Soybean mild mottle virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_000888375.1 |
| Isolate |
Nigeria |
| Release date |
2015/2/22 |
| Submitter |
Alabi,O.J., Kumar,P.L., Mgbechi-Ezeri,J.U., Naidu,R.A. |
| Host |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
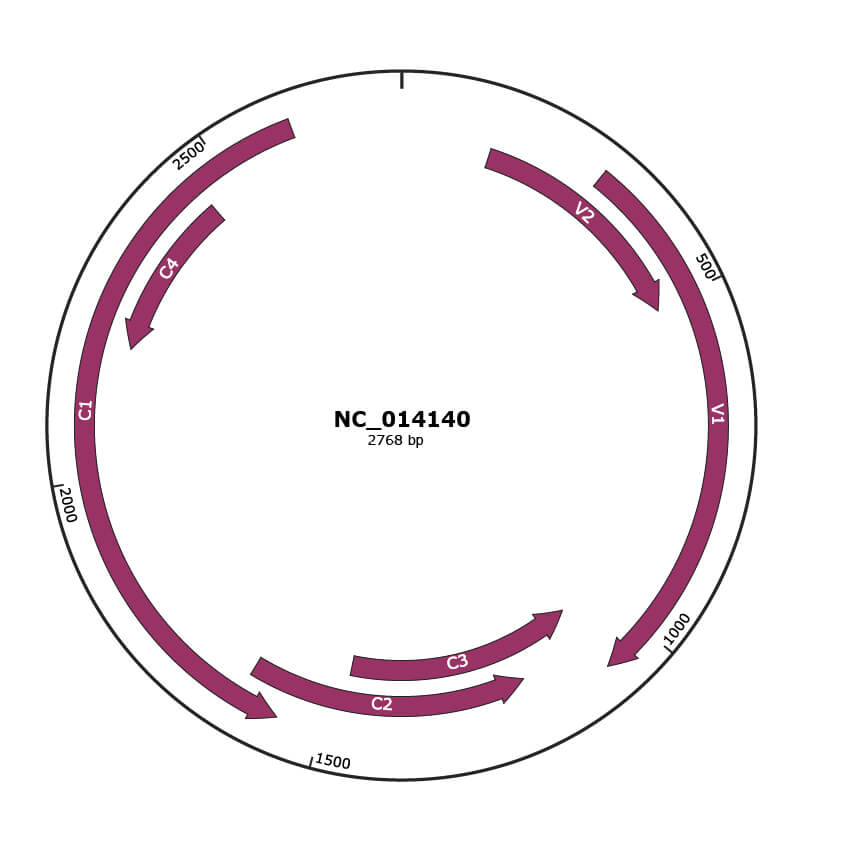
Genomic Organization
JBrowse
Genome
ACAGGGATGGCCGCGCCCGCCCCCCCTTTATTGTGGCGCCCACATCTTTGATTTCAGCCAATCAGGAAGCAGCCTCAATCCTTATTTATCTGTTTCTCCACTATAAACTTGTTGCGCAAGTTGGTATTTGAATTAAAGATGTGGGATCCTCTGCAGAACCCGTTTCCCCATACCGTACACGGTCTTCGATGTATGCTTGCGATAAAGTACGTGCAATTGGTGATTGACACGTACCCCCAAGACAGTATAGGCGAGGATCTATTGCGCCAGATTATTCAGATATTGAGGTGCAGGAACCATGACCAAGCGGAGTTTCGATACAGCATTCTCTTCGCCGATGTCGAACGTACGGAGAAGACTCAGCTTCGCAACCCCTATGGCACTACCTGCACCTGCCGTTTCTGTCCCAAACACGTACAAGCGAAGAGCTTGGAGGAACCGACCCATGTACAGGAAGCCCAGAATTTACAGGATGTATCGTTCGAGAGATGTTCCAAAGGGGTGTGAAGGTCCTTGTAAGGTTCAGTCTTACGATCAGCGGTTCGACTGTAAGCACACGGGCAGTGTGCTGTGTGTTTCAGATATTACTCGCGGAACTGGTCTTACCCATCGTGTTGGTAAGCGTTTCTGCATAAAATCCATGATGTTCAAAGGTAAAGTCTGGATGGACGACAACATCAAGGCTAAGAGCCATACGAATCACGTAATGTTTTTCTTGGTACGTGATAGAAGGCCTTATGGCTCCCCCATGGATTTTGGTCAGGTGTTCAACATGTTTGACAATGAGCCCAGTACTGCTACAGTTAAGCAGGATTATCGAGACCGTTTTCAGGTCATGAGACGATGGTACGTAGGAGTCACCGGTGGTCAGTATGCGTCGAAGGAACAGGCGTTAGTTAATAAGTTTTTTTATTGTAACAATTATGTTGTTTACAATCACCAGGAGGCTGGAAAGTACGAGAACCACACTGAGAACGCATTGTTATTGTATATGGCATGTACTCATGCCTCAAATCCAGTGTATGCAACTCTAAAAATACGGGTCTATTTTTATGACTCAATCAGCAATTAATAAAGATTGAATTTTATATCATATTTAATCTCGAAATGGGATACAATGACGAACTGCTCAAGCAATACTTTGTTGATAGCAGTCTGGACACTTAAAATAGAAATTGAACCTATACTATTCAAGAACGACATCATTAAAAACTTGAAAGCTCGAAAAAATCTCCAGTTCTGACTCTGTGAGTGGAGAAAGATCTTTAAATCCAGGAAGCATTTGTGAATCTCCAACTTCCTCTTGACACAGTTGTTGAACATTATTCGAATGTTCATCTCGTCGTATGGGAGACCCATCACCCCATAGTCTTCCCGGAGGAGTTTGAAACAGAGGGGATTGTTCACCTCCCAGATATACACGCCACGCTCTAGTTCCGATTGTGTGAGTAACTCCCCTGTGCGAGAATCCATGGTCTGTGCAGTCGAGGTGAACGTATATAGAACACCCACAAGGACAGTCTATGCGACGCCGTCTAGTCGCCCTATGACGCTTTGCGTCCCTATGTTGAGCCTTGATGTTCGGTGGAGAACAGTGGCTCTTCGAGGGTGTAGAAGATCGCATTTTTTAAAGCCCACTCCTTAAGCGCTGCATTCGACTCCTCATCCATATATTCTTTATAGGAAGATCTGGGGCCAGGATTGCAGAGGAAAATTGTTGGTATTCCACCTTTAATTTGAGTGGGCTTGCCGTACTTCACGTTGCTTTGCCAGTCTCTTTGGGACCCCATGAATTCTTTCATATGCTTTAGATAGTGGGGATCTACGTCATCGATGACGTTGTACCAGGCATCGTTTGAATAGACCTTGGCGCTGAGATCTAAATGACCACATAGGTAATTGTGCCTACCAAGGCTTCTGGCCCACATCGTCTTCCCCGTCCTGGATTCACCTTCCAGGACGATGCTTATGGGTCTCATCGGCCGCGCAGCGGAAGCTTTCACATTATCTGATGCCCATTGAGACAGAACTTCCGGCACATTGTTAAATTGTTCAACTTTAAAAGGCGATTTGTAAATCGTCGTTGGAGGCGTAAAAATCTTATTGAGGTTGCTAATAACATTATGATACTGAAAAACATAATCTCGTGGAAGCTGCTCTTTGATGATCTGTAAAGCAGCTTCAGCGGAACCAGCATTTAATGCCGACGCACATGCGTCGTTAGCATTTTTGCAACCTCCTCTGGCACTTCGACCATCAATCTGGAAAGACCCCCATTGTATGGTGTCTCCGTCTTTGTCGATGTATGTTTTGACGTCCGAACTTGATTTAGCTCCCTGAATGTTCGGATGGAAATGTGTTGACCTTCTTGGGGAAGTGAGGTCGAAGTGTCTTTCGTTCGTAATTTGACACTTTCCTTCAAACTGGATAAGCACATGGAGATGTGGTTCCCCATTCTCGTGTAGTTCACGAGCTATCTTGATGAACTTCTTGTTAGATGGACATTGAATGCTCTGCAATTGTGAAAGTGCTTCTTCTTTTGTGAGAGAACATCTGGGATATGTGAGGAAAATGTTCTTTGCCTTCACACAAAAATAACCACTCCGGGGCATATCGGTAAAAGCAAATGTACCCCCAATTGCCCCCCCCTTCTAAAACTCTATACAATTGGGGGTAATGGGGGTGAATATATACCTACTACTATTAAATTCTCTTTAGCGAGGATTTCAAATCCGCCACGTGTACAAAAGGCCATCCCTTATAATATT
Gene Information
|
NCBI Accession
|
YP_003622548.1
|
|
Location
|
139-507 |
|
Gene Name
|
V2 |
|
Protein Name
|
pre-coat protein |
|
Coding Region
|
