Sida leaf curl virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_000866845.1 |
| Isolate |
China:Hainan |
| Release date |
2015/2/13 |
| Submitter |
Guo,X., Zhou,X. |
| Host |
|
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
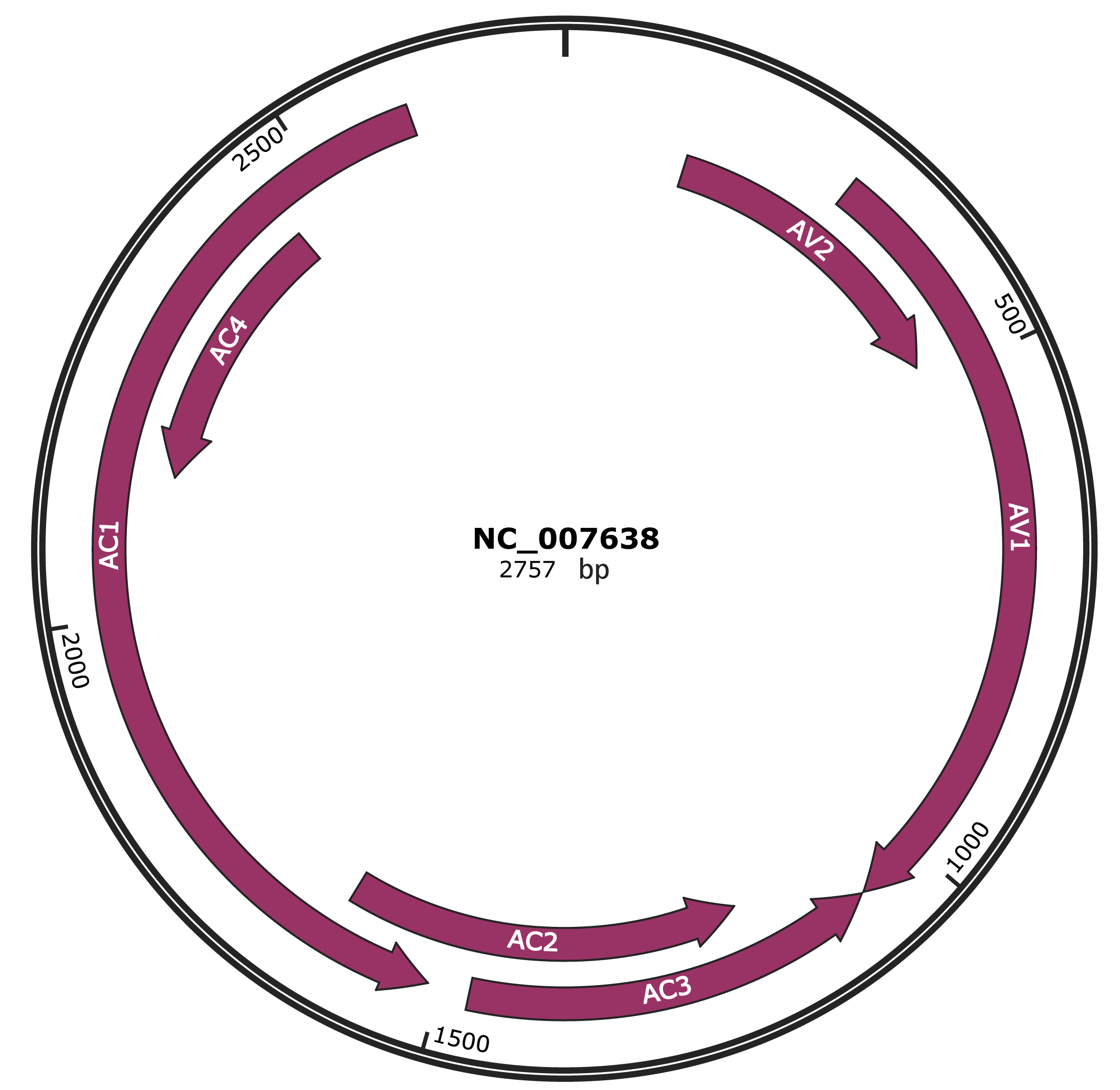
JBrowse
Genome
ACCGGATAGCCGCGCGATTTTTTAAAGTGGTCCCCCCCACTAAATGTTGTCGACCAACCAGAAGGCGCGCTCAAAGCTTAATTGTTTTTTCCCTCCCTATATAATACTTCCCTCGTAAGTTTTGGGTTCAAATATGTGGGACCCTTTAGAGAACGAATTCCCTGAAACCGTTCACGGTTTCCGTTCTATGCTTGCGGTGAAGTATATGCAGGAGATTGCGAAGAGCTACGAACCTAGCACATTGGGTTTTGAATACGTCCGTGATCTTATCTCCGTTCTGAGGTGTAAGGATTATGTCCAAGCGTCCTGCAAGTATGGCGTATTCCTCTCCAATTTCTTCCGCGCGTCGAAGGCTGAACTTCGACAGTCCTCGCCCATCAGTTGCTGCTGCCCTTACTGCCCCAGGCATAAGGAGAAGAAGATGGACCAACAGGCCCATGAACAGAAAGCCCAGGTTCTACAGAATGTATCGAACCCCTGATGTTCCTAAGGGCTGTGAGGGCCCATGTAAGGTGCAATCGTTCGATGCCAAAGACGATATTGGGCACATGGGTAAGGTTATTTGTTTGTCTGATGTTACAAGAGGTATTGGGCTGACCCACCGAGTGGGTAAGCGTTTCTGTGTGAAATCATTGTATTTCGTAGGGAAAATATGGATGGACGAGAATATCAAGGTGAAAAACCACACGAACACCGTTATGTTTTGGATTGTTAGGGATCGGCGACCTACGGGAACTCCATTGGATTTCCAGCAGGTGTTTAATGTCTACGATAACGAGCCCGCCACTGCTACAGTCAAGAACGACAAACGTGATCGTTTCCAGGTTTTAAGGAGGTTCCATGCAACGGTGACCGGAGGGCAATATGCAGCTAAGGAGTCTGCTATTATTAGGAAGTTCTATCGTGTGAACAATTATGTTGTTTACAACCACCAGGAGGCCGGAAAATACGAGAACCATACTGAGAATGCTTTGCTCTTGTACATGGCATGTACGCATGCCTCTAATCCTGTGTATGCTACTTTGAAATGTAGGAGTTATTTCTACGATACTGTAACGAATTAAGATTAATAAAGGTTGAATTTTATTGACTCAGTTTGTTGCACCTGAATTGTGCCTTGAATTACATTGTATAATACATGATCAAAAGCCCTAATTACATTATTAATACTAATAACTCCTAATCTATCTAAGTACCCAAGAACTTGATTGCGTAAGACCCTCAAGAAACGCCATGTCTGAGGATGTAAACGAGTCCAGATCCGGAAGGTTATGAAACATTTGTGAATCCCCAAGGCTTTCCTCAGGTTGTGGTTGAACCTCACTTGGACGGTTATGATGTCGTGGTTGCGGAGGAACGGCCTGTCCAGGTGGTCTAGGATCTTGAAATACAGGGGATTTGCCATATCCCAGGTATATACGCCACTCGTCGCTTGAGCTGCAGTGATGTATTCCCCTGTGCGTGAATCCATGGTTGTGACAGTTGAGACTGCGGAAGTATGTGCACCCGCATTCAAGGTCCACCCTCTTCCTGCGATTGTACTTCTTCCTCACCTTCTGATGCTCGATTTTGATGGGCACCTGAGTACAATGGCTCTGTGAGGGTGACGAACGACGCATTTTTTAAAGCCCACGTCTTTAAAGCGGAATTCTTTTCCTCGTCCAGGTACTCTTTATAGCTGGAATTGGGCCCTGGATTGCAAAGGAAGATTGTTGGGATCCCGCCTTTAATTTGAACTGGCTTGCCGTACTTGGTATTGCTTTGCCAGTCCCTCTGGGCCCCCATAAACTCTTTAAAGTGTTTGAGAAAATGGGGATCAACGTCATCGATGACGTTGTACCATGCGTCGTTGCTGTACACCTTTGGGCTTAGGTCTAGATGCCCACACAAGTAATTATGTGGACCTAATGACCTGGCCCACATCGTCTTCCCTGTTCTACTGTCACCTTCTACCACTAAACTTAAGGGTCTCAGAGGCCGCGCAGCGGCCGCCACTACATTCTCGCACGCCCACTCTTCGAGTTCTTCCGGAACTCGATCAAAAGAAGAGACAGAAAAAGGAGAAACATAAACCTCCATTGGAGGTGTAAAAATCCTATCTAAGTTAGCATTTAAATTATGAAATTGTAAAACATAATCTTTAGGGGCTAGTTCCCTAAGTACTCTAAGAGCCTCCGGCTTACTGCCTGTGTTAAGTGCTGCGGCGTAAGCGTCGTTGGCTGTCTGTTGTCCCCCTCTGGCAGATCTTCCGTCGATCTGAAACTCTCCCCATTCGATGGTGTCGCCGTCCTTGTCGATGTAGGACTTGACATCTGAGCTTGATTTAGCTCCCTGAATGTTCGGATGGAAATGTGCTGACCGGTTTGGGGAGACCAGGTCGAAGAATCGCTGATTCTGGCACTTGTATTTCCCCTCGAACTGGATGAGCACGTGAATATGAGGTTCCCCATTCTCGTGGAGTTCTCTGCAGACCTTAATGTATTTTTTGTTGGTTGGGGTGTTTAGGTTTTGGATTTGGGAAAGTGTTTCCTCTTTAGTAAGAGAGCATTTGGGATAAGTAAGGAAATAATTTTTGCAATAAATGTTAAAGCGTTTAGAGGGAGCCATAATGGTCAATGATCACCGATTGACTCGCTCTTGCAACTCTCTCTGGTATTTCGGTGATCAATATATAGTGATCACCAAATGGCATTAATCGTAAATACCCATAGAAATTCAAATCCCTCGCGCTCCAAAAGCGGCCATCCGTATAATATT
Gene Information
|
NCBI Accession
|
YP_425029.1
|
|
Location
|
134-481 |
|
Gene Name
|
AV2 |
|
Protein Name
|
AV2 protein |
|
Coding Region
|
ATGTGGGACCCTTTAGAGAACGAATTCCCTGAAACCGTTCACGGTTTCCGTTCTATGCTTGCGGTGAAGTATATGCAGGAGATTGCGAAGAGCTACGAACCTAGCACATTGGGTTTTGAATACGTCCGTGATCTTATCTCCGTTCTGAGGTGTAAGGATTATGTCCAAGCGTCCTGCAAGTATGGCGTATTCCTCTCCAATTTCTTCCGCGCGTCGAAGGCTGAACTTCGACAGTCCTCGCCCATCAGTTGCTGCTGCCCTTACTGCCCCAGGCATAAGGAGAAGAAGATGGACCAACAGGCCCATGAACAGAAAGCCCAGGTTCTACAGAATGTATCGAACCCCTGA |
