Sida yellow mottle virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_000896395.1 |
| Isolate |
Cuba |
| Release date |
2015/2/22 |
| Submitter |
Fiallo-Olive,E., Navas-Castillo,J., Moriones,E., Martinez-Zubiaur,Y. |
| Host |
|
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
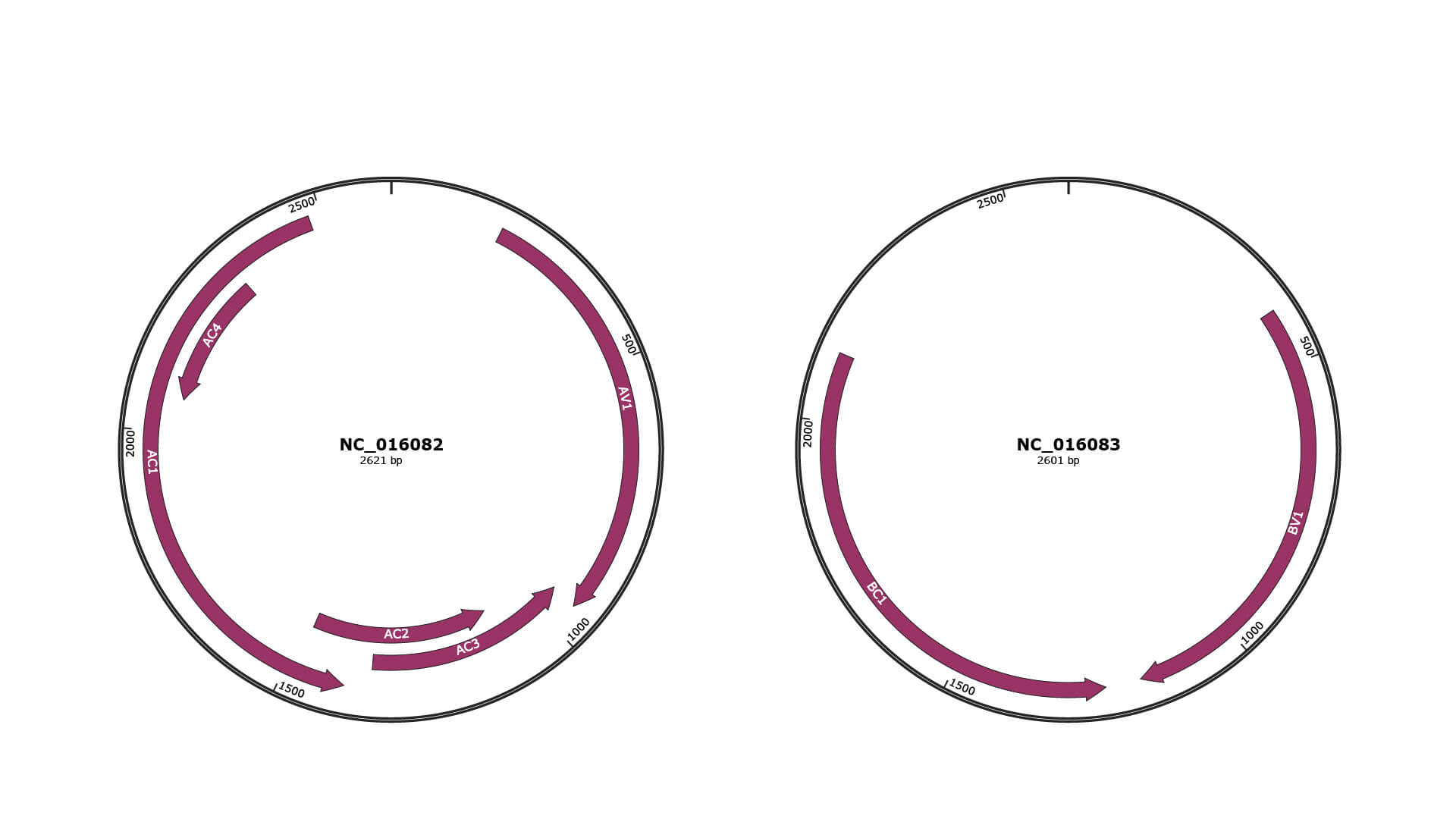
JBrowse
Genome
ACCGGATGGCCGCGCGCCCCCCCTGGTGCCGTACACTCTCGCGCGATCTTTAATTTAAATTAAAGCGTACTGCTTTGTGTTTGTCCAATCATGTTGCGTCTGACGAGCCTAGATATTTGCAACAACTTGGGCCCTAAGTTGTTGGGTGTCCGTTATAAATTAAAGATGACTTTGGCCCACAATCTTTAACTCAAAATGCCTAAGCGCGATCTGCCATGGCGCTCGATGGCGGGAACCTCAAAGGTTAGCCGCAATGCTAACTATTCTCCTCGTGCAGGTAGTGGGCCAAGAGGAAACAAGGCCTCTGAATGGGTGAACAGGCCAATGTACAGGAAGCCCAGGATCTACCGGACGCTGAGGACCCCCGATGTGCCCAGAGGCTGTGAAGGCCCATGTAAGGTCCAGTCCTATGAACAGCGCCATGACATCTCACATGTCGGGAAGGTCATGTGCATCTCGGATGTGACACGTGGTAATGGCATCACCCATCGTGTGGGTAAGCGTTTCTGTGTTAAGTCTGTGTATATCTTAGGGAAGATCTGGATGGACGAGAACATCAAGCTCAAGAACCACACGAACAGTGTCATGTTCTGGTTGGTCAGAGACCGTAGACCGTATGGCACGCCTATGGATTTTGGTCAGGTGTTTAACATGTTCGACAACGAGCCAAGCACTGCCACGGTGAAGAACGATCTCCGCGATCGTTACCAGGTTATGCACAAGTTCTATGGCAAGGTGACTGGTGGACAGTATGCCAGCAACGAGCAGGCTATAGTCAAGAGGTTCTGGAAGGTCAACAATTATGTGGTGTACAACCACCAAGAGGCTGGCAAGTACGAGAATCACACGGAGAACGCCCTGTTATTGTATATGGCATGTACTCATGCATCTAACCCTGTGTATGCAACTCTGAAGATTCGGATCTATTTTTACGATTCGATTATGAATTAATAAAATTTGAATTTTATTGAATGATTTTCCAGTACATGATTTACATACGATCTGTCTGTCGCGAATCGAACAGCTCTGATTACATTGTTTAACGAAATGACGCCTAACTGATCTAAATACATGTTGACTAAATGCCTAAATCTAGCTAAATAAGTTGACCCAGAAGCTGTCATCGATGTCGTCCAGACTTGGAAGTTCAGGTAGGCTTTGTGGAGATGCAACGCTCTCCTCAGGTTGTGATTGAACCGTATCTGTACGTGATACACCCTCGTTCTGGTGTACAACGGGTCCTCTACTCTGTACATCTTGAAATACAGGGGATTTTCGATCTCCCAGATATACACGCCATTCTCCGCCTGACGTGCAGTGATGAATTCCCCTGTGCGTGAATCCATGTCCCGTACAGTCTATGTGGAAGTAGATGGAGCACCCGCACTGGAGATCAATCCTGCGCCTCCTGATCGCCCTTTTCTTGGCCTGTCTGTGTGCTATCTTGATAGAGGGCGGCTGTGAGGGTGATGAAGATCGCATTCTTGATAGTCCAGTTTCTTAGTCCTGCATTTTCCTCTTTGTCCAGGAACTCTTTATAGCTGGAACCCTCACCAGGATTGCAAAGCACGATTGCTGGGATTCCACCTTTAATTTGAACAGGCTTACCGTATTTGCAATTTGACTGCCAATCTTTTTGGGCCCCCAGCAATTCTTTCCAGTGCTTTAGCTTTAGATATTGCGGTGCGACGTCATCAATGACGTTATACTCCACCGCGTTTGAATAGACTCGACCATTGAAGTCCAGGTGTCCACTGAGATAGTTATGTGGGCCTAACGCACGTGCCCACATCGTCTTCCCTGTTCTTGAATCACCTTCTACTATGAGACTTAATGGTCTATCTGGCCGCGCAGCGGAACCCCTACCAAAATACTCATCGGCCCATTCTTGCATCTCGTCCGGAACGTTAGTGAATGAGGAGAGTTGAAACGGAGGTACCCACGGTTCCGGAGCCTTCTGAAATATCCGATGAGCATTGGCAACTAAATTGTGATGTTGAAGGAAGAAATGTTGAGGCTGCTCTTCCTTGATTATTTGCAGCGCCTCTTCTACAGAAGAGGCATTCAATGCCTTGGCATACGTGTCGTTAGTCGATTGGCAGCCTCCTCTAGCACTTCTACCGTCGATCTGGAATTCCCCCCATTCCAGTGTATCTCCGTCCTTGTCGATGTAGGACTTGACGTCGGAGCTAGATTTAGCTCCCTGTATGTTCGGATGGAAATGTGCTGACCTGGTTGGGGAGACCAGATCGAAGAATCTGTTATTCTTGCACTGGTATTTTCCCTCGAATTGTACAAGCACATGGAGATGAGGCTCCCCATTCTCATGAAGCTCTCTGCAAATTTTGATGAACTTCTTGTTAACTGGAGTTGCTAGGTTTTGTAATTGGGAAAGTGCCTCTTCTTTTGACAGAGAGCACTGTGGATAAGTGAGGAAATAGTTTTTGGCTGAGACTTTAAAACGCTTAACCGATGGCATTTTTGTAATAAGAAGGGGTACCCCAATTGGAGTCTCTCCAAACTTGCTCTATCAATTGGGGTTTGGGGTCTCATTTATACTAGAGGTTTCTATAGAACTCTCAATCTCGTTCGCACACGTGGCGGCCATCCGATATAATATT
ACCGGATGGCCGCGCTTTGGTGTCCCCCCCCCCCTCCCGTGGTGGCGCACTCTCACGCTCCCCTCCCTGGTGCCGTGCTCACACGCGCTCTCTCATTGGTGCGGGTCCTTCACCTTCCGTCTTTTCGACTGTCCTTTAATTTGAATTAAAGGAAATGGCTTTCTCGCGCGACTTGCTTTTATTATTTGAATTATTGTCGCGAGATTAGTGAGTATGGCCCATTGTACCTGGTGAAGGACGTGGCTAACTTTGGACCAAGCTGCTGAGTTTATTTCCGAGTGATGGTGAATTAACAGTCTATATAGTGGGCTGATCAGGTATGTATTGTTTATTGTACTCAGCTGCCCTCCCACGTTTACATCGTCAGCTATAATTGTGTTTAATCCTCAATTATTGTTTGATCATGTATCCTGTTAAGAGTAAACGTGGTTCTTTTTATTACCAGCGACGATTTACGTCACGTAACACTGTGTATAACCGCTCAGCGTCTACCAAGAGACATGATGGGAAACGTCGAGGAGGTAATTCTGCTAAGCCCAACGATGAGCCCAAGATGTCAGCCCAACGCATACATGAGAATCAGTATGGGCCAGGTTATGTTATGGCCCATAATTCAGCTGTCTCGTCGTTCATCACTTATCCCAGCTTGGGCAAGTCGGACTCCAGCCGAAGCAGGTCCTATATCAAGTTGAAACGTCTCCGTTTTAAAGGGACTGTGAAGATCGAACGGGTACAATCGGAAGTGAACATGGACGGTTCCGCTCCGAAGGTCGAAGGAGTATTCTCGCTTGTTGTTGTTGTTGATCGTAAACCACACTTGGGTCCCTCTGGATGTCTGCATACATTCGACGAGCTATTCGGGGCAAGGATCAACAGTCATGGCAACCTCAGCATTGCCCCATCTCTGAAGGACCGATTCTACATAAGACACGTGTTCAAACGTGTACTGTCGGTTGAGAAGGACACGCTCATGGTGGATGTGGAAGGGTCCACATCACTCTCTAACAGGCGATACAACTGTTGGTCCACGTTTAAAGACCTTGAATGTGATTCATGCAAGGGAGTCTATGCCAACGTCAGCAAGAACGCCTTGTTAATTTATTATTGCTGGATGTCTGATACGCCTGCAAAGGCATCCTCATTTGTATCTTTCGATCTTGATTATATCGGTTAACTCAATAAATTGTGTTTATCTAAAGATGATTATCGTAATATGTGAAATGGAAAGATAACATTTATTTCAATGATTTGGCCTGAGAAGGCTGACAATTACTATTGATACATTCTTGGACCGTTGTCCGAACAAGCTCGTTCAACTGGCCCATTGACATTGTAATGTTGGACTCCGCTCTCTGGGCTCCCACGATGGAGGCAGACTCTCCAGGATCCAGGACGCTGGTCCCCAGCCTGTTTAGATGTCTGTATGGATGGAGTTCGTTATCCACCTCCGAGTCCGCATCTGACTGGGCCGTGCCTATTGTACTCCTGGAAGCCCATGATTCACCTGGCCTGATCTCAATTGGGCCACGTAACCCAAGTCTGGACATGGACGCACATCTGATGGGCTTCCTTTCCCATTTCCCATAACCCACATGGGAAAAGTCCACATCTTTGTCCGTGAACTGTTTGGACAAGATCTTCACTGTTGGTGCCCGGAACGGGATGTCGACGGAGTGTTTCGCTGTGGACAATTTCAGCTTCCCTTTGAACTTGGCGAAGTGGGTCCGCTGATGAACATTCGTATCGCACACCCTGTAGTACAACTTCCATGGAATTGGGTCCTTTAACGAGAAGAACGAAGCCGAGAAGTAGTGGAGATCTATGTTGCATCTGATCGGAAATGTCCATAACGCCTGTAACGACTCGTTGTCCGTCATCCTTTTGTCGTGGATCTCCACAATTACCGTCCCTGTGGCGTTGATCGGCACCTGTTGCCTATATTCAATGACGCAGTGGTCGATCTTCATGCAGCTACGGCTGAGCCTAGCTGTCAACTGAGACGCCGTGGAAGGGAATTGCAATATTATATCAGTTAGGTCATGGGAAAGCTGATACTCGTCCCGGTGAGATTCTATGTAATTGAAGGCACTTGGAGGATTAACTAACTGAGAATCCATATGAAGAAGAGAGGCCGCGCAGCGGAACCGATTGCTGAGGTTGAATCGGGAAGAAGATGAACAACCGATGAACAAGAAGAACAAGTTATGAACAGGTACTGTGATCTCGAAGAAGGTAAAGTGTTTCTTTTCTTTCTGTGTTTGAGAATGCTCGTTGATCTTAATCTTATGCTTACGAATATGGAAGACGAGAAAGTTGTTCAGGAATTATGTTTTTGAGAAAGAAAAGAGGGTTGATTAAGAGATAGTAGATTTCTGGAAATGAAAGAGGTTGTTTATGAACCCAGAGCGTCTGGGTTGATGGGTATTTAAATTGGGAAAGTGTTCATCAACCGATGGCATTATTGTAATAAGAGGGGGTACCCCAATTGGAGTCTCTCCAAACTTGCTCTATCAATTGGGGTCTGGGGTCTCATTTATACTAGGAGCCTCTATAGAACTCTCAATCTGGTTCGCACACGTGGCGGCCATCCGCTATAATATT
