South African cassava mosaic virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_000838365.1 |
| Release date |
2015/2/12 |
| Submitter |
Berrie,L.C., Rybicki,E.P., Rey,M.E., Rey,M.E.C. |
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
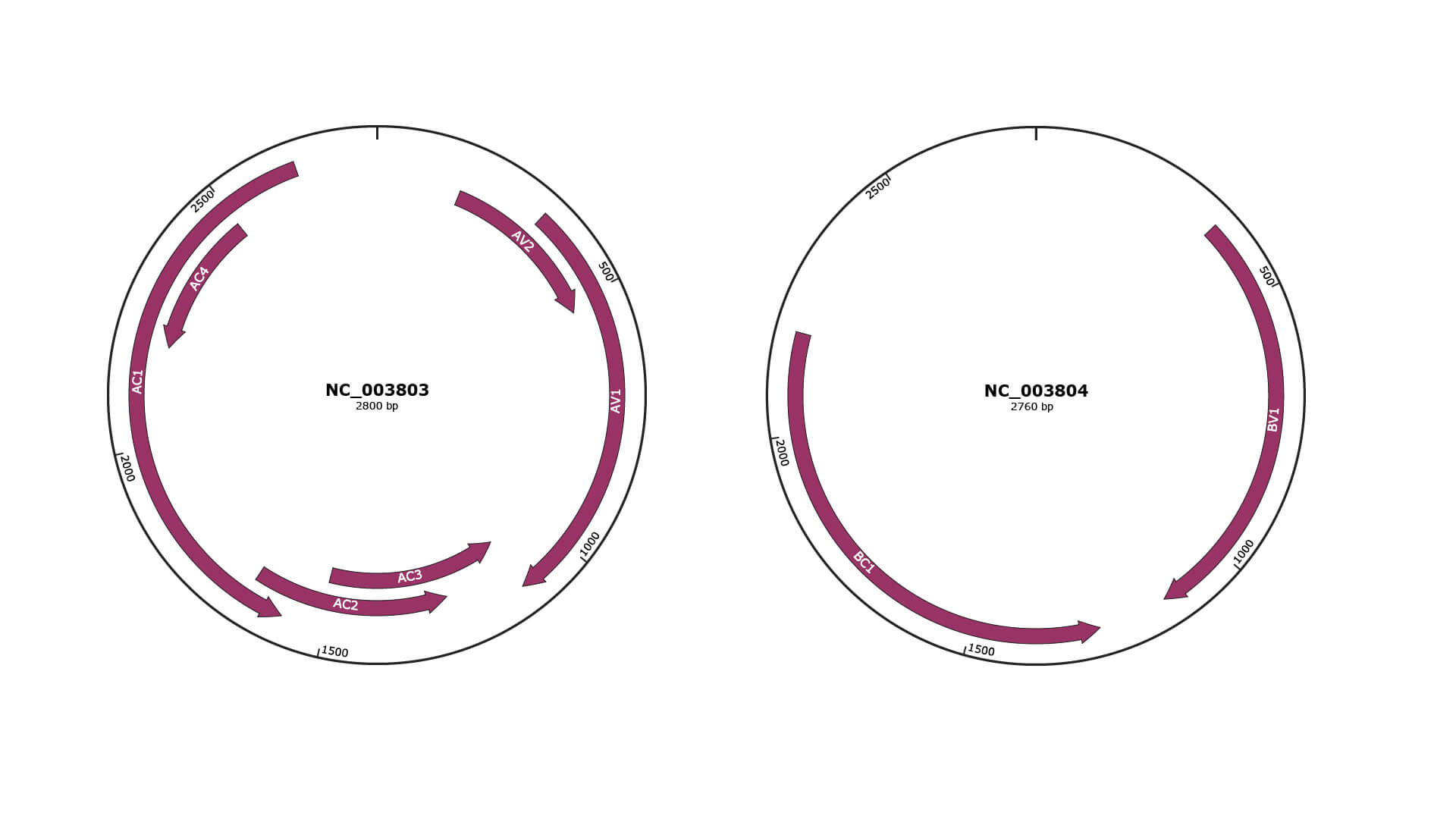
JBrowse
Genome
ACCGGATGGCCGCGCCCGACAAAGTAGGTGGACCCCATTGGATGACCGCGCCCGTAAAAGAAAGTGGTCCCCACGCACGTGTTGCTGTCGGCCAGTCATATTCACGCGTGAAAGCCTAGATATTTGTTTTATGTCGTTATAGACTTCGTCGCGAAGTAGTGGAGCGTGTCAACATGTGGGATCCATTGTTGAATGAGTTCCCCGAGTCTGTGCACGGTTTTCGCTGTATGCTTGCTATTAAATATTTGCAGGCCTTGGAGGAAACCTACGAGCCCAATACTTTGGGCCACGATCTAGTCCGTGATCTCATCGGTGTGATCCGAGCCCGTGATTATGTCGAAGCGTCCCGCCGATATAATCATTTCCACTCCCGTCTCGAAGGTGCGTCGAAGGCTGAACTTCGACAGCCCGTTCAGCAGCCGTGCTGCTGTCCCCATTGTCCAAGGCACAAACAAGCGTCGATCATGGACGTTCCGGCCCATGTACCGAAAGCCCAGAATGTACAGAATGTTCAAAAGCCCTGATGTTCCGCGTGGCTGTGAAGGCCCATGTAAGGTTCAATCTTATGAACAGCGAGATGACGTTAAGCATACTGGCAGTGTTCGTTGTGTTAGTGATGTCACGCGTGGTTCGGGAATTACACATAGAGTAGGTAAAAGGTTCTGTATCAAGTCTATATATGTGTTAGGTAAGATATGGATGGATGAAAACATCAAGAAGCAGAACCATACAAACCAGGTCATGTTCTTCTTAGTCCGTGACAGAAGGCCCTATGGCAATAGCCCCATGGACTTTGGACAGGTTTTTAATATGTTTGATAATGAGCCCAGTACAGCCACTGTGAAGAACGATCTTAGGGATAGGTATCGAGTTATGCGGAAGTTTCATGCCACCGTTGTTGGGGGTCCTTCTGGAATGAAGGAGCAGGCTTTGGTGAGGAGATTTTTTAGGATAAATAATCATGTTGTGTATAATCACCAGGAGGCAGCTAAGTATGAGAATCATACAGAGAATGCGTTATTGTTGTATATGGCATGTACGCATGCCTCTAATCCAGTGTATGCTACGCTTAAAATACGCATCTATTTTTATGATGCAGTAACAAATTAATAAAGGTTGAATTTTATTGCATGTTGCTCCGTAACTTGGAGTGTGTTTAGTAATACATCGTACAGAACATGATCAACAGCTCTGAGTACAGTGTTAATGGAAATAACGCCTATCATATTTAAATACTTGAGCACTTGATATTTAAATACTCTTAAGAAAAGACCAGTCGGAGGCCGTAAGGTCGTCCAGACCTTGAAGTTGAGAAAACACTTGTGAATCCCCAATGCCTTCCTGATGTTGTGGTTGAACCGTATCTGGAGGGTGATGATGTCGTGGTTCATGTTCCCTGGCCGCTTGTCGTGGTTGGTGATGTCGAAATAGAGGGGATTTGTTATTTCCCAGGTAAAAACGCCATTCTTTGCTTGAGGCGCAGTGATGAGTTCCCCTGTGCGAGAATCCATGGTTGATGCAGTCGATATGGAGATAGAACGAGCAGCCGCATTCGAGGTCTACCCTCCTACGTCTGAGGGCCCTAGTCTTCGCGGTGCGGTGTTGGACTTTGATGGGCACTTGAGAACAATGGCTCGTGGAGGGTGATGAAGGTTGCATTCTTTAAAGCCCAGGCTTTAAGGGACTGGTTCTTTTCCTCGTCCAGAAACTCTTTATATGATGATGTCGGTCCTGGATTGCATAGGAAGATAGTGGGAATGCCGCCTTTAATTTGAATCGGCTTCCCGTACTTGGTATTGCTTTGCCAGTCCCTTTGGGCCCCCATGAATTCTTTGAAGTGCTTGAGGTAATGGGGGTCGACGTCATCAATGACGTTGTACCATGCGTCGTTGCTGTAAACCTTTGGACTGAGATCCAAATGTCCACATAAGTAGTTGTGTGGTCCCAGAGATCGGGCCCACATCGTCTTCCCTGTCCTACTATCGCCCTCGATGACGATACTACTCGGTCTCCATGGCCGCGCAGCGAAACCCATCACGTTCTCGGAAACCCAGTCTTCAAGTTCCTCAGGAACATGAGTGAAAGAAGAAGAAAGAAAGGGAGAAATATAAGGAATCGGAGGCTCCTGAAAAATCCTATCTAAATTGCTATTTAAATTATGAAACTGTAAAACAAAATCCTTTGGGGCTAGTTCCCGGATTACATTAAGAGCCTCTGTTTTACTTGCTGCGTTAAGAGCCTTGGCGTAAGCGTCATTGGCGGATTGTTGTCCGCCGCGAGCAGATCGTCCGTCGATCTGAAACTCGCCCCATTGGATGGTGTCTCCGTCCTTGTCCAAATAGGACTTGACGTCAGAACTGGATTTAGCTCCCTGAATGTTTGGATGGAAATGTGTTGACCTGGAAGGGGATATGAGGTCGAAGAATCGTTGGTTGGTACAATTGTACTTGCCCTCGAACTGAATGAGGGCATGCAAATGAGGTTCCCCATTTTCATGGAGTTCTCTGCAGATCTTGATGAACAATTTATTTGTTGGGGTTTGGAGTTGTCGGAGTTGATCTAATGCCGCTTCTTTCGAGAGAGTGCATTTCGGATACGTGAGGAAATAATTTTTGGCTTTTATGCTAAAACGACCAGCCCTCGGCATTTTCGCTGTCGTATAGCAATCGGGGGGCACTCAAAGTTCCTAGCAATCGGGGGAATGGGGGGCAATTTATATGATGCCCCCCAAATGGCATATGTGTAATTTTGTGATGAAATTTGAATTTCGAACGTGGAAAGCGGCCATCCGTCTAATATT
ACCGGATGGCCGCGCCCGAAAAAGCAGATGGACCCCACAATGGTCCCCACGCACTAAATAATGTCAGCCAATCAATTGCAAGACTGGAAGACTCGGTAGTGACGCATGGAGTATTAAGTGGTTTCTGCACTAATTTGGACAGGCAATTTTATTGCTATGTGTGTATCATATTTTTATAGGTGTGCTACTGGCCAATCAAAGTTAGGTGATGGGGCCTACCATAAAAACGCAAAATATAGGTACGTATGTACATATTGATTATATTTTTAGGTGCGGATATAAGAGGCGCCACGTGTTTACAATGGATATGGATTGTCCTATAAATATTGTGCATGTCTCCCGTTCGTTAATGCAAGATGTATTCAGTTTACAGACGTGGGTATAAGACTCCGTATAGGAGTCCGTATGGCGCTCGTGTAACACCATATGTATATCGTAAGACCTCTGGTAAACAGACGTCTAAATCTCGTGTACCGCGAAAGTTGGTGTATGAATCGCCAAAAGGTCTATATACGCGACGCTCATTGGAGGATATCCATAATGGGGCTTCCTTGAAGTTGTCTCAACAGGGGGATTATACGTCCTACGTGTCACTCCCTTGTCGAGGTATCGAAGGTAATGGGGGTAGGTCTGTTGATCACATAAAATTATTAAACTTGAGGGTTTCTGGGACCGTCAACGTCAGTCAAGTCGGTGGTGATGATAATATGGGAGAGAGAACGACCATGAGGGGTATCTTCTTCATGGCTTGTCTTGTTGATAAGAAACCTTTCGTTCCAGAGGGGGTCAGTATATTGCCGACGTTCAATGAGTTGTTCGGGGAATATGAATCCGTGTACGGCATGCCTAGGTTGAAGGAAAACGTCCGTCACCGGTATCGCGTTATTGGGACATCGAAATTATATATAACGACGGATGAAGATCACATCCAAAAGCCCTTTAGTTTACGTCGAAGACTAAGTGGAGGGAAATATCCTATTTGGTCGTCGTTCAAGGATGTGGATAATAGTAGTACAGGTGGTAACTATAAAAATATAAATAAGAACGCTATACTAGTGAGTTATGTGTGGGTATCGCTATGTCGGACCACGTGTGATGTGTATTCGCAGTTTGTACTGAATTACGTCGGTTGATAATAAAAAGAGATAAGTGTGTTGACAGGAATTATGTTTGAACTAATGAAACATGAGATGAACATTAATTGAAAGCATATATAGTTTGATTATGCTTTTAAGCAAATATGGTACATATCAATTGTTTATTACAATTGCCTTGGTGCGTCGGATTTTATTTTGTAGAGACACTTGTTTATGGTACTCTCAAGCAGTGTCTCGAGGTCCTTTCTGGAGACGGAGTCGGATTGGGCCTGTGATATCGAGTCCCCTGGGTCCAAATCGGGTGTGTGTAATCTGTGTAGTTTCTGGTAAGGATATTCTGTGGAGTCGTTGTCTAAGTCCGTTGGTGTTGTCGATGGGTCCATTCTCATGGACTGTGAACGAAAGTGTTCCAGCTGTGCTGGGCCTAATGAGCTTGGTAGCCCAATCTGAGACCTTGTGGCCCATGTTTCGCCTGGATGGATGGTGATGGGCCTGTGGGTTATGGGTTGTTGACTACGAGCAGTTGGAGTGGGATTTAATAATCGTCGTCTTGTTTCTCCTTTTTCCACGGACCAGAAGTCTATGCAGTCTTTTGTGTATCCCTTGGATAAGATGTTAATTGTTGGGGGTTTGAAACGTATGTCCGTGGAATGTTTGGCCGATGATAATCGGAGCTTGGCCTTGATGGATGCGAATTTCACGCCTTCTATGACGTTTGAGTCTTCGACTCTGTACATGATTCTCCAAGGGGAAGGTTCAGAAATCGAAAAATATGTAGAAGAGAAGTAGTGGAGGTCCACGTTGCAAGCGATGGGGAAAGTGAATGCTGCCTGAGCTGCGTCGTCAAGGCTGACGCGATTGTCTCTGATTTCTACGATAACCGACCCAGTTGCGTTAAATGGGACCTGGTTTCGGTATTCAATTATAATGTGGTCGATTTTCATACATCGGCCTTTGAGTCGCATGGTAGCCTGCTCGAATGAGCCTGGGAATTGGAGATTGATTGGTGCAGCATCGTTTGTTAATGCGTACTCGGTGCGTTTGCTGTTGATGTAATTATTGTCTGTGACGGTAAATTGGGCGTCCATTCTATGAAGCAAAAAAACAAAGGTTAGTAAACGGAGAGACGAGAGGTATAAAAGTCAGAACAAAGTTGAAAAAATATCGTGTAGACATGGAAGCATATATGCATTTGTTATATAGAATAACACACGAGATCAGAACAAGGATCATATATGTTGAACCGGCCGCGCAGCGGATAGGAAGTCAGATAAATCGGCGAACAAAGAAAACAGTCGAATGGGGTGATGTGATGTAAACCACTTACAGAAGCGCCGAAGAAGCAGTTCGAAGTGAATTCCTGTGCTAATTAGGCGAAGACAAAGAAATAAAAGTAGAACTTATTGCGAAAAAAGGAAAGGGAGCAGATGTTACGCGTGGTGTCGTGAAATGATATGTTATTAGGTGTTTATATAGGCGTGAATAAGCTACACGTGGTAGAGAGAGAAAGAAGAGAGAGGCGAGAGCAATCGGGGGGCACTCAAAGTTCCTAGCAATCGGGGGAATGGGGGGCAATTTATATGATGCCCCCCAAATGGCATTTGTGTAATTTCTTAATGAAATTTGAATTGCGAACGTGGAAAGCGGCCATCCGTATAATATT
Gene Information
|
NCBI Accession
|
NP_620661.1
|
|
Location
|
174-524 |
|
Gene Name
|
AV2 |
|
Protein Name
|
AV2 |
|
Coding Region
|
ATGTGGGATCCATTGTTGAATGAGTTCCCCGAGTCTGTGCACGGTTTTCGCTGTATGCTTGCTATTAAATATTTGCAGGCCTTGGAGGAAACCTACGAGCCCAATACTTTGGGCCACGATCTAGTCCGTGATCTCATCGGTGTGATCCGAGCCCGTGATTATGTCGAAGCGTCCCGCCGATATAATCATTTCCACTCCCGTCTCGAAGGTGCGTCGAAGGCTGAACTTCGACAGCCCGTTCAGCAGCCGTGCTGCTGTCCCCATTGTCCAAGGCACAAACAAGCGTCGATCATGGACGTTCCGGCCCATGTACCGAAAGCCCAGAATGTACAGAATGTTCAAAAGCCCTGA |
|
Protein Sequence
|
MWDPLLNEFPESVHGFRCMLAIKYLQALEETYEPNTLGHDLVRDLIGVIRARDYVEASRRYNHFHSRLEGASKAELRQPVQQPCCCPHCPRHKQASIMDVPAHVPKAQNVQNVQKP |
|
NCBI Accession
|
NP_620662.1
|
|
Location
|
334-1110 |
|
Gene Name
|
AV1 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGTCGAAGCGTCCCGCCGATATAATCATTTCCACTCCCGTCTCGAAGGTGCGTCGAAGGCTGAACTTCGACAGCCCGTTCAGCAGCCGTGCTGCTGTCCCCATTGTCCAAGGCACAAACAAGCGTCGATCATGGACGTTCCGGCCCATGTACCGAAAGCCCAGAATGTACAGAATGTTCAAAAGCCCTGATGTTCCGCGTGGCTGTGAAGGCCCATGTAAGGTTCAATCTTATGAACAGCGAGATGACGTTAAGCATACTGGCAGTGTTCGTTGTGTTAGTGATGTCACGCGTGGTTCGGGAATTACACATAGAGTAGGTAAAAGGTTCTGTATCAAGTCTATATATGTGTTAGGTAAGATATGGATGGATGAAAACATCAAGAAGCAGAACCATACAAACCAGGTCATGTTCTTCTTAGTCCGTGACAGAAGGCCCTATGGCAATAGCCCCATGGACTTTGGACAGGTTTTTAATATGTTTGATAATGAGCCCAGTACAGCCACTGTGAAGAACGATCTTAGGGATAGGTATCGAGTTATGCGGAAGTTTCATGCCACCGTTGTTGGGGGTCCTTCTGGAATGAAGGAGCAGGCTTTGGTGAGGAGATTTTTTAGGATAAATAATCATGTTGTGTATAATCACCAGGAGGCAGCTAAGTATGAGAATCATACAGAGAATGCGTTATTGTTGTATATGGCATGTACGCATGCCTCTAATCCAGTGTATGCTACGCTTAAAATACGCATCTATTTTTATGATGCAGTAACAAATTAA |
|
Protein Sequence
|
MSKRPADIIISTPVSKVRRRLNFDSPFSSRAAVPIVQGTNKRRSWTFRPMYRKPRMYRMFKSPDVPRGCEGPCKVQSYEQRDDVKHTGSVRCVSDVTRGSGITHRVGKRFCIKSIYVLGKIWMDENIKKQNHTNQVMFFLVRDRRPYGNSPMDFGQVFNMFDNEPSTATVKNDLRDRYRVMRKFHATVVGGPSGMKEQALVRRFFRINNHVVYNHQEAAKYENHTENALLLYMACTHASNPVYATLKIRIYFYDAVTN |
|
NCBI Accession
|
NP_620663.1
|
|
Location
|
1107-1511 |
|
Gene Name
|
AC3 |
|
Protein Name
|
AC3 |
|
Coding Region
|
ATGGATTCTCGCACAGGGGAACTCATCACTGCGCCTCAAGCAAAGAATGGCGTTTTTACCTGGGAAATAACAAATCCCCTCTATTTCGACATCACCAACCACGACAAGCGGCCAGGGAACATGAACCACGACATCATCACCCTCCAGATACGGTTCAACCACAACATCAGGAAGGCATTGGGGATTCACAAGTGTTTTCTCAACTTCAAGGTCTGGACGACCTTACGGCCTCCGACTGGTCTTTTCTTAAGAGTATTTAAATATCAAGTGCTCAAGTATTTAAATATGATAGGCGTTATTTCCATTAACACTGTACTCAGAGCTGTTGATCATGTTCTGTACGATGTATTACTAAACACACTCCAAGTTACGGAGCAACATGCAATAAAATTCAACCTTTATTAA |
|
Protein Sequence
|
MDSRTGELITAPQAKNGVFTWEITNPLYFDITNHDKRPGNMNHDIITLQIRFNHNIRKALGIHKCFLNFKVWTTLRPPTGLFLRVFKYQVLKYLNMIGVISINTVLRAVDHVLYDVLLNTLQVTEQHAIKFNLY |
|
NCBI Accession
|
NP_620664.1
|
|
Location
|
1252-1659 |
|
Gene Name
|
AC2 |
|
Protein Name
|
AC2 |
|
Coding Region
|
