Sida micrantha mosaic virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_000840905.1 |
| Isolate |
Brazil |
| Release date |
2015/2/12 |
| Submitter |
Jovel,J., Reski,G., Rothenstein,D., Ringel,M., Frischmuth,T., Jeske,H. |
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
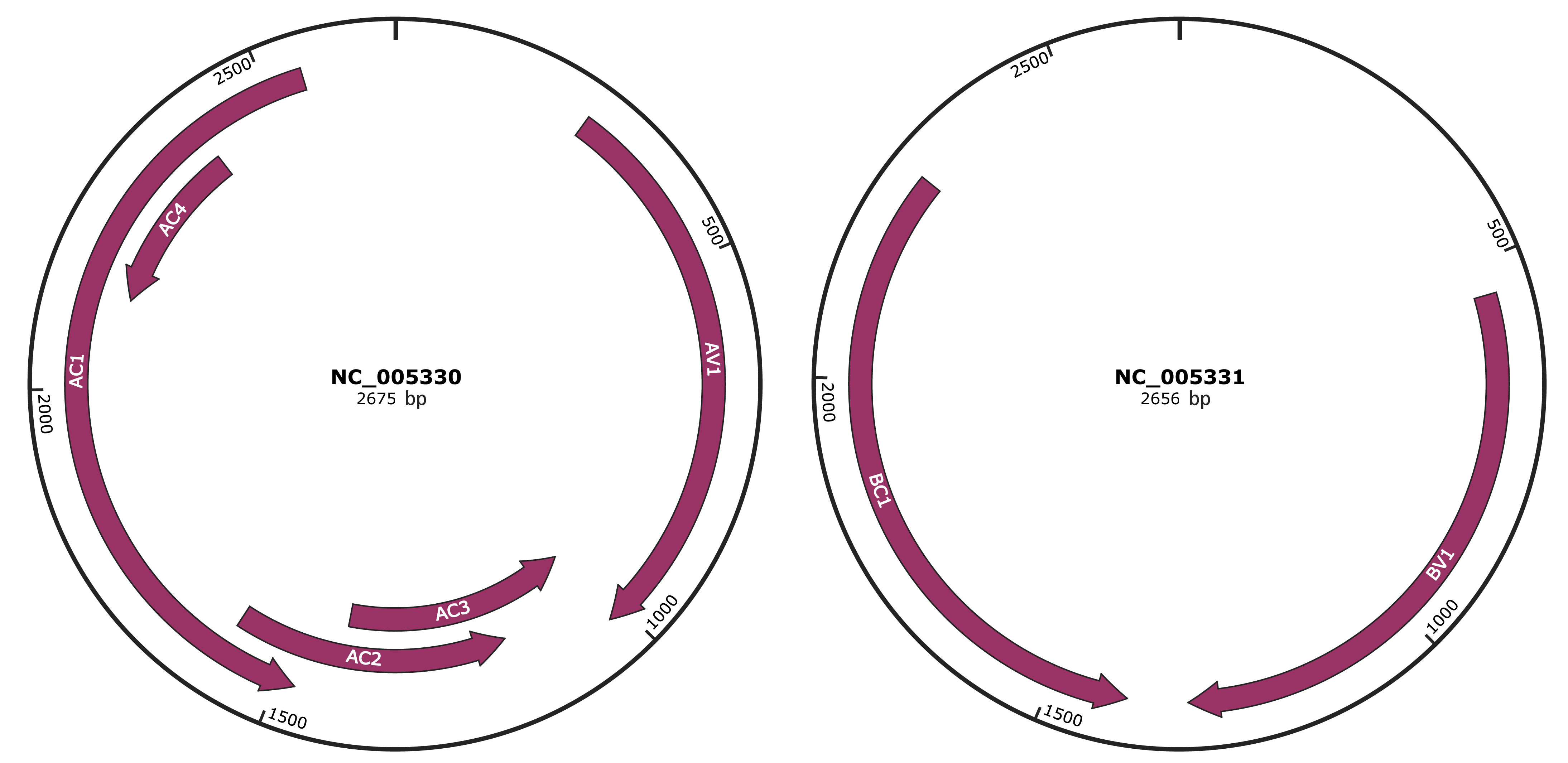
JBrowse
Genome
ACCGGATGGCCGCGCGATTTTCCCCCCCCCCCACGTGGCGCTCTGGTGGTCGTGCGATTTCTCTCCCCCCCTCTCGCGCGACGTGGAGCTCTGGTGTCCGCGCGTTCCACCCGCGCGCTCTGCCTTTAATTTAAATTAAAGGGAATAACTTTCATCAGGACCAATGAAATTGCGTCCTTTAAGCGTAAATATCAGCGTAAGACTTGGGCCCTAAGTTGTTTGACGTCTATAAAATTAGGTCATGTATGACGTCAGTATTATTTCAAAATGCCTAAGCGGGATCCCTCATGGCGCCAGATGGCGGGAACCTCAAAGGTTAGCCGCTCTTCTAATTTCTCACCTCGTGGAGGTGGAGGCCCAAAATATAACAAGGCCTCAGAATGGGTGAACAGGCCCATGTACAGGAAGCCCAGGATATACAGGACGCTAAGGACGCCTGATATTCCTAGAGGCTGTGAAGGGCCTTGTAAAGTCCAGTCATACGAGCAACGCCATGATATCTCACATGTCGGGAAGGTCATGTGCATCTCTGACGTCACCCGTGGCAACGGTATAGCACACCGTGTCGGTAAGCGTTTTTGCGTTAAGTCTGTGTACATTTTAGGGAAGATATGGATGGACGAGAACATCAAGCTCAAGAACCACACGAACAGTGTCATGTTCTGGTTGGTCAGGGACCGTAGACCGTATGGTACTCCTATGGACTTTGGCCAGGTGTTCAACATGTTTGACAACGAGCCCAGCACTGCTACGGTGAAGAACGATCTCCGTGATCGTTATCAAGTTATGCACAAGTTCTACGCCAAGGTCACTGGTGGTCAATATGCCAGCAACGAGCAGGCTCTGGTCAAGAGGTTCTGGAAGGTCAACAATCATGTGGTGTACAACCACCAGGAAGCTGGCAAGTATGAGAATCACACGGAGAATGCTTTGTTACTGTACATGGCATGTACTCATGCCTCTAACCCTGTGTATGCAACGCTTAAGATTCGGATCTATTTCTACGATTCGATAACCAATTAATAAAATTTGAATTTTATATCATGATCTTCAAGTACATAGTTTACATAGGCTTTGTCAGTGGCAAAGCGAACAGCTCTAATTACATTATTAAGGGAAATTACACCTAATTGGTCTAAGTACATCATTACAAGGCGTCTAAGCCTAATCAAATAAGTCGTTCCAGAAGCTGTCAGAGAAGTCGTCCAGACTTGGAAGTTCAGGTAGGCCTTGTGGAGACCCAATACTTTCCTGAGGCTGTGGTTGAACCTTATCTGTATGTGGTACACTCTGGTCCTCGTGTACGGCAGGTCCTCTACGTTGTACATCTTGAAATACAGGGGATTTGTTATCTCCCAGATATAGACGCCATTCTCTGCCTGATGTGCAGTGATGAATTCCCCGGTGCGTGAATCCATGGCCGGAGCAGTTAAGGTGTAGGTATATGGAGCAGCCGCACTGTATGTCCACTCGTCTACGCCTGATGGCTCTCTTCTTGGCAATCCTGTGTCTCGGTTTGATAGAGGGGGGCGTCGAGGAAGATGAATTTAGCATTGTGGAGTGTCCAAGCACGGAGCTGTGCATTTTCCTCTTTGTCTAGGAAGTCTTTATAGCAGGCCCCCTCTCCAGGATTGCATAGCACGATTGAAGGGACCCCACCTTCAATCAAACGAGGCTTTCCGTACTTGCAGTTTGTCTGCCATTTTTGTTGGGCCCCTACTAGCTCTTTCCAGTGTTTCAACTTTAGGTAATGCGGAGCGACGTCATCAATGACGTTATACTCCACTTGATCAGAATATACCTTTGAGTTGAAATCCAGATGGCCACTGAAGTAATTATGTGGGCCTAATGCTCTAGCCCACATCGTCTTGCCAGTTCGAGAACCACCTTCAACAATTAAACTTATAGGCCTCAATGGCCGCGCAGCGGAACCCCTCCCAAAATAATCATCGGCCCACTCTTGCATCTCGTCTGGCACGTCAGTGAATGAGGAGAGTCGAAACGGAGGGGCCCATGGCTCCGGAGCCTTTGCAAAGATCCTATCTAAATTACTATTTAGATTGTGAAACTGGAATAGGAACTTTTCCGGCAACTTCTCCCGGATTATCTGCAAGGCGATTTCTTTGGAAGGGGCGTTCAAGGCTTCTGCGGCAGCGTCGTTAGCTGTCTGGCAACCGCCTCTAGCACTTCTACCGTCGATCTGGAATTCCCCCCACTCGAGAGTATCTCCGTCCTTTTCGATGTAGGACTTAACGTCGGACGAGGATTTAGCTCCCTGTATGTTAGGATGGAAATGTGCTGACCTGGTTGGGGATACCAGGTCGAAGAGTCTGTTATTCGTGCATTGGAATTTCCCCTGGAACTGTATAAGGACGTGGAGATGAGGCTCCCCATTTTCGTGGAGCTCTCTGCAGATTTTGATGAACTTCTTGTTAACTGGTGTCGATAAGCTCTGTAATTGGGAAAGTGTCTCCTCTTTGGTTAAGGAGCACTGTGGATAAGTCAAGAAATAATTCTTGGCACTTATTTTAAAACGCTTTGGCGGTGGCATTTTTGTAATTAAGGGGTGTACCCCAATTGAGAGCTCGCTCTATAAGTCATATGAATTGGGGTAATGGGGACAATATATAGTAGAAGATCCTAAGGGGCTTTAAGCGGCCATCCGCACTAATATT
