Sida golden mosaic virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_000837905.1 |
| Release date |
2015/2/12 |
| Submitter |
Abouzid,A.M., Polston,J.E., Hiebert,E. |
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
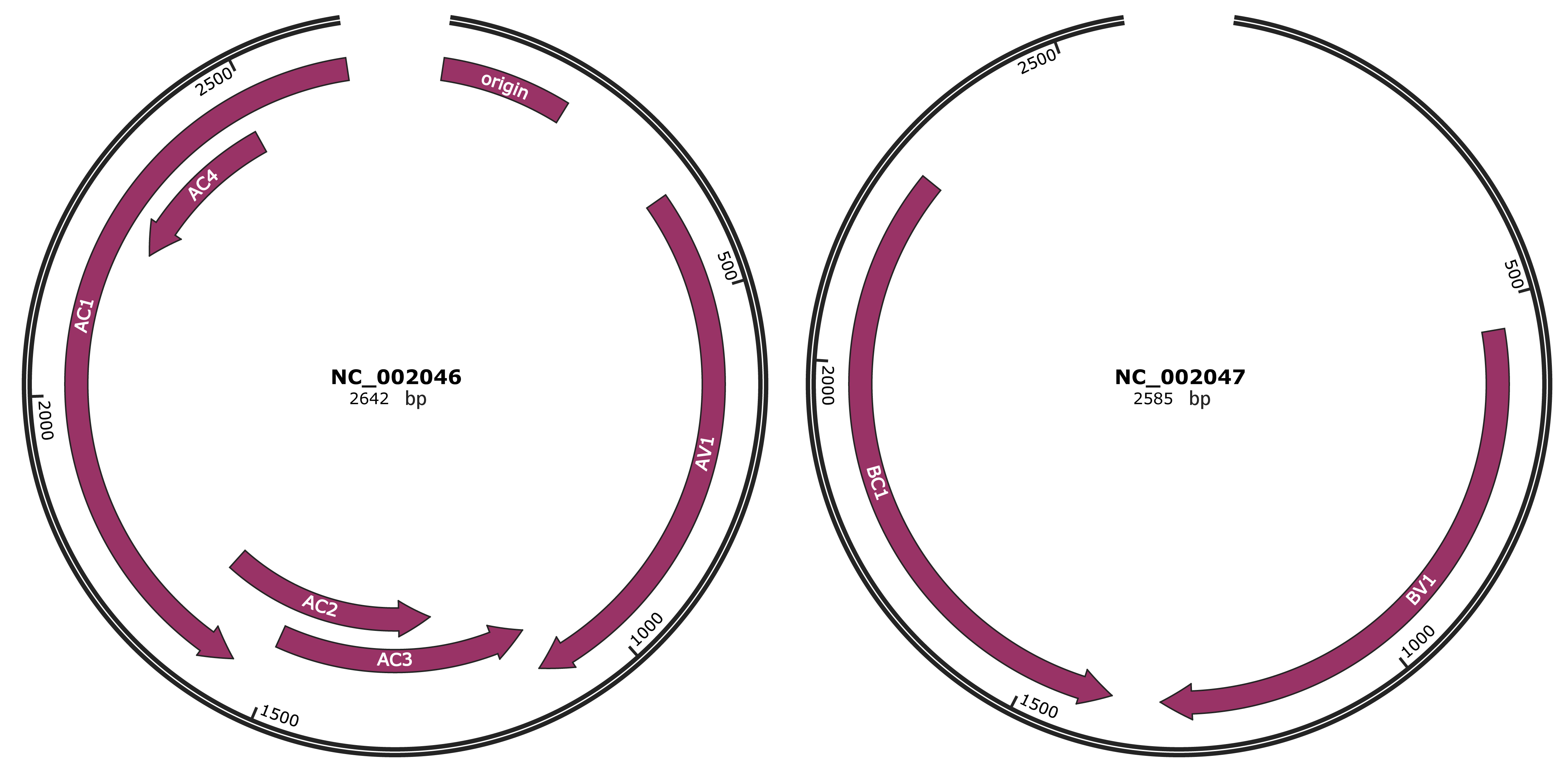
JBrowse
Genome
GGTGGCATTTTTGTAATAAGAAGTGGTACTCCAGTTGAGGTACTCCAATTGAGCCCCCTCAAACTTGCTCATTCAATTGGAGTATTAGAGTAACTTATATAGTAGAACCCTCTATAGAACTCTAAATCTGGTTCACACACGTGGCGGCCATCCGCTATAATATTACCGGATGGCCGCGCGCCCCCCTGGTGCCGTACACTCTCGCGCGATCTTTAATTTCAATTAAAGATGGTCCCAGACGCTTTCGTCCAATCAGGTCGCGTCTGACGAGTCTAGATATTTGCAACAACTTAGGGCCCAAGTTGTTGGGTGTCTGCTATAAATGAAAGAGACTTTGGCCCACTGCTTTTAACTCAAAATGCCTAAGCGCGAATTGCCATGGCGCTCTATGGCGGGAACCTCAAAGGTTAGCCGCAACGCTAATTATTCTCCTCGTGCAGGTAGTGGGCCAAGAGTTCACAAGGCCTCTGAATGGGTAAACAGGCCCATGTACAGGAAGCCCAGGATCTACCGGATGGTGAGGACCCCCGATGTGCCCAGAGGCTGTGAAGGCCCTTGCAAGGTCCAGTCTTATGAACAGCGTCACGACATCTCCCATGTCGGGAAGGTCATGTGCATTTCCGATGTGACACGTGGTAATGGCATTACCCACCGTGTGGGTAAGCGTTTCTGTGTTAAGTCTGTGTATATTCTAGGGAAGATTTGGATGGACGAGAACATTAAGCTGAAGAACCACACGAACAGTGTCATGTTCTGGTTGGTCAGAGACCGTAGACCGTATGGCACGCCTATGGATTTCGGTCAGGTGTTCAACATGTTCGATAACGAGCCTAGTACTGCCACGGTGAAGAACGATCTCCGTGATCGTTACCAGGTCATGCATAAGTTCTATGGCAAGGTCACTGGTGGACAGTATGCCAGCAACGAGCAGGCTATAGTGAAGAGATTCTGGAAGGTCAACAATCATGTGGTCTACAATCATCAAGAGGCTGGCAAGTATGAGAATCACACTGAGAACGCCCTGTTATTGTATATGGCATGTACCCATGCCTCTAATCCTGTGTATGCAACTCTGAAGATCCGAATCTATTTCTATGATTCGCTTATGAATTAATAAAATTTGAATTTTATTGAATGATTTTCCAGTACATGATTTACATACGCTCTGTCTGTCGCGAAACGTACAGCTCTAATTACATTGTTTAAGGAGATAATGCCTAATTGATCTAAGTACATGTTGACCAAACGCAGAAACCTAGCTAAATAAGTTGACCCAGAAGCTGTCATCGATGTCGTCCAAACTTGGAAGTTCAGGAAGGCTTTGTGGAGATGCAACGCTCTCCTCAGGTTGTGGTTGAACCTTATCTGTACGTGGTATATCCTCGTTCTGGTGTATAGCGGGTCCTCTACACTGTATATCCTGAAATAGAGGGGATTTTCTATCTCCCAGATATACACGCCATTCTCCGCCTGATGTGCAGTGATGAATTCCCCTGTGCGTGAATCCATGTCCCGTACAGCCTATGTGGAAGTAGATGGAGCACCCGCAATTTAGGTCAATTCTCCGCCTCCGTATGGCCCTCCTCTTGGCCTGCCTGTGTGCTTGCTTGATAGAGGGGGGCTGTGAGGGTGATGAAGATCGCATTCTTGATAGTCCAGTTCCTGAGACCTGTATTTTCCTCCTTGTCTAGGAACTCTTTATAGCTGGCACCCTCACCAGGATTGCAAAGCACGATTGCTGGGATTCCACCTTTAATTTGAACTGGCTTGCCGTATTTGCAATTTGACTGCCAATCTTTTTGGGCCCCCAGCAATTCTTTCCAGTGCTTTAGCTTTAGATATTGCGGTGCGACGTCATCAATGACGTTATACTCCACTTCGTTCGAATAGACTCGACCATTGAAGTCCAGGTGTCCACTGAGGTAATTATGTGGGCCTAACGCACGTGCCCACATCGTCTTCCCTGTTCTTGAATCACCTTCTACTATGAGACTTAATGGTCTGTCTGGCCGCGCAGCGGAACCCGAACCAAAAAATTCATCCGCCCATTCTTGCATCTCGTCGGGAACGTTAGTGAAAGAGGAGAGTTGAAATGGAGGAACCCACGGTTCCGGAGCCTTGGCGAATATCCTCTCTAAGTTGGAGCGGATGTTATGATTCTGCAAGACAAAATCTTTTGGCTGTTCTTCCCTTAAAACCGCTAAGGCAGATTGAACAGAATCTGCATTTAACGCCTTTGCATATGAATCATTAGCAGTCTGCTGGCCTCCTCTAGCTGATCTGCCGTCGATCTGGAACTCTCCCCATTCCACTGTATCACCGTCCTTGTCGATGTAAGACTTGACGTCGGAGCTGGATTTAGCTCCCTGTATGTTTGGATGGAAATGTGCTGACCTGGTTGGGGAGACCAGATCGAAGAATCTGTTATTCGTGCACTGGTATTTCCCTTCGAACTGTAAGAGCACATGGAGATGAGGCTCCCCATTTTCGTGAAGCTCTCTGCAGATTTTGATGAACTTCTTGTTCACTGTGGTATTTAGGCTTTGTAATTGGGAAAGTGCTTCTTCTTTGGTCAGAGAGCACTGTGGATAAGTGACCAAATAGTTTTTGGACTGAACTCTAAATTTCTTTGGCGGTGGCAT
TGGCATTCTTGTAATAAGAAGTGGGACTCCAGTTGAGGGACTCCAATTGAGCTCTCTCAAACTTGCTCATTCAATTGGAGTATTAGAGTCTCATATATAGTAGAACCCTCTATAGAACTCTCAATCTGGTTCACACACGTGGCGGCCATCCGCTATAATATTACCGGATGGCCGCGCTTTGGAGTACGCTCCCTCCACCGCTCCCCCCATGGTGCCGCTCTCACACGCGCTCTCTCATTGGTGCTGGTGCCTCTCCATTTTTTATTGACTGCCCTTTAATTTGAATTAAAGGGAGTACTGCTAGTCGCGCGAGTATACTTTAAATTTGAAAAATTTCCTCGCGTCTCTAGACTATGGCCCGTTGTACTACACGATCGACGTGGCGTTTTCTGGACCATGTTGCTGAGTCTGTTTAACCAATTTGAACCATCCCTTTGTATATAATGGAGGAGACCGACAGTCATATCGTATTTAGGCTGACTCAGCCTTCCACCGCGTTTAATTTGTCCATCCCAACCTGTGTTTAACCTTTGATTACCGCATGATAATGTATCCTGTGAGGGTTAAACGTGGTTATTACTTCCCTAACCGACGATTTACTACACGTAACACTGTGTTTAACCGTTCAACCGCTGGGAAACGACATGATGGGAGACGTCGAGGAGGTCGATCTGTCAAGACCAGTGATGAGCCCAAGATGTCAGCCCAATCCATACATGAGAATCAGTATGGCCCTGATTTTGTGATGTCTCACAATTCAGCCATTTCCACATTTATCAGTTATCCAGATCTGGGCAAGATAGAACCGGGTCGAAGTAGGTCCTATATCAAGTTGAAACGACTCCGTTTCAAAGGGACTGTTAAGATTGAACGTGTCACATCGGACGTGAACATGGACGGTTCTGCGCCAAAGGTCGAAGGAGTATTCTCACTGGTTGTGGTTGTGGATCGTAAACCCCACTTGACTGCATCTGGTGGTCTACATACATTCGACGAGCTGTTCGGTGCAAGGATCCACAGCCATGGTAATCTCAGCATAACCCCTTCCCTGAAAGACCGCTTTTACGTAAGACACGTGTTCAAACGTGTACTGTCCGTGGAGAAGGATACGCTTATGGTCGACGTGGAAGGCTCCACAGCACTCTCTAACAGGCGAATCAACTGCTGGTCCACGTTTAAGGATCTTGAACGTGATTCATGCAAGGGTGTCTATGGCAACGTCAGCAAGAACGCCCTCTTAGTTTATTATTGTTGGATGTCAGATACTGTGTCTAAGGCATCCTCATTTGTATCTTTCGACCTTGATTATGTCGGTTGATTAATGATAAATTAAGCATTTATTCTATTAATGGATAGTCCAATTATGAACAACGAAACATGAATGTTATTGCAATGATTTTGGCTGAGAAGCCCTACAATTACTATTAATACACTCTTGGACAGTTGTCCTAACTAGTTCGTTTAATTGGCCCATCGACATCGTGATGTTCGATACCGCTCTCTGGGCTCCCACAATAGAAGCAGACTCTCCTGGGTCCAGAACGCTGGTCCCCAGCCTGTTCAGGTGTCTGTATGGGTGGATCTCGTTCTCCACCTCCGAATCCGCATCTGATTGGGCCACGCCTATGGTGCTTCTGGAAGCCCACGACTCACCAGGCCTGATTTCAATTGGGCCTCTTAATCCAACCCTGGACATGGACCCGCATCTGATGGGCTTCCTTTCCCATCTTCCGTAGTCGACGTGGGAGAAGTCCACATCTTTATCGGTGAACTGTTTGGACAGGATTTTCACTGTCGGTGCCCGGAAGGGTATATCTACGGAGTGCTTCGCCGTCGACAATTTCAGCTTCCCCTTGAACTTCGCGAAGTGGGTCCTCTGATGAACATTCGTATCGCAGACCCTGTAGTACAATTTCCATGGAATTGGGTCCTTGAGCGAGAAGAACGAAGCTGAAAAGTAGTGGAGATCTATGTTGCATCTGATCGGAAAAGTCCACGACGCCTGCAAATACTCGTTGTCCGTCATCCTTTTGTCGTGGATCTCCACTATCACCGAACCCGTCGCGTTGATGGGTACCTGCTGCCTGTACTCTATGACGCAGTGGTCGATCTTCATACAGCTACGACTGAGCCTCGCCGTCAACTGCGACGCCGTCGACGGGAATTGCAGAATTATCTCAGTTAGGTCATGTGAAAGTTGATACTCGTCCCGGTGAGACTCTATGTAGTTGAAGGCACTCGGAGGATTTACTAACTGAGATTCCATTTGAAGAAGAAAGGCCGCGCAGCGGAACCGATTGCTGAAGTTGAATCGACAAAAGATGTCAGGAATTCTCGTGAAGAACAGTATATGAACCCCCGTTGAAGATGAACGCTTTTTCTGGGAAACCCAGAAAGTTGGTGAAGAAGTTGATGAACACTCGTCTAACCACTTTTGAAAGTGGGTAGGTTGTTGAGAAAGAGGAGAAATCTGGTGATGAAAGTTTAGGATTATAGTGAGTTAGATCTGGTAGTGTCTATAAATAGACCCAGATTTTATGTTGTTGGTAAAGAACGTCTAGGAGAAGTTTTCACTTCTGTTTAAT
Gene Information
|
NCBI Accession
|
NP_049345.1
|
|
Location
|
359-1114 |
|
Gene Name
|
AV1 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGCCTAAGCGCGAATTGCCATGGCGCTCTATGGCGGGAACCTCAAAGGTTAGCCGCAACGCTAATTATTCTCCTCGTGCAGGTAGTGGGCCAAGAGTTCACAAGGCCTCTGAATGGGTAAACAGGCCCATGTACAGGAAGCCCAGGATCTACCGGATGGTGAGGACCCCCGATGTGCCCAGAGGCTGTGAAGGCCCTTGCAAGGTCCAGTCTTATGAACAGCGTCACGACATCTCCCATGTCGGGAAGGTCATGTGCATTTCCGATGTGACACGTGGTAATGGCATTACCCACCGTGTGGGTAAGCGTTTCTGTGTTAAGTCTGTGTATATTCTAGGGAAGATTTGGATGGACGAGAACATTAAGCTGAAGAACCACACGAACAGTGTCATGTTCTGGTTGGTCAGAGACCGTAGACCGTATGGCACGCCTATGGATTTCGGTCAGGTGTTCAACATGTTCGATAACGAGCCTAGTACTGCCACGGTGAAGAACGATCTCCGTGATCGTTACCAGGTCATGCATAAGTTCTATGGCAAGGTCACTGGTGGACAGTATGCCAGCAACGAGCAGGCTATAGTGAAGAGATTCTGGAAGGTCAACAATCATGTGGTCTACAATCATCAAGAGGCTGGCAAGTATGAGAATCACACTGAGAACGCCCTGTTATTGTATATGGCATGTACCCATGCCTCTAATCCTGTGTATGCAACTCTGAAGATCCGAATCTATTTCTATGATTCGCTTATGAATTAA |
|
Protein Sequence
|
MPKRELPWRSMAGTSKVSRNANYSPRAGSGPRVHKASEWVNRPMYRKPRIYRMVRTPDVPRGCEGPCKVQSYEQRHDISHVGKVMCISDVTRGNGITHRVGKRFCVKSVYILGKIWMDENIKLKNHTNSVMFWLVRDRRPYGTPMDFGQVFNMFDNEPSTATVKNDLRDRYQVMHKFYGKVTGGQYASNEQAIVKRFWKVNNHVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSLMN |
|
NCBI Accession
|
NP_049346.1
|
|
Location
|
1111-1509 |
|
Gene Name
|
AC3 |
|
Protein Name
|
AC3 |
|
Coding Region
|
ATGGATTCACGCACAGGGGAATTCATCACTGCACATCAGGCGGAGAATGGCGTGTATATCTGGGAGATAGAAAATCCCCTCTATTTCAGGATATACAGTGTAGAGGACCCGCTATACACCAGAACGAGGATATACCACGTACAGATAAGGTTCAACCACAACCTGAGGAGAGCGTTGCATCTCCACAAAGCCTTCCTGAACTTCCAAGTTTGGACGACATCGATGACAGCTTCTGGGTCAACTTATTTAGCTAGGTTTCTGCGTTTGGTCAACATGTACTTAGATCAATTAGGCATTATCTCCTTAAACAATGTAATTAGAGCTGTACGTTTCGCGACAGACAGAGCGTATGTAAATCATGTACTGGAAAATCATTCAATAAAATTCAAATTTTATTAA |
|
Protein Sequence
|
MDSRTGEFITAHQAENGVYIWEIENPLYFRIYSVEDPLYTRTRIYHVQIRFNHNLRRALHLHKAFLNFQVWTTSMTASGSTYLARFLRLVNMYLDQLGIISLNNVIRAVRFATDRAYVNHVLENHSIKFKFY |
|
NCBI Accession
|
NP_049347.1
|
|
Location
|
1256-1645 |
|
Gene Name
|
AC2 |
|
Protein Name
|
transactivator protein |
|
Coding Region
|
ATGCGATCTTCATCACCCTCACAGCCCCCCTCTATCAAGCAAGCACACAGGCAGGCCAAGAGGAGGGCCATACGGAGGCGGAGAATTGACCTAAATTGCGGGTGCTCCATCTACTTCCACATAGGCTGTACGGGACATGGATTCACGCACAGGGGAATTCATCACTGCACATCAGGCGGAGAATGGCGTGTATATCTGGGAGATAGAAAATCCCCTCTATTTCAGGATATACAGTGTAGAGGACCCGCTATACACCAGAACGAGGATATACCACGTACAGATAAGGTTCAACCACAACCTGAGGAGAGCGTTGCATCTCCACAAAGCCTTCCTGAACTTCCAAGTTTGGACGACATCGATGACAGCTTCTGGGTCAACTTATTTAGCTAG |
|
Protein Sequence
|
MRSSSPSQPPSIKQAHRQAKRRAIRRRRIDLNCGCSIYFHIGCTGHGFTHRGIHHCTSGGEWRVYLGDRKSPLFQDIQCRGPAIHQNEDIPRTDKVQPQPEESVASPQSLPELPSLDDIDDSFWVNLFS |
|
NCBI Accession
|
NP_049348.1
|
|
Location
|
1557-2642 |
|
Gene Name
|
AC1 |
|
Protein Name
|
replication associated protein |
|
Coding Region
|
