQTWRFLRVFKTQVLKYLDRLGVISINTVVNAVEHVLYNVIHGTDRVEQSNLIKLNIY |
|
NCBI Accession
|
NP_620866.1
|
|
Location
|
1207-1614 |
|
Gene Name
|
AC2 |
|
Protein Name
|
transcriptional transactivator protein |
|
Coding Region
|
ATGCGACCTTCATCTCCCTCAGCGAGCCGCTCTACTCAGGTTCCAATCAAGGTCCAACACAGAGCAGCTAAGCGTAAGGCCATCCGGCGACGGAGGGTAGACCTCAACTGCGGGTGCTCGTACTACGTGCACATAAACTGCCACAACCATGGATTCACGCACAGGGGAACTCATCACTGCAGCTCAGGCGATGAATGGCGTCTATATCTGGGAGGTTCCAAATCCCCTCTATTTCAAGATCATCCAGCACGACAGCCGGCCGTTCAGCATGCCGTGGGACATAATAACCGTCCAGATACGGTTCAACCACAACCTGAGGAGAGCGTTGGGACTACACCAATGCTGGATGGATTTCAAGGTCTGGACGACCTTACAGCCTCAGACCTGGCGTTTCTTGAGGGTATTTAA |
|
Protein Sequence
|
MRPSSPSASRSTQVPIKVQHRAAKRKAIRRRRVDLNCGCSYYVHINCHNHGFTHRGTHHCSSGDEWRLYLGGSKSPLFQDHPARQPAVQHAVGHNNRPDTVQPQPEESVGTTPMLDGFQGLDDLTASDLAFLEGI |
|
NCBI Accession
|
NP_620867.1
|
|
Location
|
1544-2599 |
|
Gene Name
|
AC1 |
|
Protein Name
|
replication-associated protein |
|
Coding Region
|
ATGAGAAACCCACGATTCCGAATTCAGTCCAAAAATATATTCCTCACATACCCTAAGTGTTCTCTCACCAAAGAACACTTACTCGACTTCTTCCGAAGCTTGAGTCTTCCGACAAACATCAAATTTATTAAAATTTGCAGAGAACTCCATCATAATGGGGAACCTCACCTCCATGCTCTGCTTCAGTTCGAAGGGAAGCTCACGATCACAAACAATCGGCAATTCGATTGTGTACACCCAAGCAGTAGCACCAGTTTCCACCCCAACATACAGAGCGCTAAGTCCAGCTCAGACGTCAAGTCCTACATCGACAAGGATGGAGACACCATCGACTGGGGTGAGTTTCAGATCGATGGAAGATCTGCAAGAGGGGGACAGCAGACAGCCAACGACGCTTACGCCGCAGCACTTAACACAGGCAGTAAGCCAGAGGCTCTTAGAGTCATTAAGGAGTTAGCACCCAAGGATTATGTTTTACAATTTCATAATCTAAATGCTAATTTAGATAGGATTTTTACACCTCCTCCCGAGGTGTATGTGTCTCCCTTCTCAGCCTCTTCATTTGACCAAGTTCCAGATGAACTTGAGGAGTGGGTGTCAGAGAATGTCATGGGTGCCTCTGCGAGGCCTTTGAGACCTAATAGTATAGTCATCGAGGGCGATAGTCGTACAGGCAAAACGATGTGGGCTAGGTCATTGGGTCCACACAACTATCTGTGTGGACATCTGGACTTGAGTCCTAGGGTTTACAGCAATGATGCATGGTACAACGTAATTGATGACGTAGATCCGCATTATCTAAAGCACTTTAAGGAATTCATGGGGGCCCAAAGGGACTGGCAGTCAAACACCAAGTACGGGAAACCAGTTCAAATTAAAGGGGGAATCCCCACTATCTTCCTGTGCAATCCTGGGCCCAATTCCAGCTATAAAGAATTCCTTGACGAGGCGAAGAATATCGCATTGAAGGCTTGGGCTCTGAAGAATGCGACCTTCATCTCCCTCAGCGAGCCGCTCTACTCAGGTTCCAATCAAGGTCCAACACAGAGCAGCTAA |
