Squash leaf curl China virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_000865805.1 |
| Isolate |
Viet Nam |
| Release date |
2015/2/13 |
| Submitter |
Revill,P.A., Ha,C.V., Porchun,S.C., Vu,M.T., Dale,J.L. |
| Host |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
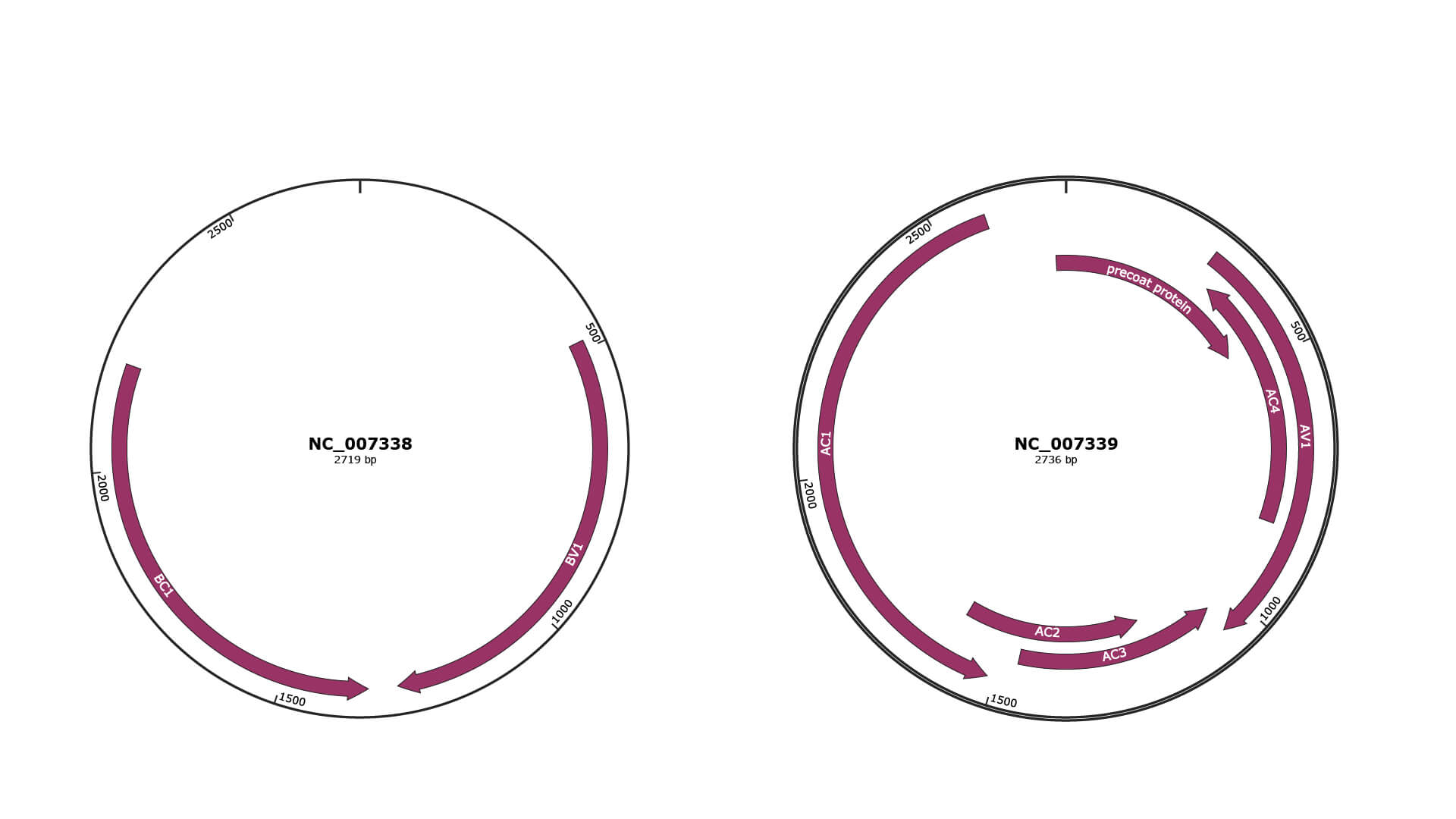
JBrowse
Genome
TAATATTACCGAAAGGCCGCGCTTTTTTTTTCCTTCAAATCTGGCCGTCTATTTTCTATAAATGCGCATCAAACTAATGCGATGAACAACACGTGTCCTATGTGTCATCCTTTACTAAAGTAAAGGATTGTACGATTTTCAAATGTGCACATGCTGGTCCCCAGTGGCTAGATATGCAATATCTAGGAAGCTGCATCTGTGGTCCCCAGCATATAAGGCTGCTGGTCTATTGCGTTTAAAGTTTGGTCTTAGCGATAATTCACCATGCATCAGTGCCCGTTGCTCTATCATATGTAAGGTATTTTGAACGGCTGAGATCAAAATAGGAATTTGACCTTTATCTGACCGTTCGATTATTTTAGATGCCCGTAATTCGATAAAACATGTCCTATCGTTCGTGTTCCATACAAACATTGAACTGAATTATATCACTATATAATTCACGATCTTGCATAGTCGTCGCCATTCGTAATTATCGATCCAAATGGCTTTTATCGCACCATATACTCCGGGAAGACGACATTCAACATCAACAAACAGACTATTGAACGCAAGCAGGAAAATGAAAGGTTGGAAGTCTCGGAAATACCATGGATTTGTGCGTTATCGGAATTTTTATTCCGCATCCAGGACCCCAACTGACCTGTTTGGTGATCCTATCTCCAGACAATACACGCGCAAGGAAATTTGTGAAACGCAACAGGGATCTGAATATGTTCTCCAGAACAACCGCTACATGACTTCGTATGTCACGTATCCTGCTAAAACTCGAACGGGAACGAATAACAGGGTTCGTTCATATATCAAGCTCACAGGTCTTACCATGTCCGGAACATTCGGCATTCGATGCTCCGATTTGATGACCGATGTCGATCAACCCAGTGGATTATATGGCGTCGTGTCGATTGTTATTGTCCGTGATAAATCACCGAAGATTTATTCGACTGCACAACCACTCATTCCATTTGTTGAGTTATTTGGTTCGGTTAATTCATGTCGTGGGACCCTGAAGGTGGCAGAACGCCACCGAGAAAGGTTTGTGGTGCTCAATCAAACGTCCATACTGATAAACACGCCTCATTGCAACGCAATGAAGAAATTCTCAATTCGTAATTGCATCTCACGCACTTACTCTACCTGGGCTACGTTCAAGGACGAAGAAGAGGAAAGTGCTACTGGGCTATATTCAAACACGCTTCGAAATGCTATTCTTATATATTATGTGTGGTTAAGCGATGTACCATCTCAACTAGACATGTACAGCAATGTAATGCTAAATTACATTGGTTAATGCAATCATGATGCTGAAAAGAACTGCCATTAATAAATTTTGCAATAAATTTATCACACGCCTTTAGTTAATGGAGCGTTTACATTCGATTTCATACATTGTTCTACCGTTTTAGTTATTATTTCAGTTATCTCGTCCCTCGTAATGCTTCCCACTTGTGATGCCGATGGACCAGGATCTATTGCGGATTCATCTAATCCGCTGAGGTTTTTGTACGGTCTGCTGGTGACAGAAACTAGCCCAACTTCCGATCTACTTGCCCATGATTCGTTCGGACCAATCGCAAGATGTGGGACGCGTAACGATCTTGAACTGTGACCCATGAGTCTTGATCCATCGACGAGCCGTCTTGTCTGTGGTTTCGACCCCACCGACCAGAAATCTATGTCGTTGACAGTGAATTCTTTGCTTTGGATCTCTATTCTTGGTGCTCGGAATTCGACGTCAGTCGAATGTTTGGCCGAGGATAGTTTTAATTTACCGAGCATCTTACAGAAATGAACTCCATTCACTACGTTCGTGTTTTCTACTCTGTATTCAACTCTCCAAGGATTTTTATCCTTAGCGGAGAAGTATGAGGATGAGTAATAGTGGAGGTTGCAGTTGCATTTAATTGGAATTGTGAACTCTGCTTGTTTCGTGTCTCCCTCCGTCAATCGCATGTCGTGAATCTCAATTACCACATGCCCGACTGCATTAATTGGTACTTGGCTGCGATATTCAAGAAGAACGTGATCAATTTTCATGCATCTGTTTCTCAATTGACTGATTTTCTGCTCGAACATGGAAGGGAACGTCAGAGTGACCTCCGCAGCGTCGTTTGTGAGAGCGTACTCTACACGCTCCGATTCTATGTATCCTCCGACTCCAAGACCCATGTTATCATTTCTTATTGACATATCGGGCGCGCAGCGTAATTGGCTCCGCAGGTGAATTAACTATGAAACGTACACTACACCAGTCTTTGCAAAAAGACCGAAGGAAATTGTGGGAAAGGAAATGCAGGACAATTGCATTTCTAAAGAACATCTAACACCGATTTATAACCTATCATGTGTTATGTCCCTTGTCCATAGCAATAATTCGAAATTCATCCGTGACCGTTGCTCTATCATATCTAAGATATTTTGAACGGCTGAGATCAAAATATGAATGTCCTCTTATTAGCCCTGTTTGTAGCCAGCCCAATTTGCTAAAATTGGGATATGGTATATGGATTCTTGGGTCACTCAAAAATAGCCCAATTAAGTATCTAGCCAGTCCGCCCATTCAAAGAACGACACCGTTTGAAGTTTATTTACATGGAAAAGTTAGAGAGAAGTTGCACCTTCTCTCTCTAGACCCCAATTGGTGTCCCTTCAAAACTATGGTATATTGGGGTATGGGGTCTTATATATACCTTAGAGAAATTTATGGCGGCCTTTCGTT
TAATATTACCGAATGGCCGCGCGATTTTTTATGTGGGCCCTCGACCAATGAAATTCACGCTACATGGCTTATTTATTACGTGGGGACCATTAAATAGACTTCCGCACCAAGTTTTGATCCACAACATGTGGGATCCACTTATGCACGAATTTCCTGAAAGTGTTCATGGTCTAAGGTGCATGTTAGCGGTGAAATATCTTCAAGAGGTGGAAAAAACATATTCTCCGGACACAGTCGGCTACGATCTTGTCCGCGATCTCATCCTTGTTCTCCGCGCAAAGAATTATGTCGAAGCGACCAGCCGATATTATCATTTCAACTCCCGCGTCGAAGGTACGCCGACGTCTCAACTTCGACAGCCCATATGTTTCCCGTGCAGTTGTCCCCATTGCCCGCGTCACAAAGGGAAAGGCCTGGACAAACAGGCCGATGAACAGAAAACCCAAGATGTACAGGATGTATAGAAGTCCCGACGTGCCAAGGGGCTGTGAAGGCCCTTGTAAAGTTCAATCGTTTGAATCTAGGCACGATGTCTCCCATATTGGTAAGGTGATGTGTATTAGTGATGTTACACGAGGAACCGGACTCACACATCGCGTTGGGAAGCGATTTTGTGTGAAATCTGTTTACGTTTTGGGGAAAATATGGATGGACGAAAATATCAAGACTAAAAACCACACTAATAGCGTCATATTTTTTCTGGTTCAAGACCGTCGTCCTACAGGAACTCCACAGGATTTTGGGGAGGTTTTTAATATGTTCGATAATGAACCGAGCACTGCAACGGTGAAGAATATGCATCGTGATCGATATCAAGTGATGCGCAAATGGCATGCCACTGTGACCGGAGGAACATACGCATCAAGGGAGCAAGCATTAGTTAGGAAGTTTGTTAGGGTTAATAATTATGTTGTCTATAATCAACAAGAGGCCGGCAAGTATGAGAATCATACTGAAAATGCATTAATGTTGTATATGGCCTGTACTCACGCATCGAACCCTGTATACGCGACTTTGAAAATCCGAATCTATTTTTATGATTCGGTAACAAATTAATATATATTCAATTTCACATCATATGTTGTCCATACATCAATTGTCTTTTCCAATACATCGTCCAATACATGATAAACTGCTCTTATTACATTATAAATACCAATCACTCCTAACCTATCCAGGTACTTAAGGACCTGGGTTTTAAAGACTCTCAAGAAAATCCCAGTCGGCGGTTGTAAGCCCGTCCAGATTTGGAAAGTTATCGCACATTTGTGAAGCCGCAGTGCTTTCCGCAGGTTGTGGTTGAACACTACCTGCACCTTGATTATGTCGTGTTCCTCTAGACAAGGTCTGATGTCGTGTTTTATTATTTTGAAATAGAGGGGATTTGGAACTTCCCAGATATACGCGCCACTCTCTGCTCGATCCACAGTGATGTACTCCCCTGTGCGTGAATCCGTGATCATGGCAATTTATTGACATGTAATACGAGCATCCGCACGGTAGATCAATTCGTCTACGTCTGATGTTCTTCTTCTTCTTCAGCGGTTGCGATGCTTTCGCGACCGGAATAGAGTGGTTCTTCGATTGTGATGAAGATTGCATTCTTTAATGCCCACTGCTTCAGTGCTGCATTCTTTTCTTCATCGAGATATTCTTTGTAACTGCTGTTTGGTCCTTTATTGCAGAGGAAGATGGTGGGAATCCCACCTTTAATCATGACTGGCTTTCCGTACTTCGTGTTGCTTTGCCAGTCTCTTTGGGCCCCCATGAATTCTTTAAAATGCTTTAGATAGTGGGGATCAACGTCATCAATGACGTTGTACCAAGCATCATTATTGTATACTCTCGGGCTTAGATCTAGATGGCCGCACAAGTAATTGTGTGGTCCTAACGAACGCGCCCACGCTGTTTTGCCCGTCCTACTATCACCCTCTAATACTATTCCTATGGGTCTATTCGGGCGCGCAGCGCAACACCCCACATTACTTGAAACCCAATCGACGAGTTCTTGCGGAACTCTGTCGAAGGATGAAATTGAAAAAGGAGAAACATACACCTCAGCACGAGGTGGAAAAATACGATCTAAATTCGAATTCATATTATGAAATTGCAAAACGTAATCTTTGGGTGCTAATTCTTTCAACACTTTCAATGCATCTTCTTTGTTTCCTGTATTTATTGCTCTTGCGTACGCGTCGTTAGCTGTTTGTTGACCTCCACGAGCAGATCGTCCATCGATCTGGAAGACACCCCATTCTAACACGTCCCCGTCTTTGTCGATGTATTGTTTGACGTCCGATGCCGATTTAGCTCCCTGAATGTTCGGATGGAAATGTGTTGACCGACTTGGGGACACCAAGTCGAAGAATCTGTTATTCTTGCATTGGAACTTTCCTTCGAACTGGATAAGAACGTGGATATGCGGAGCCCCATCTTCGTGCAACTCTCTGCAAATTTTGATAAATTTCTTCGAAGTTGGAGTTTCTAGGGTTCGCAATTGGGAAAGTGCCTCTTCTTTGGATAGAGAGCACTTTGGATATGTGAGGAAATAGTTTTTTGCACTTATTTTGAAATGCTTAGGAGGAGCCATCAAAACGCGCGTTTTGAATCGGGGTCTCTCCAAAACTATGGTATATTGGGGTATGGGGTCTCATATATACTTTGGACACCAAATGGCAAAATGGTAATTATGCAAATAATTACTTTAATTCAAAATGAATAAAGCGGCCATTCGTA
Gene Information
|
NCBI Accession
|
YP_293686.1
|
|
Location
|
485-1291 |
|
Gene Name
|
BV1 |
|
Protein Name
|
BV1 |
|
Coding Region
|
ATGGCTTTTATCGCACCATATACTCCGGGAAGACGACATTCAACATCAACAAACAGACTATTGAACGCAAGCAGGAAAATGAAAGGTTGGAAGTCTCGGAAATACCATGGATTTGTGCGTTATCGGAATTTTTATTCCGCATCCAGGACCCCAACTGACCTGTTTGGTGATCCTATCTCCAGACAATACACGCGCAAGGAAATTTGTGAAACGCAACAGGGATCTGAATATGTTCTCCAGAACAACCGCTACATGACTTCGTATGTCACGTATCCTGCTAAAACTCGAACGGGAACGAATAACAGGGTTCGTTCATATATCAAGCTCACAGGTCTTACCATGTCCGGAACATTCGGCATTCGATGCTCCGATTTGATGACCGATGTCGATCAACCCAGTGGATTATATGGCGTCGTGTCGATTGTTATTGTCCGTGATAAATCACCGAAGATTTATTCGACTGCACAACCACTCATTCCATTTGTTGAGTTATTTGGTTCGGTTAATTCATGTCGTGGGACCCTGAAGGTGGCAGAACGCCACCGAGAAAGGTTTGTGGTGCTCAATCAAACGTCCATACTGATAAACACGCCTCATTGCAACGCAATGAAGAAATTCTCAATTCGTAATTGCATCTCACGCACTTACTCTACCTGGGCTACGTTCAAGGACGAAGAAGAGGAAAGTGCTACTGGGCTATATTCAAACACGCTTCGAAATGCTATTCTTATATATTATGTGTGGTTAAGCGATGTACCATCTCAACTAGACATGTACAGCAATGTAATGCTAAATTACATTGGTTAA |
|
Protein Sequence
|
MAFIAPYTPGRRHSTSTNRLLNASRKMKGWKSRKYHGFVRYRNFYSASRTPTDLFGDPISRQYTRKEICETQQGSEYVLQNNRYMTSYVTYPAKTRTGTNNRVRSYIKLTGLTMSGTFGIRCSDLMTDVDQPSGLYGVVSIVIVRDKSPKIYSTAQPLIPFVELFGSVNSCRGTLKVAERHRERFVVLNQTSILINTPHCNAMKKFSIRNCISRTYSTWATFKDEEEESATGLYSNTLRNAILIYYVWLSDVPSQLDMYSNVMLNYIG |
|
NCBI Accession
|
YP_293687.1
|
|
Location
|
1345-2190 |
