Sida mosaic Sinaloa virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_000867305.1 |
| Isolate |
Mexico |
| Release date |
2015/2/13 |
| Submitter |
Mauricio-Castillo,J.A., Arguello-Astorga,G.R., Mendez-Lozano,J. |
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
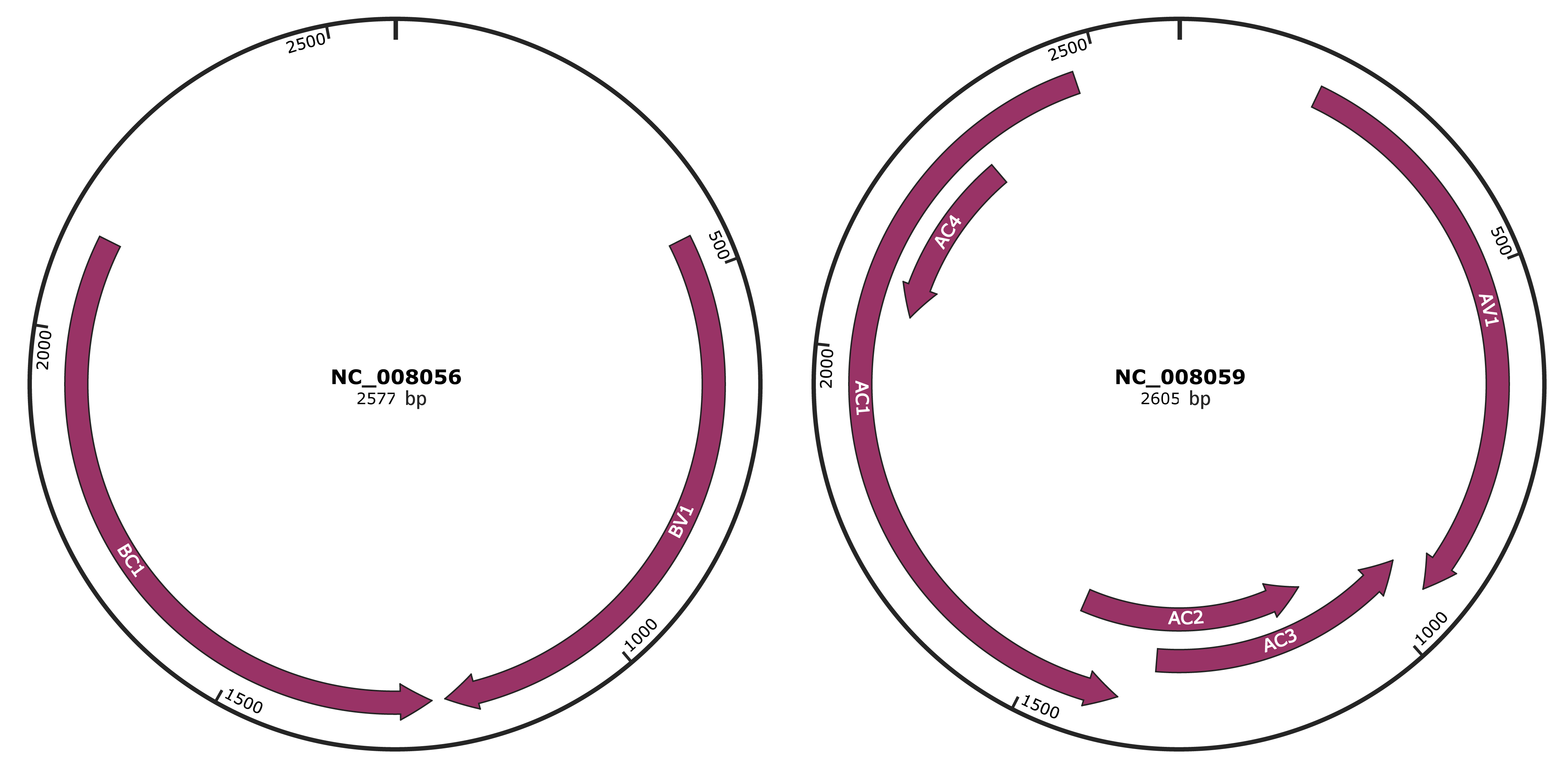
JBrowse
Genome
ACCGGATGGCCGCGCGATTTTCCCCCCTCGCGCGAAAGCTATCTACGTGCGCGCAGCTCATTGGTGCCGTACCCTCCAGCTGGTGTGCACTATCCCCCGCCCCCTCCGCTCCTGGTGCCCCCTCTACGTGGTGCCTCTCTATTGGCGCTCTCCGTTTATGATGGGCCATATTGTCAGTGAGTAACGTCCGATCTGGCTTTAATTCAAATTAAAGTTTTAGTCTTTTAAGTCCTGCGACTCGTTGTTTTTTTGACTACTGAGGCCCATCGTATAATATCGTTGACGTGGCCTGTTTTAGACCACGCTGCTGAGTCAAGTTAACTTCGAATTTGAACTAGCTTTGTCTATATCATGGGTGCTGCTTATGATTTATATTTTGAGGTGACTCAGCTGTCGTCCACGTTAGATTATGACCATTAATAACCTCTTTTGATCAAGCATTATCACTTGATAATGTACCCAGTTCGTTTTAAGCGTGGTGTCTCATTTGCTGGTCGACGTAATTATTTGCGGAATAATGTCTTTAAGCGTTCAACCATCTCTAGACGAGATGACGGTAAACGACGATCTGGTAATGCCAGCAAGCTTAATAGCGAGCCCAAGATGACAGCCCAACGTATACATGAGAATCAGTTTGGGCCTGAATTTGTAATGGCCCATAATTCAGCCTTGTCTACGTTTATCAGTTATCCATGTCTTGGTAAGACAGAACCGAGTCGAAGCAGGTCTTATATCAAGTTGAAACGCTTGCGTTTCAAGGGTACTGTTAAGATTGAACGTGTTCAGTCTGATATGAACATGGATGGTGCTATTCCGAAGGTCGAAGGAGTATTTTCTCTCGTTGTTGTTGTGGATCGTAAACCCCACTTGGGTGCGTCTGGTTGTCTGCACACCTTCGACGAACTATTCGGTGCCAGGATCCATAGCCATGGAAACCTTAGCATAACCCCTTCTCTGAAAGACCGTTATTACATAAGACACGTGTTCAAACGTGTATTGTCTGTGGAGAAAGATAGTGTGATGGTTGACGTGGAAGGTTCTACTTGTCTCTCTAATAGGCGTTTCAATTGTTGGTCTACGTTTAAGGATTTGGACCGTGATTCATGTAATGGTGTTTATGCTAACATCAGCAAGAACGCCCTATTAGTATATTACTGTTGGATGTCAGATGCTGTGTCTAAGGCGTCCAGCTTTGTATCGTTCGATCTTGATTATATTGGATAATTAATAAAAATATATTTTTATTCCAACGATTTGGGCCTAGAAGCCTTACAATTACTATTAATACACTCTTGGACCGTATTCCTAACTAATTCGTTCAACTGGCCCATTGACATTGTTATGTTCGATTCTGCTCTCCTTGCTCCCACTATAGAAGCAGACTCTCCCGGGTCTAATACGCTGGAGCCCAGCCTACTTAGGTGTCTGTATGGGTGCAATTCGTTTACTGCCTCTGAGTCCGCATCTGATTGACCAGTCCCTATAGCACTCCTGGAAGCCCATGACTCACCAGGCCTTATTTCAATTGGGCCGCGGTACCCAACTCTCGACATGGACGCACATCTGATGGGCTTCCTTTCCCATTTTCCGTAGTCCACATGGGAAAAGTCGACATCTTTGAAGGTGAACTGTTTGGATAGGATCTTTACTGTTGGTGCCCTGAACGGAATGTCCACGGAGTGTTTCGCCGTCGACAATTTTAATTTCCCTTTGAATTTCGCGAAATGGGTCCTCTGATGAACATTCGTATCGCAAACTCTGTAATAGAGTTTCCAAGGAATTGGGTCTTTGAGCGAAAAGAAAGATGCCGAGAAATAGTGGAGATCGATATTGCATCTGATCGGAAAAGTCCACGACGCTTGCAACGACTCGTTTTCCGTCATTCTCTTGTCATGGATCTCCACAATCACTGTCCCCGTCGCGTTAATTGGAACCTGCTGCCTGTATTCTATGACACAGTGGTCGATCTTCATGCAGCTCCGATTTAGCCTCGCCGTGAACTGTGACGCCGTCGAAGGAAACTGCAGGATTATCTCAGTCAGATCATGCGAAAGCTGATACTCGTCTCGCTGTGATTCTATATAATTAAAAGCATTTGGAGGAAATGCTAGCTGAGATTCCATCTGAAAAAGAAAGGCCGCGCAGCGGAACTGATAGCTGAAATTGAATTGTTGATTAAGAAATTAGGGTTTCTTTGGGAAAACACCCGAGCAACGACCCTTTATGATGAAAAGGTTTTCTGGGTTTCCCAGAAATATGCTCAATAATTGAAGAACAATTGTTTAATCTGTCTTTACTGTGTGAAATGTTTTTGAGAAAGGGGAGAATTCTGGTAAAGAATTCGAAGTTAATTATGTTATAGATCTGATAGTCTTTATATAAACACCCGCTTTTGCTGTTTGAGAATTGTCTGGGAAGTTCTATGAGTGTTAGTAATGGCATATCTGTAAATATGGGTGTTCCCCCGATAGCTCTCTCGCTCAAAACTCATATGAATTGGGGGAACTGGGGGAACATATATACTAAAAGTCTCTGTGTAGGATCTTGCAACACGTGGCGGCCATCCGCTATAATATT
ACCGATGGCCGCGCGATTTCCCCCCCTCGCGCGAATCGCCCACTTAATTCGGATAAAGTGCCCGCGCAGCGTGTCGTCCAATCATGTAACGCCTGACGAGTCTAGATATTTTAAACAACTTGGCCCTAAGTTGTAATATGTTCGTTATAATTAAAGTGGTCTTGGCCCATTATCTTTAATTCAAAATGCCTAAGCGCGATCTCCCATGGCGCTCGATCGCGGGAACTTCGAAGGTTAGTCGCAATGCTAATTATTCTCCTCGTGCAGGAAATGGGCCCAGAAATAATAAGGCCTCGGAATGGGTGAACAGGCCCATGTACAGGAAGCCCAGGATCTACCGGACTCTAAGAACGCCCGACGTGCCAAGAGGCTGTGAAGGCCCGTGTAAGGTCCAGTCCTTTGAACAGCGTCACGATATTTTACATACTGGGAGGGTAATGTGCATATCTGATGTGACACGTGGTAACGGTATCACCCATCGGGTTGGTAAGCGTTTCTGTGTTAAGTCTGTGTATATCCTTGGCAAGATATGGATGGATGAGAACATCAAGTTGAAGAACCACACGAACAGTGTTATGTTCTGGTTGGTCAGAGATCGTCGACCCTATGGCACGCCTATGGACTTCGGTCAGGTGTTCAACATGTTCGACAACGAGCCCAGCACTGCGACGGTGAAGAACGATCTCCGTGATCGTTATCAGGTCATGCACAAGTTCTATGGCAAGGTGACAGGTGGACAGTATGCCAGCAACGAGCAGGCTATAGTCAAACGCTTCTGGAAGGTCAACAATCATGTGGTGTACAATCATCAAGAGGCTGGCAAATATGAGAATCATACAGAGAACGCTCTGTTATTGTATATGGCATGTACACATGCCTCTAATCCTGTATATGCAACGCTTAAGATTCGAATCTATTTCTACGATTCGATCATGAATTAATAAATTTTTAATTTTATTGAATGAGATTCCAGTACATAACTTACGTACGACTTGTCTGTTGCGAAGCGAACAGCTCTAATTACATTGTTAATTGAAATGACGCCTAAGTCATCTAAATACATATTAACTAATCGTCTAAACCTAGCTAAATAGGTCGACCCAGAAGCTGTCATCGATGTCGTCCAGACTTGGAAGTTCAGGTAGGCTTTGTGGAGATCCAACGCTTTCCTCAGGTTGTGGTTGAATCGTATCTGTACGTGGTACACCTTGCTCCTCGTATGTATTGGCTCTTCTACATGGAACATCCTGAAATAGAGGGGATTTTCTATCTCCCAGATATACACGCCATTCTCTGCCTGATGTGCAGTGACGAATTCCCCTGTGCGTGAATCCATGTCCAATACAGCCTATGTGGAAGTAGATGGGGCACCCGCACTCTAAATCAATCCGCCGTCTCCTTATCGCCCTCCTCTTGGCTTGCCTGTGTGCTGTCTTGATAGAGGGCGGATGTGAGGGTGATGAAGATTGCATTCTTGATGGTCCAGTTCCTGAGGGAGGTGTTTTCCTCCTTGTTCAGGAAATCTTTATAGCTAGCACCCTCACCAGGATTGCAAAGCACGATTGATGGGATCCCACCTTTAATTTGAACTGGCTTTCCGTATTTGCAATTTGACTGCCAGTCCTTCTGGGCCCCCAGAAGTTCTTTCCAGTGCTTTAGCTTTAGATATTGCGGTGCGACGTCATCAATGACGTTATACTCCACTTCGTTTGAGTACACTCTTGGGTTGAAGTCCAGATGTCCACTAAGGTAATTGTGTGGGCCTAAGGCACGAGCCCACATCGTCTTCCCTGTCCTCGAGTCACCTTCTATGATGATACTTACTGGTCTCTCAGGCCGCGCAGCGGAACCCCTTCCAAAATATTCGTCCGCCCATGCTTGCATCTCGTCCGGAACTTTAGTGAACGAGGATAGTTGAAACGGAGGAACCCATCGTTCCGGAGCCTTTGCGAATATTTTCTCTAGGTTGGATCGTATGTTATGGTTTTGCAGCACAAAATCCTTTGGCTGTTCTTCTTTTAAAACCGCCATGGCAGCTTGAACAGATCCTGCATTCAACGCCTTGGCATATGAATCGTTAGCTGACTGCTGACCTCCCCTAGAAGATCTGCCGTCGATCTGGAATTCTCCCCAGTCAACTGTATCTCCGTCCTTCTCGATGTAGGACTTGACGTCGGAGCTGGATTTAGCTCCCTGTATGTTTGGATGGAAATGTGTTGACCTGGTTGGGGAGACCAGATCGAACAATCTGTTATTCGTGCAGTTGTATTTGCCTTCGAACTGGATGAGAACGTGGAGATGAGGCTCCCCATTCTTATGGAATTCCCTGCATACTCTGATGAATTTCTGGTTAACTGGTGTTTTTAGGTTTAGTAATTGGGAAAGTGCTTCTTCTTTGCTAAGAGAACACTCTGGATATGTGAGGAAATAGTTTCTGGCTTTTACTGAGAAAGAACCCTTTCGTGGCATATTTGTAAATATGGGTGTTCCCCCGAATAGCTCTCTCGCTCAAAACTCATATCCAATTGGGGGAACTGGGGGAACATATATACTAAAAGTCTCTGTGTAGGATCTTTCGACACGTGGCGGCCATCCGCTATATATT
