Sida mosaic Alagoas virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_000895795.1 |
| Isolate |
Brazil |
| Release date |
2015/2/22 |
| Submitter |
Wyant,P.S., Strohmeier,S., Schafer,B., Krenz,B., Assuncao,I.P., Lima,G.S., Jeske,H., Schaefer,B., Lima,G.S.A. |
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
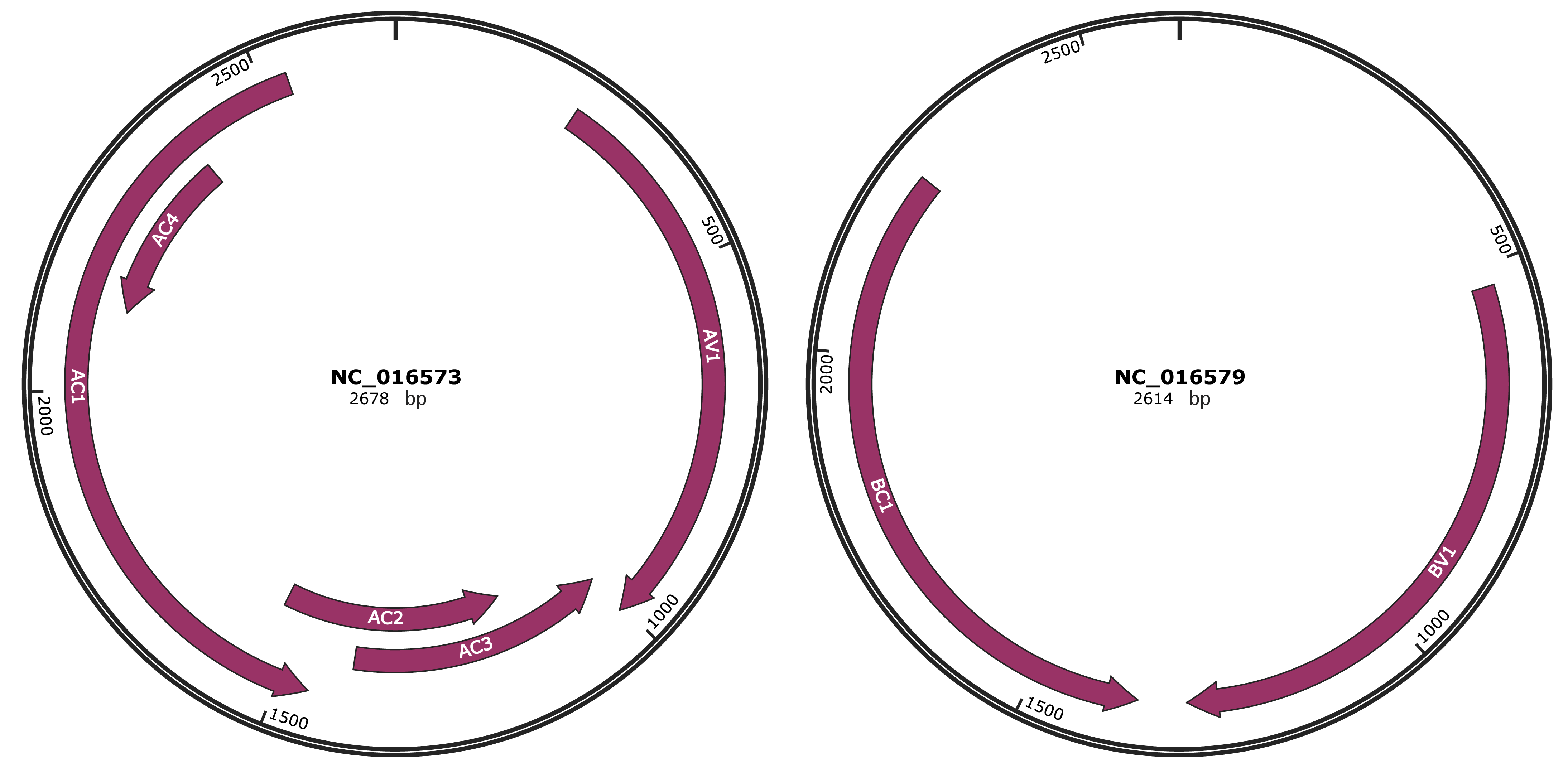
JBrowse
Genome
ACCGGATGGCCGCGCGATTTTTTTATCCCCCCACGTGGCGCTCTCCTGGTCGCGCGATCAAATCCCCTGTCCCCCCCGCGCGCTCCCCCCGCGCGCTCGTTTCCTTTAATTTTAATTAAAGCAGCTAACTTTGTACTGAGCCAATCATATTGCGTCTGACGAGTCTAGATATTTGGGAAAGACTTGGGCCCTAAGTTGTTGATTAACGGCTATAAATTAAAGGAAGACTGGTCACAGTCTTTAATTCAAGATGCCTAAGCGGGACGCCCCTTGGCGCCTGATGGCGGGAACTTCGAAGGTTAGCCGTTCATCTAATACCGGCCCTCGTGGAGGTTCTGGGCCTAAGTTCAATAAGGCCAATGAGTGGGTCAACAGGCCAATGTACAGGAAGCCCAGGATATACCGGGCCTTCAGAACTCCAGATGTCCCTCGAGGGTGTGAAGGGCCTTGCAAGGTCCAGTCATACGAACAGCGACACGACATCTCACATGTCGGCAAGGTCATGTGTATATCTGATGTCACTCGAGGTAACGGTATTACCCACCGTGTCGGTAAGCGCTTCTGTGTTAAGTCTGTGTATATTTTAGGTAAGATATGGATGGACGAGAATATCAAGCTCAAGAACCACACGAACAGTTGCATGTTCTGGCTAGTCAGGGACCGTAGACCGTATGGTACACCCATGGACTTTGGTCAGGTGTTCAACATGTTCGACAACGAGCCCAGTACTGCAACCGTGAAGAACGACCTCCGCGATCGGTTCCAGGTCATGCACAAGTTCTATGCCAAGGTTACGGGTGGTCAGTATGCCAGTAACGAGCAGGCTCTGGTCAAGAGGTTCTGGAAGGTCAACAATCATGTGGTTTACAATCACCAAGAAGCCGGGAAGTACGAGAATCATACGGAGAACGCACTACTATTGTATATGGCATGTACCCATGCCTCTAACCCTGTGTATGCAACGCTGAAGATTCGGATCTATTTTTATGATTCGATCACAAATTAATAAAATTTGAATTTTATTGAATGATTTTCCAGTACATGATTGACATACGACCTATCTGTTGCGAAACGAACAGCTCTAATTACATTATTAAGCGCAATTACACCTAATTGCTCTAAGTACAGCATGACTAAATGTCTAAACCTAGTCAAATAGGTCGTTCCAGAAGCTGTCAGAGAAGTCGTCCAGACTTGGAAGTTCAGGAATGCCTTGTGGAGACCCAATGCTCTCCTGAGGTTGTGGTTGAACCTTATCTGTACGTGGTACACTCTGGTCGTTGTGTACAACAGGTCCTCTACTCGGTAAATCTTGAAATACAGGGGATTTGTTATCTCCCAGATATAGACGCCATTCTCTGCCTGATGCGCAGTGATGTGTTCCCCGGTGCGTGAATCCATTGTTGCTGCAGTTGATGTGGACGTACAAGGAGCAGCCGCAGTCAAGGTCGACTCGTCTACGTCGGGTTGCTCTGCTCTTCGCAATCCTGTGCCGTGGTTTGATAGAGGGGGGAGTCGAGGAAGATGAATTTAGCATTGTGGAGTGTCCAGGCCCTCAATGATGCATTTTCCTCCTTGTCGAGATACTCTTTATAACTGGCCCCCTCTCCAGGATTGCAGAGCACGATTGATGGGATACCCCCTTTAATCTTTCTTGGCTTGCCGTACTTGCAATTTGACTGCCACTCTTTTTGAGCACCAATCAATTCCTTCCAGTGCTTTAGCTTTAGGTAATGGGGTGTGACATCATCGATGACGTTATACTCAGCTTCGTCTGAGTAGACCCGGGAATTGAAATCTAGATGGCCGCTTAAGTAATTATGTGGGCCTAATGCACGAGCCCACATCGTCTTGCCCGTTCGAGAGTCACCCTCAACAATTAAACTTATGGGCCTCTCTGGCCGCGCAGCGGAACCTCTCCCAAAATAATCATCGGCCCACTCTTGCATCTCGTCTGGCACGTTAGTGAAGGAGGAGAGGTGAAACGGAGGAGCCCACGGTTCCGGAGCCTTTTGAAAAATGCGAGAAGCATTTGCTACCAAGTTATGATGTTGAAGGAAGAAGTGCTGTGGTTGCTCTTCTTTGATTATTTGTAATGCTTCTTCTGCTGAACCGGCGTTCAATGCCTTGGCATATGTGTCGTTAACCGTCTGGCAACCTCCTCTAGCACTTCTTCCGTCGATTTGGAATTCTCCCCATTCGATGGTGTCTCCGTCCTTCTCGACGTAGGACTTGACGTCGGACGATGATTTAGCTCCCTGAACGTTCGGATGGAAATGTGCTGACCTGGTTGGGGAGACCAGATCGAAGAATCTGTTATTTTTGCATTGGAATTTCCCCTCGAACTGGATAAGGACGTGGAGATGAGGCTGCCCATCTTCGTGAAGTTCTCTTGCGATTTTGATGAACTTCTTATTAGTTGGGATCGATAGGTTTAATAATTGGGAAAGTGCTTCTTCTTTAGTAAGAGAGCACTGTGGATAAGTAAGAAAATAATTTTTGGCATTTATTTTAAATGGCTTTGGTGGTGGCATTCTTGTAAATAAGGCTGGACACCAATTGGAGTCTCTCAACTCTTTGCTATGCAATCGGTGTCTGGAGTCTCATTTATAGTTAGAAACCCCTTCAATAGAACTTTAGATCCTGTTCCGCACACCTGGCGCCATCCGTATAATATT
