Sida yellow vein virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_000843025.1 |
| Release date |
2015/2/12 |
| Submitter |
Frischmuth,T., Engel,M., Lauster,S., Jeske,H. |
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
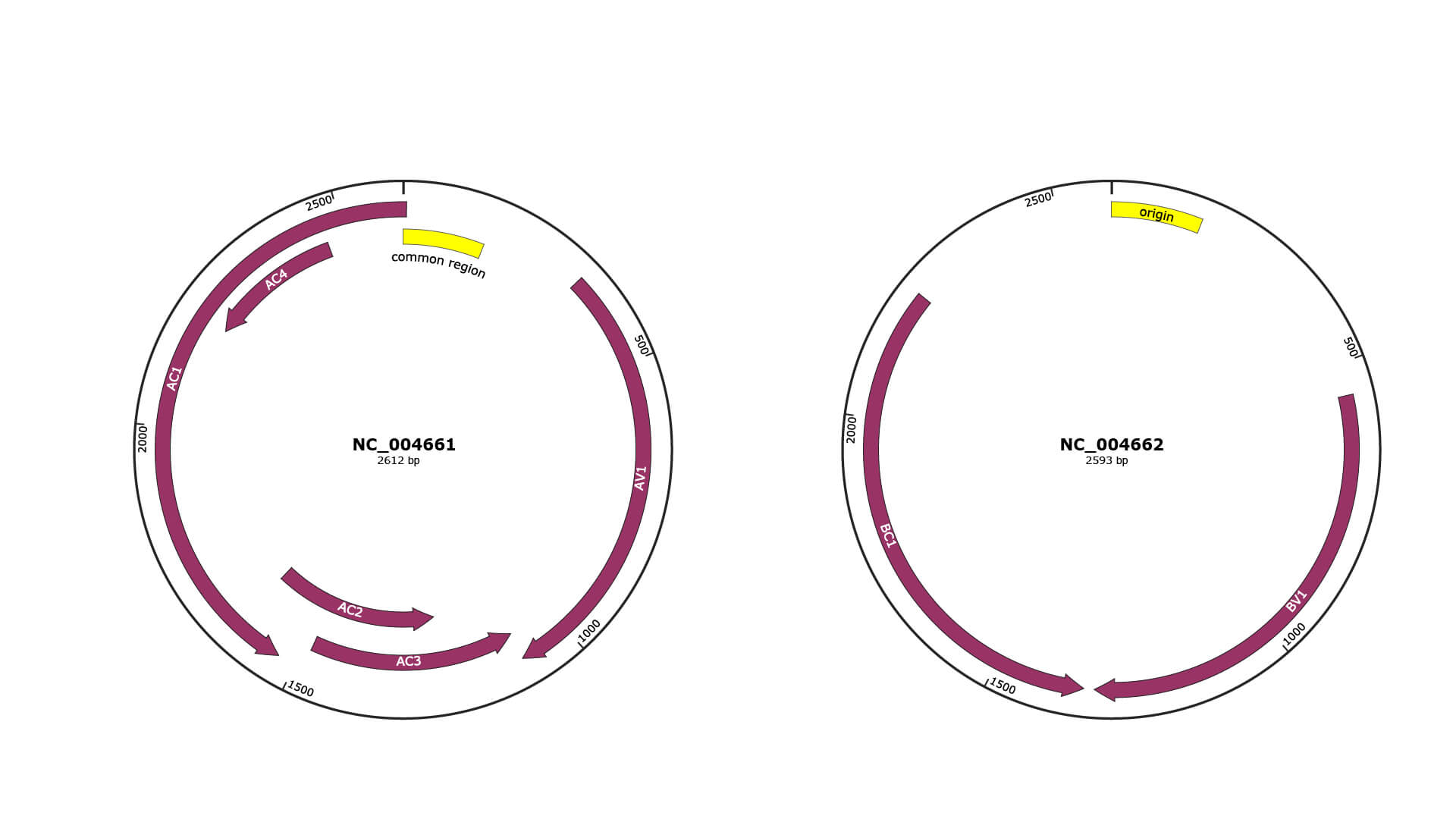
JBrowse
Genome
TGGCATTTTTGTAATAAGAGTGTGTACTCCTGATGAGCTCCCTCAAAACTGGCCTATTCAATTGGAGTATTGGAGGCTAATATATAGTAGAACTCTCATTAACGGATTTGCAACACGTGGCGGCCATCCGCTATAATATTACCGGATGGCCGCGCGGAGTACGCTCCCCCCACGCGCGCACGCTCCTCTTTAATTTGAATTAAAGCTCTCCGCTTTCGTTTCGTCCAATCATGTAACGTCTGACGAGCTTAGATATTTTGAACAACTTGGGCGCTAAGTTGTTGAGTGTCGGTTATAAATTAAAGAGGGCCCAGCCCACTGTCTTTAACTCAAAATGCCTAAGCGCGATCTCCCATGGCGCTCGATCGCGGGAACTTCAAAGGTTAGTCGCAATGCTAATTATTCTCCACGTGCAGGAAGTGGGCCGGGGGTGAACAAGGCCTCCGAATGGGTTAACAGGCCCATGTACAGGAAGCCCAGGATATACCGGACGTTAAAGACGCCCGGCGTCCCACGAGGCTGTGAAGGCCCGTGCAAGGTCCAGTCCTATGAACAGCGTCATGATATATCACATGTGGGTAAGGTCATGTGTATATCTGATGTGACACGTGGAAATGGTATCACCCACCGTGTTGGTAAGCGTTTCTGTGTTAAGTCCGTGTACATTCTCGGTAAGATCTGGATGGATGAGAACATCAAGCTCAAGAACCACACGAACAGTGTCATGTTCTGGTTGGTCAGGGACCGTAGACCGTATGGCACGCCCATGGACTTTGGCCAGGTGTTCAACATGTTCGACAATGAGCCTAGCACTGCCACGGTGAAGAACGATCTACGCGATCGTTACCAAGTCATGCACAAATTCTATGGTAAGGTGACAGGTGGACAGTATGCGAGCAACGAGCAGGCTATAGTCAAGCGCTTCTGGAAGGTCTACAATCATGTGGTCTACAACCATCAGGAGGCTGGCAAGTACGAGAATCATACGGAGAACGCTTTGTTATTGTATATGGCATGTACTCATGCGTCTAACCCTGTGTATGCAACGCTTAAGATTCGTATCTATTTCTACGATTCGATCATGAATTAATAAATTTTGAATTTTATTGAATGATTTCCCAGTACACGAGTTACATAGAATCTGTCTGTTGCGAAACGAACAGCTCTAATTACATTGTTAATGCAAATAACTCCTAATCGATCTAAATACATGTTAACTAAACGTCTAAACCTAGCTAAATAGGTCGACCCAGAAGCTGTTATCGATATCGTCCAGACTTGGAAGTTCAGGAAGGCTTTGTGGAGATGCAATGCTCTCCTCAGGTTGTGGTTGAACCGTATCTGGATATTGTATACCCTGCTGTTGGTGTAGATTGGATCCTCTACTAGGAACATCTTGAAATAAAGGGGATTTTCGATCTCCCAGGTATAAACGCCATTCTCTGCCTGATGTGCAGTGATGAGTTCCCCTGTGCGTGAATCCATGCCCTGTGCAGCCTATGTGGAAGTAGATGGAGCAACCGCACTCCAGATCAATCCGCCGTCTCCTGATCGACCTCCTCTTGGCTTGCCTGTGCGCTGTCTTGATAGAGGGCGGATGTGAGGGTGATGAAGACCGCATTCTTGATGGTCCAGTTAAGTAGTGATGAGTTTTCCTCTTTGTTCAGGAAATCTTTATAGCTGGCACCCTCACCAGGATTGCAAAGCACGATTGATGGGATCCCTCCTTTAATTTGAACTGGCTTGCCGTACTTACAATTTGACTGCCAGTCCTTCTGGCCCCAGAAAGATTCTTTCCAGTGCTTTAGCTTTAGATATTGCGGTGCGACGTCATCAATGACGTTATACTCCACTTCGTTCGAATAGACTCTTGGGTTGAAGTCCAGATGTCCACTAAGATAATTATGTGGGCCTAACGCACGAGCCCACATCGTCTTCCCTGTTCTCGAATCACCTTCCACGATGATACTAACAGGTCTCTCTGGGCGCGCAGCGGAATCACACCCAAAATAATCATCCGCCCACTCTTGCATCCTCTCCGGCACGTTAGTGAATGAGGAGAGTTGAAACGGAGGAACCCACGGTGACGGAGCCTTTGCGAATATTCTCTCTAGGTTTGAGCGGATGTTATGATTTTGCAGGACAAAATCTTTGGGTTGTTCTTCCTTCAAAACCGTCATGGCACCTAGAACAGATCCTGCATTCAACGCCTTGGCATATGAATCGTTAGCTGTTTGCTGACCTCCCCTAGCAGATCTACCGTCGACCTGGAATTCTCCCCATTCAATGGTGTCCCCGTCCTTGTCGATGTAGGACTTGACATCGGAGCTGGATTTAGCTCCCTGAATGTTCGGATGGAAATGTACTGACCTGGTTGGGGACACCAGATCGAAGAGTCTGTTATTCGTGCATTGGTACTTCCCTTCGAACTGGATGAGCACATGCAGATGAGGTTCCCCATTCTCATGCAATTCTCTGCAGATCTTGATGAACTTCTTGTTAACTGGAGTTTGTAGGTTTTCTAATTGGGAAAGTGCTTCCTCTTTAGTAAGAGAGCACTGGGGATATGTGAGGAAATAATTTTTGGACTGGACTCTAAATCTCTTAGGCGG
TGGCATTTTTGTAATAAGAGGGTGTACTCCTGATGAGCTCCCTCAAAACTGGCCTATTCAATTGGAGTATTGGAGGCTAATATATAGTAGAACTCTCATTAACGGATTTGCAACACGTGGCGGCCATCCGCTATAATATTACCGGATGGCCGCGCGCCGCCCGCTCCCTGCCACCTGGCGCTCTCTCCTCCCTTGGTGCTGGTGACCCTGACACTTGGCGCGCTCTCGACCCTCGATCTTTATATACCCACGTGGTTCGGCTAGTCTTTGTTGACCGACGCTTTAATTCAAATTAAAGCTCAACTCTTTTATGTCGCGCGATATCAATTCGAATTTGAATTATTGATTCGCGTTTTCTGAGTGTGCCCCATTGTACTACATGGACGACGTGGCCGATTTGAGACCATGCTGCTGAGCTAAGTTAAGTGTATGTCTGACTCATCCTTGTCTTTAAATTGGTCCGGAATGATATATTATATTTTAAGTGACTCAGCTGTTAACCACGTTTAAATCGTTAGCCTTATTATTCGTCTAATTACGTCTTATCCTTTGATCATGTATCCATGTAGGTATAAACGTGGTCCCTCCTTCACTCCACGACGATTTTATTCACGTAACCATGTGTTTAAGCGTTCTAATCCACTCAAACGCGATGATGGGAAACGAAGGCCTGTTAACTCTAATAAGGCCCATGATGAGTCAAGGATGAAAGCCCAACGGATCCACGAGAACCAGTTTGGACCTGACTTTGTTATGGCCCATAATTCGGCCATTTCCACGTTTATCAGCTATCCAAACCAGGGTAAGACTGAACCGAACCGGAGCAGGTCCTACATCAAGTTGAGACGACTGCGTTTCAAAGGAACTGTGAAGATTGAACGTGTCCAGTCTGATATGAACATGGACTGTGCTACCCCCAAGGTTGAAGGAGTGTTCTCCCTTGTCGTAGTTGTGGATCGTAAACCCCACTTGGGTGCATCTGGTTGTCTTCACACTTTCGACGAGCTGTTCGGTGCCAGGATCCACAGTCACGGTAATCTCAGCATCACTCCTTCCCTGAAGGACCGTTTCTACATAAGACACGTGTTCAAACGTGTGTTGTCTGTGGAGAAGGATACGTTGATGGTTGACGTGGAAGGGTCCACCACTCTCTCTAACAGGCGATATAACTGTTGGTCCACGTTTAAGGATCTTGATCACGATTCATGTAACGGTGTTTATGGCAACATTAGCAAGAACGCCCTCTTAGTTTATTATTGTTGGATGTCAGATACTGTGTCTAAGGCATCTACATTTGTATCGTTTGACCTTGACTATGTTGGATGATTAATAAAACAATAATATTTATTGCAATGATTTGGGCTGTGCCGGTTTACAATTATTGATAATACATTCTTGGACCGTAGTCCTCACTAGCTCGTTTAATTGGCCCATCGACATTGTGATGTTGGATTCTGCTCTCTGGGCTCCCACGATCGAAGCAGACTCTCCTGGATCTAACACGTTGGTCCCAAGCCTGCTTAGGTGCCTGTACGGGTGAAGCTCGTTCTCCACCTCGGAGTCCGCATCTGAATGCCCAGTTCCCACCGCACTCCTGGAAGCCCATGATTCTCCTGGCCTGATTTCAATTGGGCCTCTGAGCCCAGTTCTTGACATGGACGCGCATCTGATGGGCTTCCTTTCCCATCTTCCGTAGTCGACGTGCGAGAAGTCCACATCCTTGTCGGTGAACTGCTTGGAAAGGATCTTCACCGTCGGTGCCCGGAAAGGGATATCAACCGAGTGTTTCGCCGTCGACAGTTTCAGTTTCCCTTTGAATTTCGCGAAGTGGGTTCTCTGATGAACATTCGTATCGCAGACCCTGTAGTACAGCTTCCATGGAATTGGGTCCTTCAGCGAGAAGAACGAAGCGGAAAAGTAATGGAGATCAATGTTGCATCTGATCGGAAACGTCCACGATGCCTGTAGAGACTCATTGTCCGTCATTCTCTTGTCGTGGATCTCCACTATCACCGACCCCGTCGCGTTGATCGGAACTTGCTGCCTGTATTCTATGACACAGTGGTCGATCTTCATGCAGCTCCTGCTCAATCTCGCCGTCAACTGCGACGCCGTCGACGGAAATTGCAGAATTATCTCAGTTAGGTCATGGGAAAGCTGATACTCGTCTCGATGTGACTCTATGTAGTTGAAGGCGTTGGGAGGATTAACTAACTGAGAATCCATATGAGAAAGAAAGGCCGCGCAGCTGAAACCGATTGCTGAAGTTGAACAATTTGAGAAGATGCTACGGTTCCGTACGACTAACTGATGAAGAACTTCTGTTGAAGAATAAAATGTTTCCTGTGGTTTTCAGAAAGTAGCTGTTGAAGATGAACAACACTGGTTTAGGTTTCTGGGTTTCCCAGAAAGTAACTGATGAACAGGAAGAACAGTCGTTTAATTTCTAATGAATATGTTGTTTTGTTTTTGAGAAAGAGGAGAAATCTGGAGAGTAAAGTAAGTTATGTGTTTAGTTAGATCTGATATGTTTATATAGACACCCTATCGTTATGTTTTTAGAGCGTTCAGAGGAAGTCTTTTGTTTAATGAA