|
Gene Name
|
BC1 |
|
Protein Name
|
BC1 |
|
Coding Region
|
ATGTCAATAAGAAATGATAACATGGGTCTTGGAGTCGGAGGATACATAGAATCGGAGCGTGTAGAGTACGCTCTCACAAACGACGCTGCGGAGGTCACTCTGACGTTCCCTTCCATGTTCGAGCAGAAAATCAGTCAATTGAGAAACAGATGCATGAAAATTGATCACGTTCTTCTTGAATATCGCAGCCAAGTACCAATTAATGCAGTCGGGCATGTGGTAATTGAGATTCACGACATGCGATTGACGGAGGGAGACACGAAACAAGCAGAGTTCACAATTCCAATTAAATGCAACTGCAACCTCCACTATTACTCATCCTCATACTTCTCCGCTAAGGATAAAAATCCTTGGAGAGTTGAATACAGAGTAGAAAACACGAACGTAGTGAATGGAGTTCATTTCTGTAAGATGCTCGGTAAATTAAAACTATCCTCGGCCAAACATTCGACTGACGTCGAATTCCGAGCACCAAGAATAGAGATCCAAAGCAAAGAATTCACTGTCAACGACATAGATTTCTGGTCGGTGGGGTCGAAACCACAGACAAGACGGCTCGTCGATGGATCAAGACTCATGGGTCACAGTTCAAGATCGTTACGCGTCCCACATCTTGCGATTGGTCCGAACGAATCATGGGCAAGTAGATCGGAAGTTGGGCTAGTTTCTGTCACCAGCAGACCGTACAAAAACCTCAGCGGATTAGATGAATCCGCAATAGATCCTGGTCCATCGGCATCACAAGTGGGAAGCATTACGAGGGACGAGATAACTGAAATAATAACTAAAACGGTAGAACAATGTATGAAATCGAATGTAAACGCTCCATTAACTAAAGGCGTGTGA |
|
Protein Sequence
|
MSIRNDNMGLGVGGYIESERVEYALTNDAAEVTLTFPSMFEQKISQLRNRCMKIDHVLLEYRSQVPINAVGHVVIEIHDMRLTEGDTKQAEFTIPIKCNCNLHYYSSSYFSAKDKNPWRVEYRVENTNVVNGVHFCKMLGKLKLSSAKHSTDVEFRAPRIEIQSKEFTVNDIDFWSVGSKPQTRRLVDGSRLMGHSSRSLRVPHLAIGPNESWASRSEVGLVSVTSRPYKNLSGLDESAIDPGPSASQVGSITRDEITEIITKTVEQCMKSNVNAPLTKGV |
|
NCBI Accession
|
YP_293688.1
|
|
Location
|
join(2715-2736,1-464) |
|
Gene Name
|
AV2 |
|
Protein Name
|
precoat protein |
|
Coding Region
|
ATGAATAAAGCGGCCATTCGTATAATATTACCGAATGGCCGCGCGATTTTTTATGTGGGCCCTCGACCAATGAAATTCACGCTACATGGCTTATTTATTACGTGGGGACCATTAAATAGACTTCCGCACCAAGTTTTGATCCACAACATGTGGGATCCACTTATGCACGAATTTCCTGAAAGTGTTCATGGTCTAAGGTGCATGTTAGCGGTGAAATATCTTCAAGAGGTGGAAAAAACATATTCTCCGGACACAGTCGGCTACGATCTTGTCCGCGATCTCATCCTTGTTCTCCGCGCAAAGAATTATGTCGAAGCGACCAGCCGATATTATCATTTCAACTCCCGCGTCGAAGGTACGCCGACGTCTCAACTTCGACAGCCCATATGTTTCCCGTGCAGTTGTCCCCATTGCCCGCGTCACAAAGGGAAAGGCCTGGACAAACAGGCCGATGAACAGAAAACCCAAGATGTACAGGATGTATAG |
