Sida yellow leaf curl virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_002823465.1 |
| Isolate |
Brazil |
| Release date |
2018/8/25 |
| Submitter |
Castillo-Urquiza,G.P., Beserra,J.E. Jr., Bruckner,F.P., Lima,A.T., Varsani,A., Alfenas-Zerbini,P., Murilo Zerbini,F., Beserra,J.E.A. Jr., Lima,A.T.M., Zerbini,P.A., Zerbini,F.M. |
| Host |
|
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
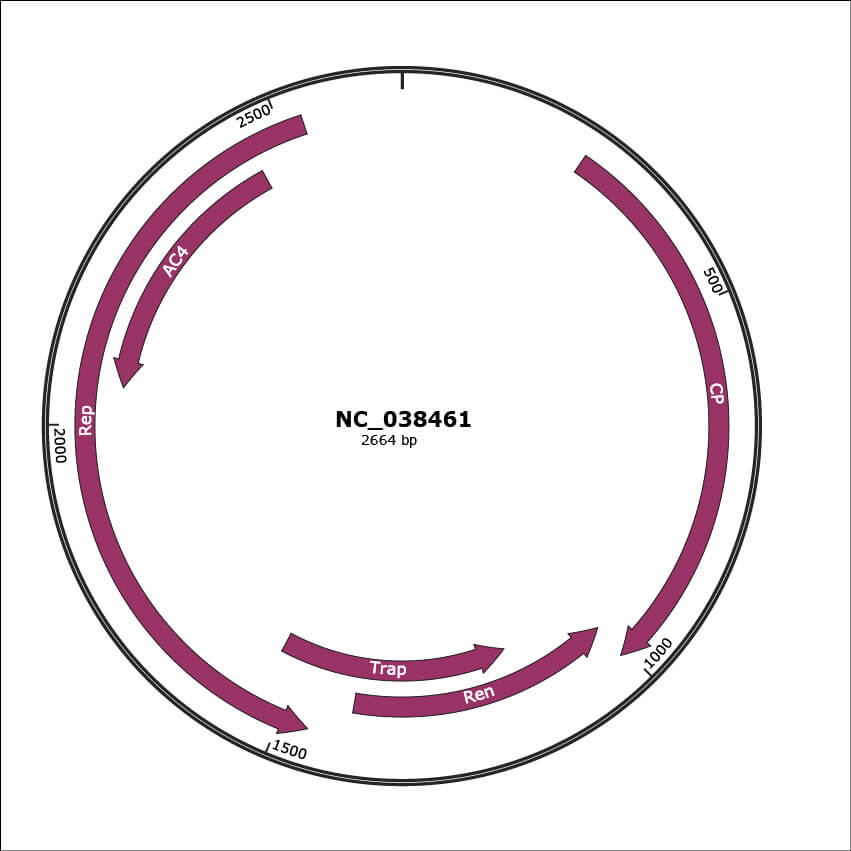
JBrowse
Genome
ACTGGATGGCCGCGCGATTTTTGGTGTCCCCCCCTACGTGGCGCTCTGGTGGCCGCTCAAATCCCCTCCCCCCCTGGTGTGGAGTCCCCCTTTGCCGCGCGCTTTCCTCCTTTAATTTGAATTAAAGGATTTAACCTTTGTCGGTCCAATTATAATGCGCCTGAGGAGCTTAGATATTTGTGTAAGACTTCGTTACTAAGTTTTATGAACCCTATAAAACTAAAGCAAGCATGACGTCAGTATGTAATTCGGAATGCCTAAGCGGGATCCCTCATGGCGCCAGGTGGCGGGAACCTCAAAGGTAAGCCGCACTTCCAATTTCTCACCTCGTGGAGGTGGAGGCCCAAAATTCAATAAGGCCTCTGAATGGGTCAACAGGCCTATGTATAGGAAGCCCAGGATATATCGAACGCTGAGAACGCCGGATGTTCCTAGAGGCTGTGAAGGGCCCTGTAAGGTCCAATCCTATGAGCAACGTCACGATATCTCCCATGTGGGGAAGGTGCTGTGCATATCTGATGTGACACGTGGAAACGGTATTACTCACCGTGTCGGTAAGCGTTTCTGTGTTAAGTCTGTGTATATTTTAGGGAAGATATGGATGGACGAGAATATCAAGCTCAAGAACCACACGAACAGTGTCATGTTCTGGTTGGTCAGGGACCGTAGACCGTATGGGACCCCGATGGACTTTGGCCAGGTGTTCAACATGTTCGATAACGAGCCCAGCACGGCAACCGTGAAGAACGATCTGCGTGATCGTTTCCAGGTGATGCACAAGTTCTATGCCAAGGTCACGGGTGGACAGTATGCCAGCAATGAGCAGGCGCTGGTCAAGCGCTTCTGGAAGGTCAACAATCATGTGGTGTACAATCATCAGGAAGCTGGGAAGTATGAGAATCACACGGAGAACGCTTTATTATTGTATATGGCATGTACTCATGCCTCTAACCCTGTGTATGCAACGCTTAAGATTCGAATCTATTTCTACGATTCGATCACGAATTAATAAAGCTTGAATTTTATTGAATGATTTTCCAGTACATATCTGACATATGATCTGTCAGTTGCGAAACGAACAGCTCTAATTACATTATTAACCGTAATTACTCCTAATATATCTAAATACAACATGACTAACTGTCTAAACCTAATCAAATAAGTCGTTCCAGAAGCTGTCAGGGAAGTCGTCCAGACTTGGAAGTTGAGATATGCCTTGTGGAGATCCAATGCTCTCCTGAGGTTGTGATTGAACCGGATCTGGATGTGGTACACTCTGGTCGTCGTGTACAGGAAGTCCTCTACGTGGTATATCTTGAAATACAGGGGATTTGTTATCTCCCAGGTATAGACGCCATTCTCTGCTTGAGGCACAGTGATGAGTTCCCCTGTGCGTGAATCCATGGTTGCTGCAACTGATGTGGACGTATATGGTGCACCCGCACTCGAGATCAATCCTTCTACGGCGAGTTCCTCTCTTCTTCGCCGCTCTGTGTTGAGGTTTGATACAGGGGGGAGTCGAGGAAGATGAATTTAGCATTGTGGAGTGTCCACGATTTTAGGGCTGCATTTTCCTCTTTGTCGAGGTAATCTTTATAACTGACTCCCTCCCCAGGATTGCAGAGCACGATTGATGGGATACCCCCTTTAATTTGAACAGGCTTGCCGTACTTGCAATTTGACTGCCAATCCTTTTGGGCCCCAATCAATTCCTTCCAGTGCTTTAGCTTTAGGTATTGCGGATTGACGTCATCAATGACGTTATATTCCACTTCATTTGAATAAACTTTGGAATTGAAGTCCAGATGGCCGCTCAGGTAATTATGTGGGCCTAATGCACGAGCCCACATCGTCTTACCAGTCCTTGACCCACCTTCTACTATCAAACTAACTGGCCTCAATGGCCGCGCAGCGGAACCTCTCCCAAAATACTCATCGGCCCACTCTTGCATCTCGTCTGGCACGTTAGTGAATGAGGAGAGGGGAAATGGAGGGACCCATGGCTCCGGAGACTTCATGAATATTCTGTCCAGGTTAGCCTTGACATTGTGATAGTTTACGAGGAAAGTCTTGGGGTCTCCGGCTTTGATAATGTCAAGAGCCTCTCCCGGAGTAGCTGCATTGACGGCGTTATGGTATACGTCGTCTTTATTCCCCTTTGTTCCCCCAGACACCTTGTACTGTCCGGATTCACAATAATCACCCTCTTTGGTGATGTAATTCTTGACGGCGTTGGTGTCTTTGGCTGCCTGAATATTGGGGTGAAATCCGGCAGACCGTCTGGGGTGAGTGAGGTCGAAAAATCTAACATCCTTGATGTTGGACTTGCCGGAGAGTTGGACAAGACAGTGAAGATGAGGGAAGCCGTCGGAGTGCTCCTCTCTGGCGACTCGTATGTATGTGGGTTTAACGACTGACCATGGAAGGGATTGAAGCATCTGAAGAGCTTCATCTTTGGGTATATCGCACTGGGGATATGTTAGGAATATGTTTTTGGCAGCTAGTCTGAACTTCTGAGGATTTCGTGGCATATTTGTAAATATTGATGAGGACACCAGGGATGGCTCTCAACTTCTGTGATATTTTCTGGTGTCCTGGTGTCCAATTTATACTAGAAAGCTCTAGGTTAGTACCAGGGGCAAAAGCGGCCATCCATATAATATT
Gene Information
|
NCBI Accession
|
YP_009506481.1
|
|
Location
|
254-1009 |
|
Gene Name
|
CP |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGCCTAAGCGGGATCCCTCATGGCGCCAGGTGGCGGGAACCTCAAAGGTAAGCCGCACTTCCAATTTCTCACCTCGTGGAGGTGGAGGCCCAAAATTCAATAAGGCCTCTGAATGGGTCAACAGGCCTATGTATAGGAAGCCCAGGATATATCGAACGCTGAGAACGCCGGATGTTCCTAGAGGCTGTGAAGGGCCCTGTAAGGTCCAATCCTATGAGCAACGTCACGATATCTCCCATGTGGGGAAGGTGCTGTGCATATCTGATGTGACACGTGGAAACGGTATTACTCACCGTGTCGGTAAGCGTTTCTGTGTTAAGTCTGTGTATATTTTAGGGAAGATATGGATGGACGAGAATATCAAGCTCAAGAACCACACGAACAGTGTCATGTTCTGGTTGGTCAGGGACCGTAGACCGTATGGGACCCCGATGGACTTTGGCCAGGTGTTCAACATGTTCGATAACGAGCCCAGCACGGCAACCGTGAAGAACGATCTGCGTGATCGTTTCCAGGTGATGCACAAGTTCTATGCCAAGGTCACGGGTGGACAGTATGCCAGCAATGAGCAGGCGCTGGTCAAGCGCTTCTGGAAGGTCAACAATCATGTGGTGTACAATCATCAGGAAGCTGGGAAGTATGAGAATCACACGGAGAACGCTTTATTATTGTATATGGCATGTACTCATGCCTCTAACCCTGTGTATGCAACGCTTAAGATTCGAATCTATTTCTACGATTCGATCACGAATTAA |