Gene Information
|
NCBI Accession
|
NP_808900.1
|
|
Location
|
1533-2612,1-6 |
|
Gene Name
|
AC1 |
|
Protein Name
|
AC1 protein |
|
Coding Region
|
ATGCCACCGCCTAAGAGATTTAGAGTCCAGTCCAAAAATTATTTCCTCACATATCCCCAGTGCTCTCTTACTAAAGAGGAAGCACTTTCCCAATTAGAAAACCTACAAACTCCAGTTAACAAGAAGTTCATCAAGATCTGCAGAGAATTGCATGAGAATGGGGAACCTCATCTGCATGTGCTCATCCAGTTCGAAGGGAAGTACCAATGCACGAATAACAGACTCTTCGATCTGGTGTCCCCAACCAGGTCAGTACATTTCCATCCGAACATTCAGGGAGCTAAATCCAGCTCCGATGTCAAGTCCTACATCGACAAGGACGGGGACACCATTGAATGGGGAGAATTCCAGGTCGACGGTAGATCTGCTAGGGGAGGTCAGCAAACAGCTAACGATTCATATGCCAAGGCGTTGAATGCAGGATCTGTTCTAGGTGCCATGACGGTTTTGAAGGAAGAACAACCCAAAGATTTTGTCCTGCAAAATCATAACATCCGCTCAAACCTAGAGAGAATATTCGCAAAGGCTCCGTCACCGTGGGTTCCTCCGTTTCAACTCTCCTCATTCACTAACGTGCCGGAGAGGATGCAAGAGTGGGCGGATGATTATTTTGGGTGTGATTCCGCTGCGCGCCCAGAGAGACCTGTTAGTATCATCGTGGAAGGTGATTCGAGAACAGGGAAGACGATGTGGGCTCGTGCGTTAGGCCCACATAATTATCTTAGTGGACATCTGGACTTCAACCCAAGAGTCTATTCGAACGAAGTGGAGTATAACGTCATTGATGACGTCGCACCGCAATATCTAAAGCTAAAGCACTGGAAAGAATCTTTCTGGGGCCAGAAGGACTGGCAGTCAAATTGTAAGTACGGCAAGCCAGTTCAAATTAAAGGAGGGATCCCATCAATCGTGCTTTGCAATCCTGGTGAGGGTGCCAGCTATAAAGATTTCCTGAACAAAGAGGAAAACTCATCACTACTTAACTGGACCATCAAGAATGCGGTCTTCATCACCCTCACATCCGCCCTCTATCAAGACAGCGCACAGGCAAGCCAAGAGGAGGTCGATCAGGAGACGGCGGATTGA |
|
Protein Sequence
|
MPPPKRFRVQSKNYFLTYPQCSLTKEEALSQLENLQTPVNKKFIKICRELHENGEPHLHVLIQFEGKYQCTNNRLFDLVSPTRSVHFHPNIQGAKSSSDVKSYIDKDGDTIEWGEFQVDGRSARGGQQTANDSYAKALNAGSVLGAMTVLKEEQPKDFVLQNHNIRSNLERIFAKAPSPWVPPFQLSSFTNVPERMQEWADDYFGCDSAARPERPVSIIVEGDSRTGKTMWARALGPHNYLSGHLDFNPRVYSNEVEYNVIDDVAPQYLKLKHWKESFWGQKDWQSNCKYGKPVQIKGGIPSIVLCNPGEGASYKDFLNKEENSSLLNWTIKNAVFITLTSALYQDSAQASQEEVDQETAD |
|
NCBI Accession
|
NP_808901.1
|
|
Location
|
335-1090 |
|
Gene Name
|
