Spilanthes yellow vein virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_000873265.1 |
| Isolate |
Viet Nam: Dalat |
| Release date |
2015/2/13 |
| Submitter |
Ha,C., Coombs,S., Revill,P., Harding,R., Vu,M., Dale,J., Ha,C.V., Revill,P.A., Harding,R.M., Vu,M.T., Dale,J.L. |
| Host |
|
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
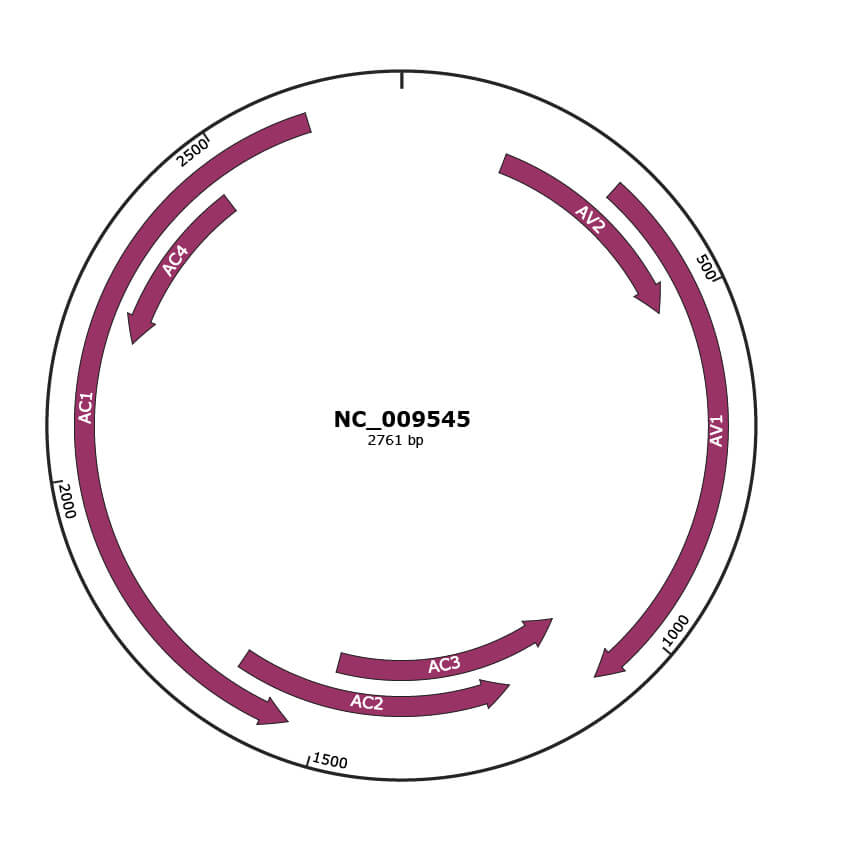
JBrowse
Genome
ACCGGACGGCCGCGATTTTTTATACATGGCCCCACCACGCATTAACAAAGGAAAAAGGAAAAAATGGTCCCCTGGGTTTTATCCAATCAGATCTTTTATTCAAACGTTAATAATAAATGTGGTCCCCTATTAAATGCGCTCCCCCCAAGCAAAATTCAAAAAATGTGGGATCCGCTCCTCCATCCTTTTCCAGAAACCGTACATGGTTTCCGTTGTATGTTAGCCGTAAAGTATTTACAGTTAGTAGAGTCTACGTATTCCCCAGATACGTTAGGGTTTGATCTTATACGTGATTTAATTACAGTAATTAGGTGTAGTAACTATGTCGAAGCGACCAGCAAGTATTGTCATTTCCACGCCCTCATCGAAGGTACGTCGGAGACTCAACTTCGACAGCCCGTATGCGAACCGTGCCTCTGCCCCCATTGTCCGCGTCACAAAGGGTCAGGTATGGACCAACAGACCTATGTTCCGAAAGCCTCGGATGTACAGAATGTTCAGAAGCCCTGATGTTCCCAGAGGTTGTGAGGGTCCTTGTAAGGTTCAGTCTTATGATTCTAAGCATGACATTGGTCATCTTGGTAAGGTACTTTGTGTTTCGGATGTTACCCGTGGTAACGGCCTTACCCATCGTACTGGTAAACGTTTTTGTGTTAAGTCGTTGTATGTTATTGGGAAGATATGGATGGATGAGAAGATTAAGAATAAGAATCATACTAACACCGTTATGTTCTGGTTAGTTAGAGATAGAAGGCCTTCAGGTGTACCTCAGGATTTTCAACAGGTTTTTAATGTTTATGATAATGAACCTGCGACAGCTACTGTGAAGAACGATTCTCGAGATCGTTACCAGGTTTTACGGCGTTTTCAGTCTACTGTTACTGGTGGTCAGTATGCTTCTAAAGAACAGGCTATTATTCGGAAGTTTATCCGTGTAAACACACATGTGACGTATAATCATCAAGAGGATGCGAAATATGCCAATCATACGGAGAATGCTTTGTTATTGTATATGTGTTGTACTCATCATGAGAACCCTGTGTATGGAACTCTAAAGATCCGCAGTTATTTTTACGACTCGGTATCTAATTAATAAATGTTGTATTTTATATCATTTGTCTCTTCGATATCAACTGTACCGTTAAGACGTTCATACAATACATATTTAACTGCTCTAATTACATTATTAACAGAAATTACACCTAAATTATTCAAATACATCATTAATTGGGTCTTGAAGACTCTCAAGAAACGCGATGTCTGAGGTTGTAAGCTCGTCCAGACTCGATAGGTTAGAAAACATTTGTGTATCCCCAATGCTTTCCGAAGGTTGTAGTTGAATTGTATCCTTATTGTTATGATGTCTGTCTCCATGAGGAATGGTCGGTTCTCGTGGTTGATGATCTTGAAATATAGGGGATTTGTTATTGTCCAGATATAGACGCCATTCTCTGCTTGAGCTGCAGTGATAAGTTCCCCTGTGCGAGAATCCATGGTTGACACAGTTTATTGATAGGTAGTATGTGCAACCACACTTCAGGTCAATCCTCCGTCTCCTGATGGTCTTCTTCTTCGCCTCTCGGTGCTGGACCTTGATATTCGGTAGAGTACAATGGCTCGTTGAGGGTGATGAAGATCGCATTGTAATTAGACCACCTCTTGAGCTTTGCGTTCTTTTCCTCTTCTAAAAACTCTGTATATGAAGAGGTTGGACCTGGATTGCAGAGGAAGATAGTGGGTATCCCACCTTTAATTTGAACCGGCTTTCCGTACTTTCTGTTGCTTTGCCAGTTTGTTTGGGACCCCATGAATTCTTTATAGTGCTTTAGATAGTGCGGGTCGACGTCATCTATTACGTTATACCATGCGTCGTTAGAGAACACATTAGGGTTTAAGTCTAAATGTCCACATAAGTAATTATGTGGCCCTAATGACCTGGCCCACAACGTTTTCCCGGTTCGACTTTCACCTTCAATGACAATGCCTTTGGGCCTTAGAGGCCGCGCAGCGGAATTTGTCACAAATTCTTGAGCCCATACCTTCATCATGGTCGGGACATTGTCAAATGCTGTCGTGGGAAATGGACACACAAACGGTTCTGGTGGTTTCTCGAATTCTTTTTCGATATTTGCCACTATGTTGTGCCGTTGTAATAGATATGTCCACGGTTGCTTCTCCTTTACTAATTGCTTGGCAGCATTTACGGATGTTGCGTTCCAGACCTCTGCACCAAGATCGTTAAGATCCTGTTGGCCTCCTCTAGCACTCCTTCCGTCGATCTGGAATTCTCCCCATTCCAGTGTGTCTCCGTCCTTGTCGATATAGGACTTGACATCGGAGCTTGATTTAGCTCCCTGTATGTTCGGATGGAAATGTGTTGACCGGGTTGGGGATACAAGGTCGAAGAATCGTTTATTCGTGCAGACGTATTTCCCCTCGAATTGAATAAGCACGTGGAGATGAGGGCTCCCATCTTCGTGTAGCTCTCTGCAGATTTTAATGAATTTTTTATTTGTTGGACAAACTAGGTTACTTAATTGGGAAAGTGTTTCTTCTTTGGTGAGAGAGCAGTGTGGGTATGTAAGAAAATAATTTCTGGCTGAAACTCTAAATCTGTTATTCGGAGCCATTTATTGCTCTGGATTGGTGACACTCTGAGCTCGAAGAGTATAATAGTATTGGTGACTGGTGTACAATATATAGAGGTGAGTAAAAGCCTCAAATTCCACGTGGAATCTATCGCGGCCGTCCTTATAATATT
Gene Information
|
NCBI Accession
|
YP_001285760.1
|
|
Location
|
163-510 |
|
Gene Name
|
AV2 |
|
Protein Name
|
AV2 protein |
|
Coding Region
|