|
Protein Sequence
|
MNKAAIRIILPNGRAIFYVGPRPMKFTLHGLFITWGPLNRLPHQVLIHNMWDPLMHEFPESVHGLRCMLAVKYLQEVEKTYSPDTVGYDLVRDLILVLRAKNYVEATSRYYHFNSRVEGTPTSQLRQPICFPCSCPHCPRHKGKGLDKQADEQKTQDVQDV |
|
NCBI Accession
|
YP_293689.1
|
|
Location
|
286-1056 |
|
Gene Name
|
AV1 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGTCGAAGCGACCAGCCGATATTATCATTTCAACTCCCGCGTCGAAGGTACGCCGACGTCTCAACTTCGACAGCCCATATGTTTCCCGTGCAGTTGTCCCCATTGCCCGCGTCACAAAGGGAAAGGCCTGGACAAACAGGCCGATGAACAGAAAACCCAAGATGTACAGGATGTATAGAAGTCCCGACGTGCCAAGGGGCTGTGAAGGCCCTTGTAAAGTTCAATCGTTTGAATCTAGGCACGATGTCTCCCATATTGGTAAGGTGATGTGTATTAGTGATGTTACACGAGGAACCGGACTCACACATCGCGTTGGGAAGCGATTTTGTGTGAAATCTGTTTACGTTTTGGGGAAAATATGGATGGACGAAAATATCAAGACTAAAAACCACACTAATAGCGTCATATTTTTTCTGGTTCAAGACCGTCGTCCTACAGGAACTCCACAGGATTTTGGGGAGGTTTTTAATATGTTCGATAATGAACCGAGCACTGCAACGGTGAAGAATATGCATCGTGATCGATATCAAGTGATGCGCAAATGGCATGCCACTGTGACCGGAGGAACATACGCATCAAGGGAGCAAGCATTAGTTAGGAAGTTTGTTAGGGTTAATAATTATGTTGTCTATAATCAACAAGAGGCCGGCAAGTATGAGAATCATACTGAAAATGCATTAATGTTGTATATGGCCTGTACTCACGCATCGAACCCTGTATACGCGACTTTGAAAATCCGAATCTATTTTTATGATTCGGTAACAAATTAA |
|
Protein Sequence
|
MSKRPADIIISTPASKVRRRLNFDSPYVSRAVVPIARVTKGKAWTNRPMNRKPKMYRMYRSPDVPRGCEGPCKVQSFESRHDVSHIGKVMCISDVTRGTGLTHRVGKRFCVKSVYVLGKIWMDENIKTKNHTNSVIFFLVQDRRPTGTPQDFGEVFNMFDNEPSTATVKNMHRDRYQVMRKWHATVTGGTYASREQALVRKFVRVNNYVVYNQQEAGKYENHTENALMLYMACTHASNPVYATLKIRIYFYDSVTN |
|
NCBI Accession
|
YP_293690.1
|
|
Location
|
316-834 |
|
Gene Name
|
AC4 |
|
Protein Name
|
hypothetical protein |
|
Coding Region
|