Gene Information
|
NCBI Accession
|
YP_004901693.1
|
|
Location
|
196-951 |
|
Gene Name
|
AV1 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGCCTAAGCGCGATCTGCCATGGCGCTCGATGGCGGGAACCTCAAAGGTTAGCCGCAATGCTAACTATTCTCCTCGTGCAGGTAGTGGGCCAAGAGGAAACAAGGCCTCTGAATGGGTGAACAGGCCAATGTACAGGAAGCCCAGGATCTACCGGACGCTGAGGACCCCCGATGTGCCCAGAGGCTGTGAAGGCCCATGTAAGGTCCAGTCCTATGAACAGCGCCATGACATCTCACATGTCGGGAAGGTCATGTGCATCTCGGATGTGACACGTGGTAATGGCATCACCCATCGTGTGGGTAAGCGTTTCTGTGTTAAGTCTGTGTATATCTTAGGGAAGATCTGGATGGACGAGAACATCAAGCTCAAGAACCACACGAACAGTGTCATGTTCTGGTTGGTCAGAGACCGTAGACCGTATGGCACGCCTATGGATTTTGGTCAGGTGTTTAACATGTTCGACAACGAGCCAAGCACTGCCACGGTGAAGAACGATCTCCGCGATCGTTACCAGGTTATGCACAAGTTCTATGGCAAGGTGACTGGTGGACAGTATGCCAGCAACGAGCAGGCTATAGTCAAGAGGTTCTGGAAGGTCAACAATTATGTGGTGTACAACCACCAAGAGGCTGGCAAGTACGAGAATCACACGGAGAACGCCCTGTTATTGTATATGGCATGTACTCATGCATCTAACCCTGTGTATGCAACTCTGAAGATTCGGATCTATTTTTACGATTCGATTATGAATTAA |
|
Protein Sequence
|
MPKRDLPWRSMAGTSKVSRNANYSPRAGSGPRGNKASEWVNRPMYRKPRIYRTLRTPDVPRGCEGPCKVQSYEQRHDISHVGKVMCISDVTRGNGITHRVGKRFCVKSVYILGKIWMDENIKLKNHTNSVMFWLVRDRRPYGTPMDFGQVFNMFDNEPSTATVKNDLRDRYQVMHKFYGKVTGGQYASNEQAIVKRFWKVNNYVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSIMN |
|
NCBI Accession
|
YP_004901694.1
|
|
Location
|
948-1346 |
|
Gene Name
|
AC3 |
|
Protein Name
|
replication enhancement protein |
|
Coding Region
|
ATGGATTCACGCACAGGGGAATTCATCACTGCACGTCAGGCGGAGAATGGCGTGTATATCTGGGAGATCGAAAATCCCCTGTATTTCAAGATGTACAGAGTAGAGGACCCGTTGTACACCAGAACGAGGGTGTATCACGTACAGATACGGTTCAATCACAACCTGAGGAGAGCGTTGCATCTCCACAAAGCCTACCTGAACTTCCAAGTCTGGACGACATCGATGACAGCTTCTGGGTCAACTTATTTAGCTAGATTTAGGCATTTAGTCAACATGTATTTAGATCAGTTAGGCGTCATTTCGTTAAACAATGTAATCAGAGCTGTTCGATTCGCGACAGACAGATCGTATGTAAATCATGTACTGGAAAATCATTCAATAAAATTCAAATTTTATTAA |
|