ACCGGATGGCCGCGCGATTTTCCCCCCCCTACGTGGCGCTCTGGTGCCCGCTCGATTCCCTCCCCCCCCTACGTGGCGCTCTGGTGCCCGCTCGATTCCCTCCCCCTCTCACGTGTCGCTCTGTTCTCGCGCGTGTCATTAAACTGTTTTTAACAATTTAGCGCTTTTTTGGAGTCCGCGAATTGAGCTAAGCGCATTTTTTGAGTTCCGGAACGGTACAACCATAATAAATGCTTTAATTCAAATTAAAGTTGTCTGACCCCTTTTCGTCAAATCAGTTCGCGCTCGTTGTACTTCATTGTTTTTCTCGCGATTTGTTCTAGACCGTTTGATAACATTATTGTGCAATACTTTATTGCATCATTGAAGCAGTATTGAGTGGTGCGAGAAAAATATAGACCCACATTACTACATGTTCTACGTGGACCAGTTAAGTGTGTTGTATGCATGTATGTTAATTTAGGAATTGTATATTTAAAGTATGTGGGTCTTGAGTAGGATATCTCGTTCGACCGACTAATTTAATATGTATGCAGCCAAGTTTAGACGTGGTCAATCTAGTAATTACCGTCGTAATTACAAAAGGAAGAACGTCTTTAAGACTGTTTATGGTGTTAAGCGGTACGATGGGAAACGTGGATTTAATATTCAGAACAAGGCCCATGATGATAGTAAGATGTCGGCCCAGCGTATTCACGAGAACCAGTTTGGGCCAGAGTTTGTAATGGCCCACAACACAGCCATTTCAACGTTCATCACATTTCCAAGCCTATGTAAGACGGAGCCGAACCGAAGCAGGTCCTATATTAAGTTGAAACGACTTCGTTTTAAGGGTACTGTCAAGATTGAACGGGTTCACACTGACGTCATTATGGATGGATCAAGCCCAAAAACCGAAGGAGTATTTTCATTGGTCGTTGTGGTGGACCGGAAACCTCATTTGGGTCCATCTGGATGTCTCCATACGTTTGATGAGCTCTTTGGGGCCAGGATCCACAGTCATGGTAATTTAGCCATAACCCCGTCCCTTAAAGACCGTTTCTATATACGACATGTGCACAAACGTGTTCTGTCTGTGGAGAAGGACACCCTAATGGTTGATATTGAAGGGACGACATCACTCTCTAACAGGCGTTTTAACTGTTGGTCCTCTTTTAAGGATGTAGACCGGGATTCATGTAACGGTGTTTATGCAAACATAAGCAAGAACGCCCTGTTAGTTTATTACTGTTGGATGTCTGACTCTTCGTCCAAGGCATCGACATTTGTATCATATGATCTTGACTATATTGGTTAATGATAATATTGTTTTACAATACATGATAATGGCTCTTTGAGCCTTAATTAACATAATAATGGATTTAATTTAAAGGTTTGGGCTGGGGAGCTATACAATTTGTCTTGATACATTCCTGGACCGCAGTCCTGACTAGGTCGTTTAATTGGGCCTCTGACATGGTGATATGCGATTCTGTCCTTCTTGCAGCAACAATTGAGGCTGAGTCTCCTGGGTCTAACAAGCTGGTCCCCAGTCTGTGTAGGCCTCGATATGGGAGTGCTGCGTTCTCTATTTCAGAATCGGCACTGGATTGTCCGATCCCTATGGTACTCTTTGCAGCCCAGGTCTCTCCTGGATCAATGGATAGTGGGCTAGGAAGCCCATGTGTTGTTGTTGAGGTGGATCGGATCAATTTCCTTTCCCATTTGCCATAGCCCACATGGCAGAAGTCGATATCTCTGTCTGTAAACTGTTTAGACAATATTTTGACTGTCGGTGCTCGGAAAGGAATATCCACGGAATGTTTCGCCGTTGAAAGCTTCAGCTTTCCCTTGAACTTCGCGAAGTGGGTCCTCTGATGAACATTTGTGTCGCTGACCCTGTAGTACAGCTTCCAAGGGATTGGGTCCTTCAGGGAGAAGAAGGACGAGGAGAAATAGTGGAGATCTATGTTACATCTGATCGGAAAAGTCCACGACGCCTGTAAGGATTCGTTTTCAGTCATTCTCTTGTCGTGGATCTCCACTATGACGGAACCTGCGGCGTTTATCGGTACTTGTTGTCTGTATTCGATGACGCAATGGTCGATCTTCATACAGCTACGACTGAGCCTGGCACTTATCTGAGCCGCCGCAGAAGGAAACTGTAGTACGATCTCAGTTAGGTCATGAGAAAGTTGATACTCGTCACGCTGAGACTCTATATAATTAAATGCATTTGGCGGATTAACTAACTGAGATTCCATTTGAACTAATTAATCTGAAAGAGAAGGCCGCGCAGCGGAATGTTCAAGTGATTTGAAAAGGCGATTATCGAACGGGGAAGACGATCTGAGTTAGGGTTTCGTCAGTTTCTGGACGGATTAAGAGGAGATATGAGATGAAATGGGTGTTATCTACAGGAGTGTAGAGGTGTTGTTTGAGTCTATACTTACTGGGCTGGGAGTAATTATATAGCCCATAAAAAGAGTGGCATTCTTGTAAATAAGGCTGGACACCAATTGGAGTCTCTCAACTCTTTTGCTATGCAATCGGTGTCTGGAGTCTCATTTATAGTAGAACCCTCAATAGAACTTTAGATCCTGTTCGCACACCTGGCGGCCATCCGTATAATATT
Gene Information
|
NCBI Accession
|
YP_004958219.1
|
|
Location
|
251-1006 |
|
Gene Name
|
AV1 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGCCTAAGCGGGACGCCCCTTGGCGCCTGATGGCGGGAACTTCGAAGGTTAGCCGTTCATCTAATACCGGCCCTCGTGGAGGTTCTGGGCCTAAGTTCAATAAGGCCAATGAGTGGGTCAACAGGCCAATGTACAGGAAGCCCAGGATATACCGGGCCTTCAGAACTCCAGATGTCCCTCGAGGGTGTGAAGGGCCTTGCAAGGTCCAGTCATACGAACAGCGACACGACATCTCACATGTCGGCAAGGTCATGTGTATATCTGATGTCACTCGAGGTAACGGTATTACCCACCGTGTCGGTAAGCGCTTCTGTGTTAAGTCTGTGTATATTTTAGGTAAGATATGGATGGACGAGAATATCAAGCTCAAGAACCACACGAACAGTTGCATGTTCTGGCTAGTCAGGGACCGTAGACCGTATGGTACACCCATGGACTTTGGTCAGGTGTTCAACATGTTCGACAACGAGCCCAGTACTGCAACCGTGAAGAACGACCTCCGCGATCGGTTCCAGGTCATGCACAAGTTCTATGCCAAGGTTACGGGTGGTCAGTATGCCAGTAACGAGCAGGCTCTGGTCAAGAGGTTCTGGAAGGTCAACAATCATGTGGTTTACAATCACCAAGAAGCCGGGAAGTACGAGAATCATACGGAGAACGCACTACTATTGTATATGGCATGTACCCATGCCTCTAACCCTGTGTATGCAACGCTGAAGATTCGGATCTATTTTTATGATTCGATCACAAATTAA |