ATGCCATTTGCGCATCACTTGATATCGATCACGATGCATATTCTTCACCGTTGCAGTGCTCGGTTCATTATCGAACATATTAAAAACCTCCCCAAAATCCTGTGGAGTTCCTGTAGGACGACGGTCTTGAACCAGAAAAAATATGACGCTATTAGTGTGGTTTTTAGTCTTGATATTTTCGTCCATCCATATTTTCCCCAAAACGTAAACAGATTTCACACAAAATCGCTTCCCAACGCGATGTGTGAGTCCGGTTCCTCGTGTAACATCACTAATACACATCACCTTACCAATATGGGAGACATCGTGCCTAGATTCAAACGATTGAACTTTACAAGGGCCTTCACAGCCCCTTGGCACGTCGGGACTTCTATACATCCTGTACATCTTGGGTTTTCTGTTCATCGGCCTGTTTGTCCAGGCCTTTCCCTTTGTGACGCGGGCAATGGGGACAACTGCACGGGAAACATATGGGCTGTCGAAGTTGAGACGTCGGCGTACCTTCGACGCGGGAGTTGA |
|
Protein Sequence
|
MPFAHHLISITMHILHRCSARFIIEHIKNLPKILWSSCRTTVLNQKKYDAISVVFSLDIFVHPYFPQNVNRFHTKSLPNAMCESGSSCNITNTHHLTNMGDIVPRFKRLNFTRAFTAPWHVGTSIHPVHLGFSVHRPVCPGLSLCDAGNGDNCTGNIWAVEVETSAYLRRGS |
|
NCBI Accession
|
YP_293691.1
|
|
Location
|
1053-1463 |
|
Gene Name
|
AC3 |
|
Protein Name
|
replication enhancer |
|
Coding Region
|
ATGATCACGGATTCACGCACAGGGGAGTACATCACTGTGGATCGAGCAGAGAGTGGCGCGTATATCTGGGAAGTTCCAAATCCCCTCTATTTCAAAATAATAAAACACGACATCAGACCTTGTCTAGAGGAACACGACATAATCAAGGTGCAGGTAGTGTTCAACCACAACCTGCGGAAAGCACTGCGGCTTCACAAATGTGCGATAACTTTCCAAATCTGGACGGGCTTACAACCGCCGACTGGGATTTTCTTGAGAGTCTTTAAAACCCAGGTCCTTAAGTACCTGGATAGGTTAGGAGTGATTGGTATTTATAATGTAATAAGAGCAGTTTATCATGTATTGGACGATGTATTGGAAAAGACAATTGATGTATGGACAACATATGATGTGAAATTGAATATATATTAA |
|
Protein Sequence
|
MITDSRTGEYITVDRAESGAYIWEVPNPLYFKIIKHDIRPCLEEHDIIKVQVVFNHNLRKALRLHKCAITFQIWTGLQPPTGIFLRVFKTQVLKYLDRLGVIGIYNVIRAVYHVLDDVLEKTIDVWTTYDVKLNIY |
|
NCBI Accession
|
YP_293692.1
|
|
Location
|
1198-1602 |
|
Gene Name
|
AC2 |
|
Protein Name
|
transcriptional activator |
|
Coding Region
|
ATGCAATCTTCATCACAATCGAAGAACCACTCTATTCCGGTCGCGAAAGCATCGCAACCGCTGAAGAAGAAGAAGAACATCAGACGTAGACGAATTGATCTACCGTGCGGATGCTCGTATTACATGTCAATAAATTGCCATGATCACGGATTCACGCACAGGGGAGTACATCACTGTGGATCGAGCAGAGAGTGGCGCGTATATCTGGGAAGTTCCAAATCCCCTCTATTTCAAAATAATAAAACACGACATCAGACCTTGTCTAGAGGAACACGACATAATCAAGGTGCAGGTAGTGTTCAACCACAACCTGCGGAAAGCACTGCGGCTTCACAAATGTGCGATAACTTTCCAAATCTGGACGGGCTTACAACCGCCGACTGGGATTTTCTTGAGAGTCTTTAA |