Protein Sequence
|
MDSRTGEFITARQAENGVYIWEIENPLYFKMYRVEDPLYTRTRVYHVQIRFNHNLRRALHLHKAYLNFQVWTTSMTASGSTYLARFRHLVNMYLDQLGVISLNNVIRAVRFATDRSYVNHVLENHSIKFKFY |
|
NCBI Accession
|
YP_004901695.1
|
|
Location
|
1093-1482 |
|
Gene Name
|
AC2 |
|
Protein Name
|
transactivator protein |
|
Coding Region
|
ATGCGATCTTCATCACCCTCACAGCCGCCCTCTATCAAGATAGCACACAGACAGGCCAAGAAAAGGGCGATCAGGAGGCGCAGGATTGATCTCCAGTGCGGGTGCTCCATCTACTTCCACATAGACTGTACGGGACATGGATTCACGCACAGGGGAATTCATCACTGCACGTCAGGCGGAGAATGGCGTGTATATCTGGGAGATCGAAAATCCCCTGTATTTCAAGATGTACAGAGTAGAGGACCCGTTGTACACCAGAACGAGGGTGTATCACGTACAGATACGGTTCAATCACAACCTGAGGAGAGCGTTGCATCTCCACAAAGCCTACCTGAACTTCCAAGTCTGGACGACATCGATGACAGCTTCTGGGTCAACTTATTTAGCTAG |
|
Protein Sequence
|
MRSSSPSQPPSIKIAHRQAKKRAIRRRRIDLQCGCSIYFHIDCTGHGFTHRGIHHCTSGGEWRVYLGDRKSPVFQDVQSRGPVVHQNEGVSRTDTVQSQPEESVASPQSLPELPSLDDIDDSFWVNLFS |
|
NCBI Accession
|
YP_004901696.1
|
|
Location
|
1394-2479 |
|
Gene Name
|
AC1 |
|
Protein Name
|
replication associated protein |
|
Coding Region
|
ATGCCATCGGTTAAGCGTTTTAAAGTCTCAGCCAAAAACTATTTCCTCACTTATCCACAGTGCTCTCTGTCAAAAGAAGAGGCACTTTCCCAATTACAAAACCTAGCAACTCCAGTTAACAAGAAGTTCATCAAAATTTGCAGAGAGCTTCATGAGAATGGGGAGCCTCATCTCCATGTGCTTGTACAATTCGAGGGAAAATACCAGTGCAAGAATAACAGATTCTTCGATCTGGTCTCCCCAACCAGGTCAGCACATTTCCATCCGAACATACAGGGAGCTAAATCTAGCTCCGACGTCAAGTCCTACATCGACAAGGACGGAGATACACTGGAATGGGGGGAATTCCAGATCGACGGTAGAAGTGCTAGAGGAGGCTGCCAATCGACTAACGACACGTATGCCAAGGCATTGAATGCCTCTTCTGTAGAAGAGGCGCTGCAAATAATCAAGGAAGAGCAGCCTCAACATTTCTTCCTTCAACATCACAATTTAGTTGCCAATGCTCATCGGATATTTCAGAAGGCTCCGGAACCGTGGGTACCTCCGTTTCAACTCTCCTCATTCACTAACGTTCCGGACGAGATGCAAGAATGGGCCGATGAGTATTTTGGTAGGGGTTCCGCTGCGCGGCCAGATAGACCATTAAGTCTCATAGTAGAAGGTGATTCAAGAACAGGGAAGACGATGTGGGCACGTGCGTTAGGCCCACATAACTATCTCAGTGGACACCTGGACTTCAATGGTCGAGTCTATTCAAACGCGGTGGAGTATAACGTCATTGATGACGTCGCACCGCAATATCTAAAGCTAAAGCACTGGAAAGAATTGCTGGGGGCCCAAAAAGATTGGCAGTCAAATTGCAAATACGGTAAGCCTGTTCAAATTAAAGGTGGAATCCCAGCAATCGTGCTTTGCAATCCTGGTGAGGGTTCCAGCTATAAAGAGTTCCTGGACAAAGAGGAAAATGCAGGACTAAGAAACTGGACTATCAAGAATGCGATCTTCATCACCCTCACAGCCGCCCTCTATCAAGATAGCACACAGACAGGCCAAGAAAAGGGCGATCAGGAGGCGCAGGATTGA |
