Solanum mosaic Bolivia virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_000921815.1 |
| Isolate |
Bolivia |
| Release date |
2015/2/22 |
| Submitter |
Wyant,P.S., Gotthardt,D., Schafer,B., Krenz,B., Jeske,H. |
| Host |
|
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
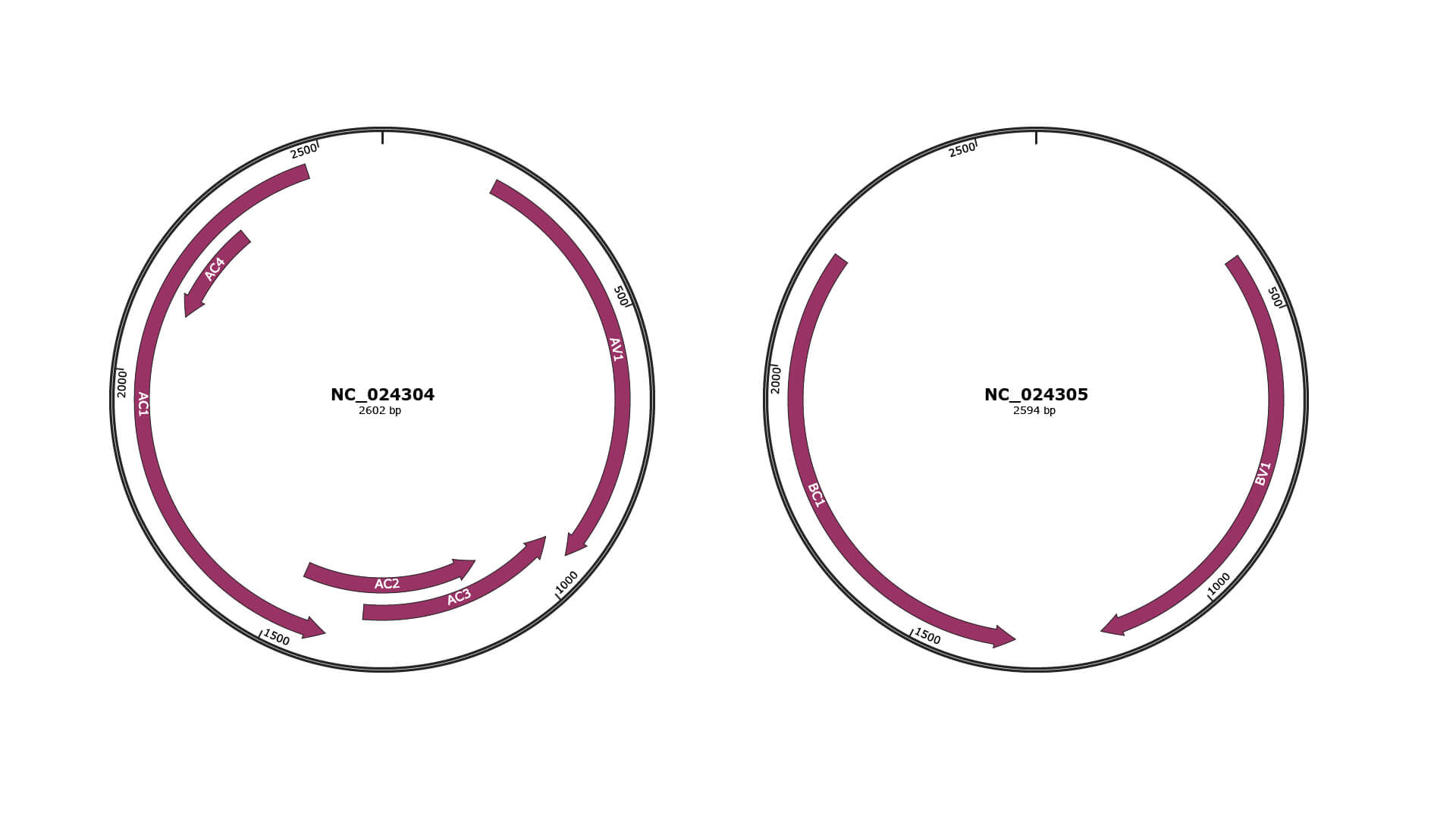
JBrowse
Genome
ACCGGATGGGCCGCGCGATCTTTTATACCGGGCCCCGCCTCCGTAAATTGCGCTCAATCACTTTAGAATTGGTCCCACTATATCTGACCAATCATGTTCTGTCCTGAAAGCTAAGATATTTTAAAATCCTTAGGCGCGAAGTATTTAAATTAATATAAATGGGCCATATCTTACGTGGCCTGACATGCTTTAATTCAAAATGCCTAAGCGTGATGCCCCATCACGTTTGATGGCGGGAACCTCAAAGGTTCGCCGTACTACCAATTATTCACCTCGTGGAGGCATGCCTAAGCGGGATGCTTGGGTTAATAGGCCCATGTACAGGAAGCCTAGGATCTATCGTATGTGGAGAAGTCCAGATGTCCCTAGAGGTTGTGAAGGGCCTTGTAAGGTCCAGTCTTTCGAACAGCGTCATGACATTTCCCATGTTGGCAAGGTGATGTGTGTTTCGGATGTGACACGTGGTAATGGTATTACTCACCGTGTTGGTAAGCGTTTTTGTGTTAAGTCCGTGTACATTCTAGGTAAGATATGGATGGACGAGAATATCAAGTTGAAGAACCATACTAACAGCGTCATGTTCTGGTTGGTGAGAGATCGTAGACCGTATGGTACACCTATGGATTTTGGCCAGGTGTTCAACATGTTTGACAATGAGCCTAGTACTGCTACTGTGAAGAACGATCTTCGTGATCGTTACCAAGTTATGCATAAGTTTTATGCAAAAGTTACAGGTGGACAATATGCTAGCAATGAGCAGGCTCTCGTGAAGCGTTTCTGGAAGGTCAATAACTACGTGGTGTACAACCATCAAGAAGCTGGGAAATATGAAAATCATACTGAGAACGCCTTATTGTTGTATATGGCATGTACTCATGCTTCTAATCCCGTGTATGCTACATTGAAAATTCGGATCTATTTTTATGATTCGATCAGTAATTAATAAAGTTTGAATTTTATTGAATGATCTTCGAGTACATAATTTACATAAGATCTGTCTGTCGCGGAGCGAACAGCTCTAATTACATTGTTAATTGAAATAACACCTAATTGATCTAGATATAACAAAACTAAATATTTAAATCTATTTAAATATGTCGTCCCAGAAGCTGTCAGAGAACTCGTCCAGACTTGGAAATTGAGAAATGCCTTGTGGAGATCCAACGCTTTCCTCGCGTTGTGGTTGAACCGAATCTGGATGTGGTAAATCCTGGTGTTGGTGTATGGTGGATCCTCCACGTTGGTTATCTTGAAATAAAGGGGATTTGATATTTCCCAAATATATACGCCATTCTCTGCTTGAGGCACAGTGATGAGTTCCCCTGTGCGTGAATCCATGGTTGCTGCAGTTGATATGGACGTAAATGGAGCAGCCGCAGTTCAAGTCAATGCGTCTGCGTCTAATTGGTCGCCGTTTGGCTGCTCTGTGCTGTGCTTTGATAGAGAGGGGAGTTGAGGAAGATGAATTTAGCATTATGAAGTGTCCACGCTCTTAGAGATGCATTTTCCTCTTTGTCTAGGAAGACTTTATAACTAGCCCCCTCTCCTGGATTGCACAGCACAATTGATGGGATGCCTCCTTTAATTTGAACTGGCTTTCCGTATTTGCAGTTGGATTGCCAGTCCTTTTGGGCCCCAATTAACTCTTTCCAGTGTTTCATCTTTAGATAATGCGGGCTGACATCATCTATGACATTATATTCAGCTTTATTTGAATAAACTCTGGAATTAAAATCAAGATGTCCGCTCAAATAATTATGTGGGCCTAATGCTCGAGCCCACATCGTCTTCCCCGTTCGACTATCACCTTCAATGATAATACTAATAGGTCTCTCTGGCCGCGCAGCGGAATCCTTTCCAAAATAATCATCAGCCCATTCCTGCATCTCGTCAGGCACGTTAGTGAAAGATGAGAGTCGAAAAGGAGATACCCATGGTTCTGGAGGCTTCTCAAATATTTTTTGAACATGTGCTCTAATTTTATCTAATTGAAGAACATAATCCCGGGGTTGTTCTTCTCTAAGTATTTTAAGTGCCGTGGTAATGCTATCTGCGTTTAGAACCTTCGCATAAGTATCGTTGGCAGATTGACAACCTCCTCTAGCTGATCTTCCATCTATTTGGAAAGTTCCAAAATCAACGAAGTCTCCGTCTTTCTCCATATAGGTCTTGACGTCTGACGAACTCTTAGCTCCCTGAATGTTCGGATGGAAATGTGCTGACCTTGTTGGGGATACCAAGTCGAAGAATCGTTGATTTGTGCAGATGTATTTTCCTTCGAATTGGATAAGCACATGGAGATGAGGCTCCCCATTTTCGTGTAGCTCTCTACAAACCCTAATGAATTTCTTGTTGATATTACAATTTAAGGCTTGTAATTGTGAAAGAGCCTCTTCTTTAGATAGTGAACAATGAGGGTATGTAAGGAAATAATTTTTAGACTGAACTCTAAAACGTTTAGGCGGTGGCATATTTGTAAATAAGAGGTGTCTCCAATTGGGAGCTCTCAAACTTGGTGAAATGAATTGGAGACTGGAGTACAATATATAGTAGAGTCTCTTAAAGGTTTTTTGCACACGTGGCGGCCATCCGTTATAATATT
ACCGGATGGCCGCGTTGCCCCTCTTTTGCTCAGATTGTGACGCGTGTCCCTTATCTTTTCGCATTTTAATTAAGCGCATTTTTGAAATCCGCGAATTGAGTTCACCGCATTTATTTCAAGTCCGCGCGTGAAGTCACGACAAATAACTTTAATTTGAATAAAAGCGGAGCTTTTTTCCAGCCAATCAATTCGCGTCTGACGAGCCTATTTAATTTGTAGATTTTTACTGTTCAAAATGTTGACCGAACGGACGTGAGATATAATTTGTAAGTTGAATTATTTGGGCTCGTCATATGACATTATTTTGACGTGGACCAATAATATTTCGCTGTGGAAGCTAAATAACTAGTTTATGAAACCAGGAATTTTATATATAAATTCCGTATTGATTAATGTCAAAATTATATTGCAATATGTTTCCTACTAAATATAGACGTGGGATTTCATTTAATCCACGACGAAGTTATGGACGCACTTATTTGTTTAAGCGTTCTAATTATATTAAACGCACGGATGGGAAACGTCGATTAAGTAATTCTAATCAGGCTACTGATGATGGGAAGCTGTCACAACAACGTATTCATGAAAACCAGTTTGGGCCAGAATTTGTTATGGGTCATAATACAGCCATTTCAACATTTATCACCTTTCCTAAGCTGGGTAAGAATCAGCCCAATCGATCCAGGTCATATATTAAGTTGCAACGACTACGTTTCAAAGGCACCGTGAAGATTGAACGTGTTAATACGGACGTGAACATGGTCGGTGCACCTCCAAAGATTGAAGGCGTATTCTCAGTGGTTGTCGTGGTTGATCGTAAACCACATTTAAGTCCAACGGGATGTCTCCACACATTTGACGAAGTATTCGGTGCACGTATAAACAGCCATGGCAATTTAGATATAACTCCTTCGTTGAAAGATCGTTTTTACATACGTCACGTGCTGAAACGTGTGATATCTGTCGAGAAGGATACCACGATGATCGACCTCGAAGGAAGGACAACGTTGTCTAACAGGCGTTTTAATTGTTGGTCTTCGTTTAGGGATCTAGATCATGACTCATGTAACGGCGTATATGCTAATATAAGCAAGAACGCCTTGTTAGTTTATTATTGTTGGATGTCGGATATCATATCTAAGGCATCGACATTTGTATCTTTTGATCTTGACTATGTTGGTTAAATAACAAGAGTATATTGTTTAATTGCATTACATGCGAGTAAGCATAACAAGAATTATATATAAGAAACTGGTAATTTAAGCAATAAGAAATACAGTTAAGAAAGCATGGCTACGCATCTTAATACAAAGTAAAGTAAAGACATTTTATTTATTTCAAAGATTTGGGTTGTGTAGGAATACAGTTCGTATTAATACATTCTTGGACTGTTGTCCTTACAATGTCGTTTAATTGGGCCATTGACATTGTTATGTTGGACTGTGTCCGTTGGGCCCCAATTATTGAAGCAGATTCACCCGGGTCCAACATTGTTGAGCCCAATCTGTTAAGCTCTCTATATGGATGGGCTCCATCATCTATTTCGGAATCTGCATATGGGCCTATGGTACTTCTTGTAGCCCATGATTCTCCTGGTTTGAGTTCTATTGGGCCGGGAAGCCCAAATCTGGAAGTGGATGCGGATCTTACTAATTTCCTCTCCCACTTCCCATAACTTACATGGGAGAAATCTATATCCTTGTCCGTAAATTGTTTGGACAGGATTTTAACTGTGGGAGCTTTGAAGGGGATGTCCACTGAGTGTTTAGCCGTTGATAGTTTCAGTTTCCCTTTGAATTTGGCGAAGTGAGTCCTCTGATGAACATTGGAGTCGCAAACTCTGTAATACAGCTTCCATGGAATTGGGTCTTTGAGGGAGAAGAATGAAGAAGAAAAATAGTGGAGATCTATGTTACATCTAATTGGAAAAGTCCAGGTTGCCTGTAAGGATTCATTGTCAGTCATCCTCTTGTCATGAATCTCCACTATCACAGTCCCAGATGCGTTGATTGGGACTTGTTGCCTGTATTCTATGACGCAATGGTCGATCTTCATACAGCTACGACTGAGTCTTGCACTTAATTGAGATGCCGTTGAAGGAAATTGTAAGATGATCTCGGTTAGGTCATGAGATAGTTGATATTCATCTCGATGAGACTCAATATAATTAAAGGCGTTTGGAGGATGAGCTAGTTGAGAATCCATATAAGAAAATATGGCTGCGCAGCTGAATACAAAGTAAATTACAGACAAGGCGTCTATTTAAAGAAGAGAGAAATTGAGATATAACAGCTGAATATTGTGAATACAAGACGTCTATTTATAGAAGGGAGAAATTGAGATATAGGAAATTATTATTAAGAGTAACAGTATGTGTGGATTAAATAAGCGTCTAGAGTGGTTAATTGTAATTATTAGCCTTTATTCTAAAATAAATAAATGTGCTACAGGGATAATGGCATAATTGTAAATAAGGGAGTGTCTCCAATCGGGAGCTCTCAAACTTGGTGAAATGAATTGGAGACTGGAGTACAATATATAGTAGAGTCCATAATGGGTTTTATGCACACGTGGCGGCCATCCGTTATAATATT
