Sida golden yellow vein virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_000840485.1 |
| Isolate |
Jamaica |
| Release date |
2015/2/12 |
| Submitter |
Stewart,C.S., Kon,T., Gilbertson,R.L., Roye,M.E., Gilbertson,B.L. |
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
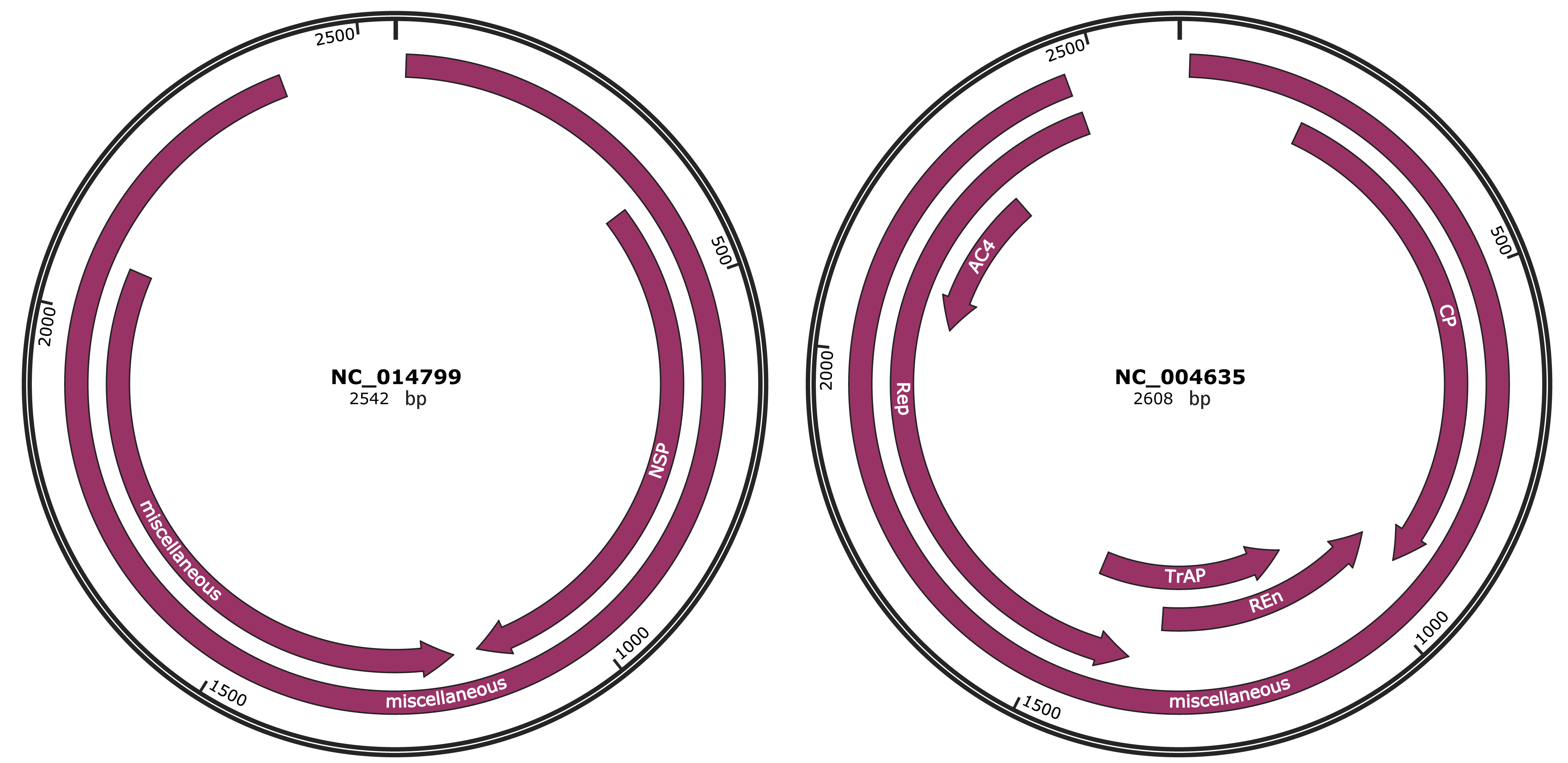
JBrowse
Genome
ACCGGATGGCCGCGCTTTGGTGGCCCCCTGGTGCCCTCTCACGCGCCCTCCTCTGGTGCTCGCTTTCCACGCGCTCTCTCATTGGCGTAGGTGTCTCACGCTCTTTTTTGTGTTTGTCCTTTAATTCAAATTAAAGGTTAATTCTTTATCGCGCGATTTGACCATATTGGTCGCGATGACTGACTATGTCCACTTTTACCTGTTGGTGGACGTGGCTTGATTTTGTCCATGTCGCTGAGCCTATTTGTGTTTAACTATTGACCTGGCTTTTCTATATATTTGAGAGAAATATGTATTATATGTTAAGTGGCTCAGCTGTTCCCCACGTTTATATTTTTATTCCTAATAATAGTTTAGCCATTATTATTACCGTATGAATATGTATCCTTTTAGGAATAAACGTGGGTCCTCATTCACTCAACGTCGTTATTATCCACGCAATACTGTGTTTAACCGTTTAACCGCCTCTAAGAGACATGATGTGAAACTACGACTGGGTCATATGAACAAGCCCACTGACGAGCCCAAGATGTCAGCCCAACGCATACATGAGAATCAATATAGTCCAGAGTTTGTTATGTCACAAAACTCCGCCATATCAACCTTTATCAGCTATCCTAATCTGGGTAAGACAGAACCCAATCGAAGCAGGTCTTATATAAAGTTGAAACGACTCCGTTTCAGAGGGACTGTGAAGATTGAGCGTGTTCAATCGGATGTGAATATGGATGGTTCTGTTCCTAAATTAGAAGGAGTTTTTTCTATCGTTGTAGTCGTGGATCGTAAACCCCACTTGGGTCCGACTGGTAGTCTTCATACATTCGACGAACTATTTGGTGCAATGATCCATAGTCATGGTAATCTTAGCATAACCCCGTCTCTGAAAGATCGGTTCTATATTCGACACGTGTTCAAACGTGTGATATCTGTTGATAAGGATACGACAATGTTTGACGTGGGAGGGTCTACTACGCTCTCTAATAGGCGATTCAATTGTTGGGCATCGTTTAAGGATTTTGATTGTGACTCAAGCAAGGGTGTATATGACAATATCAGCAAGAACGCTCTATTAGTTTATTATTGTTGGATGTCAGATACTATGTCTAAGGCATCGAATTTTGTATCGTTTGAACTCGATTATATCGGATGATTAATAAAATAACATTTATTAATTACAATAGTTTTTTATTGCAATGATTTAGGCTGAGAAGCCTTGCAATTACTATTAATACATTCATGGACCGTTGTCCTAACTAACTCGTTCAACTGTCCCATAGTCATTGTTATATTTGATTCCGCTCTCTGGGCTCCCACTATCGAAGCAGACTCACCCGGGTCCAATACGGTTGTACCCAGCCTGCTCAGATGTCTATATGGATGGAGCTCGAGCTCATTCTCTGTCTCCGAGTCCGCATCTGATTGGGCCGTACCTATTGTACTCCTGGAAGCCCATGATTCTCCTGGTCTTATTTCGATTGGGCCTCGTAGCCCAGTTCTGGACATGGACGCGCATCTGATGGGCTTCCTTTCCCATTTCCCATAGTCCACATGGGAAAAGTCCACATCTTTGTCTGTGAACTGTTTGACAGTATCTTTACCGTCGGTGCCCGGAAGGGGATATCCACTGAGTGTTTGGCTGTGGACAATTTCAGCTTCCCTTTGAATTTGGCGAAGTGTGTCCTCTGATGAACATTTGTATCTGAAACTCTGTAATAGAGTTTCCATGGAATTGGGTCTTTGAGTGAGAAGAAGGAAGCTGAGAAATAGTGGAGATCTATGTTGCACCTGATCGGAAAAGTCCATGACGCCTGTAATGACTCATTGTCTGTCATTCTTTTGTCATGTATCTCCACTATCACCGTCCCGGAAGCGTTAATGGGTACCTGTTGCCTGTACTCAATTACACAGTGGTCGATCTTCATACAGCTTCTGCTAAGTCTCGCCGTTAATTGTGCCGTCGTCGAAGGGAATTGCATAACTATCTCAGTTAAGTCATGGCATAGCTGATATTCATCTCTATGTGACTCTATATAGTTGAAGGCACTTGGAGGATTCATTAACTGAGATTCCATCTAGAAGATAAGGCCGCGCAGCGGCACTGACCACCGAGACTGAACTGATAAAGAAAAAACTAGGGTTTCTTCTTTTGAATAGCTTATGACGTCTAACTGAGGACGAATTGACTTCCTGGGTATTGACGATGAATATCGTTATGAGAAACCCAGAAATTTGCAGAAGAAACGAGGAACAATTGTTGAACTTGTCCAGAAATTGCTTTTGTTCTTTAGAAAGTGGAGAAATATTATCAGTCAAGTGTTGGGTATAACATGTTAGATCTGGCATATTTATATACAGACTTTTTTTTTTTGTTGATTTATTTGCATTTTTCTATCGATGGCATTTTTGTAATAATAAGGGGTCACCGATTGAGGCTCTCTCAAACTTGCTCTAGCAATTGGGGAACGGGGTCTCATTTATACAAGAAGCCTCAATAGAACTCTCAATCTCGTTCGCACACGTGGCGGCCATCCGCTATAATATT
ACCGGATGGCCGCGCGATTTTTTCGCCCTTTACTTTCCACGCGCGCTCCGCTTTTCTCACTCGCGCTATCGTCCAATCATATTGCGCCTGCCGCGCTTAATTAATTCAAACAACTTGGGCCCTAAGTTGTTGTCTGGGCCTATAAAGGAAAAGCGGATTTGGGCCACATTCTTTAATTCAAAATGACTAAGCGCGATTCATCTTGGCGCTCGATTGGTGGAACCTCAAAGGTTCGTCGCACGTTGAATTTCTCCCCACGTGGAGGTGGTGGCCCAAAACAGACACGGGCCTCAGAATGGGTTAACAGGCCTATGTACAGGAAGCCCTTGATCTATCGGACTATACGAACGCCCGACGTTCCCAGAGGTTGTGAAGGCCCGTGCAAGGTCCAGTCCTATGAACAGCGTCATGATATCTCTCACGTCGGGAAGGTGATGTGTATTTCTGATGTCACTCGTGGTAATGGTATTACCCACCGTGTGGGTAAGCGTTTTTGTGTTAAGTCTGTCTATATTTTAGGGAAGATATGGATGGATGAGAACATCAAGCTTAAGAACCACACGAACAGTGTCATGTTCTGGTTGGTCAGGGACCGTCGACCCTATGGCACTCCTATGGATTTCGGTCAGGTGTTCAACATGTATGACAATGAGCCTAGTACAGCTACGATCAAGAACGATCTCCGTGATCGTCATCAGGTTATGCACAGGTTCTATGGTAAGGTCACAGGTGGTCAATATGCCAGCAACGAGCAAGCTTTGGTTAGGCGATTCTGGAAGGTCAACAATCATGTAGAGTACAACCATCAAGAAGCTGGGAAATACGAGAATCATACGGAGAACGCCTTATTATTGTATATGGCATGTACTCATGCCTCTAACCCCGTGTATGCGACATTGAAAATTCGGATCTATTTTTATGATTCGATAACAAATTAATAAAATTTAAATTTTATTTCATGATTTTCAAGCACATGAGTTACATATGGTTTGGCTGTTGCAAAACGAACAGCTCTAATTACATTGTTTATTCCAATTACACCTAATTGGTACAAGTACTCATTTACTAATTGTCCAAATCTAGCTAAATAAGTTGACCCAGAAGCTGTCATCGATGTCGTCCAAACTTGGAAGTTCAGGTAGGCTTTGTGGAGACCCAACGCTCTCCTCAGGTTGTGGTTGAATCGTATCTGTATGTGGTACACTCTGGTTCTGGTGTATATCTGGTCCTCTACCCAGTATATCTTGAAATAGAGGGGATTTTCTATCTCCCAGATATACACGCCATTCTCTGCCTGACGTGCAGTGATGAGTTCCCCTGTGCGTGAAACCATGTCCCGTGCAGTTGATGTGGAAGTAAATGGAGCACCCGCAATTTAGATCAATCCTGCGCCTCCTGATTGCCCGCCTCTTGGATTGCCTGTGTGCCTTCTTGATAGAGGGGGGCTGTGAGGGTGATGAATTTGGCATTCTTGATGGTCCAGTTCCTGAGACCTGTGTTTTCCTCTTTGTTCAGGAAATCTTTATAGCTGGCACCCTCACCAGGATTGCAAAGCACGATTGATGGGATCCCTCCTTTAATTTGAACTGGCTTGCCGTATTTGCAATTTGACTGCCAGTCCTTCTGGGCCCCCAGAAGTTCTTTCCAGTGCTTTAGCTTTAGATATTGCGGTGCGACGTCATCAATGACGTTATATTCCACTTCATTTGAAAAGACCCGGGAATTGAAGTCTAAGTGTCCACTGAGATAATTGTGTGGGCCTAAGGCACGAGCCCACATCGTCTTCCCTGTCCTCGAGTCGCCTTCAATTATGATACTCACAGGCCTCTCCGGCCGCGCAGCGGCATCTGTTCCAAAATAACCGTCTGACCATGCTTGCATCTCGTCTGGAACGGCATTGAAAGAGGAGAGGGGAAACGGAGGAGACCATGGCTCCGGAGCCTTAGCGAATATCCTTTCTAAGTTGGCACGGATGTTATGATTCTGCAAAACGAAATCTTTTGGCTGTTCTTCTTTTAAAACCGCCATGGCAGATTCAACGGAATCTGCATTTAACGCCTTGGCATATGAATCATTAGCAGACTGGCAGCCTCCTCTAGCACTTCTGCCGTCGATCTGGAATTCTCCCCATTCCAGTGTATCTCCGTCCTTTGCGATGTAGGACTTGACGTCGGAGCTGGATTTAGCTCCCTGTATGTTTGGATGGAAATGTGCTGACCTGGTTGGGGAGGCCAGATCGAAGAATCTGTTATTCTTGCATGCATATTTTCCCTCGAATTGCATGGGCACATGGAGATGAGGCTTCCCATTTTGATGGAGCTCTCTGCAAATTTTGATGAACTTCTTATTCACTGGCGTGGAGAGGTTTAGCAATTGGGAAAGTGCCTCTTCTTTGGTGAGGGAGCAGCCTGGATAAGTGATAAAATAGTTTTTGGCATTTATTTTGAAACGTTTAATCGATGGCATTTTTGTAATAATAAGGGGGTCACCGATTGAGGCTCTCTCAAACTTGCTCTAGCAATTGGGGAACGGGGTCTCATTTATACAAGAAGCCTCAATAGAACTCTCAATCTCGTTCGCACACGTGGCGGCCATCCGCAATAATATT
Gene Information
|
NCBI Accession
|
YP_004064949.1
|
|
Location
|
374-1150 |
|
Gene Name
|
NSP |
|
Protein Name
|
nuclear shuttle protein |
|
Coding Region
|
ATGAATATGTATCCTTTTAGGAATAAACGTGGGTCCTCATTCACTCAACGTCGTTATTATCCACGCAATACTGTGTTTAACCGTTTAACCGCCTCTAAGAGACATGATGTGAAACTACGACTGGGTCATATGAACAAGCCCACTGACGAGCCCAAGATGTCAGCCCAACGCATACATGAGAATCAATATAGTCCAGAGTTTGTTATGTCACAAAACTCCGCCATATCAACCTTTATCAGCTATCCTAATCTGGGTAAGACAGAACCCAATCGAAGCAGGTCTTATATAAAGTTGAAACGACTCCGTTTCAGAGGGACTGTGAAGATTGAGCGTGTTCAATCGGATGTGAATATGGATGGTTCTGTTCCTAAATTAGAAGGAGTTTTTTCTATCGTTGTAGTCGTGGATCGTAAACCCCACTTGGGTCCGACTGGTAGTCTTCATACATTCGACGAACTATTTGGTGCAATGATCCATAGTCATGGTAATCTTAGCATAACCCCGTCTCTGAAAGATCGGTTCTATATTCGACACGTGTTCAAACGTGTGATATCTGTTGATAAGGATACGACAATGTTTGACGTGGGAGGGTCTACTACGCTCTCTAATAGGCGATTCAATTGTTGGGCATCGTTTAAGGATTTTGATTGTGACTCAAGCAAGGGTGTATATGACAATATCAGCAAGAACGCTCTATTAGTTTATTATTGTTGGATGTCAGATACTATGTCTAAGGCATCGAATTTTGTATCGTTTGAACTCGATTATATCGGATGA |
|
Protein Sequence
|