|
Protein Sequence
|
MQSSSQSKNHSIPVAKASQPLKKKKNIRRRRIDLPCGCSYYMSINCHDHGFTHRGVHHCGSSREWRVYLGSSKSPLFQNNKTRHQTLSRGTRHNQGAGSVQPQPAESTAASQMCDNFPNLDGLTTADWDFLESL |
|
NCBI Accession
|
YP_293693.1
|
|
Location
|
1514-2590 |
|
Gene Name
|
AC1 |
|
Protein Name
|
replication initiation protein |
|
Coding Region
|
ATGGCTCCTCCTAAGCATTTCAAAATAAGTGCAAAAAACTATTTCCTCACATATCCAAAGTGCTCTCTATCCAAAGAAGAGGCACTTTCCCAATTGCGAACCCTAGAAACTCCAACTTCGAAGAAATTTATCAAAATTTGCAGAGAGTTGCACGAAGATGGGGCTCCGCATATCCACGTTCTTATCCAGTTCGAAGGAAAGTTCCAATGCAAGAATAACAGATTCTTCGACTTGGTGTCCCCAAGTCGGTCAACACATTTCCATCCGAACATTCAGGGAGCTAAATCGGCATCGGACGTCAAACAATACATCGACAAAGACGGGGACGTGTTAGAATGGGGTGTCTTCCAGATCGATGGACGATCTGCTCGTGGAGGTCAACAAACAGCTAACGACGCGTACGCAAGAGCAATAAATACAGGAAACAAAGAAGATGCATTGAAAGTGTTGAAAGAATTAGCACCCAAAGATTACGTTTTGCAATTTCATAATATGAATTCGAATTTAGATCGTATTTTTCCACCTCGTGCTGAGGTGTATGTTTCTCCTTTTTCAATTTCATCCTTCGACAGAGTTCCGCAAGAACTCGTCGATTGGGTTTCAAGTAATGTGGGGTGTTGCGCTGCGCGCCCGAATAGACCCATAGGAATAGTATTAGAGGGTGATAGTAGGACGGGCAAAACAGCGTGGGCGCGTTCGTTAGGACCACACAATTACTTGTGCGGCCATCTAGATCTAAGCCCGAGAGTATACAATAATGATGCTTGGTACAACGTCATTGATGACGTTGATCCCCACTATCTAAAGCATTTTAAAGAATTCATGGGGGCCCAAAGAGACTGGCAAAGCAACACGAAGTACGGAAAGCCAGTCATGATTAAAGGTGGGATTCCCACCATCTTCCTCTGCAATAAAGGACCAAACAGCAGTTACAAAGAATATCTCGATGAAGAAAAGAATGCAGCACTGAAGCAGTGGGCATTAAAGAATGCAATCTTCATCACAATCGAAGAACCACTCTATTCCGGTCGCGAAAGCATCGCAACCGCTGAAGAAGAAGAAGAACATCAGACGTAG |
|
Protein Sequence
|
MAPPKHFKISAKNYFLTYPKCSLSKEEALSQLRTLETPTSKKFIKICRELHEDGAPHIHVLIQFEGKFQCKNNRFFDLVSPSRSTHFHPNIQGAKSASDVKQYIDKDGDVLEWGVFQIDGRSARGGQQTANDAYARAINTGNKEDALKVLKELAPKDYVLQFHNMNSNLDRIFPPRAEVYVSPFSISSFDRVPQELVDWVSSNVGCCAARPNRPIGIVLEGDSRTGKTAWARSLGPHNYLCGHLDLSPRVYNNDAWYNVIDDVDPHYLKHFKEFMGAQRDWQSNTKYGKPVMIKGGIPTIFLCNKGPNSSYKEYLDEEKNAALKQWALKNAIFITIEEPLYSGRESIATAEEEEEHQT |