ATGTGGGATCCTCTGCAGAACCCGTTTCCCCATACCGTACACGGTCTTCGATGTATGCTTGCGATAAAGTACGTGCAATTGGTGATTGACACGTACCCCCAAGACAGTATAGGCGAGGATCTATTGCGCCAGATTATTCAGATATTGAGGTGCAGGAACCATGACCAAGCGGAGTTTCGATACAGCATTCTCTTCGCCGATGTCGAACGTACGGAGAAGACTCAGCTTCGCAACCCCTATGGCACTACCTGCACCTGCCGTTTCTGTCCCAAACACGTACAAGCGAAGAGCTTGGAGGAACCGACCCATGTACAGGAAGCCCAGAATTTACAGGATGTATCGTTCGAGAGATGTTCCAAAGGGGTGTGA |
|
Protein Sequence
|
MWDPLQNPFPHTVHGLRCMLAIKYVQLVIDTYPQDSIGEDLLRQIIQILRCRNHDQAEFRYSILFADVERTEKTQLRNPYGTTCTCRFCPKHVQAKSLEEPTHVQEAQNLQDVSFERCSKGV |
|
NCBI Accession
|
YP_003622549.1
|
|
Location
|
299-1072 |
|
Gene Name
|
V1 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGACCAAGCGGAGTTTCGATACAGCATTCTCTTCGCCGATGTCGAACGTACGGAGAAGACTCAGCTTCGCAACCCCTATGGCACTACCTGCACCTGCCGTTTCTGTCCCAAACACGTACAAGCGAAGAGCTTGGAGGAACCGACCCATGTACAGGAAGCCCAGAATTTACAGGATGTATCGTTCGAGAGATGTTCCAAAGGGGTGTGAAGGTCCTTGTAAGGTTCAGTCTTACGATCAGCGGTTCGACTGTAAGCACACGGGCAGTGTGCTGTGTGTTTCAGATATTACTCGCGGAACTGGTCTTACCCATCGTGTTGGTAAGCGTTTCTGCATAAAATCCATGATGTTCAAAGGTAAAGTCTGGATGGACGACAACATCAAGGCTAAGAGCCATACGAATCACGTAATGTTTTTCTTGGTACGTGATAGAAGGCCTTATGGCTCCCCCATGGATTTTGGTCAGGTGTTCAACATGTTTGACAATGAGCCCAGTACTGCTACAGTTAAGCAGGATTATCGAGACCGTTTTCAGGTCATGAGACGATGGTACGTAGGAGTCACCGGTGGTCAGTATGCGTCGAAGGAACAGGCGTTAGTTAATAAGTTTTTTTATTGTAACAATTATGTTGTTTACAATCACCAGGAGGCTGGAAAGTACGAGAACCACACTGAGAACGCATTGTTATTGTATATGGCATGTACTCATGCCTCAAATCCAGTGTATGCAACTCTAAAAATACGGGTCTATTTTTATGACTCAATCAGCAATTAA |
|
Protein Sequence
|
MTKRSFDTAFSSPMSNVRRRLSFATPMALPAPAVSVPNTYKRRAWRNRPMYRKPRIYRMYRSRDVPKGCEGPCKVQSYDQRFDCKHTGSVLCVSDITRGTGLTHRVGKRFCIKSMMFKGKVWMDDNIKAKSHTNHVMFFLVRDRRPYGSPMDFGQVFNMFDNEPSTATVKQDYRDRFQVMRRWYVGVTGGQYASKEQALVNKFFYCNNYVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRVYFYDSISN |
|
NCBI Accession
|
YP_003622550.1
|
|
Location
|
1069-1473 |
|
Gene Name
|
C3 |
|
Protein Name
|
replication enhancer |
|
