Siegesbeckia yellow vein virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_000867465.1 |
| Isolate |
China:Guangdong province |
| Release date |
2015/2/13 |
| Submitter |
Wu,J.B., Zhou,X.P., Cai,J.H., Wu,J. |
| Host |
|
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
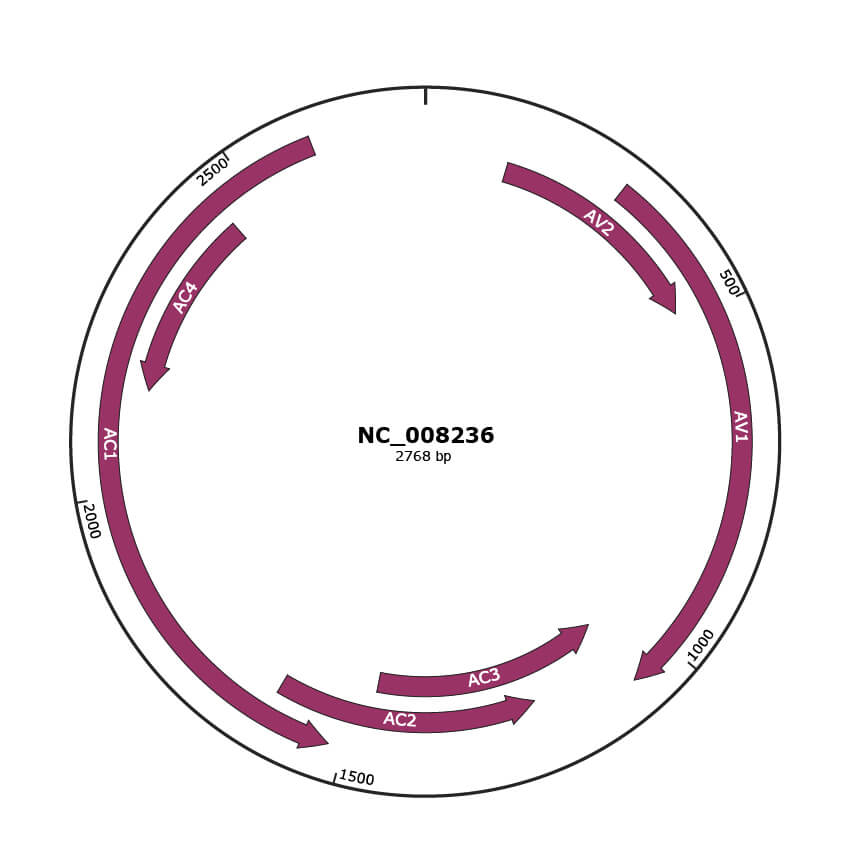
JBrowse
Genome
ACCGGATGGCCGCCGATTTTTTTAAAGTGGGCCCCCAAAAAAATGATCTAGACCGTTGCTCAAAGCTAACTAAAAAATATCCACGTATGCTTTTGTATATTTAAATGTATTTCCTTTTGATTTATATATGAAAATGTGGGATCCTTTAATTAACGAATTCCCTGAGACCGTTCACGGTTTTAGATGTATGCTTGCAATAAAATATCTGCAAGCCGTTCAATTGACGTACTCCCCTGATACGGTAGGATACGATTTAATTCGTGAACTTATACGTATTTTACGTACTAAGGATTATGGCCAAGCGACCTGCAGATATAGTCATTTCCACTCCCGCCTCCAAGGTACGTCGGAGGTTGAACTTCGACAGCCCCTATCGCAGCAGTGCTGCTGCCCCAACTGTCCTTGTCACCAACAAAAGGAGGACATGGGTCAATCGGCCCATGTACAGAAAGCCCAGAATGTACAGGATGTACAAAAGCCCTGATGTTCCTCGTGGTTGTGAAGGTCCATGTAAGGTTCAGTCGTTTGAACAGCGTCACGATGTAGTCCATGTAGGTAAAGTAATATGCGTGTCTGATGTTACCCGTGGTAATGGGTTGACTCACCGTGTGGGTAAGAGGTTCTGTATTAAATCTGTATACGTTTTGGGTAAAATCTGGATGGATGAAAATATTAAGACCAAGAATCACACTAATACGGTCATGTTCTACCTAGTCCGTGATAGAAGACCCTTTGGTACTCCTCAGGATTTTGGACAAGTTTTTAACATGTATGATAATGAACCTAGTACTGCAACTGTGAAGAATGACAACAGAGATCGATTTCAAGTACTTAGAAGATTTCAGTCTACCGTTACTGGTGGCCAGTATGCATCTAAGGAGCAAGCCATAGTTAGGAAATTTATGAAGATTAACAACCACGTTACTTACAACCATCAGGAAGCTGCGAAGTACGATAACCATACAGAGAACGCCTTGTTATTGTATATGGCATGTACTCATGCCAGTAACCCTGTGTATGCTACTTTGAAAATCAGGATCTATTTTTACGATTCTGTTCAGAATTAATAAATATTGAATTTTATATCATGAAATTCCTGTACATACATTGTGTGTTGTAGTTTATTATATAATACATGATCTACTGCTCTAATTACATTATTAATAGATATTACACCTAAATTATCTAAATACTGCATGACTTGCTTCTTAAATACTCTCAAGAAACGCCATGTCTGAGGCTGTAAGCGAGTCCAGACTTCGAAAATCAGAAAGCATTTGTGAATTCCCAGTTGAGTTCTCAGGTTGTAGTTGAATTGAATCTGGACGGTAATCTTGTCTTGTTCTTTGTTGAATGGCCTGCTGAGGTGATCTGTTATCTTGAAATATAGGGGATTTGGCACCGTCCAGATATACACGCCATTCTTTGCCTGAGCTGCAGTGATGAGTTCCCCTGTGCGTGAATCCATCGTTGGCACAGTGTATTCCTATGTATATTGTGCAACCACAGTCTAGGTCAACCCTACGTCTCCTGGTCACTTTCTTCCTCTTGGCTAGCTTGTGCTGGACTTTGATTGGTATTGGAGTAGAGTGGCTCGTTGAGGGTGATGAAGGTTGCATTTTTTATTGCCCAGGCTTTTAATGCACTATTCTTTTCTTCATCAAGATATTCTATATAGGAGGCAGTTGGTCCTGGATTGCAAAGGAAGATTGTTGGGATTCCACCTTTAATTTGAATTGGCTTCCCATACTTTGTGTTGCTTTGCCAGTCTCGTTGGGCCCCCATGAATTCCTTAAAGTGCTTTAGATAGTGCGGGTCTACGTCATCAATGACGTTGTACCATGCATCATTGCTGTAGACTTTTGGGCTCAAGTCAAGATGACCACACAAATAGTTGTGTGGTCCCAGTGATCTTGCCCACATTGTCTTCCCTGTCCTGCTATCACCCTGTATGACTATACTTACAGGTCTCCATGGCCGCGCAGCGGCATTGGCTATGTTTTCAGAGACCCATTCTTCAAGTTCTTCTGGAACTTGATTAAAAGAAGATGAAATAAAAGGAGAAACATAAATATCTATAGGAGGTGTAAAGATCCTATCTAAATTACTATTTAAATTATGAAACTGTAAAACATAATCTTTGGGAGCTTTCTCCCTTAATATATTGAGGGCCGAAACTTTGGACCCTGAGTTGATTGCCTCGGCATACGCGTCGTTTGCAGATTGGCAACCTCCTCTAGCTGATCGTCCATCGATCTGGAAAACTCCAGAATCAAGGATGTCTCCGTCTTTCTCCATGTAGGTTTTGACATCAGACGAGCTTTTAGCTCCCTGAATGTTTGGATGGAAATGTGCTGACCTACTTGGGGATGTGAGATCGAAGAATCTATTATTTTTGCATTGGAATTTTCCTTCGAACTGGATGAGAACATGCAGGTGAGGATTCCCATCGTTGTGTAGTTCTCTGCAGATTCTGATGAATAATATATTAGTTGGGGTTTCTAGGGTTTGTAATTGTGAAAGTGCTTCTTCTTTTGTAAGTGAGCACTGTGGGTATGTTAGAAAATAATTTTTTGCATTTATTCTGAATTTAGTAGGTGGAGGCATGTTGACTTGGTCAATCGGTGTCTCTCAATCTTTGCTATGCAATCGGTGTCTGGGGTCTTATTTATATGAGACACCAAATGGCAATATTGTAATTTGGTAAAGTGGAGCGTATAACTTTAATTCAAACTCCAGAATGGTAAAGCGGCCATCCGTCTAATATT
Gene Information
|
NCBI Accession
|
YP_665621.1
|
|
Location
|
128-484 |
|
Gene Name
|
AV2 |
|
Protein Name
|
precoat protein |
|
Coding Region
|