ACCGGATGGCCGCGCGATTTTTTTCCCCCCTACGTGGCGCGCTGGTGACCATTGGATACCGCTCTCCCTGGTGGTCCCCCTCCCAAGGTGTTACTCCCCCCTCCCCGGCTGAATTCAATTGAGCGCTATTTTGGAGTCCGCGAAATGGGTTAACCGCATTTTTTGACGTCCGCATACGATTGGTCCCTTTAATTTGAATTAAAGGATGTATAAATTCTATTGTCCAATCATTTCGCTCGGGTTGTCTCCTCGCGCGACGCTCGCTTTTGCCCAACGGGATGAGATGTGATCTTGGTCGTTGGATAATAATATAATTTATTCAGCCTCTTTAATGTGAAATTTGAATTATTGGCGAGCGTCGTACTACCATGTCCCATCGTACGAACTTGATGAGTTGGACCAGTCAAGTTGCACCTACAGAGTTAAATTGATCAAGGAATTTATGTTTAAATTCCCTGGTGACAGATGGTGATATCAGGTTAATTTACCACGTCTATTGTTTGAGTAGCTACAGTTAACGTTTGTGTGATAGTCAGTTTTAAAACATGTTTCCCAGTAGGTATAGACGTGGTTGGTCGTCTAATCAGCGACGAGGTTACACACGTAATCCCGTGTTTAAGCGTTCTTATGTTGCTAAACGAAGTGAAGTAAAACGACGACCCAGTTATCCAAACAAGACCCAAGAAGAAGGGAAACTAGCAGCCCAACGGATGCACGAGAACCAGTTTGGGCCTGAATTTGTTATGGGCCATAATTCAGCCATTTCGACGTTCATCACTTACCCTTCGCTGGGGAAGGCTCTCCCGAACCGATCCAGGTCATATATTAAGTTAAGACGACTGCGTTTTAAGGGTACTGTCAAGGTTGAGCGTGTGCATGCTAACGTCAACATGGATGGGTCCAACCCAAAGGTGGAAGGAGTCTTCTCTCTTGTTGTTGTTGTGGATCGTAAACCCCATCTGGGCTCATCTGGAGCCCTTCTTACATTTGATGAGTTATTCGGTGCTAGGATCCACAGCCATGGTAATCTCGCGATAGTACCCTCTCTGAAAGACCGTTTCTACATACGACACGTGTTCAAACGTGTGTTGTCCGTTGAGAAGGATTCCATGATGGTGGACGTAGAAGGGACGACCACTCTAACTACCAGGCGTTTTAGTTGTTGGTCTTCGTTTACGGATGTTGACCGTGAATCGTGTAACGGCGTCTATGCTAACATAAGCAAGAACGCCCTTTTAGTTTATTACTGCTGGATGTCGGATAATATTTCCAAGGCATCGACATTTGTTTCGTTTGACCTCGATTATATTGGCTAAATTGGAAATTTAATACAAGCTTAATGCAAATGACCATATTTATATTTCAGTATTAAATATACATGTTCCTCTACAATAATCTCAGTGCAATGATTTGGGTTGAGAAGGGGTACAGTTACTGTTGATACATTCCTGGGCCGTGGCCCTAACTAGTTCTATCATCTGGGCCATTGACATCGTTATGTTGGATTGGGCCCTTTGAGCACCCACTATTGAGGCCGAGTCACCTGGGTCTAGACTACTGGTTCCTAGCCTGTGCAGCTGCCTATATGGGTGCGCCGCGTTCTCTGCATCGGAGTCTGCGACTGAGTGACTGATCCCTACAGTGCTCCTGACAGCCCAGGACTCTCCAGGCCTTAATTCAATTGGGCTGTGCAACCCAACACCCGATATGGACGCAGATCTGATCATCTTTCTCTCCCACTTTCCGTAGCCAACGTGGCTGAAATCGATGTCCTTCTCTGTAAACTGCTTGGAGAGGATCTTCACTGTTGGGGCACGGAAAGGTATGTCTACAGAGTGTTTGGCCGTCGACAGCTTCAGCATTCCCTTGAATTTCGCGAAATGGGTCCTCTGATGGACGTTAGTGTCGCACACTCTGTAGTACAATTTCCATGGAATTGGGTCCTTGAGGGAGAAGAAGGACGAGGAAAAGTAATGGAGATCGATGTTGCATCGTATCGGAAACGTCCAGGACGCTTGCAGCGACTCGTTGTCAGTCATTCTCCTGTCATGGATCTCCACGACGACGGAACCCACGGCGTTAATGGGTACCTGCTGTCTGTATTCTATGACGCAATGGTCTATTTTCATACAGCTACGACTGAGCCGTGCGCTTAATTGGGACGCCGTGGAGGGAAATTGAAGAAGAATCTCTGTTAGGTCATGAGAAAGCTGATATTCATCACGCTGAGACTCAATATAATTGAATGCGTTTGGAGGATTCACTAGCTGAGATTCCATTGAATTTTAATATCAGAAATAGGCCGCGCAGCGGGAACGACAGAGAAATTTGAACAGGTGAAACGATTAGGTCTGAAAGACTTTAGGGTTTCTGTTGATGGTGAAAGAGTAAAGTTGAGAAGATGAACTTCTTGTTAACTGGTGTCGATAAGCTCTGTAATTGGGAAAGTGTCTCCTCTTTGGTTAAGAAGCACTGTGGATAAGTCAAGAAATAATTCTTGGCACTTATTTTAAAACGCTTTGGCGGTGGCATTTTTGTAATTAAGGGGTGTACCCCAATTGAGAGCTCGCTCTATAAGTCATATGAATTGGGGTAATGGGGACAATATATAGTAGAAGATCCTAAGGGGCTTTAAGCGGCCATCCGCACTAATATT
Gene Information
|
NCBI Accession
|
NP_957671.1
|
|
Location
|
268-1023 |
|
Gene Name
|
AV1 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGCCTAAGCGGGATCCCTCATGGCGCCAGATGGCGGGAACCTCAAAGGTTAGCCGCTCTTCTAATTTCTCACCTCGTGGAGGTGGAGGCCCAAAATATAACAAGGCCTCAGAATGGGTGAACAGGCCCATGTACAGGAAGCCCAGGATATACAGGACGCTAAGGACGCCTGATATTCCTAGAGGCTGTGAAGGGCCTTGTAAAGTCCAGTCATACGAGCAACGCCATGATATCTCACATGTCGGGAAGGTCATGTGCATCTCTGACGTCACCCGTGGCAACGGTATAGCACACCGTGTCGGTAAGCGTTTTTGCGTTAAGTCTGTGTACATTTTAGGGAAGATATGGATGGACGAGAACATCAAGCTCAAGAACCACACGAACAGTGTCATGTTCTGGTTGGTCAGGGACCGTAGACCGTATGGTACTCCTATGGACTTTGGCCAGGTGTTCAACATGTTTGACAACGAGCCCAGCACTGCTACGGTGAAGAACGATCTCCGTGATCGTTATCAAGTTATGCACAAGTTCTACGCCAAGGTCACTGGTGGTCAATATGCCAGCAACGAGCAGGCTCTGGTCAAGAGGTTCTGGAAGGTCAACAATCATGTGGTGTACAACCACCAGGAAGCTGGCAAGTATGAGAATCACACGGAGAATGCTTTGTTACTGTACATGGCATGTACTCATGCCTCTAACCCTGTGTATGCAACGCTTAAGATTCGGATCTATTTCTACGATTCGATAACCAATTAA |