|
Protein Sequence
|
MWDPLENEFPETVHGFRSMLAVKYMQEIAKSYEPSTLGFEYVRDLISVLRCKDYVQASCKYGVFLSNFFRASKAELRQSSPISCCCPYCPRHKEKKMDQQAHEQKAQVLQNVSNP |
|
NCBI Accession
|
YP_425030.1
|
|
Location
|
294-1064 |
|
Gene Name
|
AV1 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGTCCAAGCGTCCTGCAAGTATGGCGTATTCCTCTCCAATTTCTTCCGCGCGTCGAAGGCTGAACTTCGACAGTCCTCGCCCATCAGTTGCTGCTGCCCTTACTGCCCCAGGCATAAGGAGAAGAAGATGGACCAACAGGCCCATGAACAGAAAGCCCAGGTTCTACAGAATGTATCGAACCCCTGATGTTCCTAAGGGCTGTGAGGGCCCATGTAAGGTGCAATCGTTCGATGCCAAAGACGATATTGGGCACATGGGTAAGGTTATTTGTTTGTCTGATGTTACAAGAGGTATTGGGCTGACCCACCGAGTGGGTAAGCGTTTCTGTGTGAAATCATTGTATTTCGTAGGGAAAATATGGATGGACGAGAATATCAAGGTGAAAAACCACACGAACACCGTTATGTTTTGGATTGTTAGGGATCGGCGACCTACGGGAACTCCATTGGATTTCCAGCAGGTGTTTAATGTCTACGATAACGAGCCCGCCACTGCTACAGTCAAGAACGACAAACGTGATCGTTTCCAGGTTTTAAGGAGGTTCCATGCAACGGTGACCGGAGGGCAATATGCAGCTAAGGAGTCTGCTATTATTAGGAAGTTCTATCGTGTGAACAATTATGTTGTTTACAACCACCAGGAGGCCGGAAAATACGAGAACCATACTGAGAATGCTTTGCTCTTGTACATGGCATGTACGCATGCCTCTAATCCTGTGTATGCTACTTTGAAATGTAGGAGTTATTTCTACGATACTGTAACGAATTAA |
|
Protein Sequence
|
MSKRPASMAYSSPISSARRRLNFDSPRPSVAAALTAPGIRRRRWTNRPMNRKPRFYRMYRTPDVPKGCEGPCKVQSFDAKDDIGHMGKVICLSDVTRGIGLTHRVGKRFCVKSLYFVGKIWMDENIKVKNHTNTVMFWIVRDRRPTGTPLDFQQVFNVYDNEPATATVKNDKRDRFQVLRRFHATVTGGQYAAKESAIIRKFYRVNNYVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKCRSYFYDTVTN |
|
NCBI Accession
|
YP_425031.1
|
|
Location
|
1067-1471 |
|
Gene Name
|
AC3 |
|
Protein Name
|
AC3 protein |
|
Coding Region
|
ATGGATTCACGCACAGGGGAATACATCACTGCAGCTCAAGCGACGAGTGGCGTATATACCTGGGATATGGCAAATCCCCTGTATTTCAAGATCCTAGACCACCTGGACAGGCCGTTCCTCCGCAACCACGACATCATAACCGTCCAAGTGAGGTTCAACCACAACCTGAGGAAAGCCTTGGGGATTCACAAATGTTTCATAACCTTCCGGATCTGGACTCGTTTACATCCTCAGACATGGCGTTTCTTGAGGGTCTTACGCAATCAAGTTCTTGGGTACTTAGATAGATTAGGAGTTATTAGTATTAATAATGTAATTAGGGCTTTTGATCATGTATTATACAATGTAATTCAAGGCACAATTCAGGTGCAACAAACTGAGTCAATAAAATTCAACCTTTATTAA |
|
Protein Sequence
|
MDSRTGEYITAAQATSGVYTWDMANPLYFKILDHLDRPFLRNHDIITVQVRFNHNLRKALGIHKCFITFRIWTRLHPQTWRFLRVLRNQVLGYLDRLGVISINNVIRAFDHVLYNVIQGTIQVQQTESIKFNLY |
|
NCBI Accession
|
YP_425032.1
|
|
Location
|
1185-1619 |
|
Gene Name
|
AC2 |
|
Protein Name
|
AC2 protein |
|
Coding Region
|
ATGCGTCGTTCGTCACCCTCACAGAGCCATTGTACTCAGGTGCCCATCAAAATCGAGCATCAGAAGGTGAGGAAGAAGTACAATCGCAGGAAGAGGGTGGACCTTGAATGCGGGTGCACATACTTCCGCAGTCTCAACTGTCACAACCATGGATTCACGCACAGGGGAATACATCACTGCAGCTCAAGCGACGAGTGGCGTATATACCTGGGATATGGCAAATCCCCTGTATTTCAAGATCCTAGACCACCTGGACAGGCCGTTCCTCCGCAACCACGACATCATAACCGTCCAAGTGAGGTTCAACCACAACCTGAGGAAAGCCTTGGGGATTCACAAATGTTTCATAACCTTCCGGATCTGGACTCGTTTACATCCTCAGACATGGCGTTTCTTGAGGGTCTTACGCAATCAAGTTCTTGGGTACTTAGATAG |
|
Protein Sequence
|
MRRSSPSQSHCTQVPIKIEHQKVRKKYNRRKRVDLECGCTYFRSLNCHNHGFTHRGIHHCSSSDEWRIYLGYGKSPVFQDPRPPGQAVPPQPRHHNRPSEVQPQPEESLGDSQMFHNLPDLDSFTSSDMAFLEGLTQSSSWVLR |
|
NCBI Accession
|
YP_425033.1
|
|
Location
|
1513-2607 |
|
Gene Name
|
AC1 |
|
Protein Name
|
replication protein |
|
Coding Region
|
ATGGCTCCCTCTAAACGCTTTAACATTTATTGCAAAAATTATTTCCTTACTTATCCCAAATGCTCTCTTACTAAAGAGGAAACACTTTCCCAAATCCAAAACCTAAACACCCCAACCAACAAAAAATACATTAAGGTCTGCAGAGAACTCCACGAGAATGGGGAACCTCATATTCACGTGCTCATCCAGTTCGAGGGGAAATACAAGTGCCAGAATCAGCGATTCTTCGACCTGGTCTCCCCAAACCGGTCAGCACATTTCCATCCGAACATTCAGGGAGCTAAATCAAGCTCAGATGTCAAGTCCTACATCGACAAGGACGGCGACACCATCGAATGGGGAGAGTTTCAGATCGACGGAAGATCTGCCAGAGGGGGACAACAGACAGCCAACGACGCTTACGCCGCAGCACTTAACACAGGCAGTAAGCCGGAGGCTCTTAGAGTACTTAGGGAACTAGCCCCTAAAGATTATGTTTTACAATTTCATAATTTAAATGCTAACTTAGATAGGATTTTTACACCTCCAATGGAGGTTTATGTTTCTCCTTTTTCTGTCTCTTCTTTTGATCGAGTTCCGGAAGAACTCGAAGAGTGGGCGTGCGAGAATGTAGTGGCGGCCGCTGCGCGGCCTCTGAGACCCTTAAGTTTAGTGGTAGAAGGTGACAGTAGAACAGGGAAGACGATGTGGGCCAGGTCATTAGGTCCACATAATTACTTGTGTGGGCATCTAGACCTAAGCCCAAAGGTGTACAGCAACGACGCATGGTACAACGTCATCGATGACGTTGATCCCCATTTTCTCAAACACTTTAAAGAGTTTATGGGGGCCCAGAGGGACTGGCAAAGCAATACCAAGTACGGCAAGCCAGTTCAAATTAAAGGCGGGATCCCAACAATCTTCCTTTGCAATCCAGGGCCCAATTCCAGCTATAAAGAGTACCTGGACGAGGAAAAGAATTCCGCTTTAAAGACGTGGGCTTTAAAAAATGCGTCGTTCGTCACCCTCACAGAGCCATTGTACTCAGGTGCCCATCAAAATCGAGCATCAGAAGGTGAGGAAGAAGTACAATCGCAGGAAGAGGGTGGACCTTGA |
|
Protein Sequence
|
MAPSKRFNIYCKNYFLTYPKCSLTKEETLSQIQNLNTPTNKKYIKVCRELHENGEPHIHVLIQFEGKYKCQNQRFFDLVSPNRSAHFHPNIQGAKSSSDVKSYIDKDGDTIEWGEFQIDGRSARGGQQTANDAYAAALNTGSKPEALRVLRELAPKDYVLQFHNLNANLDRIFTPPMEVYVSPFSVSSFDRVPEELEEWACENVVAAAARPLRPLSLVVEGDSRTGKTMWARSLGPHNYLCGHLDLSPKVYSNDAWYNVIDDVDPHFLKHFKEFMGAQRDWQSNTKYGKPVQIKGGIPTIFLCNPGPNSSYKEYLDEEKNSALKTWALKNASFVTLTEPLYSGAHQNRASEGEEEVQSQEEGGP |
|
NCBI Accession
|
YP_425034.1
|
|
Location
|
2148-2450 |
|
Gene Name
|
AC4 |
|
Protein Name
|
AC4 protein |
|
Coding Region
|
ATGGGGAACCTCATATTCACGTGCTCATCCAGTTCGAGGGGAAATACAAGTGCCAGAATCAGCGATTCTTCGACCTGGTCTCCCCAAACCGGTCAGCACATTTCCATCCGAACATTCAGGGAGCTAAATCAAGCTCAGATGTCAAGTCCTACATCGACAAGGACGGCGACACCATCGAATGGGGAGAGTTTCAGATCGACGGAAGATCTGCCAGAGGGGGACAACAGACAGCCAACGACGCTTACGCCGCAGCACTTAACACAGGCAGTAAGCCGGAGGCTCTTAGAGTACTTAGGGAACTAG |
|
Protein Sequence
|
MGNLIFTCSSSSRGNTSARISDSSTWSPQTGQHISIRTFRELNQAQMSSPTSTRTATPSNGESFRSTEDLPEGDNRQPTTLTPQHLTQAVSRRLLEYLGN |