Sida golden mottle virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_000888355.1 |
| Isolate |
USA: Bradenton, Florida |
| Release date |
2015/2/22 |
| Submitter |
Al-Aqeel,H.A., Polston,J.E. |
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
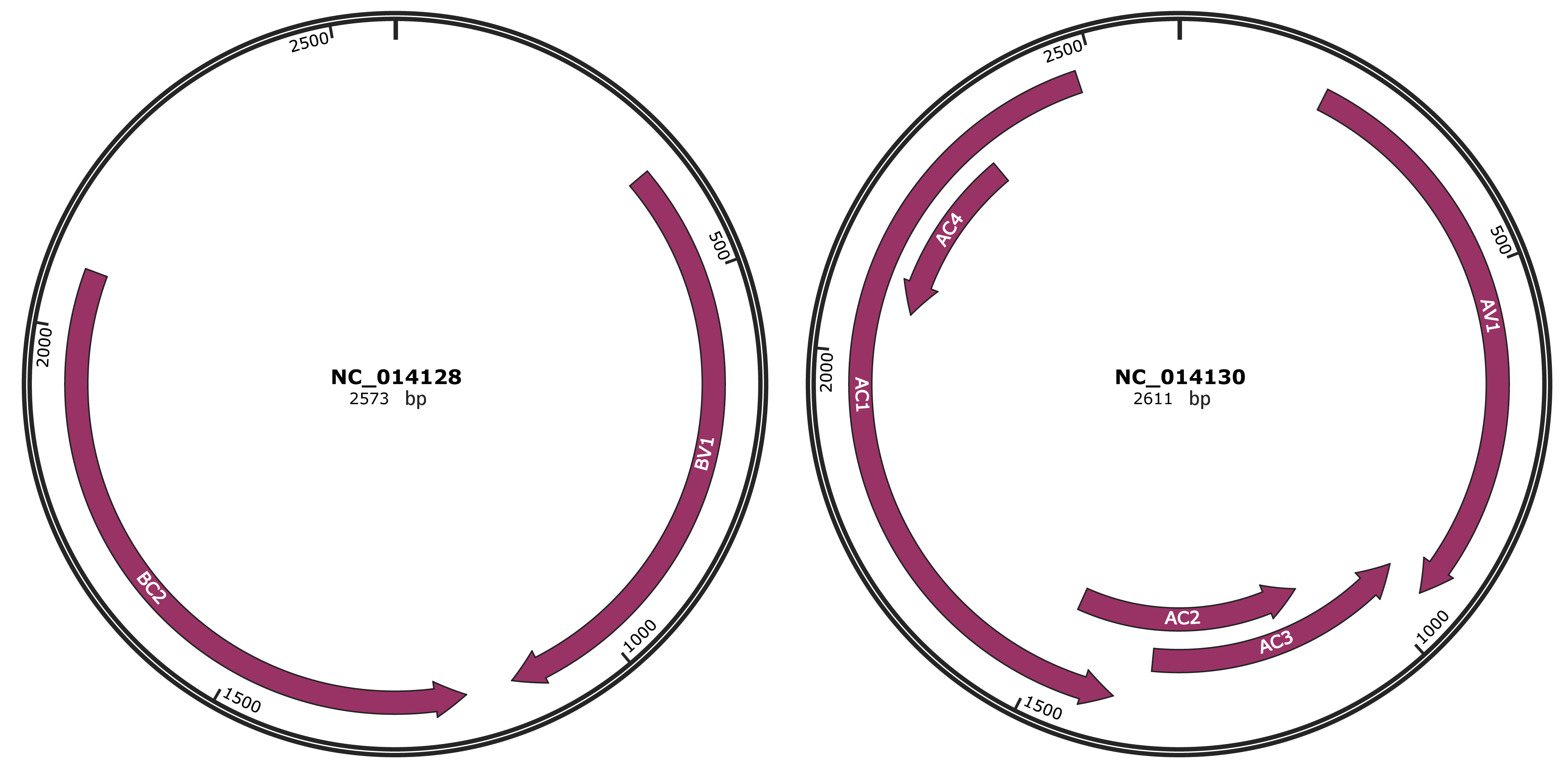
JBrowse
Genome
ACCGGATGGCCGCGCGCCCCCCCCCCCCTCACGCGCGCTCCCCTGGTGCTGTTCTGGTACGCGCTCTCTCATTGGTGCTGGTCCTTCACGCGCCTTTGTTTGAGTGGCCTTTAATTCAAATTAAAGGATAATACTTTCTCGCGCGAATGGCTTTTATGATTTGAATTATTGTCGCGCGATGACTGACTATGGCCCATTGTACTATGTGAAGGACGTGGCTATATTTGGACCATGTCGCTGAGTTTATTTGTGTCTAACGTTAAATGAATTGTCTATAAAATTAAGTGGTCATGTGCGTCATGTACAACCAACTCAGCGTTTAACCACGTTTATATTGTTTAGTCCATTATTATTGTATGATAATGTATCCTTCTAAGATTAAACGTGGTTTTTATTATCCTTATCGACGATTTAATACACGTAGCAATTTGTTTAACCGTTCAACCGCTGTGAAACGACATGATGCGAGACGTCGAAGAGGTCGATCTGTCAAGCCCACTGATGAGCCCAAGATGTCGGCCCAATCCATACATGAGAATCAGTATGGCTCTGATTTTGTCATGGCCCATAATTCAGCTATCTCTACGTTCATCAGTTTCCCAGACTTGGGCAAGATGGAACCGGGTCGAAGTAGGTCATATATCAAGTTGAAACGACTTCGTTTCAAAGGGACTGTGAAGATTGAACGTGTGCAATCGGATCTGAACATGGACGGGACTGTCCCCAAAATTGAAGGAGTTTTCTCCCTTGTTGTTGTTGTGGATCGTAAACCCCACTTGGGTCCAAGTGGTTGTCTGCATACATTTGACGAGTTGTTCGGAGCAATCATTCACAGTCATGGCAATCTCAGCATTGTCCCTTCTCTGAAAGACCGTTATTATATTCGCCACGTGTTCAAACGTGTATTGTCATTGGAAAATGACACGCTGATGGTCGACGTCGAAGGATCTACTTCTCTATCTGACAGGCGTTTTAATTGTTGGTCCACTTTTAAAGACGTGGATCGTGATTCATGCAAGGGTGTTTATGATAATATAAGCAAGAACGCTCTGCTAATTTATTATTGCTGGGTGTCCGAAACGCCTTCAAAGGCCTCTAATTATGTATCTTTTGATCTTGACTATGTTGGCTAACTCAATAAAATTTGTTTAACCAAATTTATTTATCTTATTATGATATATCAAAAGATAACATTTATTTCAGTGATTTGGCCTGATTAACCTGACAATTACTATTAATACATTCCCGGACTGTAGTTCTGACTATCTCATTCAACTGGCCCATTGACATTGTGATGTTTGACTCCGCTCTCTGGGCTCCCACAATGGAAGCAGACTCTCCTGGGTCTAGAACGCTGGTCCCCAGTCTGTTTAGGTGTCTGTATGGATAGAGTTCGTTCTCCACTTCTGATTCCGCATCTGACTGGGCCGTTCCTATTGTACTTCTGGAAGCCCATGATTCACCAGGCCTGATCTCGATTGGGCCGCGTAACCCAACCCTGGACATGGACGCGCATCTGATGGGCTTCCTCTCCCATTTCCCATAGTCCACATGAGAAAAGTCCACATCTTTGTCTGTGAACTGTTTGGACAGGATCTTCACTGTTGGTGCCCGGAAGGGGATGTCGACCGAGTGTTTTGCTGTGGACAATTTCAGTTTCCCTTTGAATTTGGCGAAGTGAGTCCGTTGATGAACATTTGTATCGCAAACGCGATAGTACAACTTCCATGGAATTGGGTCTTTTAATGAGAAGAACGAAGCCGAGAAATAGTGGAGATCTATGTTGCACCTGATCGGAAAAGTCCACGACGCCTGTAAAGACTCATTGTCTGTCATTCTTTTGTCGTGAATCTCCACGATTACTGACCCTGTGGCGTTGATCGGAACTTGTTGTCTGTATTCTATGACGCAATGGTCTATCTTCATGCAGCTACGACTGAGTCTAGCTGTTAATTGCGACGCCGTTGAAGGAAATTGCAGTATTATCTCAGTTAGGTCATGAGAAAGTTGATACTCGTCTCGGTGAGATTCTATGTAATTGAAAGCGTTCGGAGGATTGACCAACTGAGAATCCATATGAAGAAGAAAGGCCGCGCAGCGGAACTGATTGCTGAAGTTGAATCGGAAAGAAGATGAACAACTGACTATGAAGATGATCAAATCTGGAAAGCCCTCCTTTGATCTCGAAGGAGGTAAATGTATAACTTTCTATCTGGGTTTGAGAATTTCAGATGTTTAAGAAGATCAGTTGTTTCTGACGGTTTCTGTGTTTGAGAATGCTTGAATATGGAGATATATGAAGAATAATTGTTTTTGAGAAAGGAAAGAGTGTTTAGTAAGAGTTTAATAGAACTCAGAAAATGGAAGAGGTTGTATGTGATCCCAGACTTGTTGGGATTCTGGTATTTATATTGGTAAAGTGTTCATCCAGTGGTGGTATTTCTGTAAATATGGGATGTTCCCCCCTTAGCTCTCTCGCTCAAAAGTCTTAACAATTGGGGGAACTGGGGGAACTTATATAGTAGAAGTTCCATAAGGCAATGCAACACGTGGCGGCCATCCGTTATAATATT
ACCGGATGGCCGCGCGCCCCCCCTGATGCCGTACATTCACGCGCGATCTTTAATTTGAATTAAAGATGAACCAGACGCTCTCGTCCAATCATAACGCGTCTGACGAGCCTAAATATTTTGAACAACTTGGGCGCTAAGTTGTTGGGTAACCGTTATAAATTTAAAAGGATTTGGCCCACTTTCTTTAACTCAAAATGTCTAAGCGCGATGGCTCTTGGCGCTCTATGGAGGGAATTTCAAAAGTGAAACGTACTCTGAATTTCTCCCCTCGTGGAGGAGGTGGGCCAAAAATGTCAAGGGCCGCCGAATGGGTGAACAGGCCCATGTACAGGAAGCCCAGGATCTACCGGACGCTAAAGACACCTGGTGTGCCCAGAGGATGTGAAGGCCCGTGCAAGGTCCAGTCTTATGAACAGCGCCACGACATATCCCATGTGGGTAAGGTCATGTGCATCTCTGACGTGACACGTGGTAATGGCATTACCCATCGCGTGGGTAAGCGTTTTTGTGTTAAGTCTGTGTATATCCTTGGTAAGATCTGGATGGACGAGAACATCAAGCTCAAGAACCACACGAACAGTGTCATGTTCTGGTTGGTCAGAGACCGTAGACCCTATGGAACTCCAATGGATTTCGGCCAGGTGTTCAACATGTTCGACAACGAGCCAAGCACTGCTACGGTGAAGAATGATCTACGCGATCGTTACCAGGTCATGCACAAGTTCTATGGCAAGGTGACCGGTGGACAGTATGCCAGCAACGAGCAGGCTATAGTTAAGAGGTTCTGGAAGGTCTACAATCATGTGGTCTACAATCATCAAGAGGCTGGCAAGTACGAGAATCATACAGAGAACGCCCTGTTATTGTATATGGCATGTACTCATGCATCTAACCCCGTGTATGCAACGCTTAAGATCCGAATCTATTTCTACGATTCGATCACAAATTAATAAATTTTGAATTTTATTACATGATTTTCTGGAACATAAGTTACATACGATCTGTCTGTCGCGAATCGTACAGCTCTGATTACATTGTTAATTGAAATCACGCCTAACCTATCTAAATACAAATTAACTAAGCGCTTAAATCTAGCTAAATAAGTCGACCCAGAAGCTGTCATCGATATCGTCCAGACTTGGAAGTTCAGGAAGGCTTTGTGGAGATGCAACGCTTTCCTCAGGTTGTGGTTGAATCGTATTTGTAGCGTGTATATTCTGGTGTTCGTGTACAACGGGTCTTCTATTTGGTACATCGTGAAATAGAGGGGATTTTCTATCTCCCAGATATACACGCCATTCTCTGCCTGAGGTACAGTGATGAGTTCCCCTGTGCGTGAATCCATGCCCGGTGCAGCCTATGTGGAAGTAAATGGAGCAACCGCACTCTAGATCAATCCGCCGTCTCCTGATGGCCCTCTTCTTGGCTTGCTTGTGTTTCTGTTTGATAGAGGGCGGATGTGAGGGTGATGAAGAGCGCATTCTTCAGGGTCCAATTCTTTAGACCTGTGTTTTCCTCTTTGTCTAGGAAGTCTTTATAGCTGGCACCCTCACCCGGATTGCAAAGCACGATTGATGGAATCCCGCCTTTAATTTGAACTGGTTTGCCGTATTTGCAATTTGACTGCCAGTCCTTCTGGGCCCCCAGAAGTTCTTTCCAGTGCTTCAACTTTAGATAGTGCGGTGCGACGTCATCAATGACGTTATACTCCACTTCATTTGAATATACCCGGGGATTGAAGTCCAGATGTCCACTGAGATAATTATGTGGGCCTAACGCACGAGCCCACATTGTCTTACCTGTCCTTGAGTCACCTTCCACTATGATACTTACTGGTCTATCTGGCCGCGCAGCGGAACCTCTCCCAAAATAACTGTCCGCCCAGTCTTGCATTTCTTCAGGAACGGCAGTGAAAGAGGAGAGGGGAAACGGAGGAGACCATGGATCCGGAGACTTACTGAAAATCCTATCGAGGTTACTGGATAGGTTGTGATATTGGAAAAGATATTTTTCCGGCAACTTTTCTCTGATGATTTTCAGTGCCGCCTCCTTTGTTCCAGAATTCAATGCCTCGGCGGCTGCATCATTAGATGTTTGCTGACCTCCGCGAGCACTTCTTCCGTCGATCTGGAACACTCCCCATTCAATGGTGTCCCCGTCTTTCTCGACGTAGGACTTGACGTCGGAGCTGGATTTAGCTCCCTGTATGTTCGGATGGAAATGTACTGAACTGGTTGGGGACACCAGATCGAAGAATCTGTTATTCGTGCAGTTGTACTTCCCCTCGAACTGGATGAGCACATGGATATGAGGCTCCCCATTTTCGTGAAGCTCTCTGCAAATTTTGATGAACTTCTTGTTCACCGGAGTATTTAATGTTTGTAATTGGGAAAGTGCTTCCTCTTTGGTGATGGAGCACTGCGGATATGTGAGGAAATAGTTTTTGGCTTTAACTGAGAAAGAACCCTTTCGTGGCATTTTTGTAAATATAGGATGTTCCCCCCTTAGCTCTCTCGCTCAAAAGTCTAGACAATTGGGGGAACTGGGGGAACTTATATAGTAGAAGTTCCTAAAGGCAATGCAACACGTGGCGGCCATCCGTTATAATATT