ATGCCACCGCCAAAGAAATTTAGAGTTCAGTCCAAAAACTATTTGGTCACTTATCCACAGTGCTCTCTGACCAAAGAAGAAGCACTTTCCCAATTACAAAGCCTAAATACCACAGTGAACAAGAAGTTCATCAAAATCTGCAGAGAGCTTCACGAAAATGGGGAGCCTCATCTCCATGTGCTCTTACAGTTCGAAGGGAAATACCAGTGCACGAATAACAGATTCTTCGATCTGGTCTCCCCAACCAGGTCAGCACATTTCCATCCAAACATACAGGGAGCTAAATCCAGCTCCGACGTCAAGTCTTACATCGACAAGGACGGTGATACAGTGGAATGGGGAGAGTTCCAGATCGACGGCAGATCAGCTAGAGGAGGCCAGCAGACTGCTAATGATTCATATGCAAAGGCGTTAAATGCAGATTCTGTTCAATCTGCCTTAGCGGTTTTAAGGGAAGAACAGCCAAAAGATTTTGTCTTGCAGAATCATAACATCCGCTCCAACTTAGAGAGGATATTCGCCAAGGCTCCGGAACCGTGGGTTCCTCCATTTCAACTCTCCTCTTTCACTAACGTTCCCGACGAGATGCAAGAATGGGCGGATGAATTTTTTGGTTCGGGTTCCGCTGCGCGGCCAGACAGACCATTAAGTCTCATAGTAGAAGGTGATTCAAGAACAGGGAAGACGATGTGGGCACGTGCGTTAGGCCCACATAATTACCTCAGTGGACACCTGGACTTCAATGGTCGAGTCTATTCGAACGAAGTGGAGTATAACGTCATTGATGACGTCGCACCGCAATATCTAAAGCTAAAGCACTGGAAAGAATTGCTGGGGGCCCAAAAAGATTGGCAGTCAAATTGCAAATACGGCAAGCCAGTTCAAATTAAAGGTGGAATCCCAGCAATCGTGCTTTGCAATCCTGGTGAGGGTGCCAGCTATAAAGAGTTCCTAGACAAGGAGGAAAATACAGGTCTCAGGAACTGGACTATCAAGAATGCGATCTTCATCACCCTCACAGCCCCCCTCTATCAAGCAAGCACACAGGCAGGCCAAGAGGAGGGCCATACGGAGGCGGAGAATTGA |
|
Protein Sequence
|
MPPPKKFRVQSKNYLVTYPQCSLTKEEALSQLQSLNTTVNKKFIKICRELHENGEPHLHVLLQFEGKYQCTNNRFFDLVSPTRSAHFHPNIQGAKSSSDVKSYIDKDGDTVEWGEFQIDGRSARGGQQTANDSYAKALNADSVQSALAVLREEQPKDFVLQNHNIRSNLERIFAKAPEPWVPPFQLSSFTNVPDEMQEWADEFFGSGSAARPDRPLSLIVEGDSRTGKTMWARALGPHNYLSGHLDFNGRVYSNEVEYNVIDDVAPQYLKLKHWKELLGAQKDWQSNCKYGKPVQIKGGIPAIVLCNPGEGASYKEFLDKEENTGLRNWTIKNAIFITLTAPLYQASTQAGQEEGHTEAEN |
|
NCBI Accession
|
NP_049349.1
|
|
Location
|
2228-2485 |
|
Gene Name
|
AC4 |
|
Protein Name
|
AC4 |
|
Coding Region
|
ATGGGGAGCCTCATCTCCATGTGCTCTTACAGTTCGAAGGGAAATACCAGTGCACGAATAACAGATTCTTCGATCTGGTCTCCCCAACCAGGTCAGCACATTTCCATCCAAACATACAGGGAGCTAAATCCAGCTCCGACGTCAAGTCTTACATCGACAAGGACGGTGATACAGTGGAATGGGGAGAGTTCCAGATCGACGGCAGATCAGCTAGAGGAGGCCAGCAGACTGCTAATGATTCATATGCAAAGGCGTTAA |