|
Protein Sequence
|
MRNPRFRIQSKNIFLTYPKCSLTKEHLLDFFRSLSLPTNIKFIKICRELHHNGEPHLHALLQFEGKLTITNNRQFDCVHPSSSTSFHPNIQSAKSSSDVKSYIDKDGDTIDWGEFQIDGRSARGGQQTANDAYAAALNTGSKPEALRVIKELAPKDYVLQFHNLNANLDRIFTPPPEVYVSPFSASSFDQVPDELEEWVSENVMGASARPLRPNSIVIEGDSRTGKTMWARSLGPHNYLCGHLDLSPRVYSNDAWYNVIDDVDPHYLKHFKEFMGAQRDWQSNTKYGKPVQIKGGIPTIFLCNPGPNSSYKEFLDEAKNIALKAWALKNATFISLSEPLYSGSNQGPTQSS |
|
NCBI Accession
|
NP_620868.1
|
|
Location
|
2143-2445 |
|
Gene Name
|
AC4 |
|
Protein Name
|
AC4 protein |
|
Coding Region
|
ATGGGGAACCTCACCTCCATGCTCTGCTTCAGTTCGAAGGGAAGCTCACGATCACAAACAATCGGCAATTCGATTGTGTACACCCAAGCAGTAGCACCAGTTTCCACCCCAACATACAGAGCGCTAAGTCCAGCTCAGACGTCAAGTCCTACATCGACAAGGATGGAGACACCATCGACTGGGGTGAGTTTCAGATCGATGGAAGATCTGCAAGAGGGGGACAGCAGACAGCCAACGACGCTTACGCCGCAGCACTTAACACAGGCAGTAAGCCAGAGGCTCTTAGAGTCATTAAGGAGTTAG |
|
Protein Sequence
|
MGNLTSMLCFSSKGSSRSQTIGNSIVYTQAVAPVSTPTYRALSPAQTSSPTSTRMETPSTGVSFRSMEDLQEGDSRQPTTLTPQHLTQAVSQRLLESLRS |
|
NCBI Accession
|
NP_620869.1
|
|
Location
|
185-1123 |
|
Gene Name
|
BV1 |
|
Protein Name
|
nuclear shuttle protein |
|
Coding Region
|
ATGAGTGAGGGCCCTATGTGTGGATATCTAACCGCATATTGTGCGAATGGATTAAACGTGGCAAGATCATGCCGTTTATTGGGAACTATATTATTATGCTGTGGTCTATATATATGGGTATGTCGTGTATTGAGATCTGCACATGGTTGTTTCAGGATGAGAAGAGGTGCTTATACCCCCCGTTCTACGCCATTCCCTCGTGACCGGAGATCGTATAATGCCGGTAAGGGTAGATCCTTTCGTTCGTACCGTCGTCGTGGACCTGTTCGTCCATTAGCTCGTCGGAACCTGTTTGGTGATGACCATGCACGTGCATTCACGTATAAGACCTTATCGGAGGATCAATTTGGACCGGACTTTACCATACATAATAATAATTATAAGTCATCTTATATATCTATGCCTGCCAAAACACGTGCCCTTAGCGATAACAGGGTAGGTGATTATATCAAACTTGTAAATATATCATTTACAGGTACAGTGTGTATAAAAAACAGCCAGATGGAGTCTGACGGAAGCCCAATGTTGGGCCTGCATGGGCTGTTTACTTGTGTATTGGTCCGGGATAAGACCCCTCGTATATATTCTGCCACTGAGCCTTTGATACCTTTCCCACAGTTGTTTGGGTCCATAAACGCGAGCTATGCGGATTTGTCTATACAAGACCCATATAAGGATCGATTCACAGTTATCCGTCAGGTGTCTTACCCAGTTAATACGGAGAAGGGTGATCATATGTGTCGTTTCAAAGGCACTCGTCGTTTTGTTGGTAGATACCCTATCTGGACTAGTTTTAAAGATGATGGTGGCAGTGGAGATTCATCGGGATTATATAGTAATACGTATAAAAATGCCATACTTGTATATTATGTATGGCTCAGCGACGTATCGTCACAATTGGAAATGTATTGTAAATATGTAACTCGATATATTGGTTAA |