AV1 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGCCTAAGCGCGATCTCCCATGGCGCTCGATCGCGGGAACTTCAAAGGTTAGTCGCAATGCTAATTATTCTCCACGTGCAGGAAGTGGGCCGGGGGTGAACAAGGCCTCCGAATGGGTTAACAGGCCCATGTACAGGAAGCCCAGGATATACCGGACGTTAAAGACGCCCGGCGTCCCACGAGGCTGTGAAGGCCCGTGCAAGGTCCAGTCCTATGAACAGCGTCATGATATATCACATGTGGGTAAGGTCATGTGTATATCTGATGTGACACGTGGAAATGGTATCACCCACCGTGTTGGTAAGCGTTTCTGTGTTAAGTCCGTGTACATTCTCGGTAAGATCTGGATGGATGAGAACATCAAGCTCAAGAACCACACGAACAGTGTCATGTTCTGGTTGGTCAGGGACCGTAGACCGTATGGCACGCCCATGGACTTTGGCCAGGTGTTCAACATGTTCGACAATGAGCCTAGCACTGCCACGGTGAAGAACGATCTACGCGATCGTTACCAAGTCATGCACAAATTCTATGGTAAGGTGACAGGTGGACAGTATGCGAGCAACGAGCAGGCTATAGTCAAGCGCTTCTGGAAGGTCTACAATCATGTGGTCTACAACCATCAGGAGGCTGGCAAGTACGAGAATCATACGGAGAACGCTTTGTTATTGTATATGGCATGTACTCATGCGTCTAACCCTGTGTATGCAACGCTTAAGATTCGTATCTATTTCTACGATTCGATCATGAATTAA |
|
Protein Sequence
|
MPKRDLPWRSIAGTSKVSRNANYSPRAGSGPGVNKASEWVNRPMYRKPRIYRTLKTPGVPRGCEGPCKVQSYEQRHDISHVGKVMCISDVTRGNGITHRVGKRFCVKSVYILGKIWMDENIKLKNHTNSVMFWLVRDRRPYGTPMDFGQVFNMFDNEPSTATVKNDLRDRYQVMHKFYGKVTGGQYASNEQAIVKRFWKVYNHVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSIMN |
|
NCBI Accession
|
NP_808902.1
|
|
Location
|
1087-1485 |
|
Gene Name
|
AC3 |
|
Protein Name
|
AC3 protein |
|
Coding Region
|
ATGGATTCACGCACAGGGGAACTCATCACTGCACATCAGGCAGAGAATGGCGTTTATACCTGGGAGATCGAAAATCCCCTTTATTTCAAGATGTTCCTAGTAGAGGATCCAATCTACACCAACAGCAGGGTATACAATATCCAGATACGGTTCAACCACAACCTGAGGAGAGCATTGCATCTCCACAAAGCCTTCCTGAACTTCCAAGTCTGGACGATATCGATAACAGCTTCTGGGTCGACCTATTTAGCTAGGTTTAGACGTTTAGTTAACATGTATTTAGATCGATTAGGAGTTATTTGCATTAACAATGTAATTAGAGCTGTTCGTTTCGCAACAGACAGATTCTATGTAACTCGTGTACTGGGAAATCATTCAATAAAATTCAAAATTTATTAA |
|
Protein Sequence
|
MDSRTGELITAHQAENGVYTWEIENPLYFKMFLVEDPIYTNSRVYNIQIRFNHNLRRALHLHKAFLNFQVWTISITASGSTYLARFRRLVNMYLDRLGVICINNVIRAVRFATDRFYVTRVLGNHSIKFKIY |
|
NCBI Accession
|
NP_808903.1
|
|
Location
|
1232-1621 |
|
Gene Name