|
Protein Sequence
|
MPKRDPSWRQMAGTSKVSRSSNFSPRGGGGPKYNKASEWVNRPMYRKPRIYRTLRTPDIPRGCEGPCKVQSYEQRHDISHVGKVMCISDVTRGNGIAHRVGKRFCVKSVYILGKIWMDENIKLKNHTNSVMFWLVRDRRPYGTPMDFGQVFNMFDNEPSTATVKNDLRDRYQVMHKFYAKVTGGQYASNEQALVKRFWKVNNHVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSITN |
|
NCBI Accession
|
NP_957672.1
|
|
Location
|
1020-1418 |
|
Gene Name
|
AC3 |
|
Protein Name
|
replication enhancer |
|
Coding Region
|
ATGGATTCACGCACCGGGGAATTCATCACTGCACATCAGGCAGAGAATGGCGTCTATATCTGGGAGATAACAAATCCCCTGTATTTCAAGATGTACAACGTAGAGGACCTGCCGTACACGAGGACCAGAGTGTACCACATACAGATAAGGTTCAACCACAGCCTCAGGAAAGTATTGGGTCTCCACAAGGCCTACCTGAACTTCCAAGTCTGGACGACTTCTCTGACAGCTTCTGGAACGACTTATTTGATTAGGCTTAGACGCCTTGTAATGATGTACTTAGACCAATTAGGTGTAATTTCCCTTAATAATGTAATTAGAGCTGTTCGCTTTGCCACTGACAAAGCCTATGTAAACTATGTACTTGAAGATCATGATATAAAATTCAAATTTTATTAA |
|
Protein Sequence
|
MDSRTGEFITAHQAENGVYIWEITNPLYFKMYNVEDLPYTRTRVYHIQIRFNHSLRKVLGLHKAYLNFQVWTTSLTASGTTYLIRLRRLVMMYLDQLGVISLNNVIRAVRFATDKAYVNYVLEDHDIKFKFY |
|
NCBI Accession
|
NP_957673.1
|
|
Location
|
1165-1584 |
|
Gene Name
|
AC2 |
|
Protein Name
|
transcriptional regulator |
|
Coding Region
|
ATGCACAGCTCCGTGCTTGGACACTCCACAATGCTAAATTCATCTTCCTCGACGCCCCCCTCTATCAAACCGAGACACAGGATTGCCAAGAAGAGAGCCATCAGGCGTAGACGAGTGGACATACAGTGCGGCTGCTCCATATACCTACACCTTAACTGCTCCGGCCATGGATTCACGCACCGGGGAATTCATCACTGCACATCAGGCAGAGAATGGCGTCTATATCTGGGAGATAACAAATCCCCTGTATTTCAAGATGTACAACGTAGAGGACCTGCCGTACACGAGGACCAGAGTGTACCACATACAGATAAGGTTCAACCACAGCCTCAGGAAAGTATTGGGTCTCCACAAGGCCTACCTGAACTTCCAAGTCTGGACGACTTCTCTGACAGCTTCTGGAACGACTTATTTGATTAG |