Coding Region
|
ATGGATTCTCGCACAGGGGAGTTACTCACACAATCGGAACTAGAGCGTGGCGTGTATATCTGGGAGGTGAACAATCCCCTCTGTTTCAAACTCCTCCGGGAAGACTATGGGGTGATGGGTCTCCCATACGACGAGATGAACATTCGAATAATGTTCAACAACTGTGTCAAGAGGAAGTTGGAGATTCACAAATGCTTCCTGGATTTAAAGATCTTTCTCCACTCACAGAGTCAGAACTGGAGATTTTTTCGAGCTTTCAAGTTTTTAATGATGTCGTTCTTGAATAGTATAGGTTCAATTTCTATTTTAAGTGTCCAGACTGCTATCAACAAAGTATTGCTTGAGCAGTTCGTCATTGTATCCCATTTCGAGATTAAATATGATATAAAATTCAATCTTTATTAA |
|
Protein Sequence
|
MDSRTGELLTQSELERGVYIWEVNNPLCFKLLREDYGVMGLPYDEMNIRIMFNNCVKRKLEIHKCFLDLKIFLHSQSQNWRFFRAFKFLMMSFLNSIGSISILSVQTAINKVLLEQFVIVSHFEIKYDIKFNLY |
|
NCBI Accession
|
YP_003622551.1
|
|
Location
|
1187-1624 |
|
Gene Name
|
C2 |
|
Protein Name
|
transcriptional activator protein |
|
Coding Region
|
ATGCGATCTTCTACACCCTCGAAGAGCCACTGTTCTCCACCGAACATCAAGGCTCAACATAGGGACGCAAAGCGTCATAGGGCGACTAGACGGCGTCGCATAGACTGTCCTTGTGGGTGTTCTATATACGTTCACCTCGACTGCACAGACCATGGATTCTCGCACAGGGGAGTTACTCACACAATCGGAACTAGAGCGTGGCGTGTATATCTGGGAGGTGAACAATCCCCTCTGTTTCAAACTCCTCCGGGAAGACTATGGGGTGATGGGTCTCCCATACGACGAGATGAACATTCGAATAATGTTCAACAACTGTGTCAAGAGGAAGTTGGAGATTCACAAATGCTTCCTGGATTTAAAGATCTTTCTCCACTCACAGAGTCAGAACTGGAGATTTTTTCGAGCTTTCAAGTTTTTAATGATGTCGTTCTTGAATAG |
|
Protein Sequence
|
MRSSTPSKSHCSPPNIKAQHRDAKRHRATRRRRIDCPCGCSIYVHLDCTDHGFSHRGVTHTIGTRAWRVYLGGEQSPLFQTPPGRLWGDGSPIRRDEHSNNVQQLCQEEVGDSQMLPGFKDLSPLTESELEIFSSFQVFNDVVLE |
|
NCBI Accession
|
YP_003622552.1
|
|
Location
|
1563-2612 |
|
Gene Name
|
C1 |
|
Protein Name
|
replication-associated protein |
|
Coding Region
|