Gene Information
|
NCBI Accession
|
YP_003620403.1
|
|
Location
|
357-1133 |
|
Gene Name
|
BV1 |
|
Protein Name
|
NSP |
|
Coding Region
|
ATGATAATGTATCCTTCTAAGATTAAACGTGGTTTTTATTATCCTTATCGACGATTTAATACACGTAGCAATTTGTTTAACCGTTCAACCGCTGTGAAACGACATGATGCGAGACGTCGAAGAGGTCGATCTGTCAAGCCCACTGATGAGCCCAAGATGTCGGCCCAATCCATACATGAGAATCAGTATGGCTCTGATTTTGTCATGGCCCATAATTCAGCTATCTCTACGTTCATCAGTTTCCCAGACTTGGGCAAGATGGAACCGGGTCGAAGTAGGTCATATATCAAGTTGAAACGACTTCGTTTCAAAGGGACTGTGAAGATTGAACGTGTGCAATCGGATCTGAACATGGACGGGACTGTCCCCAAAATTGAAGGAGTTTTCTCCCTTGTTGTTGTTGTGGATCGTAAACCCCACTTGGGTCCAAGTGGTTGTCTGCATACATTTGACGAGTTGTTCGGAGCAATCATTCACAGTCATGGCAATCTCAGCATTGTCCCTTCTCTGAAAGACCGTTATTATATTCGCCACGTGTTCAAACGTGTATTGTCATTGGAAAATGACACGCTGATGGTCGACGTCGAAGGATCTACTTCTCTATCTGACAGGCGTTTTAATTGTTGGTCCACTTTTAAAGACGTGGATCGTGATTCATGCAAGGGTGTTTATGATAATATAAGCAAGAACGCTCTGCTAATTTATTATTGCTGGGTGTCCGAAACGCCTTCAAAGGCCTCTAATTATGTATCTTTTGATCTTGACTATGTTGGCTAA |
|
Protein Sequence
|
MIMYPSKIKRGFYYPYRRFNTRSNLFNRSTAVKRHDARRRRGRSVKPTDEPKMSAQSIHENQYGSDFVMAHNSAISTFISFPDLGKMEPGRSRSYIKLKRLRFKGTVKIERVQSDLNMDGTVPKIEGVFSLVVVVDRKPHLGPSGCLHTFDELFGAIIHSHGNLSIVPSLKDRYYIRHVFKRVLSLENDTLMVDVEGSTSLSDRRFNCWSTFKDVDRDSCKGVYDNISKNALLIYYCWVSETPSKASNYVSFDLDYVG |
|
NCBI Accession
|
YP_003620404.1
|
|
Location
|
1195-2076 |
|
Gene Name
|
BC2 |
|
Protein Name
|
MP |
|
Coding Region
|
ATGGATTCTCAGTTGGTCAATCCTCCGAACGCTTTCAATTACATAGAATCTCACCGAGACGAGTATCAACTTTCTCATGACCTAACTGAGATAATACTGCAATTTCCTTCAACGGCGTCGCAATTAACAGCTAGACTCAGTCGTAGCTGCATGAAGATAGACCATTGCGTCATAGAATACAGACAACAAGTTCCGATCAACGCCACAGGGTCAGTAATCGTGGAGATTCACGACAAAAGAATGACAGACAATGAGTCTTTACAGGCGTCGTGGACTTTTCCGATCAGGTGCAACATAGATCTCCACTATTTCTCGGCTTCGTTCTTCTCATTAAAAGACCCAATTCCATGGAAGTTGTACTATCGCGTTTGCGATACAAATGTTCATCAACGGACTCACTTCGCCAAATTCAAAGGGAAACTGAAATTGTCCACAGCAAAACACTCGGTCGACATCCCCTTCCGGGCACCAACAGTGAAGATCCTGTCCAAACAGTTCACAGACAAAGATGTGGACTTTTCTCATGTGGACTATGGGAAATGGGAGAGGAAGCCCATCAGATGCGCGTCCATGTCCAGGGTTGGGTTACGCGGCCCAATCGAGATCAGGCCTGGTGAATCATGGGCTTCCAGAAGTACAATAGGAACGGCCCAGTCAGATGCGGAATCAGAAGTGGAGAACGAACTCTATCCATACAGACACCTAAACAGACTGGGGACCAGCGTTCTAGACCCAGGAGAGTCTGCTTCCATTGTGGGAGCCCAGAGAGCGGAGTCAAACATCACAATGTCAATGGGCCAGTTGAATGAGATAGTCAGAACTACAGTCCGGGAATGTATTAATAGTAATTGTCAGGTTAATCAGGCCAAATCACTGAAATAA |
|
Protein Sequence
|
MDSQLVNPPNAFNYIESHRDEYQLSHDLTEIILQFPSTASQLTARLSRSCMKIDHCVIEYRQQVPINATGSVIVEIHDKRMTDNESLQASWTFPIRCNIDLHYFSASFFSLKDPIPWKLYYRVCDTNVHQRTHFAKFKGKLKLSTAKHSVDIPFRAPTVKILSKQFTDKDVDFSHVDYGKWERKPIRCASMSRVGLRGPIEIRPGESWASRSTIGTAQSDAESEVENELYPYRHLNRLGTSVLDPGESASIVGAQRAESNITMSMGQLNEIVRTTVRECINSNCQVNQAKSLK |
|
NCBI Accession
|
YP_003620405.1
|
|
Location
|
195-950 |
|
Gene Name
|
AV1 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGTCTAAGCGCGATGGCTCTTGGCGCTCTATGGAGGGAATTTCAAAAGTGAAACGTACTCTGAATTTCTCCCCTCGTGGAGGAGGTGGGCCAAAAATGTCAAGGGCCGCCGAATGGGTGAACAGGCCCATGTACAGGAAGCCCAGGATCTACCGGACGCTAAAGACACCTGGTGTGCCCAGAGGATGTGAAGGCCCGTGCAAGGTCCAGTCTTATGAACAGCGCCACGACATATCCCATGTGGGTAAGGTCATGTGCATCTCTGACGTGACACGTGGTAATGGCATTACCCATCGCGTGGGTAAGCGTTTTTGTGTTAAGTCTGTGTATATCCTTGGTAAGATCTGGATGGACGAGAACATCAAGCTCAAGAACCACACGAACAGTGTCATGTTCTGGTTGGTCAGAGACCGTAGACCCTATGGAACTCCAATGGATTTCGGCCAGGTGTTCAACATGTTCGACAACGAGCCAAGCACTGCTACGGTGAAGAATGATCTACGCGATCGTTACCAGGTCATGCACAAGTTCTATGGCAAGGTGACCGGTGGACAGTATGCCAGCAACGAGCAGGCTATAGTTAAGAGGTTCTGGAAGGTCTACAATCATGTGGTCTACAATCATCAAGAGGCTGGCAAGTACGAGAATCATACAGAGAACGCCCTGTTATTGTATATGGCATGTACTCATGCATCTAACCCCGTGTATGCAACGCTTAAGATCCGAATCTATTTCTACGATTCGATCACAAATTAA |
|
Protein Sequence
|