ATGAAAATGTGGGATCCTTTAATTAACGAATTCCCTGAGACCGTTCACGGTTTTAGATGTATGCTTGCAATAAAATATCTGCAAGCCGTTCAATTGACGTACTCCCCTGATACGGTAGGATACGATTTAATTCGTGAACTTATACGTATTTTACGTACTAAGGATTATGGCCAAGCGACCTGCAGATATAGTCATTTCCACTCCCGCCTCCAAGGTACGTCGGAGGTTGAACTTCGACAGCCCCTATCGCAGCAGTGCTGCTGCCCCAACTGTCCTTGTCACCAACAAAAGGAGGACATGGGTCAATCGGCCCATGTACAGAAAGCCCAGAATGTACAGGATGTACAAAAGCCCTGA |
|
Protein Sequence
|
MKMWDPLINEFPETVHGFRCMLAIKYLQAVQLTYSPDTVGYDLIRELIRILRTKDYGQATCRYSHFHSRLQGTSEVELRQPLSQQCCCPNCPCHQQKEDMGQSAHVQKAQNVQDVQKP |
|
NCBI Accession
|
YP_665622.1
|
|
Location
|
294-1067 |
|
Gene Name
|
AV1 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGGCCAAGCGACCTGCAGATATAGTCATTTCCACTCCCGCCTCCAAGGTACGTCGGAGGTTGAACTTCGACAGCCCCTATCGCAGCAGTGCTGCTGCCCCAACTGTCCTTGTCACCAACAAAAGGAGGACATGGGTCAATCGGCCCATGTACAGAAAGCCCAGAATGTACAGGATGTACAAAAGCCCTGATGTTCCTCGTGGTTGTGAAGGTCCATGTAAGGTTCAGTCGTTTGAACAGCGTCACGATGTAGTCCATGTAGGTAAAGTAATATGCGTGTCTGATGTTACCCGTGGTAATGGGTTGACTCACCGTGTGGGTAAGAGGTTCTGTATTAAATCTGTATACGTTTTGGGTAAAATCTGGATGGATGAAAATATTAAGACCAAGAATCACACTAATACGGTCATGTTCTACCTAGTCCGTGATAGAAGACCCTTTGGTACTCCTCAGGATTTTGGACAAGTTTTTAACATGTATGATAATGAACCTAGTACTGCAACTGTGAAGAATGACAACAGAGATCGATTTCAAGTACTTAGAAGATTTCAGTCTACCGTTACTGGTGGCCAGTATGCATCTAAGGAGCAAGCCATAGTTAGGAAATTTATGAAGATTAACAACCACGTTACTTACAACCATCAGGAAGCTGCGAAGTACGATAACCATACAGAGAACGCCTTGTTATTGTATATGGCATGTACTCATGCCAGTAACCCTGTGTATGCTACTTTGAAAATCAGGATCTATTTTTACGATTCTGTTCAGAATTAA |
|
Protein Sequence
|
MAKRPADIVISTPASKVRRRLNFDSPYRSSAAAPTVLVTNKRRTWVNRPMYRKPRMYRMYKSPDVPRGCEGPCKVQSFEQRHDVVHVGKVICVSDVTRGNGLTHRVGKRFCIKSVYVLGKIWMDENIKTKNHTNTVMFYLVRDRRPFGTPQDFGQVFNMYDNEPSTATVKNDNRDRFQVLRRFQSTVTGGQYASKEQAIVRKFMKINNHVTYNHQEAAKYDNHTENALLLYMACTHASNPVYATLKIRIYFYDSVQN |
|
NCBI Accession
|
YP_665623.1
|
|
Location
|
1064-1468 |
|
Gene Name
|
AC3 |
|
Protein Name
|
replication enhancer protein |
|
Coding Region
|
ATGGATTCACGCACAGGGGAACTCATCACTGCAGCTCAGGCAAAGAATGGCGTGTATATCTGGACGGTGCCAAATCCCCTATATTTCAAGATAACAGATCACCTCAGCAGGCCATTCAACAAAGAACAAGACAAGATTACCGTCCAGATTCAATTCAACTACAACCTGAGAACTCAACTGGGAATTCACAAATGCTTTCTGATTTTCGAAGTCTGGACTCGCTTACAGCCTCAGACATGGCGTTTCTTGAGAGTATTTAAGAAGCAAGTCATGCAGTATTTAGATAATTTAGGTGTAATATCTATTAATAATGTAATTAGAGCAGTAGATCATGTATTATATAATAAACTACAACACACAATGTATGTACAGGAATTTCATGATATAAAATTCAATATTTATTAA |
|
Protein Sequence
|
MDSRTGELITAAQAKNGVYIWTVPNPLYFKITDHLSRPFNKEQDKITVQIQFNYNLRTQLGIHKCFLIFEVWTRLQPQTWRFLRVFKKQVMQYLDNLGVISINNVIRAVDHVLYNKLQHTMYVQEFHDIKFNIY |
|
NCBI Accession
|
YP_665624.1
|
|
Location
|
1209-1619 |
|
Gene Name
|
AC2 |
|
Protein Name
|
transcription activator protein |
|
Coding Region
|
ATGCAACCTTCATCACCCTCAACGAGCCACTCTACTCCAATACCAATCAAAGTCCAGCACAAGCTAGCCAAGAGGAAGAAAGTGACCAGGAGACGTAGGGTTGACCTAGACTGTGGTTGCACAATATACATAGGAATACACTGTGCCAACGATGGATTCACGCACAGGGGAACTCATCACTGCAGCTCAGGCAAAGAATGGCGTGTATATCTGGACGGTGCCAAATCCCCTATATTTCAAGATAACAGATCACCTCAGCAGGCCATTCAACAAAGAACAAGACAAGATTACCGTCCAGATTCAATTCAACTACAACCTGAGAACTCAACTGGGAATTCACAAATGCTTTCTGATTTTCGAAGTCTGGACTCGCTTACAGCCTCAGACATGGCGTTTCTTGAGAGTATTTAA |
|
Protein Sequence
|
MQPSSPSTSHSTPIPIKVQHKLAKRKKVTRRRRVDLDCGCTIYIGIHCANDGFTHRGTHHCSSGKEWRVYLDGAKSPIFQDNRSPQQAIQQRTRQDYRPDSIQLQPENSTGNSQMLSDFRSLDSLTASDMAFLESI |
|
NCBI Accession
|
YP_665625.1
|
|
Location
|
1522-2607 |
|
Gene Name
|
AC1 |
|
Protein Name
|
replication-associated protein |
|
Coding Region
|
ATGCCTCCACCTACTAAATTCAGAATAAATGCAAAAAATTATTTTCTAACATACCCACAGTGCTCACTTACAAAAGAAGAAGCACTTTCACAATTACAAACCCTAGAAACCCCAACTAATATATTATTCATCAGAATCTGCAGAGAACTACACAACGATGGGAATCCTCACCTGCATGTTCTCATCCAGTTCGAAGGAAAATTCCAATGCAAAAATAATAGATTCTTCGATCTCACATCCCCAAGTAGGTCAGCACATTTCCATCCAAACATTCAGGGAGCTAAAAGCTCGTCTGATGTCAAAACCTACATGGAGAAAGACGGAGACATCCTTGATTCTGGAGTTTTCCAGATCGATGGACGATCAGCTAGAGGAGGTTGCCAATCTGCAAACGACGCGTATGCCGAGGCAATCAACTCAGGGTCCAAAGTTTCGGCCCTCAATATATTAAGGGAGAAAGCTCCCAAAGATTATGTTTTACAGTTTCATAATTTAAATAGTAATTTAGATAGGATCTTTACACCTCCTATAGATATTTATGTTTCTCCTTTTATTTCATCTTCTTTTAATCAAGTTCCAGAAGAACTTGAAGAATGGGTCTCTGAAAACATAGCCAATGCCGCTGCGCGGCCATGGAGACCTGTAAGTATAGTCATACAGGGTGATAGCAGGACAGGGAAGACAATGTGGGCAAGATCACTGGGACCACACAACTATTTGTGTGGTCATCTTGACTTGAGCCCAAAAGTCTACAGCAATGATGCATGGTACAACGTCATTGATGACGTAGACCCGCACTATCTAAAGCACTTTAAGGAATTCATGGGGGCCCAACGAGACTGGCAAAGCAACACAAAGTATGGGAAGCCAATTCAAATTAAAGGTGGAATCCCAACAATCTTCCTTTGCAATCCAGGACCAACTGCCTCCTATATAGAATATCTTGATGAAGAAAAGAATAGTGCATTAAAAGCCTGGGCAATAAAAAATGCAACCTTCATCACCCTCAACGAGCCACTCTACTCCAATACCAATCAAAGTCCAGCACAAGCTAGCCAAGAGGAAGAAAGTGACCAGGAGACGTAG |
|
Protein Sequence
|
MPPPTKFRINAKNYFLTYPQCSLTKEEALSQLQTLETPTNILFIRICRELHNDGNPHLHVLIQFEGKFQCKNNRFFDLTSPSRSAHFHPNIQGAKSSSDVKTYMEKDGDILDSGVFQIDGRSARGGCQSANDAYAEAINSGSKVSALNILREKAPKDYVLQFHNLNSNLDRIFTPPIDIYVSPFISSSFNQVPEELEEWVSENIANAAARPWRPVSIVIQGDSRTGKTMWARSLGPHNYLCGHLDLSPKVYSNDAWYNVIDDVDPHYLKHFKEFMGAQRDWQSNTKYGKPIQIKGGIPTIFLCNPGPTASYIEYLDEEKNSALKAWAIKNATFITLNEPLYSNTNQSPAQASQEEESDQET |
|
NCBI Accession
|
YP_665626.1
|
|
Location
|
2157-2450 |
|
Gene Name
|
AC4 |
|
Protein Name
|
AC4 protein |
|
Coding Region
|
ATGGGAATCCTCACCTGCATGTTCTCATCCAGTTCGAAGGAAAATTCCAATGCAAAAATAATAGATTCTTCGATCTCACATCCCCAAGTAGGTCAGCACATTTCCATCCAAACATTCAGGGAGCTAAAAGCTCGTCTGATGTCAAAACCTACATGGAGAAAGACGGAGACATCCTTGATTCTGGAGTTTTCCAGATCGATGGACGATCAGCTAGAGGAGGTTGCCAATCTGCAAACGACGCGTATGCCGAGGCAATCAACTCAGGGTCCAAAGTTTCGGCCCTCAATATATTAA |
|
Protein Sequence
|
MGILTCMFSSSSKENSNAKIIDSSISHPQVGQHISIQTFRELKARLMSKPTWRKTETSLILEFSRSMDDQLEEVANLQTTRMPRQSTQGPKFRPSIY |