|
Protein Sequence
|
MPKRDAPWRLMAGTSKVSRSSNTGPRGGSGPKFNKANEWVNRPMYRKPRIYRAFRTPDVPRGCEGPCKVQSYEQRHDISHVGKVMCISDVTRGNGITHRVGKRFCVKSVYILGKIWMDENIKLKNHTNSCMFWLVRDRRPYGTPMDFGQVFNMFDNEPSTATVKNDLRDRFQVMHKFYAKVTGGQYASNEQALVKRFWKVNNHVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSITN |
|
NCBI Accession
|
YP_004958220.1
|
|
Location
|
1003-1401 |
|
Gene Name
|
AC3 |
|
Protein Name
|
replication enhancer |
|
Coding Region
|
ATGGATTCACGCACCGGGGAACACATCACTGCGCATCAGGCAGAGAATGGCGTCTATATCTGGGAGATAACAAATCCCCTGTATTTCAAGATTTACCGAGTAGAGGACCTGTTGTACACAACGACCAGAGTGTACCACGTACAGATAAGGTTCAACCACAACCTCAGGAGAGCATTGGGTCTCCACAAGGCATTCCTGAACTTCCAAGTCTGGACGACTTCTCTGACAGCTTCTGGAACGACCTATTTGACTAGGTTTAGACATTTAGTCATGCTGTACTTAGAGCAATTAGGTGTAATTGCGCTTAATAATGTAATTAGAGCTGTTCGTTTCGCAACAGATAGGTCGTATGTCAATCATGTACTGGAAAATCATTCAATAAAATTCAAATTTTATTAA |
|
Protein Sequence
|
MDSRTGEHITAHQAENGVYIWEITNPLYFKIYRVEDLLYTTTRVYHVQIRFNHNLRRALGLHKAFLNFQVWTTSLTASGTTYLTRFRHLVMLYLEQLGVIALNNVIRAVRFATDRSYVNHVLENHSIKFKFY |
|
NCBI Accession
|
YP_004958221.1
|
|
Location
|
1148-1537 |
|
Gene Name
|
AC2 |
|
Protein Name
|
transcriptional regulator |
|
Coding Region
|
ATGCTAAATTCATCTTCCTCGACTCCCCCCTCTATCAAACCACGGCACAGGATTGCGAAGAGCAGAGCAACCCGACGTAGACGAGTCGACCTTGACTGCGGCTGCTCCTTGTACGTCCACATCAACTGCAGCAACAATGGATTCACGCACCGGGGAACACATCACTGCGCATCAGGCAGAGAATGGCGTCTATATCTGGGAGATAACAAATCCCCTGTATTTCAAGATTTACCGAGTAGAGGACCTGTTGTACACAACGACCAGAGTGTACCACGTACAGATAAGGTTCAACCACAACCTCAGGAGAGCATTGGGTCTCCACAAGGCATTCCTGAACTTCCAAGTCTGGACGACTTCTCTGACAGCTTCTGGAACGACCTATTTGACTAG |