|
Protein Sequence
|
MPSVKRFKVSAKNYFLTYPQCSLSKEEALSQLQNLATPVNKKFIKICRELHENGEPHLHVLVQFEGKYQCKNNRFFDLVSPTRSAHFHPNIQGAKSSSDVKSYIDKDGDTLEWGEFQIDGRSARGGCQSTNDTYAKALNASSVEEALQIIKEEQPQHFFLQHHNLVANAHRIFQKAPEPWVPPFQLSSFTNVPDEMQEWADEYFGRGSAARPDRPLSLIVEGDSRTGKTMWARALGPHNYLSGHLDFNGRVYSNAVEYNVIDDVAPQYLKLKHWKELLGAQKDWQSNCKYGKPVQIKGGIPAIVLCNPGEGSSYKEFLDKEENAGLRNWTIKNAIFITLTAALYQDSTQTGQEKGDQEAQD |
|
NCBI Accession
|
YP_004901697.1
|
|
Location
|
2065-2322 |
|
Gene Name
|
AC4 |
|
Protein Name
|
AC4 protein |
|
Coding Region
|
ATGGGGAGCCTCATCTCCATGTGCTTGTACAATTCGAGGGAAAATACCAGTGCAAGAATAACAGATTCTTCGATCTGGTCTCCCCAACCAGGTCAGCACATTTCCATCCGAACATACAGGGAGCTAAATCTAGCTCCGACGTCAAGTCCTACATCGACAAGGACGGAGATACACTGGAATGGGGGGAATTCCAGATCGACGGTAGAAGTGCTAGAGGAGGCTGCCAATCGACTAACGACACGTATGCCAAGGCATTGA |
|
Protein Sequence
|
MGSLISMCLYNSRENTSARITDSSIWSPQPGQHISIRTYRELNLAPTSSPTSTRTEIHWNGGNSRSTVEVLEEAANRLTTRMPRH |
|
NCBI Accession
|
YP_004901698.1
|
|
Location
|
404-1174 |
|
Gene Name
|
BV1 |
|
Protein Name
|
nuclear shutting protein |
|
Coding Region
|
ATGTATCCTGTTAAGAGTAAACGTGGTTCTTTTTATTACCAGCGACGATTTACGTCACGTAACACTGTGTATAACCGCTCAGCGTCTACCAAGAGACATGATGGGAAACGTCGAGGAGGTAATTCTGCTAAGCCCAACGATGAGCCCAAGATGTCAGCCCAACGCATACATGAGAATCAGTATGGGCCAGGTTATGTTATGGCCCATAATTCAGCTGTCTCGTCGTTCATCACTTATCCCAGCTTGGGCAAGTCGGACTCCAGCCGAAGCAGGTCCTATATCAAGTTGAAACGTCTCCGTTTTAAAGGGACTGTGAAGATCGAACGGGTACAATCGGAAGTGAACATGGACGGTTCCGCTCCGAAGGTCGAAGGAGTATTCTCGCTTGTTGTTGTTGTTGATCGTAAACCACACTTGGGTCCCTCTGGATGTCTGCATACATTCGACGAGCTATTCGGGGCAAGGATCAACAGTCATGGCAACCTCAGCATTGCCCCATCTCTGAAGGACCGATTCTACATAAGACACGTGTTCAAACGTGTACTGTCGGTTGAGAAGGACACGCTCATGGTGGATGTGGAAGGGTCCACATCACTCTCTAACAGGCGATACAACTGTTGGTCCACGTTTAAAGACCTTGAATGTGATTCATGCAAGGGAGTCTATGCCAACGTCAGCAAGAACGCCTTGTTAATTTATTATTGCTGGATGTCTGATACGCCTGCAAAGGCATCCTCATTTGTATCTTTCGATCTTGATTATATCGGTTAA |