ATGCAACCTTCATCACCCTCCACGAGCCATTGTTCTCAAGTGCCCATCAAAGTCCAACACCGCACCGCGAAGACTAGGGCCCTCAGACGTAGGAGGGTAGACCTCGAATGCGGCTGCTCGTTCTATCTCCATATCGACTGCATCAACCATGGATTCTCGCACAGGGGAACTCATCACTGCGCCTCAAGCAAAGAATGGCGTTTTTACCTGGGAAATAACAAATCCCCTCTATTTCGACATCACCAACCACGACAAGCGGCCAGGGAACATGAACCACGACATCATCACCCTCCAGATACGGTTCAACCACAACATCAGGAAGGCATTGGGGATTCACAAGTGTTTTCTCAACTTCAAGGTCTGGACGACCTTACGGCCTCCGACTGGTCTTTTCTTAAGAGTATTTAA |
|
Protein Sequence
|
MQPSSPSTSHCSQVPIKVQHRTAKTRALRRRRVDLECGCSFYLHIDCINHGFSHRGTHHCASSKEWRFYLGNNKSPLFRHHQPRQAAREHEPRHHHPPDTVQPQHQEGIGDSQVFSQLQGLDDLTASDWSFLKSI |
|
NCBI Accession
|
NP_620665.1
|
|
Location
|
1583-2647 |
|
Gene Name
|
AC1 |
|
Protein Name
|
replicase |
|
Coding Region
|
ATGCCGAGGGCTGGTCGTTTTAGCATAAAAGCCAAAAATTATTTCCTCACGTATCCGAAATGCACTCTCTCGAAAGAAGCGGCATTAGATCAACTCCGACAACTCCAAACCCCAACAAATAAATTGTTCATCAAGATCTGCAGAGAACTCCATGAAAATGGGGAACCTCATTTGCATGCCCTCATTCAGTTCGAGGGCAAGTACAATTGTACCAACCAACGATTCTTCGACCTCATATCCCCTTCCAGGTCAACACATTTCCATCCAAACATTCAGGGAGCTAAATCCAGTTCTGACGTCAAGTCCTATTTGGACAAGGACGGAGACACCATCCAATGGGGCGAGTTTCAGATCGACGGACGATCTGCTCGCGGCGGACAACAATCCGCCAATGACGCTTACGCCAAGGCTCTTAACGCAGCAAGTAAAACAGAGGCTCTTAATGTAATCCGGGAACTAGCCCCAAAGGATTTTGTTTTACAGTTTCATAATTTAAATAGCAATTTAGATAGGATTTTTCAGGAGCCTCCGATTCCTTATATTTCTCCCTTTCTTTCTTCTTCTTTCACTCATGTTCCTGAGGAACTTGAAGACTGGGTTTCCGAGAACGTGATGGGTTTCGCTGCGCGGCCATGGAGACCGAGTAGTATCGTCATCGAGGGCGATAGTAGGACAGGGAAGACGATGTGGGCCCGATCTCTGGGACCACACAACTACTTATGTGGACATTTGGATCTCAGTCCAAAGGTTTACAGCAACGACGCATGGTACAACGTCATTGATGACGTCGACCCCCATTACCTCAAGCACTTCAAAGAATTCATGGGGGCCCAAAGGGACTGGCAAAGCAATACCAAGTACGGGAAGCCGATTCAAATTAAAGGCGGCATTCCCACTATCTTCCTATGCAATCCAGGACCGACATCATCATATAAAGAGTTTCTGGACGAGGAAAAGAACCAGTCCCTTAAAGCCTGGGCTTTAAAGAATGCAACCTTCATCACCCTCCACGAGCCATTGTTCTCAAGTGCCCATCAAAGTCCAACACCGCACCGCGAAGACTAG |
|
Protein Sequence
|