|
Protein Sequence
|
MLNSSSSTPPSIKPRHRIAKSRATRRRRVDLDCGCSLYVHINCSNNGFTHRGTHHCASGREWRLYLGDNKSPVFQDLPSRGPVVHNDQSVPRTDKVQPQPQESIGSPQGIPELPSLDDFSDSFWNDLFD |
|
NCBI Accession
|
YP_004958222.1
|
|
Location
|
1458-2534 |
|
Gene Name
|
AC1 |
|
Protein Name
|
replication associated protein |
|
Coding Region
|
ATGCCACCACCAAAGCCATTTAAAATAAATGCCAAAAATTATTTTCTTACTTATCCACAGTGCTCTCTTACTAAAGAAGAAGCACTTTCCCAATTATTAAACCTATCGATCCCAACTAATAAGAAGTTCATCAAAATCGCAAGAGAACTTCACGAAGATGGGCAGCCTCATCTCCACGTCCTTATCCAGTTCGAGGGGAAATTCCAATGCAAAAATAACAGATTCTTCGATCTGGTCTCCCCAACCAGGTCAGCACATTTCCATCCGAACGTTCAGGGAGCTAAATCATCGTCCGACGTCAAGTCCTACGTCGAGAAGGACGGAGACACCATCGAATGGGGAGAATTCCAAATCGACGGAAGAAGTGCTAGAGGAGGTTGCCAGACGGTTAACGACACATATGCCAAGGCATTGAACGCCGGTTCAGCAGAAGAAGCATTACAAATAATCAAAGAAGAGCAACCACAGCACTTCTTCCTTCAACATCATAACTTGGTAGCAAATGCTTCTCGCATTTTTCAAAAGGCTCCGGAACCGTGGGCTCCTCCGTTTCACCTCTCCTCCTTCACTAACGTGCCAGACGAGATGCAAGAGTGGGCCGATGATTATTTTGGGAGAGGTTCCGCTGCGCGGCCAGAGAGGCCCATAAGTTTAATTGTTGAGGGTGACTCTCGAACGGGCAAGACGATGTGGGCTCGTGCATTAGGCCCACATAATTACTTAAGCGGCCATCTAGATTTCAATTCCCGGGTCTACTCAGACGAAGCTGAGTATAACGTCATCGATGATGTCACACCCCATTACCTAAAGCTAAAGCACTGGAAGGAATTGATTGGTGCTCAAAAAGAGTGGCAGTCAAATTGCAAGTACGGCAAGCCAAGAAAGATTAAAGGGGGTATCCCATCAATCGTGCTCTGCAATCCTGGAGAGGGGGCCAGTTATAAAGAGTATCTCGACAAGGAGGAAAATGCATCATTGAGGGCCTGGACACTCCACAATGCTAAATTCATCTTCCTCGACTCCCCCCTCTATCAAACCACGGCACAGGATTGCGAAGAGCAGAGCAACCCGACGTAG |
|
Protein Sequence
|