Gene Information
|
NCBI Accession
|
YP_009042055.1
|
|
Location
|
200-943 |
|
Gene Name
|
AV1 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGCCTAAGCGTGATGCCCCATCACGTTTGATGGCGGGAACCTCAAAGGTTCGCCGTACTACCAATTATTCACCTCGTGGAGGCATGCCTAAGCGGGATGCTTGGGTTAATAGGCCCATGTACAGGAAGCCTAGGATCTATCGTATGTGGAGAAGTCCAGATGTCCCTAGAGGTTGTGAAGGGCCTTGTAAGGTCCAGTCTTTCGAACAGCGTCATGACATTTCCCATGTTGGCAAGGTGATGTGTGTTTCGGATGTGACACGTGGTAATGGTATTACTCACCGTGTTGGTAAGCGTTTTTGTGTTAAGTCCGTGTACATTCTAGGTAAGATATGGATGGACGAGAATATCAAGTTGAAGAACCATACTAACAGCGTCATGTTCTGGTTGGTGAGAGATCGTAGACCGTATGGTACACCTATGGATTTTGGCCAGGTGTTCAACATGTTTGACAATGAGCCTAGTACTGCTACTGTGAAGAACGATCTTCGTGATCGTTACCAAGTTATGCATAAGTTTTATGCAAAAGTTACAGGTGGACAATATGCTAGCAATGAGCAGGCTCTCGTGAAGCGTTTCTGGAAGGTCAATAACTACGTGGTGTACAACCATCAAGAAGCTGGGAAATATGAAAATCATACTGAGAACGCCTTATTGTTGTATATGGCATGTACTCATGCTTCTAATCCCGTGTATGCTACATTGAAAATTCGGATCTATTTTTATGATTCGATCAGTAATTAA |
|
Protein Sequence
|
MPKRDAPSRLMAGTSKVRRTTNYSPRGGMPKRDAWVNRPMYRKPRIYRMWRSPDVPRGCEGPCKVQSFEQRHDISHVGKVMCVSDVTRGNGITHRVGKRFCVKSVYILGKIWMDENIKLKNHTNSVMFWLVRDRRPYGTPMDFGQVFNMFDNEPSTATVKNDLRDRYQVMHKFYAKVTGGQYASNEQALVKRFWKVNNYVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSISN |
|
NCBI Accession
|
YP_009042056.1
|
|
Location
|
940-1338 |
|
Gene Name
|
AC3 |
|
Protein Name
|
replication enhancer |
|
Coding Region
|
ATGGATTCACGCACAGGGGAACTCATCACTGTGCCTCAAGCAGAGAATGGCGTATATATTTGGGAAATATCAAATCCCCTTTATTTCAAGATAACCAACGTGGAGGATCCACCATACACCAACACCAGGATTTACCACATCCAGATTCGGTTCAACCACAACGCGAGGAAAGCGTTGGATCTCCACAAGGCATTTCTCAATTTCCAAGTCTGGACGAGTTCTCTGACAGCTTCTGGGACGACATATTTAAATAGATTTAAATATTTAGTTTTGTTATATCTAGATCAATTAGGTGTTATTTCAATTAACAATGTAATTAGAGCTGTTCGCTCCGCGACAGACAGATCTTATGTAAATTATGTACTCGAAGATCATTCAATAAAATTCAAACTTTATTAA |