|
Protein Sequence
|
MPKRDPSWRQVAGTSKVSRTSNFSPRGGGGPKFNKASEWVNRPMYRKPRIYRTLRTPDVPRGCEGPCKVQSYEQRHDISHVGKVLCISDVTRGNGITHRVGKRFCVKSVYILGKIWMDENIKLKNHTNSVMFWLVRDRRPYGTPMDFGQVFNMFDNEPSTATVKNDLRDRFQVMHKFYAKVTGGQYASNEQALVKRFWKVNNHVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSITN |
|
NCBI Accession
|
YP_009506482.1
|
|
Location
|
1006-1404 |
|
Gene Name
|
Ren |
|
Protein Name
|
replication enhancer protein |
|
Coding Region
|
ATGGATTCACGCACAGGGGAACTCATCACTGTGCCTCAAGCAGAGAATGGCGTCTATACCTGGGAGATAACAAATCCCCTGTATTTCAAGATATACCACGTAGAGGACTTCCTGTACACGACGACCAGAGTGTACCACATCCAGATCCGGTTCAATCACAACCTCAGGAGAGCATTGGATCTCCACAAGGCATATCTCAACTTCCAAGTCTGGACGACTTCCCTGACAGCTTCTGGAACGACTTATTTGATTAGGTTTAGACAGTTAGTCATGTTGTATTTAGATATATTAGGAGTAATTACGGTTAATAATGTAATTAGAGCTGTTCGTTTCGCAACTGACAGATCATATGTCAGATATGTACTGGAAAATCATTCAATAAAATTCAAGCTTTATTAA |
|
Protein Sequence
|
MDSRTGELITVPQAENGVYTWEITNPLYFKIYHVEDFLYTTTRVYHIQIRFNHNLRRALDLHKAYLNFQVWTTSLTASGTTYLIRFRQLVMLYLDILGVITVNNVIRAVRFATDRSYVRYVLENHSIKFKLY |
|
NCBI Accession
|
YP_009506483.1
|
|
Location
|
1151-1540 |
|
Gene Name
|
Trap |
|
Protein Name
|
trans-activating protein |
|
Coding Region
|
ATGCTAAATTCATCTTCCTCGACTCCCCCCTGTATCAAACCTCAACACAGAGCGGCGAAGAAGAGAGGAACTCGCCGTAGAAGGATTGATCTCGAGTGCGGGTGCACCATATACGTCCACATCAGTTGCAGCAACCATGGATTCACGCACAGGGGAACTCATCACTGTGCCTCAAGCAGAGAATGGCGTCTATACCTGGGAGATAACAAATCCCCTGTATTTCAAGATATACCACGTAGAGGACTTCCTGTACACGACGACCAGAGTGTACCACATCCAGATCCGGTTCAATCACAACCTCAGGAGAGCATTGGATCTCCACAAGGCATATCTCAACTTCCAAGTCTGGACGACTTCCCTGACAGCTTCTGGAACGACTTATTTGATTAG |
|
Protein Sequence
|
MLNSSSSTPPCIKPQHRAAKKRGTRRRRIDLECGCTIYVHISCSNHGFTHRGTHHCASSREWRLYLGDNKSPVFQDIPRRGLPVHDDQSVPHPDPVQSQPQESIGSPQGISQLPSLDDFPDSFWNDLFD |
|
NCBI Accession
|
YP_009506484.1
|
|
Location
|
1461-2531 |
|
Gene Name
|
Rep |
|
Protein Name
|
replication-associated protein |
|
Coding Region
|