|
AC2 |
|
Protein Name
|
AC2 protein |
|
Coding Region
|
ATGCGGTCTTCATCACCCTCACATCCGCCCTCTATCAAGACAGCGCACAGGCAAGCCAAGAGGAGGTCGATCAGGAGACGGCGGATTGATCTGGAGTGCGGTTGCTCCATCTACTTCCACATAGGCTGCACAGGGCATGGATTCACGCACAGGGGAACTCATCACTGCACATCAGGCAGAGAATGGCGTTTATACCTGGGAGATCGAAAATCCCCTTTATTTCAAGATGTTCCTAGTAGAGGATCCAATCTACACCAACAGCAGGGTATACAATATCCAGATACGGTTCAACCACAACCTGAGGAGAGCATTGCATCTCCACAAAGCCTTCCTGAACTTCCAAGTCTGGACGATATCGATAACAGCTTCTGGGTCGACCTATTTAGCTAG |
|
Protein Sequence
|
MRSSSPSHPPSIKTAHRQAKRRSIRRRRIDLECGCSIYFHIGCTGHGFTHRGTHHCTSGREWRLYLGDRKSPLFQDVPSRGSNLHQQQGIQYPDTVQPQPEESIASPQSLPELPSLDDIDNSFWVDLFS |
|
NCBI Accession
|
NP_808904.1
|
|
Location
|
2204-2467 |
|
Gene Name
|
AC4 |
|
Protein Name
|
AC4 protein |
|
Coding Region
|
ATGAGAATGGGGAACCTCATCTGCATGTGCTCATCCAGTTCGAAGGGAAGTACCAATGCACGAATAACAGACTCTTCGATCTGGTGTCCCCAACCAGGTCAGTACATTTCCATCCGAACATTCAGGGAGCTAAATCCAGCTCCGATGTCAAGTCCTACATCGACAAGGACGGGGACACCATTGAATGGGGAGAATTCCAGGTCGACGGTAGATCTGCTAGGGGAGGTCAGCAAACAGCTAACGATTCATATGCCAAGGCGTTGA |
|
Protein Sequence
|
MRMGNLICMCSSSSKGSTNARITDSSIWCPQPGQYISIRTFRELNPAPMSSPTSTRTGTPLNGENSRSTVDLLGEVSKQLTIHMPRR |
|
NCBI Accession
|
NP_808905.1
|
|
Location
|
556-1326 |
|
Gene Name
|
BV1 |
|
Protein Name
|
BV1 protein |
|
Coding Region
|
ATGTATCCATGTAGGTATAAACGTGGTCCCTCCTTCACTCCACGACGATTTTATTCACGTAACCATGTGTTTAAGCGTTCTAATCCACTCAAACGCGATGATGGGAAACGAAGGCCTGTTAACTCTAATAAGGCCCATGATGAGTCAAGGATGAAAGCCCAACGGATCCACGAGAACCAGTTTGGACCTGACTTTGTTATGGCCCATAATTCGGCCATTTCCACGTTTATCAGCTATCCAAACCAGGGTAAGACTGAACCGAACCGGAGCAGGTCCTACATCAAGTTGAGACGACTGCGTTTCAAAGGAACTGTGAAGATTGAACGTGTCCAGTCTGATATGAACATGGACTGTGCTACCCCCAAGGTTGAAGGAGTGTTCTCCCTTGTCGTAGTTGTGGATCGTAAACCCCACTTGGGTGCATCTGGTTGTCTTCACACTTTCGACGAGCTGTTCGGTGCCAGGATCCACAGTCACGGTAATCTCAGCATCACTCCTTCCCTGAAGGACCGTTTCTACATAAGACACGTGTTCAAACGTGTGTTGTCTGTGGAGAAGGATACGTTGATGGTTGACGTGGAAGGGTCCACCACTCTCTCTAACAGGCGATATAACTGTTGGTCCACGTTTAAGGATCTTGATCACGATTCATGTAACGGTGTTTATGGCAACATTAGCAAGAACGCCCTCTTAGTTTATTATTGTTGGATGTCAGATACTGTGTCTAAGGCATCTACATTTGTATCGTTTGACCTTGACTATGTTGGATGA |