|
Protein Sequence
|
MDSRTGELITVPQAENGVYIWEISNPLYFKITNVEDPPYTNTRIYHIQIRFNHNARKALDLHKAFLNFQVWTSSLTASGTTYLNRFKYLVLLYLDQLGVISINNVIRAVRSATDRSYVNYVLEDHSIKFKLY |
|
NCBI Accession
|
YP_009042057.1
|
|
Location
|
1085-1474 |
|
Gene Name
|
AC2 |
|
Protein Name
|
transcriptional regulator |
|
Coding Region
|
ATGCTAAATTCATCTTCCTCAACTCCCCTCTCTATCAAAGCACAGCACAGAGCAGCCAAACGGCGACCAATTAGACGCAGACGCATTGACTTGAACTGCGGCTGCTCCATTTACGTCCATATCAACTGCAGCAACCATGGATTCACGCACAGGGGAACTCATCACTGTGCCTCAAGCAGAGAATGGCGTATATATTTGGGAAATATCAAATCCCCTTTATTTCAAGATAACCAACGTGGAGGATCCACCATACACCAACACCAGGATTTACCACATCCAGATTCGGTTCAACCACAACGCGAGGAAAGCGTTGGATCTCCACAAGGCATTTCTCAATTTCCAAGTCTGGACGAGTTCTCTGACAGCTTCTGGGACGACATATTTAAATAG |
|
Protein Sequence
|
MLNSSSSTPLSIKAQHRAAKRRPIRRRRIDLNCGCSIYVHINCSNHGFTHRGTHHCASSREWRIYLGNIKSPLFQDNQRGGSTIHQHQDLPHPDSVQPQREESVGSPQGISQFPSLDEFSDSFWDDIFK |
|
NCBI Accession
|
YP_009042058.1
|
|
Location
|
1401-2471 |
|
Gene Name
|
AC1 |
|
Protein Name
|
replication-associated protein |
|
Coding Region
|
ATGCCACCGCCTAAACGTTTTAGAGTTCAGTCTAAAAATTATTTCCTTACATACCCTCATTGTTCACTATCTAAAGAAGAGGCTCTTTCACAATTACAAGCCTTAAATTGTAATATCAACAAGAAATTCATTAGGGTTTGTAGAGAGCTACACGAAAATGGGGAGCCTCATCTCCATGTGCTTATCCAATTCGAAGGAAAATACATCTGCACAAATCAACGATTCTTCGACTTGGTATCCCCAACAAGGTCAGCACATTTCCATCCGAACATTCAGGGAGCTAAGAGTTCGTCAGACGTCAAGACCTATATGGAGAAAGACGGAGACTTCGTTGATTTTGGAACTTTCCAAATAGATGGAAGATCAGCTAGAGGAGGTTGTCAATCTGCCAACGATACTTATGCGAAGGTTCTAAACGCAGATAGCATTACCACGGCACTTAAAATACTTAGAGAAGAACAACCCCGGGATTATGTTCTTCAATTAGATAAAATTAGAGCACATGTTCAAAAAATATTTGAGAAGCCTCCAGAACCATGGGTATCTCCTTTTCGACTCTCATCTTTCACTAACGTGCCTGACGAGATGCAGGAATGGGCTGATGATTATTTTGGAAAGGATTCCGCTGCGCGGCCAGAGAGACCTATTAGTATTATCATTGAAGGTGATAGTCGAACGGGGAAGACGATGTGGGCTCGAGCATTAGGCCCACATAATTATTTGAGCGGACATCTTGATTTTAATTCCAGAGTTTATTCAAATAAAGCTGAATATAATGTCATAGATGATGTCAGCCCGCATTATCTAAAGATGAAACACTGGAAAGAGTTAATTGGGGCCCAAAAGGACTGGCAATCCAACTGCAAATACGGAAAGCCAGTTCAAATTAAAGGAGGCATCCCATCAATTGTGCTGTGCAATCCAGGAGAGGGGGCTAGTTATAAAGTCTTCCTAGACAAAGAGGAAAATGCATCTCTAAGAGCGTGGACACTTCATAATGCTAAATTCATCTTCCTCAACTCCCCTCTCTATCAAAGCACAGCACAGAGCAGCCAAACGGCGACCAATTAG |
|
Protein Sequence
|
MPPPKRFRVQSKNYFLTYPHCSLSKEEALSQLQALNCNINKKFIRVCRELHENGEPHLHVLIQFEGKYICTNQRFFDLVSPTRSAHFHPNIQGAKSSSDVKTYMEKDGDFVDFGTFQIDGRSARGGCQSANDTYAKVLNADSITTALKILREEQPRDYVLQLDKIRAHVQKIFEKPPEPWVSPFRLSSFTNVPDEMQEWADDYFGKDSAARPERPISIIIEGDSRTGKTMWARALGPHNYLSGHLDFNSRVYSNKAEYNVIDDVSPHYLKMKHWKELIGAQKDWQSNCKYGKPVQIKGGIPSIVLCNPGEGASYKVFLDKEENASLRAWTLHNAKFIFLNSPLYQSTAQSSQTATN |
|
NCBI Accession
|
YP_009042059.1
|
|
Location
|
2117-2314 |
|
Gene Name
|
AC4 |
|
Protein Name
|
AC4 protein |
|
Coding Region
|
ATGGGGAGCCTCATCTCCATGTGCTTATCCAATTCGAAGGAAAATACATCTGCACAAATCAACGATTCTTCGACTTGGTATCCCCAACAAGGTCAGCACATTTCCATCCGAACATTCAGGGAGCTAAGAGTTCGTCAGACGTCAAGACCTATATGGAGAAAGACGGAGACTTCGTTGATTTTGGAACTTTCCAAATAG |
|
Protein Sequence
|
MGSLISMCLSNSKENTSAQINDSSTWYPQQGQHISIRTFRELRVRQTSRPIWRKTETSLILELSK |
|
NCBI Accession
|
YP_009042060.1
|
|
Location
|
393-1184 |
|
Gene Name
|
BV1 |
|
Protein Name
|
nuclear shuttle protein |
|
Coding Region
|
ATGTCAAAATTATATTGCAATATGTTTCCTACTAAATATAGACGTGGGATTTCATTTAATCCACGACGAAGTTATGGACGCACTTATTTGTTTAAGCGTTCTAATTATATTAAACGCACGGATGGGAAACGTCGATTAAGTAATTCTAATCAGGCTACTGATGATGGGAAGCTGTCACAACAACGTATTCATGAAAACCAGTTTGGGCCAGAATTTGTTATGGGTCATAATACAGCCATTTCAACATTTATCACCTTTCCTAAGCTGGGTAAGAATCAGCCCAATCGATCCAGGTCATATATTAAGTTGCAACGACTACGTTTCAAAGGCACCGTGAAGATTGAACGTGTTAATACGGACGTGAACATGGTCGGTGCACCTCCAAAGATTGAAGGCGTATTCTCAGTGGTTGTCGTGGTTGATCGTAAACCACATTTAAGTCCAACGGGATGTCTCCACACATTTGACGAAGTATTCGGTGCACGTATAAACAGCCATGGCAATTTAGATATAACTCCTTCGTTGAAAGATCGTTTTTACATACGTCACGTGCTGAAACGTGTGATATCTGTCGAGAAGGATACCACGATGATCGACCTCGAAGGAAGGACAACGTTGTCTAACAGGCGTTTTAATTGTTGGTCTTCGTTTAGGGATCTAGATCATGACTCATGTAACGGCGTATATGCTAATATAAGCAAGAACGCCTTGTTAGTTTATTATTGTTGGATGTCGGATATCATATCTAAGGCATCGACATTTGTATCTTTTGATCTTGACTATGTTGGTTAA |