ATGCCCCGGAGTGGTTATTTTTGTGTGAAGGCAAAGAACATTTTCCTCACATATCCCAGATGTTCTCTCACAAAAGAAGAAGCACTTTCACAATTGCAGAGCATTCAATGTCCATCTAACAAGAAGTTCATCAAGATAGCTCGTGAACTACACGAGAATGGGGAACCACATCTCCATGTGCTTATCCAGTTTGAAGGAAAGTGTCAAATTACGAACGAAAGACACTTCGACCTCACTTCCCCAAGAAGGTCAACACATTTCCATCCGAACATTCAGGGAGCTAAATCAAGTTCGGACGTCAAAACATACATCGACAAAGACGGAGACACCATACAATGGGGGTCTTTCCAGATTGATGGTCGAAGTGCCAGAGGAGGTTGCAAAAATGCTAACGACGCATGTGCGTCGGCATTAAATGCTGGTTCCGCTGAAGCTGCTTTACAGATCATCAAAGAGCAGCTTCCACGAGATTATGTTTTTCAGTATCATAATGTTATTAGCAACCTCAATAAGATTTTTACGCCTCCAACGACGATTTACAAATCGCCTTTTAAAGTTGAACAATTTAACAATGTGCCGGAAGTTCTGTCTCAATGGGCATCAGATAATGTGAAAGCTTCCGCTGCGCGGCCGATGAGACCCATAAGCATCGTCCTGGAAGGTGAATCCAGGACGGGGAAGACGATGTGGGCCAGAAGCCTTGGTAGGCACAATTACCTATGTGGTCATTTAGATCTCAGCGCCAAGGTCTATTCAAACGATGCCTGGTACAACGTCATCGATGACGTAGATCCCCACTATCTAAAGCATATGAAAGAATTCATGGGGTCCCAAAGAGACTGGCAAAGCAACGTGAAGTACGGCAAGCCCACTCAAATTAAAGGTGGAATACCAACAATTTTCCTCTGCAATCCTGGCCCCAGATCTTCCTATAAAGAATATATGGATGAGGAGTCGAATGCAGCGCTTAAGGAGTGGGCTTTAAAAAATGCGATCTTCTACACCCTCGAAGAGCCACTGTTCTCCACCGAACATCAAGGCTCAACATAG |
|
Protein Sequence
|
MPRSGYFCVKAKNIFLTYPRCSLTKEEALSQLQSIQCPSNKKFIKIARELHENGEPHLHVLIQFEGKCQITNERHFDLTSPRRSTHFHPNIQGAKSSSDVKTYIDKDGDTIQWGSFQIDGRSARGGCKNANDACASALNAGSAEAALQIIKEQLPRDYVFQYHNVISNLNKIFTPPTTIYKSPFKVEQFNNVPEVLSQWASDNVKASAARPMRPISIVLEGESRTGKTMWARSLGRHNYLCGHLDLSAKVYSNDAWYNVIDDVDPHYLKHMKEFMGSQRDWQSNVKYGKPTQIKGGIPTIFLCNPGPRSSYKEYMDEESNAALKEWALKNAIFYTLEEPLFSTEHQGST |
|
NCBI Accession
|
YP_003622553.1
|
|
Location
|
2198-2455 |
|
Gene Name
|
C4 |
|
Protein Name
|
C4 protein |
|
Coding Region
|
ATGGGGAACCACATCTCCATGTGCTTATCCAGTTTGAAGGAAAGTGTCAAATTACGAACGAAAGACACTTCGACCTCACTTCCCCAAGAAGGTCAACACATTTCCATCCGAACATTCAGGGAGCTAAATCAAGTTCGGACGTCAAAACATACATCGACAAAGACGGAGACACCATACAATGGGGGTCTTTCCAGATTGATGGTCGAAGTGCCAGAGGAGGTTGCAAAAATGCTAACGACGCATGTGCGTCGGCATTAA |
|
Protein Sequence
|
MGNHISMCLSSLKESVKLRTKDTSTSLPQEGQHISIRTFRELNQVRTSKHTSTKTETPYNGGLSRLMVEVPEEVAKMLTTHVRRH |