MNMYPFRNKRGSSFTQRRYYPRNTVFNRLTASKRHDVKLRLGHMNKPTDEPKMSAQRIHENQYSPEFVMSQNSAISTFISYPNLGKTEPNRSRSYIKLKRLRFRGTVKIERVQSDVNMDGSVPKLEGVFSIVVVVDRKPHLGPTGSLHTFDELFGAMIHSHGNLSITPSLKDRFYIRHVFKRVISVDKDTTMFDVGGSTTLSNRRFNCWASFKDFDCDSSKGVYDNISKNALLVYYCWMSDTMSKASNFVSFELDYIG |
|
NCBI Accession
|
YP_004064944.1
|
|
Location
|
183-938 |
|
Gene Name
|
CP |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGACTAAGCGCGATTCATCTTGGCGCTCGATTGGTGGAACCTCAAAGGTTCGTCGCACGTTGAATTTCTCCCCACGTGGAGGTGGTGGCCCAAAACAGACACGGGCCTCAGAATGGGTTAACAGGCCTATGTACAGGAAGCCCTTGATCTATCGGACTATACGAACGCCCGACGTTCCCAGAGGTTGTGAAGGCCCGTGCAAGGTCCAGTCCTATGAACAGCGTCATGATATCTCTCACGTCGGGAAGGTGATGTGTATTTCTGATGTCACTCGTGGTAATGGTATTACCCACCGTGTGGGTAAGCGTTTTTGTGTTAAGTCTGTCTATATTTTAGGGAAGATATGGATGGATGAGAACATCAAGCTTAAGAACCACACGAACAGTGTCATGTTCTGGTTGGTCAGGGACCGTCGACCCTATGGCACTCCTATGGATTTCGGTCAGGTGTTCAACATGTATGACAATGAGCCTAGTACAGCTACGATCAAGAACGATCTCCGTGATCGTCATCAGGTTATGCACAGGTTCTATGGTAAGGTCACAGGTGGTCAATATGCCAGCAACGAGCAAGCTTTGGTTAGGCGATTCTGGAAGGTCAACAATCATGTAGAGTACAACCATCAAGAAGCTGGGAAATACGAGAATCATACGGAGAACGCCTTATTATTGTATATGGCATGTACTCATGCCTCTAACCCCGTGTATGCGACATTGAAAATTCGGATCTATTTTTATGATTCGATAACAAATTAA |
|
Protein Sequence
|
MTKRDSSWRSIGGTSKVRRTLNFSPRGGGGPKQTRASEWVNRPMYRKPLIYRTIRTPDVPRGCEGPCKVQSYEQRHDISHVGKVMCISDVTRGNGITHRVGKRFCVKSVYILGKIWMDENIKLKNHTNSVMFWLVRDRRPYGTPMDFGQVFNMYDNEPSTATIKNDLRDRHQVMHRFYGKVTGGQYASNEQALVRRFWKVNNHVEYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSITN |
|
NCBI Accession
|
YP_004064945.1
|
|
Location
|
935-1333 |
|
Gene Name
|
REn |
|
Protein Name
|
replication enhancer |
|
Coding Region
|