|
Protein Sequence
|
MSEGPMCGYLTAYCANGLNVARSCRLLGTILLCCGLYIWVCRVLRSAHGCFRMRRGAYTPRSTPFPRDRRSYNAGKGRSFRSYRRRGPVRPLARRNLFGDDHARAFTYKTLSEDQFGPDFTIHNNNYKSSYISMPAKTRALSDNRVGDYIKLVNISFTGTVCIKNSQMESDGSPMLGLHGLFTCVLVRDKTPRIYSATEPLIPFPQLFGSINASYADLSIQDPYKDRFTVIRQVSYPVNTEKGDHMCRFKGTRRFVGRYPIWTSFKDDGGSGDSSGLYSNTYKNAILVYYVWLSDVSSQLEMYCKYVTRYIG |
|
NCBI Accession
|
NP_620870.1
|
|
Location
|
1132-1992 |
|
Gene Name
|
BC1 |
|
Protein Name
|
movement protein |
|
Coding Region
|
ATGGAGAATAATAGTAGCAATGCAGCGTATCTTCGTTCCGAAAGAGTTGAATATGAGTTAACCAATGACTCAACAGACGTCAAGTTAAGCTTTCCATCTCTTCTGGATACCAAAATATCGCTCCTCAAGGGTCACTGCTGCAAAATAGACCACATCGTCCTAGAGTATAGAAACCAGGTACCCATTAACGCCACAGGGCATGTCATCATTGAAATTCACGACCAAAGACTGCATGACGGAGACTCAAAACAGGCTGAATTTACTATTCCCGTCCAATGCAATTGCAACCTTCACTACTATTCTTCATCGTTCTTCTCCATGAAGGACATAAACCCATGGAGGGTTATGTACAGAGTCGTAGACACAAACGTCATCAACGGGGTCCACTTCTGCCGTATACAGGGCAAACTCAAGCTGTCAACTGCAAAGCAGTCTAATGACATACAGTTCAGATCTCCCAAAATCGAGATACTGAGCAAGGCCTTCACTGAGAGGGACATTGATTTCTGGTCAGTGGGTCCAAAAGCCCAGCAGAGGAAACTGGTCCAAGGCCCAAGTCTAATAGGATCCCGCTCCAAGAGATATGCTCCATGTTCCATAGGCCCAAATGAATCATGGGCCGTTAGAAGCGAGATTGGGCTTAACGGGCCATGGGCCGTTACGAGCGAGGCTGGGCCATCATTTGAAAGGCCTTACAGCCAACTAAACCGGCTCAACCCAGACGCATTGGACCCAGGAAAGTCAGTATCACAAGTAGGATCGAACCACTTCACACGAGAGGACTTAAACGACATCATCAGCAAGACAGTAGATATGTGTTTAAATACGAGTATGCAAAGTCATGTATCCAAAAATGTATAA |
|
Protein Sequence
|
MENNSSNAAYLRSERVEYELTNDSTDVKLSFPSLLDTKISLLKGHCCKIDHIVLEYRNQVPINATGHVIIEIHDQRLHDGDSKQAEFTIPVQCNCNLHYYSSSFFSMKDINPWRVMYRVVDTNVINGVHFCRIQGKLKLSTAKQSNDIQFRSPKIEILSKAFTERDIDFWSVGPKAQQRKLVQGPSLIGSRSKRYAPCSIGPNESWAVRSEIGLNGPWAVTSEAGPSFERPYSQLNRLNPDALDPGKSVSQVGSNHFTREDLNDIISKTVDMCLNTSMQSHVSKNV |