|
Protein Sequence
|
MYPCRYKRGPSFTPRRFYSRNHVFKRSNPLKRDDGKRRPVNSNKAHDESRMKAQRIHENQFGPDFVMAHNSAISTFISYPNQGKTEPNRSRSYIKLRRLRFKGTVKIERVQSDMNMDCATPKVEGVFSLVVVVDRKPHLGASGCLHTFDELFGARIHSHGNLSITPSLKDRFYIRHVFKRVLSVEKDTLMVDVEGSTTLSNRRYNCWSTFKDLDHDSCNGVYGNISKNALLVYYCWMSDTVSKASTFVSFDLDYVG |
|
NCBI Accession
|
NP_808906.1
|
|
Location
|
1345-2226 |
|
Gene Name
|
BC1 |
|
Protein Name
|
BC1 protein |
|
Coding Region
|
ATGGATTCTCAGTTAGTTAATCCTCCCAACGCCTTCAACTACATAGAGTCACATCGAGACGAGTATCAGCTTTCCCATGACCTAACTGAGATAATTCTGCAATTTCCGTCGACGGCGTCGCAGTTGACGGCGAGATTGAGCAGGAGCTGCATGAAGATCGACCACTGTGTCATAGAATACAGGCAGCAAGTTCCGATCAACGCGACGGGGTCGGTGATAGTGGAGATCCACGACAAGAGAATGACGGACAATGAGTCTCTACAGGCATCGTGGACGTTTCCGATCAGATGCAACATTGATCTCCATTACTTTTCCGCTTCGTTCTTCTCGCTGAAGGACCCAATTCCATGGAAGCTGTACTACAGGGTCTGCGATACGAATGTTCATCAGAGAACCCACTTCGCGAAATTCAAAGGGAAACTGAAACTGTCGACGGCGAAACACTCGGTTGATATCCCTTTCCGGGCACCGACGGTGAAGATCCTTTCCAAGCAGTTCACCGACAAGGATGTGGACTTCTCGCACGTCGACTACGGAAGATGGGAAAGGAAGCCCATCAGATGCGCGTCCATGTCAAGAACTGGGCTCAGAGGCCCAATTGAAATCAGGCCAGGAGAATCATGGGCTTCCAGGAGTGCGGTGGGAACTGGGCATTCAGATGCGGACTCCGAGGTGGAGAACGAGCTTCACCCGTACAGGCACCTAAGCAGGCTTGGGACCAACGTGTTAGATCCAGGAGAGTCTGCTTCGATCGTGGGAGCCCAGAGAGCAGAATCCAACATCACAATGTCGATGGGCCAATTAAACGAGCTAGTGAGGACTACGGTCCAAGAATGTATTATCAATAATTGTAAACCGGCACAGCCCAAATCATTGCAATAA |
|
Protein Sequence
|
MDSQLVNPPNAFNYIESHRDEYQLSHDLTEIILQFPSTASQLTARLSRSCMKIDHCVIEYRQQVPINATGSVIVEIHDKRMTDNESLQASWTFPIRCNIDLHYFSASFFSLKDPIPWKLYYRVCDTNVHQRTHFAKFKGKLKLSTAKHSVDIPFRAPTVKILSKQFTDKDVDFSHVDYGRWERKPIRCASMSRTGLRGPIEIRPGESWASRSAVGTGHSDADSEVENELHPYRHLSRLGTNVLDPGESASIVGAQRAESNITMSMGQLNELVRTTVQECIINNCKPAQPKSLQ |