MSKRDGSWRSMEGISKVKRTLNFSPRGGGGPKMSRAAEWVNRPMYRKPRIYRTLKTPGVPRGCEGPCKVQSYEQRHDISHVGKVMCISDVTRGNGITHRVGKRFCVKSVYILGKIWMDENIKLKNHTNSVMFWLVRDRRPYGTPMDFGQVFNMFDNEPSTATVKNDLRDRYQVMHKFYGKVTGGQYASNEQAIVKRFWKVYNHVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSITN |
|
NCBI Accession
|
YP_003620406.1
|
|
Location
|
947-1345 |
|
Gene Name
|
AC3 |
|
Protein Name
|
REn |
|
Coding Region
|
ATGGATTCACGCACAGGGGAACTCATCACTGTACCTCAGGCAGAGAATGGCGTGTATATCTGGGAGATAGAAAATCCCCTCTATTTCACGATGTACCAAATAGAAGACCCGTTGTACACGAACACCAGAATATACACGCTACAAATACGATTCAACCACAACCTGAGGAAAGCGTTGCATCTCCACAAAGCCTTCCTGAACTTCCAAGTCTGGACGATATCGATGACAGCTTCTGGGTCGACTTATTTAGCTAGATTTAAGCGCTTAGTTAATTTGTATTTAGATAGGTTAGGCGTGATTTCAATTAACAATGTAATCAGAGCTGTACGATTCGCGACAGACAGATCGTATGTAACTTATGTTCCAGAAAATCATGTAATAAAATTCAAAATTTATTAA |
|
Protein Sequence
|
MDSRTGELITVPQAENGVYIWEIENPLYFTMYQIEDPLYTNTRIYTLQIRFNHNLRKALHLHKAFLNFQVWTISMTASGSTYLARFKRLVNLYLDRLGVISINNVIRAVRFATDRSYVTYVPENHVIKFKIY |
|
NCBI Accession
|
YP_003620407.1
|
|
Location
|
1092-1481 |
|
Gene Name
|
AC2 |
|
Protein Name
|
TrAP |
|
Coding Region
|
ATGCGCTCTTCATCACCCTCACATCCGCCCTCTATCAAACAGAAACACAAGCAAGCCAAGAAGAGGGCCATCAGGAGACGGCGGATTGATCTAGAGTGCGGTTGCTCCATTTACTTCCACATAGGCTGCACCGGGCATGGATTCACGCACAGGGGAACTCATCACTGTACCTCAGGCAGAGAATGGCGTGTATATCTGGGAGATAGAAAATCCCCTCTATTTCACGATGTACCAAATAGAAGACCCGTTGTACACGAACACCAGAATATACACGCTACAAATACGATTCAACCACAACCTGAGGAAAGCGTTGCATCTCCACAAAGCCTTCCTGAACTTCCAAGTCTGGACGATATCGATGACAGCTTCTGGGTCGACTTATTTAGCTAG |
|
Protein Sequence
|
MRSSSPSHPPSIKQKHKQAKKRAIRRRRIDLECGCSIYFHIGCTGHGFTHRGTHHCTSGREWRVYLGDRKSPLFHDVPNRRPVVHEHQNIHATNTIQPQPEESVASPQSLPELPSLDDIDDSFWVDLFS |
|
NCBI Accession
|
YP_003620408.1
|
|
Location
|
1393-2478 |
|
Gene Name
|
AC1 |
|
Protein Name
|
REP protein |
|
Coding Region
|