MPRAGRFSIKAKNYFLTYPKCTLSKEAALDQLRQLQTPTNKLFIKICRELHENGEPHLHALIQFEGKYNCTNQRFFDLISPSRSTHFHPNIQGAKSSSDVKSYLDKDGDTIQWGEFQIDGRSARGGQQSANDAYAKALNAASKTEALNVIRELAPKDFVLQFHNLNSNLDRIFQEPPIPYISPFLSSSFTHVPEELEDWVSENVMGFAARPWRPSSIVIEGDSRTGKTMWARSLGPHNYLCGHLDLSPKVYSNDAWYNVIDDVDPHYLKHFKEFMGAQRDWQSNTKYGKPIQIKGGIPTIFLCNPGPTSSYKEFLDEEKNQSLKAWALKNATFITLHEPLFSSAHQSPTPHRED |
|
NCBI Accession
|
NP_620666.1
|
|
Location
|
2200-2496 |
|
Gene Name
|
AC4 |
|
Protein Name
|
AC4 |
|
Coding Region
|
ATGAAAATGGGGAACCTCATTTGCATGCCCTCATTCAGTTCGAGGGCAAGTACAATTGTACCAACCAACGATTCTTCGACCTCATATCCCCTTCCAGGTCAACACATTTCCATCCAAACATTCAGGGAGCTAAATCCAGTTCTGACGTCAAGTCCTATTTGGACAAGGACGGAGACACCATCCAATGGGGCGAGTTTCAGATCGACGGACGATCTGCTCGCGGCGGACAACAATCCGCCAATGACGCTTACGCCAAGGCTCTTAACGCAGCAAGTAAAACAGAGGCTCTTAATGTAA |
|
Protein Sequence
|
MKMGNLICMPSFSSRASTIVPTNDSSTSYPLPGQHISIQTFRELNPVLTSSPIWTRTETPSNGASFRSTDDLLAADNNPPMTLTPRLLTQQVKQRLLM |
|
NCBI Accession
|
NP_620667.1
|
|
Location
|
357-1133 |
|
Gene Name
|
BV1 |
|
Protein Name
|
BV1 |
|
Coding Region
|
ATGTATTCAGTTTACAGACGTGGGTATAAGACTCCGTATAGGAGTCCGTATGGCGCTCGTGTAACACCATATGTATATCGTAAGACCTCTGGTAAACAGACGTCTAAATCTCGTGTACCGCGAAAGTTGGTGTATGAATCGCCAAAAGGTCTATATACGCGACGCTCATTGGAGGATATCCATAATGGGGCTTCCTTGAAGTTGTCTCAACAGGGGGATTATACGTCCTACGTGTCACTCCCTTGTCGAGGTATCGAAGGTAATGGGGGTAGGTCTGTTGATCACATAAAATTATTAAACTTGAGGGTTTCTGGGACCGTCAACGTCAGTCAAGTCGGTGGTGATGATAATATGGGAGAGAGAACGACCATGAGGGGTATCTTCTTCATGGCTTGTCTTGTTGATAAGAAACCTTTCGTTCCAGAGGGGGTCAGTATATTGCCGACGTTCAATGAGTTGTTCGGGGAATATGAATCCGTGTACGGCATGCCTAGGTTGAAGGAAAACGTCCGTCACCGGTATCGCGTTATTGGGACATCGAAATTATATATAACGACGGATGAAGATCACATCCAAAAGCCCTTTAGTTTACGTCGAAGACTAAGTGGAGGGAAATATCCTATTTGGTCGTCGTTCAAGGATGTGGATAATAGTAGTACAGGTGGTAACTATAAAAATATAAATAAGAACGCTATACTAGTGAGTTATGTGTGGGTATCGCTATGTCGGACCACGTGTGATGTGTATTCGCAGTTTGTACTGAATTACGTCGGTTGA |
|
Protein Sequence
|
MYSVYRRGYKTPYRSPYGARVTPYVYRKTSGKQTSKSRVPRKLVYESPKGLYTRRSLEDIHNGASLKLSQQGDYTSYVSLPCRGIEGNGGRSVDHIKLLNLRVSGTVNVSQVGGDDNMGERTTMRGIFFMACLVDKKPFVPEGVSILPTFNELFGEYESVYGMPRLKENVRHRYRVIGTSKLYITTDEDHIQKPFSLRRRLSGGKYPIWSSFKDVDNSSTGGNYKNINKNAILVSYVWVSLCRTTCDVYSQFVLNYVG |
|
NCBI Accession
|
NP_620668.1
|
|
Location
|
1262-2185 |
|
Gene Name
|
BC1 |
|
Protein Name
|
BC1 |
|
Coding Region
|
ATGGACGCCCAATTTACCGTCACAGACAATAATTACATCAACAGCAAACGCACCGAGTACGCATTAACAAACGATGCTGCACCAATCAATCTCCAATTCCCAGGCTCATTCGAGCAGGCTACCATGCGACTCAAAGGCCGATGTATGAAAATCGACCACATTATAATTGAATACCGAAACCAGGTCCCATTTAACGCAACTGGGTCGGTTATCGTAGAAATCAGAGACAATCGCGTCAGCCTTGACGACGCAGCTCAGGCAGCATTCACTTTCCCCATCGCTTGCAACGTGGACCTCCACTACTTCTCTTCTACATATTTTTCGATTTCTGAACCTTCCCCTTGGAGAATCATGTACAGAGTCGAAGACTCAAACGTCATAGAAGGCGTGAAATTCGCATCCATCAAGGCCAAGCTCCGATTATCATCGGCCAAACATTCCACGGACATACGTTTCAAACCCCCAACAATTAACATCTTATCCAAGGGATACACAAAAGACTGCATAGACTTCTGGTCCGTGGAAAAAGGAGAAACAAGACGACGATTATTAAATCCCACTCCAACTGCTCGTAGTCAACAACCCATAACCCACAGGCCCATCACCATCCATCCAGGCGAAACATGGGCCACAAGGTCTCAGATTGGGCTACCAAGCTCATTAGGCCCAGCACAGCTGGAACACTTTCGTTCACAGTCCATGAGAATGGACCCATCGACAACACCAACGGACTTAGACAACGACTCCACAGAATATCCTTACCAGAAACTACACAGATTACACACACCCGATTTGGACCCAGGGGACTCGATATCACAGGCCCAATCCGACTCCGTCTCCAGAAAGGACCTCGAGACACTGCTTGAGAGTACCATAAACAAGTGTCTCTACAAAATAAAATCCGACGCACCAAGGCAATTGTAA |
|
Protein Sequence
|
MDAQFTVTDNNYINSKRTEYALTNDAAPINLQFPGSFEQATMRLKGRCMKIDHIIIEYRNQVPFNATGSVIVEIRDNRVSLDDAAQAAFTFPIACNVDLHYFSSTYFSISEPSPWRIMYRVEDSNVIEGVKFASIKAKLRLSSAKHSTDIRFKPPTINILSKGYTKDCIDFWSVEKGETRRRLLNPTPTARSQQPITHRPITIHPGETWATRSQIGLPSSLGPAQLEHFRSQSMRMDPSTTPTDLDNDSTEYPYQKLHRLHTPDLDPGDSISQAQSDSVSRKDLETLLESTINKCLYKIKSDAPRQL |