|
Protein Sequence
|
MHSSVLGHSTMLNSSSSTPPSIKPRHRIAKKRAIRRRRVDIQCGCSIYLHLNCSGHGFTHRGIHHCTSGREWRLYLGDNKSPVFQDVQRRGPAVHEDQSVPHTDKVQPQPQESIGSPQGLPELPSLDDFSDSFWNDLFD |
|
NCBI Accession
|
NP_957674.1
|
|
Location
|
1475-2551 |
|
Gene Name
|
AC1 |
|
Protein Name
|
replication associated protein |
|
Coding Region
|
ATGCCACCGCCAAAGCGTTTTAAAATAAGTGCCAAGAATTATTTCTTGACTTATCCACAGTGCTCCTTAACCAAAGAGGAGACACTTTCCCAATTACAGAGCTTATCGACACCAGTTAACAAGAAGTTCATCAAAATCTGCAGAGAGCTCCACGAAAATGGGGAGCCTCATCTCCACGTCCTTATACAGTTCCAGGGGAAATTCCAATGCACGAATAACAGACTCTTCGACCTGGTATCCCCAACCAGGTCAGCACATTTCCATCCTAACATACAGGGAGCTAAATCCTCGTCCGACGTTAAGTCCTACATCGAAAAGGACGGAGATACTCTCGAGTGGGGGGAATTCCAGATCGACGGTAGAAGTGCTAGAGGCGGTTGCCAGACAGCTAACGACGCTGCCGCAGAAGCCTTGAACGCCCCTTCCAAAGAAATCGCCTTGCAGATAATCCGGGAGAAGTTGCCGGAAAAGTTCCTATTCCAGTTTCACAATCTAAATAGTAATTTAGATAGGATCTTTGCAAAGGCTCCGGAGCCATGGGCCCCTCCGTTTCGACTCTCCTCATTCACTGACGTGCCAGACGAGATGCAAGAGTGGGCCGATGATTATTTTGGGAGGGGTTCCGCTGCGCGGCCATTGAGGCCTATAAGTTTAATTGTTGAAGGTGGTTCTCGAACTGGCAAGACGATGTGGGCTAGAGCATTAGGCCCACATAATTACTTCAGTGGCCATCTGGATTTCAACTCAAAGGTATATTCTGATCAAGTGGAGTATAACGTCATTGATGACGTCGCTCCGCATTACCTAAAGTTGAAACACTGGAAAGAGCTAGTAGGGGCCCAACAAAAATGGCAGACAAACTGCAAGTACGGAAAGCCTCGTTTGATTGAAGGTGGGGTCCCTTCAATCGTGCTATGCAATCCTGGAGAGGGGGCCTGCTATAAAGACTTCCTAGACAAAGAGGAAAATGCACAGCTCCGTGCTTGGACACTCCACAATGCTAAATTCATCTTCCTCGACGCCCCCCTCTATCAAACCGAGACACAGGATTGCCAAGAAGAGAGCCATCAGGCGTAG |
|
Protein Sequence
|