ATGTGGGATCCGCTCCTCCATCCTTTTCCAGAAACCGTACATGGTTTCCGTTGTATGTTAGCCGTAAAGTATTTACAGTTAGTAGAGTCTACGTATTCCCCAGATACGTTAGGGTTTGATCTTATACGTGATTTAATTACAGTAATTAGGTGTAGTAACTATGTCGAAGCGACCAGCAAGTATTGTCATTTCCACGCCCTCATCGAAGGTACGTCGGAGACTCAACTTCGACAGCCCGTATGCGAACCGTGCCTCTGCCCCCATTGTCCGCGTCACAAAGGGTCAGGTATGGACCAACAGACCTATGTTCCGAAAGCCTCGGATGTACAGAATGTTCAGAAGCCCTGA |
|
Protein Sequence
|
MWDPLLHPFPETVHGFRCMLAVKYLQLVESTYSPDTLGFDLIRDLITVIRCSNYVEATSKYCHFHALIEGTSETQLRQPVCEPCLCPHCPRHKGSGMDQQTYVPKASDVQNVQKP |
|
NCBI Accession
|
YP_001285761.1
|
|
Location
|
323-1093 |
|
Gene Name
|
AV1 |
|
Protein Name
|
CP protein |
|
Coding Region
|
ATGTCGAAGCGACCAGCAAGTATTGTCATTTCCACGCCCTCATCGAAGGTACGTCGGAGACTCAACTTCGACAGCCCGTATGCGAACCGTGCCTCTGCCCCCATTGTCCGCGTCACAAAGGGTCAGGTATGGACCAACAGACCTATGTTCCGAAAGCCTCGGATGTACAGAATGTTCAGAAGCCCTGATGTTCCCAGAGGTTGTGAGGGTCCTTGTAAGGTTCAGTCTTATGATTCTAAGCATGACATTGGTCATCTTGGTAAGGTACTTTGTGTTTCGGATGTTACCCGTGGTAACGGCCTTACCCATCGTACTGGTAAACGTTTTTGTGTTAAGTCGTTGTATGTTATTGGGAAGATATGGATGGATGAGAAGATTAAGAATAAGAATCATACTAACACCGTTATGTTCTGGTTAGTTAGAGATAGAAGGCCTTCAGGTGTACCTCAGGATTTTCAACAGGTTTTTAATGTTTATGATAATGAACCTGCGACAGCTACTGTGAAGAACGATTCTCGAGATCGTTACCAGGTTTTACGGCGTTTTCAGTCTACTGTTACTGGTGGTCAGTATGCTTCTAAAGAACAGGCTATTATTCGGAAGTTTATCCGTGTAAACACACATGTGACGTATAATCATCAAGAGGATGCGAAATATGCCAATCATACGGAGAATGCTTTGTTATTGTATATGTGTTGTACTCATCATGAGAACCCTGTGTATGGAACTCTAAAGATCCGCAGTTATTTTTACGACTCGGTATCTAATTAA |
|
Protein Sequence
|
MSKRPASIVISTPSSKVRRRLNFDSPYANRASAPIVRVTKGQVWTNRPMFRKPRMYRMFRSPDVPRGCEGPCKVQSYDSKHDIGHLGKVLCVSDVTRGNGLTHRTGKRFCVKSLYVIGKIWMDEKIKNKNHTNTVMFWLVRDRRPSGVPQDFQQVFNVYDNEPATATVKNDSRDRYQVLRRFQSTVTGGQYASKEQAIIRKFIRVNTHVTYNHQEDAKYANHTENALLLYMCCTHHENPVYGTLKIRSYFYDSVSN |
|
NCBI Accession
|
YP_001285762.1
|
|
Location
|
1090-1494 |
|
Gene Name
|
AC3 |
|
Protein Name
|
REn protein |
|
Coding Region
|