ATGCCACGAAAGGGTTCTTTCTCAGTTAAAGCCAAAAACTATTTCCTCACATATCCGCAGTGCTCCATCACCAAAGAGGAAGCACTTTCCCAATTACAAACATTAAATACTCCGGTGAACAAGAAGTTCATCAAAATTTGCAGAGAGCTTCACGAAAATGGGGAGCCTCATATCCATGTGCTCATCCAGTTCGAGGGGAAGTACAACTGCACGAATAACAGATTCTTCGATCTGGTGTCCCCAACCAGTTCAGTACATTTCCATCCGAACATACAGGGAGCTAAATCCAGCTCCGACGTCAAGTCCTACGTCGAGAAAGACGGGGACACCATTGAATGGGGAGTGTTCCAGATCGACGGAAGAAGTGCTCGCGGAGGTCAGCAAACATCTAATGATGCAGCCGCCGAGGCATTGAATTCTGGAACAAAGGAGGCGGCACTGAAAATCATCAGAGAAAAGTTGCCGGAAAAATATCTTTTCCAATATCACAACCTATCCAGTAACCTCGATAGGATTTTCAGTAAGTCTCCGGATCCATGGTCTCCTCCGTTTCCCCTCTCCTCTTTCACTGCCGTTCCTGAAGAAATGCAAGACTGGGCGGACAGTTATTTTGGGAGAGGTTCCGCTGCGCGGCCAGATAGACCAGTAAGTATCATAGTGGAAGGTGACTCAAGGACAGGTAAGACAATGTGGGCTCGTGCGTTAGGCCCACATAATTATCTCAGTGGACATCTGGACTTCAATCCCCGGGTATATTCAAATGAAGTGGAGTATAACGTCATTGATGACGTCGCACCGCACTATCTAAAGTTGAAGCACTGGAAAGAACTTCTGGGGGCCCAGAAGGACTGGCAGTCAAATTGCAAATACGGCAAACCAGTTCAAATTAAAGGCGGGATTCCATCAATCGTGCTTTGCAATCCGGGTGAGGGTGCCAGCTATAAAGACTTCCTAGACAAAGAGGAAAACACAGGTCTAAAGAATTGGACCCTGAAGAATGCGCTCTTCATCACCCTCACATCCGCCCTCTATCAAACAGAAACACAAGCAAGCCAAGAAGAGGGCCATCAGGAGACGGCGGATTGA |
|
Protein Sequence
|
MPRKGSFSVKAKNYFLTYPQCSITKEEALSQLQTLNTPVNKKFIKICRELHENGEPHIHVLIQFEGKYNCTNNRFFDLVSPTSSVHFHPNIQGAKSSSDVKSYVEKDGDTIEWGVFQIDGRSARGGQQTSNDAAAEALNSGTKEAALKIIREKLPEKYLFQYHNLSSNLDRIFSKSPDPWSPPFPLSSFTAVPEEMQDWADSYFGRGSAARPDRPVSIIVEGDSRTGKTMWARALGPHNYLSGHLDFNPRVYSNEVEYNVIDDVAPHYLKLKHWKELLGAQKDWQSNCKYGKPVQIKGGIPSIVLCNPGEGASYKDFLDKEENTGLKNWTLKNALFITLTSALYQTETQASQEEGHQETAD |
|
NCBI Accession
|
YP_003620409.1
|
|
Location
|
2064-2321 |
|
Gene Name
|
AC4 |
|
Protein Name
|
AC4 |
|
Coding Region
|
ATGGGGAGCCTCATATCCATGTGCTCATCCAGTTCGAGGGGAAGTACAACTGCACGAATAACAGATTCTTCGATCTGGTGTCCCCAACCAGTTCAGTACATTTCCATCCGAACATACAGGGAGCTAAATCCAGCTCCGACGTCAAGTCCTACGTCGAGAAAGACGGGGACACCATTGAATGGGGAGTGTTCCAGATCGACGGAAGAAGTGCTCGCGGAGGTCAGCAAACATCTAATGATGCAGCCGCCGAGGCATTGA |
|
Protein Sequence
|
MGSLISMCSSSSRGSTTARITDSSIWCPQPVQYISIRTYRELNPAPTSSPTSRKTGTPLNGECSRSTEEVLAEVSKHLMMQPPRH |