Gene Information
|
NCBI Accession
|
YP_619876.1
|
|
Location
|
454-1224 |
|
Gene Name
|
BV1 |
|
Protein Name
|
nuclear shuttle protein |
|
Coding Region
|
ATGTACCCAGTTCGTTTTAAGCGTGGTGTCTCATTTGCTGGTCGACGTAATTATTTGCGGAATAATGTCTTTAAGCGTTCAACCATCTCTAGACGAGATGACGGTAAACGACGATCTGGTAATGCCAGCAAGCTTAATAGCGAGCCCAAGATGACAGCCCAACGTATACATGAGAATCAGTTTGGGCCTGAATTTGTAATGGCCCATAATTCAGCCTTGTCTACGTTTATCAGTTATCCATGTCTTGGTAAGACAGAACCGAGTCGAAGCAGGTCTTATATCAAGTTGAAACGCTTGCGTTTCAAGGGTACTGTTAAGATTGAACGTGTTCAGTCTGATATGAACATGGATGGTGCTATTCCGAAGGTCGAAGGAGTATTTTCTCTCGTTGTTGTTGTGGATCGTAAACCCCACTTGGGTGCGTCTGGTTGTCTGCACACCTTCGACGAACTATTCGGTGCCAGGATCCATAGCCATGGAAACCTTAGCATAACCCCTTCTCTGAAAGACCGTTATTACATAAGACACGTGTTCAAACGTGTATTGTCTGTGGAGAAAGATAGTGTGATGGTTGACGTGGAAGGTTCTACTTGTCTCTCTAATAGGCGTTTCAATTGTTGGTCTACGTTTAAGGATTTGGACCGTGATTCATGTAATGGTGTTTATGCTAACATCAGCAAGAACGCCCTATTAGTATATTACTGTTGGATGTCAGATGCTGTGTCTAAGGCGTCCAGCTTTGTATCGTTCGATCTTGATTATATTGGATAA |
|
Protein Sequence
|
MYPVRFKRGVSFAGRRNYLRNNVFKRSTISRRDDGKRRSGNASKLNSEPKMTAQRIHENQFGPEFVMAHNSALSTFISYPCLGKTEPSRSRSYIKLKRLRFKGTVKIERVQSDMNMDGAIPKVEGVFSLVVVVDRKPHLGASGCLHTFDELFGARIHSHGNLSITPSLKDRYYIRHVFKRVLSVEKDSVMVDVEGSTCLSNRRFNCWSTFKDLDRDSCNGVYANISKNALLVYYCWMSDAVSKASSFVSFDLDYIG |
|
NCBI Accession
|
YP_619877.1
|
|
Location
|
1242-2123 |
|
Gene Name
|
BC1 |
|
Protein Name
|
movement protein |
|
Coding Region
|
ATGGAATCTCAGCTAGCATTTCCTCCAAATGCTTTTAATTATATAGAATCACAGCGAGACGAGTATCAGCTTTCGCATGATCTGACTGAGATAATCCTGCAGTTTCCTTCGACGGCGTCACAGTTCACGGCGAGGCTAAATCGGAGCTGCATGAAGATCGACCACTGTGTCATAGAATACAGGCAGCAGGTTCCAATTAACGCGACGGGGACAGTGATTGTGGAGATCCATGACAAGAGAATGACGGAAAACGAGTCGTTGCAAGCGTCGTGGACTTTTCCGATCAGATGCAATATCGATCTCCACTATTTCTCGGCATCTTTCTTTTCGCTCAAAGACCCAATTCCTTGGAAACTCTATTACAGAGTTTGCGATACGAATGTTCATCAGAGGACCCATTTCGCGAAATTCAAAGGGAAATTAAAATTGTCGACGGCGAAACACTCCGTGGACATTCCGTTCAGGGCACCAACAGTAAAGATCCTATCCAAACAGTTCACCTTCAAAGATGTCGACTTTTCCCATGTGGACTACGGAAAATGGGAAAGGAAGCCCATCAGATGTGCGTCCATGTCGAGAGTTGGGTACCGCGGCCCAATTGAAATAAGGCCTGGTGAGTCATGGGCTTCCAGGAGTGCTATAGGGACTGGTCAATCAGATGCGGACTCAGAGGCAGTAAACGAATTGCACCCATACAGACACCTAAGTAGGCTGGGCTCCAGCGTATTAGACCCGGGAGAGTCTGCTTCTATAGTGGGAGCAAGGAGAGCAGAATCGAACATAACAATGTCAATGGGCCAGTTGAACGAATTAGTTAGGAATACGGTCCAAGAGTGTATTAATAGTAATTGTAAGGCTTCTAGGCCCAAATCGTTGGAATAA |
|
Protein Sequence
|
MESQLAFPPNAFNYIESQRDEYQLSHDLTEIILQFPSTASQFTARLNRSCMKIDHCVIEYRQQVPINATGTVIVEIHDKRMTENESLQASWTFPIRCNIDLHYFSASFFSLKDPIPWKLYYRVCDTNVHQRTHFAKFKGKLKLSTAKHSVDIPFRAPTVKILSKQFTFKDVDFSHVDYGKWERKPIRCASMSRVGYRGPIEIRPGESWASRSAIGTGQSDADSEAVNELHPYRHLSRLGSSVLDPGESASIVGARRAESNITMSMGQLNELVRNTVQECINSNCKASRPKSLE |
|
NCBI Accession
|
YP_619885.1
|
|
Location
|
186-941 |
|
Gene Name
|
AV1 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGCCTAAGCGCGATCTCCCATGGCGCTCGATCGCGGGAACTTCGAAGGTTAGTCGCAATGCTAATTATTCTCCTCGTGCAGGAAATGGGCCCAGAAATAATAAGGCCTCGGAATGGGTGAACAGGCCCATGTACAGGAAGCCCAGGATCTACCGGACTCTAAGAACGCCCGACGTGCCAAGAGGCTGTGAAGGCCCGTGTAAGGTCCAGTCCTTTGAACAGCGTCACGATATTTTACATACTGGGAGGGTAATGTGCATATCTGATGTGACACGTGGTAACGGTATCACCCATCGGGTTGGTAAGCGTTTCTGTGTTAAGTCTGTGTATATCCTTGGCAAGATATGGATGGATGAGAACATCAAGTTGAAGAACCACACGAACAGTGTTATGTTCTGGTTGGTCAGAGATCGTCGACCCTATGGCACGCCTATGGACTTCGGTCAGGTGTTCAACATGTTCGACAACGAGCCCAGCACTGCGACGGTGAAGAACGATCTCCGTGATCGTTATCAGGTCATGCACAAGTTCTATGGCAAGGTGACAGGTGGACAGTATGCCAGCAACGAGCAGGCTATAGTCAAACGCTTCTGGAAGGTCAACAATCATGTGGTGTACAATCATCAAGAGGCTGGCAAATATGAGAATCATACAGAGAACGCTCTGTTATTGTATATGGCATGTACACATGCCTCTAATCCTGTATATGCAACGCTTAAGATTCGAATCTATTTCTACGATTCGATCATGAATTAA |
|
Protein Sequence
|