MPPPKRFKISAKNYFLTYPQCSLTKEETLSQLQSLSTPVNKKFIKICRELHENGEPHLHVLIQFQGKFQCTNNRLFDLVSPTRSAHFHPNIQGAKSSSDVKSYIEKDGDTLEWGEFQIDGRSARGGCQTANDAAAEALNAPSKEIALQIIREKLPEKFLFQFHNLNSNLDRIFAKAPEPWAPPFRLSSFTDVPDEMQEWADDYFGRGSAARPLRPISLIVEGGSRTGKTMWARALGPHNYFSGHLDFNSKVYSDQVEYNVIDDVAPHYLKLKHWKELVGAQQKWQTNCKYGKPRLIEGGVPSIVLCNPGEGACYKDFLDKEENAQLRAWTLHNAKFIFLDAPLYQTETQDCQEESHQA |
|
NCBI Accession
|
NP_957675.1
|
|
Location
|
2137-2394 |
|
Gene Name
|
AC4 |
|
Protein Name
|
AC4 protein |
|
Coding Region
|
ATGGGGAGCCTCATCTCCACGTCCTTATACAGTTCCAGGGGAAATTCCAATGCACGAATAACAGACTCTTCGACCTGGTATCCCCAACCAGGTCAGCACATTTCCATCCTAACATACAGGGAGCTAAATCCTCGTCCGACGTTAAGTCCTACATCGAAAAGGACGGAGATACTCTCGAGTGGGGGGAATTCCAGATCGACGGTAGAAGTGCTAGAGGCGGTTGCCAGACAGCTAACGACGCTGCCGCAGAAGCCTTGA |
|
Protein Sequence
|
MGSLISTSLYSSRGNSNARITDSSTWYPQPGQHISILTYRELNPRPTLSPTSKRTEILSSGGNSRSTVEVLEAVARQLTTLPQKP |
|
NCBI Accession
|
NP_957676.1
|
|
Location
|
546-1316 |
|
Gene Name
|
BV1 |
|
Protein Name
|
nuclear shuttle protein |
|
Coding Region
|
ATGTTTCCCAGTAGGTATAGACGTGGTTGGTCGTCTAATCAGCGACGAGGTTACACACGTAATCCCGTGTTTAAGCGTTCTTATGTTGCTAAACGAAGTGAAGTAAAACGACGACCCAGTTATCCAAACAAGACCCAAGAAGAAGGGAAACTAGCAGCCCAACGGATGCACGAGAACCAGTTTGGGCCTGAATTTGTTATGGGCCATAATTCAGCCATTTCGACGTTCATCACTTACCCTTCGCTGGGGAAGGCTCTCCCGAACCGATCCAGGTCATATATTAAGTTAAGACGACTGCGTTTTAAGGGTACTGTCAAGGTTGAGCGTGTGCATGCTAACGTCAACATGGATGGGTCCAACCCAAAGGTGGAAGGAGTCTTCTCTCTTGTTGTTGTTGTGGATCGTAAACCCCATCTGGGCTCATCTGGAGCCCTTCTTACATTTGATGAGTTATTCGGTGCTAGGATCCACAGCCATGGTAATCTCGCGATAGTACCCTCTCTGAAAGACCGTTTCTACATACGACACGTGTTCAAACGTGTGTTGTCCGTTGAGAAGGATTCCATGATGGTGGACGTAGAAGGGACGACCACTCTAACTACCAGGCGTTTTAGTTGTTGGTCTTCGTTTACGGATGTTGACCGTGAATCGTGTAACGGCGTCTATGCTAACATAAGCAAGAACGCCCTTTTAGTTTATTACTGCTGGATGTCGGATAATATTTCCAAGGCATCGACATTTGTTTCGTTTGACCTCGATTATATTGGCTAA |