ATGGTTTCACGCACAGGGGAACTCATCACTGCACGTCAGGCAGAGAATGGCGTGTATATCTGGGAGATAGAAAATCCCCTCTATTTCAAGATATACTGGGTAGAGGACCAGATATACACCAGAACCAGAGTGTACCACATACAGATACGATTCAACCACAACCTGAGGAGAGCGTTGGGTCTCCACAAAGCCTACCTGAACTTCCAAGTTTGGACGACATCGATGACAGCTTCTGGGTCAACTTATTTAGCTAGATTTGGACAATTAGTAAATGAGTACTTGTACCAATTAGGTGTAATTGGAATAAACAATGTAATTAGAGCTGTTCGTTTTGCAACAGCCAAACCATATGTAACTCATGTGCTTGAAAATCATGAAATAAAATTTAAATTTTATTAA |
|
Protein Sequence
|
MVSRTGELITARQAENGVYIWEIENPLYFKIYWVEDQIYTRTRVYHIQIRFNHNLRRALGLHKAYLNFQVWTTSMTASGSTYLARFGQLVNEYLYQLGVIGINNVIRAVRFATAKPYVTHVLENHEIKFKFY |
|
NCBI Accession
|
YP_004064946.1
|
|
Location
|
1080-1469 |
|
Gene Name
|
TrAP |
|
Protein Name
|
transcriptional activator protein |
|
Coding Region
|
ATGCCAAATTCATCACCCTCACAGCCCCCCTCTATCAAGAAGGCACACAGGCAATCCAAGAGGCGGGCAATCAGGAGGCGCAGGATTGATCTAAATTGCGGGTGCTCCATTTACTTCCACATCAACTGCACGGGACATGGTTTCACGCACAGGGGAACTCATCACTGCACGTCAGGCAGAGAATGGCGTGTATATCTGGGAGATAGAAAATCCCCTCTATTTCAAGATATACTGGGTAGAGGACCAGATATACACCAGAACCAGAGTGTACCACATACAGATACGATTCAACCACAACCTGAGGAGAGCGTTGGGTCTCCACAAAGCCTACCTGAACTTCCAAGTTTGGACGACATCGATGACAGCTTCTGGGTCAACTTATTTAGCTAG |
|
Protein Sequence
|
MPNSSPSQPPSIKKAHRQSKRRAIRRRRIDLNCGCSIYFHINCTGHGFTHRGTHHCTSGREWRVYLGDRKSPLFQDILGRGPDIHQNQSVPHTDTIQPQPEESVGSPQSLPELPSLDDIDDSFWVNLFS |
|
NCBI Accession
|
YP_004064947.1
|
|
Location
|
1381-2466 |
|
Gene Name
|
Rep |
|
Protein Name
|
replication-associated protein |
|
Coding Region
|
ATGCCATCGATTAAACGTTTCAAAATAAATGCCAAAAACTATTTTATCACTTATCCAGGCTGCTCCCTCACCAAAGAAGAGGCACTTTCCCAATTGCTAAACCTCTCCACGCCAGTGAATAAGAAGTTCATCAAAATTTGCAGAGAGCTCCATCAAAATGGGAAGCCTCATCTCCATGTGCCCATGCAATTCGAGGGAAAATATGCATGCAAGAATAACAGATTCTTCGATCTGGCCTCCCCAACCAGGTCAGCACATTTCCATCCAAACATACAGGGAGCTAAATCCAGCTCCGACGTCAAGTCCTACATCGCAAAGGACGGAGATACACTGGAATGGGGAGAATTCCAGATCGACGGCAGAAGTGCTAGAGGAGGCTGCCAGTCTGCTAATGATTCATATGCCAAGGCGTTAAATGCAGATTCCGTTGAATCTGCCATGGCGGTTTTAAAAGAAGAACAGCCAAAAGATTTCGTTTTGCAGAATCATAACATCCGTGCCAACTTAGAAAGGATATTCGCTAAGGCTCCGGAGCCATGGTCTCCTCCGTTTCCCCTCTCCTCTTTCAATGCCGTTCCAGACGAGATGCAAGCATGGTCAGACGGTTATTTTGGAACAGATGCCGCTGCGCGGCCGGAGAGGCCTGTGAGTATCATAATTGAAGGCGACTCGAGGACAGGGAAGACGATGTGGGCTCGTGCCTTAGGCCCACACAATTATCTCAGTGGACACTTAGACTTCAATTCCCGGGTCTTTTCAAATGAAGTGGAATATAACGTCATTGATGACGTCGCACCGCAATATCTAAAGCTAAAGCACTGGAAAGAACTTCTGGGGGCCCAGAAGGACTGGCAGTCAAATTGCAAATACGGCAAGCCAGTTCAAATTAAAGGAGGGATCCCATCAATCGTGCTTTGCAATCCTGGTGAGGGTGCCAGCTATAAAGATTTCCTGAACAAAGAGGAAAACACAGGTCTCAGGAACTGGACCATCAAGAATGCCAAATTCATCACCCTCACAGCCCCCCTCTATCAAGAAGGCACACAGGCAATCCAAGAGGCGGGCAATCAGGAGGCGCAGGATTGA |
|
Protein Sequence
|
MPSIKRFKINAKNYFITYPGCSLTKEEALSQLLNLSTPVNKKFIKICRELHQNGKPHLHVPMQFEGKYACKNNRFFDLASPTRSAHFHPNIQGAKSSSDVKSYIAKDGDTLEWGEFQIDGRSARGGCQSANDSYAKALNADSVESAMAVLKEEQPKDFVLQNHNIRANLERIFAKAPEPWSPPFPLSSFNAVPDEMQAWSDGYFGTDAAARPERPVSIIIEGDSRTGKTMWARALGPHNYLSGHLDFNSRVFSNEVEYNVIDDVAPQYLKLKHWKELLGAQKDWQSNCKYGKPVQIKGGIPSIVLCNPGEGASYKDFLNKEENTGLRNWTIKNAKFITLTAPLYQEGTQAIQEAGNQEAQD |
|
NCBI Accession
|
YP_004064948.1
|
|
Location
|
2052-2309 |
|
Gene Name
|
AC4 |
|
Protein Name
|
AC4 |
|
Coding Region
|
ATGGGAAGCCTCATCTCCATGTGCCCATGCAATTCGAGGGAAAATATGCATGCAAGAATAACAGATTCTTCGATCTGGCCTCCCCAACCAGGTCAGCACATTTCCATCCAAACATACAGGGAGCTAAATCCAGCTCCGACGTCAAGTCCTACATCGCAAAGGACGGAGATACACTGGAATGGGGAGAATTCCAGATCGACGGCAGAAGTGCTAGAGGAGGCTGCCAGTCTGCTAATGATTCATATGCCAAGGCGTTAA |
|
Protein Sequence
|
MGSLISMCPCNSRENMHARITDSSIWPPQPGQHISIQTYRELNPAPTSSPTSQRTEIHWNGENSRSTAEVLEEAASLLMIHMPRR |