MPPPKPFKINAKNYFLTYPQCSLTKEEALSQLLNLSIPTNKKFIKIARELHEDGQPHLHVLIQFEGKFQCKNNRFFDLVSPTRSAHFHPNVQGAKSSSDVKSYVEKDGDTIEWGEFQIDGRSARGGCQTVNDTYAKALNAGSAEEALQIIKEEQPQHFFLQHHNLVANASRIFQKAPEPWAPPFHLSSFTNVPDEMQEWADDYFGRGSAARPERPISLIVEGDSRTGKTMWARALGPHNYLSGHLDFNSRVYSDEAEYNVIDDVTPHYLKLKHWKELIGAQKEWQSNCKYGKPRKIKGGIPSIVLCNPGEGASYKEYLDKEENASLRAWTLHNAKFIFLDSPLYQTTAQDCEEQSNPT |
|
NCBI Accession
|
YP_004958223.1
|
|
Location
|
2120-2377 |
|
Gene Name
|
AC4 |
|
Protein Name
|
AC4 protein |
|
Coding Region
|
ATGGGCAGCCTCATCTCCACGTCCTTATCCAGTTCGAGGGGAAATTCCAATGCAAAAATAACAGATTCTTCGATCTGGTCTCCCCAACCAGGTCAGCACATTTCCATCCGAACGTTCAGGGAGCTAAATCATCGTCCGACGTCAAGTCCTACGTCGAGAAGGACGGAGACACCATCGAATGGGGAGAATTCCAAATCGACGGAAGAAGTGCTAGAGGAGGTTGCCAGACGGTTAACGACACATATGCCAAGGCATTGA |
|
Protein Sequence
|
MGSLISTSLSSSRGNSNAKITDSSIWSPQPGQHISIRTFRELNHRPTSSPTSRRTETPSNGENSKSTEEVLEEVARRLTTHMPRH |
|
NCBI Accession
|
YP_004958244.1
|
|
Location
|
527-1297 |
|
Gene Name
|
BV1 |
|
Protein Name
|
nuclear shuttle protein |
|
Coding Region
|
ATGTATGCAGCCAAGTTTAGACGTGGTCAATCTAGTAATTACCGTCGTAATTACAAAAGGAAGAACGTCTTTAAGACTGTTTATGGTGTTAAGCGGTACGATGGGAAACGTGGATTTAATATTCAGAACAAGGCCCATGATGATAGTAAGATGTCGGCCCAGCGTATTCACGAGAACCAGTTTGGGCCAGAGTTTGTAATGGCCCACAACACAGCCATTTCAACGTTCATCACATTTCCAAGCCTATGTAAGACGGAGCCGAACCGAAGCAGGTCCTATATTAAGTTGAAACGACTTCGTTTTAAGGGTACTGTCAAGATTGAACGGGTTCACACTGACGTCATTATGGATGGATCAAGCCCAAAAACCGAAGGAGTATTTTCATTGGTCGTTGTGGTGGACCGGAAACCTCATTTGGGTCCATCTGGATGTCTCCATACGTTTGATGAGCTCTTTGGGGCCAGGATCCACAGTCATGGTAATTTAGCCATAACCCCGTCCCTTAAAGACCGTTTCTATATACGACATGTGCACAAACGTGTTCTGTCTGTGGAGAAGGACACCCTAATGGTTGATATTGAAGGGACGACATCACTCTCTAACAGGCGTTTTAACTGTTGGTCCTCTTTTAAGGATGTAGACCGGGATTCATGTAACGGTGTTTATGCAAACATAAGCAAGAACGCCCTGTTAGTTTATTACTGTTGGATGTCTGACTCTTCGTCCAAGGCATCGACATTTGTATCATATGATCTTGACTATATTGGTTAA |
|