ATGCCACGAAATCCTCAGAAGTTCAGACTAGCTGCCAAAAACATATTCCTAACATATCCCCAGTGCGATATACCCAAAGATGAAGCTCTTCAGATGCTTCAATCCCTTCCATGGTCAGTCGTTAAACCCACATACATACGAGTCGCCAGAGAGGAGCACTCCGACGGCTTCCCTCATCTTCACTGTCTTGTCCAACTCTCCGGCAAGTCCAACATCAAGGATGTTAGATTTTTCGACCTCACTCACCCCAGACGGTCTGCCGGATTTCACCCCAATATTCAGGCAGCCAAAGACACCAACGCCGTCAAGAATTACATCACCAAAGAGGGTGATTATTGTGAATCCGGACAGTACAAGGTGTCTGGGGGAACAAAGGGGAATAAAGACGACGTATACCATAACGCCGTCAATGCAGCTACTCCGGGAGAGGCTCTTGACATTATCAAAGCCGGAGACCCCAAGACTTTCCTCGTAAACTATCACAATGTCAAGGCTAACCTGGACAGAATATTCATGAAGTCTCCGGAGCCATGGGTCCCTCCATTTCCCCTCTCCTCATTCACTAACGTGCCAGACGAGATGCAAGAGTGGGCCGATGAGTATTTTGGGAGAGGTTCCGCTGCGCGGCCATTGAGGCCAGTTAGTTTGATAGTAGAAGGTGGGTCAAGGACTGGTAAGACGATGTGGGCTCGTGCATTAGGCCCACATAATTACCTGAGCGGCCATCTGGACTTCAATTCCAAAGTTTATTCAAATGAAGTGGAATATAACGTCATTGATGACGTCAATCCGCAATACCTAAAGCTAAAGCACTGGAAGGAATTGATTGGGGCCCAAAAGGATTGGCAGTCAAATTGCAAGTACGGCAAGCCTGTTCAAATTAAAGGGGGTATCCCATCAATCGTGCTCTGCAATCCTGGGGAGGGAGTCAGTTATAAAGATTACCTCGACAAAGAGGAAAATGCAGCCCTAAAATCGTGGACACTCCACAATGCTAAATTCATCTTCCTCGACTCCCCCCTGTATCAAACCTCAACACAGAGCGGCGAAGAAGAGAGGAACTCGCCGTAG |
|
Protein Sequence
|
MPRNPQKFRLAAKNIFLTYPQCDIPKDEALQMLQSLPWSVVKPTYIRVAREEHSDGFPHLHCLVQLSGKSNIKDVRFFDLTHPRRSAGFHPNIQAAKDTNAVKNYITKEGDYCESGQYKVSGGTKGNKDDVYHNAVNAATPGEALDIIKAGDPKTFLVNYHNVKANLDRIFMKSPEPWVPPFPLSSFTNVPDEMQEWADEYFGRGSAARPLRPVSLIVEGGSRTGKTMWARALGPHNYLSGHLDFNSKVYSNEVEYNVIDDVNPQYLKLKHWKELIGAQKDWQSNCKYGKPVQIKGGIPSIVLCNPGEGVSYKDYLDKEENAALKSWTLHNAKFIFLDSPLYQTSTQSGEEERNSP |
|
NCBI Accession
|
YP_009506485.1
|
|
Location
|
2057-2452 |
|
Gene Name
|
AC4 |
|
Protein Name
|
AC4 |
|
Coding Region
|
ATGAAGCTCTTCAGATGCTTCAATCCCTTCCATGGTCAGTCGTTAAACCCACATACATACGAGTCGCCAGAGAGGAGCACTCCGACGGCTTCCCTCATCTTCACTGTCTTGTCCAACTCTCCGGCAAGTCCAACATCAAGGATGTTAGATTTTTCGACCTCACTCACCCCAGACGGTCTGCCGGATTTCACCCCAATATTCAGGCAGCCAAAGACACCAACGCCGTCAAGAATTACATCACCAAAGAGGGTGATTATTGTGAATCCGGACAGTACAAGGTGTCTGGGGGAACAAAGGGGAATAAAGACGACGTATACCATAACGCCGTCAATGCAGCTACTCCGGGAGAGGCTCTTGACATTATCAAAGCCGGAGACCCCAAGACTTTCCTCGTAA |
|
Protein Sequence
|
MKLFRCFNPFHGQSLNPHTYESPERSTPTASLIFTVLSNSPASPTSRMLDFSTSLTPDGLPDFTPIFRQPKTPTPSRITSPKRVIIVNPDSTRCLGEQRGIKTTYTITPSMQLLRERLLTLSKPETPRLSS |