|
Protein Sequence
|
MFPSRYRRGWSSNQRRGYTRNPVFKRSYVAKRSEVKRRPSYPNKTQEEGKLAAQRMHENQFGPEFVMGHNSAISTFITYPSLGKALPNRSRSYIKLRRLRFKGTVKVERVHANVNMDGSNPKVEGVFSLVVVVDRKPHLGSSGALLTFDELFGARIHSHGNLAIVPSLKDRFYIRHVFKRVLSVEKDSMMVDVEGTTTLTTRRFSCWSSFTDVDRESCNGVYANISKNALLVYYCWMSDNISKASTFVSFDLDYIG |
|
NCBI Accession
|
NP_957677.1
|
|
Location
|
1398-2279 |
|
Gene Name
|
BC1 |
|
Protein Name
|
movement protein |
|
Coding Region
|
ATGGAATCTCAGCTAGTGAATCCTCCAAACGCATTCAATTATATTGAGTCTCAGCGTGATGAATATCAGCTTTCTCATGACCTAACAGAGATTCTTCTTCAATTTCCCTCCACGGCGTCCCAATTAAGCGCACGGCTCAGTCGTAGCTGTATGAAAATAGACCATTGCGTCATAGAATACAGACAGCAGGTACCCATTAACGCCGTGGGTTCCGTCGTCGTGGAGATCCATGACAGGAGAATGACTGACAACGAGTCGCTGCAAGCGTCCTGGACGTTTCCGATACGATGCAACATCGATCTCCATTACTTTTCCTCGTCCTTCTTCTCCCTCAAGGACCCAATTCCATGGAAATTGTACTACAGAGTGTGCGACACTAACGTCCATCAGAGGACCCATTTCGCGAAATTCAAGGGAATGCTGAAGCTGTCGACGGCCAAACACTCTGTAGACATACCTTTCCGTGCCCCAACAGTGAAGATCCTCTCCAAGCAGTTTACAGAGAAGGACATCGATTTCAGCCACGTTGGCTACGGAAAGTGGGAGAGAAAGATGATCAGATCTGCGTCCATATCGGGTGTTGGGTTGCACAGCCCAATTGAATTAAGGCCTGGAGAGTCCTGGGCTGTCAGGAGCACTGTAGGGATCAGTCACTCAGTCGCAGACTCCGATGCAGAGAACGCGGCGCACCCATATAGGCAGCTGCACAGGCTAGGAACCAGTAGTCTAGACCCAGGTGACTCGGCCTCAATAGTGGGTGCTCAAAGGGCCCAATCCAACATAACGATGTCAATGGCCCAGATGATAGAACTAGTTAGGGCCACGGCCCAGGAATGTATCAACAGTAACTGTACCCCTTCTCAACCCAAATCATTGCACTGA |
|
Protein Sequence
|
MESQLVNPPNAFNYIESQRDEYQLSHDLTEILLQFPSTASQLSARLSRSCMKIDHCVIEYRQQVPINAVGSVVVEIHDRRMTDNESLQASWTFPIRCNIDLHYFSSSFFSLKDPIPWKLYYRVCDTNVHQRTHFAKFKGMLKLSTAKHSVDIPFRAPTVKILSKQFTEKDIDFSHVGYGKWERKMIRSASISGVGLHSPIELRPGESWAVRSTVGISHSVADSDAENAAHPYRQLHRLGTSSLDPGDSASIVGAQRAQSNITMSMAQMIELVRATAQECINSNCTPSQPKSLH |