Protein Sequence
|
MYAAKFRRGQSSNYRRNYKRKNVFKTVYGVKRYDGKRGFNIQNKAHDDSKMSAQRIHENQFGPEFVMAHNTAISTFITFPSLCKTEPNRSRSYIKLKRLRFKGTVKIERVHTDVIMDGSSPKTEGVFSLVVVVDRKPHLGPSGCLHTFDELFGARIHSHGNLAITPSLKDRFYIRHVHKRVLSVEKDTLMVDIEGTTSLSNRRFNCWSSFKDVDRDSCNGVYANISKNALLVYYCWMSDSSSKASTFVSYDLDYIG |
|
NCBI Accession
|
YP_004958245.1
|
|
Location
|
1362-2243 |
|
Gene Name
|
BC1 |
|
Protein Name
|
movement protein |
|
Coding Region
|
ATGGAATCTCAGTTAGTTAATCCGCCAAATGCATTTAATTATATAGAGTCTCAGCGTGACGAGTATCAACTTTCTCATGACCTAACTGAGATCGTACTACAGTTTCCTTCTGCGGCGGCTCAGATAAGTGCCAGGCTCAGTCGTAGCTGTATGAAGATCGACCATTGCGTCATCGAATACAGACAACAAGTACCGATAAACGCCGCAGGTTCCGTCATAGTGGAGATCCACGACAAGAGAATGACTGAAAACGAATCCTTACAGGCGTCGTGGACTTTTCCGATCAGATGTAACATAGATCTCCACTATTTCTCCTCGTCCTTCTTCTCCCTGAAGGACCCAATCCCTTGGAAGCTGTACTACAGGGTCAGCGACACAAATGTTCATCAGAGGACCCACTTCGCGAAGTTCAAGGGAAAGCTGAAGCTTTCAACGGCGAAACATTCCGTGGATATTCCTTTCCGAGCACCGACAGTCAAAATATTGTCTAAACAGTTTACAGACAGAGATATCGACTTCTGCCATGTGGGCTATGGCAAATGGGAAAGGAAATTGATCCGATCCACCTCAACAACAACACATGGGCTTCCTAGCCCACTATCCATTGATCCAGGAGAGACCTGGGCTGCAAAGAGTACCATAGGGATCGGACAATCCAGTGCCGATTCTGAAATAGAGAACGCAGCACTCCCATATCGAGGCCTACACAGACTGGGGACCAGCTTGTTAGACCCAGGAGACTCAGCCTCAATTGTTGCTGCAAGAAGGACAGAATCGCATATCACCATGTCAGAGGCCCAATTAAACGACCTAGTCAGGACTGCGGTCCAGGAATGTATCAAGACAAATTGTATAGCTCCCCAGCCCAAACCTTTAAATTAA |
|
Protein Sequence
|
MESQLVNPPNAFNYIESQRDEYQLSHDLTEIVLQFPSAAAQISARLSRSCMKIDHCVIEYRQQVPINAAGSVIVEIHDKRMTENESLQASWTFPIRCNIDLHYFSSSFFSLKDPIPWKLYYRVSDTNVHQRTHFAKFKGKLKLSTAKHSVDIPFRAPTVKILSKQFTDRDIDFCHVGYGKWERKLIRSTSTTTHGLPSPLSIDPGETWAAKSTIGIGQSSADSEIENAALPYRGLHRLGTSLLDPGDSASIVAARRTESHITMSEAQLNDLVRTAVQECIKTNCIAPQPKPLN |