MPKRDLPWRSIAGTSKVSRNANYSPRAGNGPRNNKASEWVNRPMYRKPRIYRTLRTPDVPRGCEGPCKVQSFEQRHDILHTGRVMCISDVTRGNGITHRVGKRFCVKSVYILGKIWMDENIKLKNHTNSVMFWLVRDRRPYGTPMDFGQVFNMFDNEPSTATVKNDLRDRYQVMHKFYGKVTGGQYASNEQAIVKRFWKVNNHVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSIMN |
|
NCBI Accession
|
YP_619886.1
|
|
Location
|
938-1336 |
|
Gene Name
|
AC3 |
|
Protein Name
|
replication enhancer protein |
|
Coding Region
|
ATGGATTCACGCACAGGGGAATTCGTCACTGCACATCAGGCAGAGAATGGCGTGTATATCTGGGAGATAGAAAATCCCCTCTATTTCAGGATGTTCCATGTAGAAGAGCCAATACATACGAGGAGCAAGGTGTACCACGTACAGATACGATTCAACCACAACCTGAGGAAAGCGTTGGATCTCCACAAAGCCTACCTGAACTTCCAAGTCTGGACGACATCGATGACAGCTTCTGGGTCGACCTATTTAGCTAGGTTTAGACGATTAGTTAATATGTATTTAGATGACTTAGGCGTCATTTCAATTAACAATGTAATTAGAGCTGTTCGCTTCGCAACAGACAAGTCGTACGTAAGTTATGTACTGGAATCTCATTCAATAAAATTAAAAATTTATTAA |
|
Protein Sequence
|
MDSRTGEFVTAHQAENGVYIWEIENPLYFRMFHVEEPIHTRSKVYHVQIRFNHNLRKALDLHKAYLNFQVWTTSMTASGSTYLARFRRLVNMYLDDLGVISINNVIRAVRFATDKSYVSYVLESHSIKLKIY |
|
NCBI Accession
|
YP_619887.1
|
|
Location
|
1083-1472 |
|
Gene Name
|
AC2 |
|
Protein Name
|
transactivator protein TrAP |
|
Coding Region
|
ATGCAATCTTCATCACCCTCACATCCGCCCTCTATCAAGACAGCACACAGGCAAGCCAAGAGGAGGGCGATAAGGAGACGGCGGATTGATTTAGAGTGCGGGTGCCCCATCTACTTCCACATAGGCTGTATTGGACATGGATTCACGCACAGGGGAATTCGTCACTGCACATCAGGCAGAGAATGGCGTGTATATCTGGGAGATAGAAAATCCCCTCTATTTCAGGATGTTCCATGTAGAAGAGCCAATACATACGAGGAGCAAGGTGTACCACGTACAGATACGATTCAACCACAACCTGAGGAAAGCGTTGGATCTCCACAAAGCCTACCTGAACTTCCAAGTCTGGACGACATCGATGACAGCTTCTGGGTCGACCTATTTAGCTAG |
|
Protein Sequence
|
MQSSSPSHPPSIKTAHRQAKRRAIRRRRIDLECGCPIYFHIGCIGHGFTHRGIRHCTSGREWRVYLGDRKSPLFQDVPCRRANTYEEQGVPRTDTIQPQPEESVGSPQSLPELPSLDDIDDSFWVDLFS |
|
NCBI Accession
|
YP_619888.1
|
|
Location
|
1384-2469 |
|
Gene Name
|
AC1 |
|
Protein Name
|
replication protein |
|
Coding Region
|