ATGGATTCTCGCACAGGGGAACTTATCACTGCAGCTCAAGCAGAGAATGGCGTCTATATCTGGACAATAACAAATCCCCTATATTTCAAGATCATCAACCACGAGAACCGACCATTCCTCATGGAGACAGACATCATAACAATAAGGATACAATTCAACTACAACCTTCGGAAAGCATTGGGGATACACAAATGTTTTCTAACCTATCGAGTCTGGACGAGCTTACAACCTCAGACATCGCGTTTCTTGAGAGTCTTCAAGACCCAATTAATGATGTATTTGAATAATTTAGGTGTAATTTCTGTTAATAATGTAATTAGAGCAGTTAAATATGTATTGTATGAACGTCTTAACGGTACAGTTGATATCGAAGAGACAAATGATATAAAATACAACATTTATTAA |
|
Protein Sequence
|
MDSRTGELITAAQAENGVYIWTITNPLYFKIINHENRPFLMETDIITIRIQFNYNLRKALGIHKCFLTYRVWTSLQPQTSRFLRVFKTQLMMYLNNLGVISVNNVIRAVKYVLYERLNGTVDIEETNDIKYNIY |
|
NCBI Accession
|
YP_001285763.1
|
|
Location
|
1208-1642 |
|
Gene Name
|
AC2 |
|
Protein Name
|
TrAP protein |
|
Coding Region
|
ATGCGATCTTCATCACCCTCAACGAGCCATTGTACTCTACCGAATATCAAGGTCCAGCACCGAGAGGCGAAGAAGAAGACCATCAGGAGACGGAGGATTGACCTGAAGTGTGGTTGCACATACTACCTATCAATAAACTGTGTCAACCATGGATTCTCGCACAGGGGAACTTATCACTGCAGCTCAAGCAGAGAATGGCGTCTATATCTGGACAATAACAAATCCCCTATATTTCAAGATCATCAACCACGAGAACCGACCATTCCTCATGGAGACAGACATCATAACAATAAGGATACAATTCAACTACAACCTTCGGAAAGCATTGGGGATACACAAATGTTTTCTAACCTATCGAGTCTGGACGAGCTTACAACCTCAGACATCGCGTTTCTTGAGAGTCTTCAAGACCCAATTAATGATGTATTTGAATAA |
|
Protein Sequence
|
MRSSSPSTSHCTLPNIKVQHREAKKKTIRRRRIDLKCGCTYYLSINCVNHGFSHRGTYHCSSSREWRLYLDNNKSPIFQDHQPREPTIPHGDRHHNNKDTIQLQPSESIGDTQMFSNLSSLDELTTSDIAFLESLQDPINDVFE |
|
NCBI Accession
|
YP_001285764.1
|
|
Location
|
1542-2630 |
|
Gene Name
|
AC1 |
|
Protein Name
|
rep protein |
|
Coding Region
|
ATGGCTCCGAATAACAGATTTAGAGTTTCAGCCAGAAATTATTTTCTTACATACCCACACTGCTCTCTCACCAAAGAAGAAACACTTTCCCAATTAAGTAACCTAGTTTGTCCAACAAATAAAAAATTCATTAAAATCTGCAGAGAGCTACACGAAGATGGGAGCCCTCATCTCCACGTGCTTATTCAATTCGAGGGGAAATACGTCTGCACGAATAAACGATTCTTCGACCTTGTATCCCCAACCCGGTCAACACATTTCCATCCGAACATACAGGGAGCTAAATCAAGCTCCGATGTCAAGTCCTATATCGACAAGGACGGAGACACACTGGAATGGGGAGAATTCCAGATCGACGGAAGGAGTGCTAGAGGAGGCCAACAGGATCTTAACGATCTTGGTGCAGAGGTCTGGAACGCAACATCCGTAAATGCTGCCAAGCAATTAGTAAAGGAGAAGCAACCGTGGACATATCTATTACAACGGCACAACATAGTGGCAAATATCGAAAAAGAATTCGAGAAACCACCAGAACCGTTTGTGTGTCCATTTCCCACGACAGCATTTGACAATGTCCCGACCATGATGAAGGTATGGGCTCAAGAATTTGTGACAAATTCCGCTGCGCGGCCTCTAAGGCCCAAAGGCATTGTCATTGAAGGTGAAAGTCGAACCGGGAAAACGTTGTGGGCCAGGTCATTAGGGCCACATAATTACTTATGTGGACATTTAGACTTAAACCCTAATGTGTTCTCTAACGACGCATGGTATAACGTAATAGATGACGTCGACCCGCACTATCTAAAGCACTATAAAGAATTCATGGGGTCCCAAACAAACTGGCAAAGCAACAGAAAGTACGGAAAGCCGGTTCAAATTAAAGGTGGGATACCCACTATCTTCCTCTGCAATCCAGGTCCAACCTCTTCATATACAGAGTTTTTAGAAGAGGAAAAGAACGCAAAGCTCAAGAGGTGGTCTAATTACAATGCGATCTTCATCACCCTCAACGAGCCATTGTACTCTACCGAATATCAAGGTCCAGCACCGAGAGGCGAAGAAGAAGACCATCAGGAGACGGAGGATTGA |
|
Protein Sequence
|
MAPNNRFRVSARNYFLTYPHCSLTKEETLSQLSNLVCPTNKKFIKICRELHEDGSPHLHVLIQFEGKYVCTNKRFFDLVSPTRSTHFHPNIQGAKSSSDVKSYIDKDGDTLEWGEFQIDGRSARGGQQDLNDLGAEVWNATSVNAAKQLVKEKQPWTYLLQRHNIVANIEKEFEKPPEPFVCPFPTTAFDNVPTMMKVWAQEFVTNSAARPLRPKGIVIEGESRTGKTLWARSLGPHNYLCGHLDLNPNVFSNDAWYNVIDDVDPHYLKHYKEFMGSQTNWQSNRKYGKPVQIKGGIPTIFLCNPGPTSSYTEFLEEEKNAKLKRWSNYNAIFITLNEPLYSTEYQGPAPRGEEEDHQETED |
|
NCBI Accession
|
YP_001285765.1
|
|
Location
|
2201-2473 |
|
Gene Name
|
AC4 |
|
Protein Name
|
AC4 protein |
|
Coding Region
|
ATGGGAGCCCTCATCTCCACGTGCTTATTCAATTCGAGGGGAAATACGTCTGCACGAATAAACGATTCTTCGACCTTGTATCCCCAACCCGGTCAACACATTTCCATCCGAACATACAGGGAGCTAAATCAAGCTCCGATGTCAAGTCCTATATCGACAAGGACGGAGACACACTGGAATGGGGAGAATTCCAGATCGACGGAAGGAGTGCTAGAGGAGGCCAACAGGATCTTAACGATCTTGGTGCAGAGGTCTGGAACGCAACATCCGTAA |
|
Protein Sequence
|
MGALISTCLFNSRGNTSARINDSSTLYPQPGQHISIRTYRELNQAPMSSPISTRTETHWNGENSRSTEGVLEEANRILTILVQRSGTQHP |