|
Protein Sequence
|
MYPVKSKRGSFYYQRRFTSRNTVYNRSASTKRHDGKRRGGNSAKPNDEPKMSAQRIHENQYGPGYVMAHNSAVSSFITYPSLGKSDSSRSRSYIKLKRLRFKGTVKIERVQSEVNMDGSAPKVEGVFSLVVVVDRKPHLGPSGCLHTFDELFGARINSHGNLSIAPSLKDRFYIRHVFKRVLSVEKDTLMVDVEGSTSLSNRRYNCWSTFKDLECDSCKGVYANVSKNALLIYYCWMSDTPAKASSFVSFDLDYIG |
|
NCBI Accession
|
YP_004901699.1
|
|
Location
|
1236-2117 |
|
Gene Name
|
BC1 |
|
Protein Name
|
movement protein |
|
Coding Region
|
ATGGATTCTCAGTTAGTTAATCCTCCAAGTGCCTTCAATTACATAGAATCTCACCGGGACGAGTATCAGCTTTCCCATGACCTAACTGATATAATATTGCAATTCCCTTCCACGGCGTCTCAGTTGACAGCTAGGCTCAGCCGTAGCTGCATGAAGATCGACCACTGCGTCATTGAATATAGGCAACAGGTGCCGATCAACGCCACAGGGACGGTAATTGTGGAGATCCACGACAAAAGGATGACGGACAACGAGTCGTTACAGGCGTTATGGACATTTCCGATCAGATGCAACATAGATCTCCACTACTTCTCGGCTTCGTTCTTCTCGTTAAAGGACCCAATTCCATGGAAGTTGTACTACAGGGTGTGCGATACGAATGTTCATCAGCGGACCCACTTCGCCAAGTTCAAAGGGAAGCTGAAATTGTCCACAGCGAAACACTCCGTCGACATCCCGTTCCGGGCACCAACAGTGAAGATCTTGTCCAAACAGTTCACGGACAAAGATGTGGACTTTTCCCATGTGGGTTATGGGAAATGGGAAAGGAAGCCCATCAGATGTGCGTCCATGTCCAGACTTGGGTTACGTGGCCCAATTGAGATCAGGCCAGGTGAATCATGGGCTTCCAGGAGTACAATAGGCACGGCCCAGTCAGATGCGGACTCGGAGGTGGATAACGAACTCCATCCATACAGACATCTAAACAGGCTGGGGACCAGCGTCCTGGATCCTGGAGAGTCTGCCTCCATCGTGGGAGCCCAGAGAGCGGAGTCCAACATTACAATGTCAATGGGCCAGTTGAACGAGCTTGTTCGGACAACGGTCCAAGAATGTATCAATAGTAATTGTCAGCCTTCTCAGGCCAAATCATTGAAATAA |
|
Protein Sequence
|
MDSQLVNPPSAFNYIESHRDEYQLSHDLTDIILQFPSTASQLTARLSRSCMKIDHCVIEYRQQVPINATGTVIVEIHDKRMTDNESLQALWTFPIRCNIDLHYFSASFFSLKDPIPWKLYYRVCDTNVHQRTHFAKFKGKLKLSTAKHSVDIPFRAPTVKILSKQFTDKDVDFSHVGYGKWERKPIRCASMSRLGLRGPIEIRPGESWASRSTIGTAQSDADSEVDNELHPYRHLNRLGTSVLDPGESASIVGAQRAESNITMSMGQLNELVRTTVQECINSNCQPSQAKSLK |