ATGCCACGAAAGGGTTCTTTCTCAGTAAAAGCCAGAAACTATTTCCTCACATATCCAGAGTGTTCTCTTAGCAAAGAAGAAGCACTTTCCCAATTACTAAACCTAAAAACACCAGTTAACCAGAAATTCATCAGAGTATGCAGGGAATTCCATAAGAATGGGGAGCCTCATCTCCACGTTCTCATCCAGTTCGAAGGCAAATACAACTGCACGAATAACAGATTGTTCGATCTGGTCTCCCCAACCAGGTCAACACATTTCCATCCAAACATACAGGGAGCTAAATCCAGCTCCGACGTCAAGTCCTACATCGAGAAGGACGGAGATACAGTTGACTGGGGAGAATTCCAGATCGACGGCAGATCTTCTAGGGGAGGTCAGCAGTCAGCTAACGATTCATATGCCAAGGCGTTGAATGCAGGATCTGTTCAAGCTGCCATGGCGGTTTTAAAAGAAGAACAGCCAAAGGATTTTGTGCTGCAAAACCATAACATACGATCCAACCTAGAGAAAATATTCGCAAAGGCTCCGGAACGATGGGTTCCTCCGTTTCAACTATCCTCGTTCACTAAAGTTCCGGACGAGATGCAAGCATGGGCGGACGAATATTTTGGAAGGGGTTCCGCTGCGCGGCCTGAGAGACCAGTAAGTATCATCATAGAAGGTGACTCGAGGACAGGGAAGACGATGTGGGCTCGTGCCTTAGGCCCACACAATTACCTTAGTGGACATCTGGACTTCAACCCAAGAGTGTACTCAAACGAAGTGGAGTATAACGTCATTGATGACGTCGCACCGCAATATCTAAAGCTAAAGCACTGGAAAGAACTTCTGGGGGCCCAGAAGGACTGGCAGTCAAATTGCAAATACGGAAAGCCAGTTCAAATTAAAGGTGGGATCCCATCAATCGTGCTTTGCAATCCTGGTGAGGGTGCTAGCTATAAAGATTTCCTGAACAAGGAGGAAAACACCTCCCTCAGGAACTGGACCATCAAGAATGCAATCTTCATCACCCTCACATCCGCCCTCTATCAAGACAGCACACAGGCAAGCCAAGAGGAGGGCGATAAGGAGACGGCGGATTGA |
|
Protein Sequence
|
MPRKGSFSVKARNYFLTYPECSLSKEEALSQLLNLKTPVNQKFIRVCREFHKNGEPHLHVLIQFEGKYNCTNNRLFDLVSPTRSTHFHPNIQGAKSSSDVKSYIEKDGDTVDWGEFQIDGRSSRGGQQSANDSYAKALNAGSVQAAMAVLKEEQPKDFVLQNHNIRSNLEKIFAKAPERWVPPFQLSSFTKVPDEMQAWADEYFGRGSAARPERPVSIIIEGDSRTGKTMWARALGPHNYLSGHLDFNPRVYSNEVEYNVIDDVAPQYLKLKHWKELLGAQKDWQSNCKYGKPVQIKGGIPSIVLCNPGEGASYKDFLNKEENTSLRNWTIKNAIFITLTSALYQDSTQASQEEGDKETAD |
|
NCBI Accession
|
YP_619889.1
|
|
Location
|
2055-2312 |
|
Gene Name
|
AC4 |
|
Protein Name
|
AC4 |
|
Coding Region
|
ATGGGGAGCCTCATCTCCACGTTCTCATCCAGTTCGAAGGCAAATACAACTGCACGAATAACAGATTGTTCGATCTGGTCTCCCCAACCAGGTCAACACATTTCCATCCAAACATACAGGGAGCTAAATCCAGCTCCGACGTCAAGTCCTACATCGAGAAGGACGGAGATACAGTTGACTGGGGAGAATTCCAGATCGACGGCAGATCTTCTAGGGGAGGTCAGCAGTCAGCTAACGATTCATATGCCAAGGCGTTGA |
|
Protein Sequence
|
MGSLISTFSSSSKANTTARITDCSIWSPQPGQHISIQTYRELNPAPTSSPTSRRTEIQLTGENSRSTADLLGEVSSQLTIHMPRR |