|
Protein Sequence
|
MSKLYCNMFPTKYRRGISFNPRRSYGRTYLFKRSNYIKRTDGKRRLSNSNQATDDGKLSQQRIHENQFGPEFVMGHNTAISTFITFPKLGKNQPNRSRSYIKLQRLRFKGTVKIERVNTDVNMVGAPPKIEGVFSVVVVVDRKPHLSPTGCLHTFDEVFGARINSHGNLDITPSLKDRFYIRHVLKRVISVEKDTTMIDLEGRTTLSNRRFNCWSSFRDLDHDSCNGVYANISKNALLVYYCWMSDIISKASTFVSFDLDYVG |
|
NCBI Accession
|
YP_009042061.1
|
|
Location
|
1333-2205 |
|
Gene Name
|
BC1 |
|
Protein Name
|
movement protein |
|
Coding Region
|
ATGGATTCTCAACTAGCTCATCCTCCAAACGCCTTTAATTATATTGAGTCTCATCGAGATGAATATCAACTATCTCATGACCTAACCGAGATCATCTTACAATTTCCTTCAACGGCATCTCAATTAAGTGCAAGACTCAGTCGTAGCTGTATGAAGATCGACCATTGCGTCATAGAATACAGGCAACAAGTCCCAATCAACGCATCTGGGACTGTGATAGTGGAGATTCATGACAAGAGGATGACTGACAATGAATCCTTACAGGCAACCTGGACTTTTCCAATTAGATGTAACATAGATCTCCACTATTTTTCTTCTTCATTCTTCTCCCTCAAAGACCCAATTCCATGGAAGCTGTATTACAGAGTTTGCGACTCCAATGTTCATCAGAGGACTCACTTCGCCAAATTCAAAGGGAAACTGAAACTATCAACGGCTAAACACTCAGTGGACATCCCCTTCAAAGCTCCCACAGTTAAAATCCTGTCCAAACAATTTACGGACAAGGATATAGATTTCTCCCATGTAAGTTATGGGAAGTGGGAGAGGAAATTAGTAAGATCCGCATCCACTTCCAGATTTGGGCTTCCCGGCCCAATAGAACTCAAACCAGGAGAATCATGGGCTACAAGAAGTACCATAGGCCCATATGCAGATTCCGAAATAGATGATGGAGCCCATCCATATAGAGAGCTTAACAGATTGGGCTCAACAATGTTGGACCCGGGTGAATCTGCTTCAATAATTGGGGCCCAACGGACACAGTCCAACATAACAATGTCAATGGCCCAATTAAACGACATTGTAAGGACAACAGTCCAAGAATGTATTAATACGAACTGTATTCCTACACAACCCAAATCTTTGAAATAA |
|
Protein Sequence
|
MDSQLAHPPNAFNYIESHRDEYQLSHDLTEIILQFPSTASQLSARLSRSCMKIDHCVIEYRQQVPINASGTVIVEIHDKRMTDNESLQATWTFPIRCNIDLHYFSSSFFSLKDPIPWKLYYRVCDSNVHQRTHFAKFKGKLKLSTAKHSVDIPFKAPTVKILSKQFTDKDIDFSHVSYGKWERKLVRSASTSRFGLPGPIELKPGESWATRSTIGPYADSEIDDGAHPYRELNRLGSTMLDPGESASIIGAQRTQSNITMSMAQLNDIVRTTVQECINTNCIPTQPKSLK |