|
Protein Sequence
|
MGSLISMCSYSSKGNTSARITDSSIWSPQPGQHISIQTYRELNPAPTSSLTSTRTVIQWNGESSRSTADQLEEASRLLMIHMQRR |
|
NCBI Accession
|
NP_049350.1
|
|
Location
|
542-1318 |
|
Gene Name
|
BV1 |
|
Protein Name
|
nuclear transport protein |
|
Coding Region
|
ATGATAATGTATCCTGTGAGGGTTAAACGTGGTTATTACTTCCCTAACCGACGATTTACTACACGTAACACTGTGTTTAACCGTTCAACCGCTGGGAAACGACATGATGGGAGACGTCGAGGAGGTCGATCTGTCAAGACCAGTGATGAGCCCAAGATGTCAGCCCAATCCATACATGAGAATCAGTATGGCCCTGATTTTGTGATGTCTCACAATTCAGCCATTTCCACATTTATCAGTTATCCAGATCTGGGCAAGATAGAACCGGGTCGAAGTAGGTCCTATATCAAGTTGAAACGACTCCGTTTCAAAGGGACTGTTAAGATTGAACGTGTCACATCGGACGTGAACATGGACGGTTCTGCGCCAAAGGTCGAAGGAGTATTCTCACTGGTTGTGGTTGTGGATCGTAAACCCCACTTGACTGCATCTGGTGGTCTACATACATTCGACGAGCTGTTCGGTGCAAGGATCCACAGCCATGGTAATCTCAGCATAACCCCTTCCCTGAAAGACCGCTTTTACGTAAGACACGTGTTCAAACGTGTACTGTCCGTGGAGAAGGATACGCTTATGGTCGACGTGGAAGGCTCCACAGCACTCTCTAACAGGCGAATCAACTGCTGGTCCACGTTTAAGGATCTTGAACGTGATTCATGCAAGGGTGTCTATGGCAACGTCAGCAAGAACGCCCTCTTAGTTTATTATTGTTGGATGTCAGATACTGTGTCTAAGGCATCCTCATTTGTATCTTTCGACCTTGATTATGTCGGTTGA |
|
Protein Sequence
|
MIMYPVRVKRGYYFPNRRFTTRNTVFNRSTAGKRHDGRRRGGRSVKTSDEPKMSAQSIHENQYGPDFVMSHNSAISTFISYPDLGKIEPGRSRSYIKLKRLRFKGTVKIERVTSDVNMDGSAPKVEGVFSLVVVVDRKPHLTASGGLHTFDELFGARIHSHGNLSITPSLKDRFYVRHVFKRVLSVEKDTLMVDVEGSTALSNRRINCWSTFKDLERDSCKGVYGNVSKNALLVYYCWMSDTVSKASSFVSFDLDYVG |
|
NCBI Accession
|
NP_049351.1
|
|
Location
|
1385-2266 |
|
Gene Name
|
BC1 |
|
Protein Name
|
movement/pathogenicity protein |
|
Coding Region
|
ATGGAATCTCAGTTAGTAAATCCTCCGAGTGCCTTCAACTACATAGAGTCTCACCGGGACGAGTATCAACTTTCACATGACCTAACTGAGATAATTCTGCAATTCCCGTCGACGGCGTCGCAGTTGACGGCGAGGCTCAGTCGTAGCTGTATGAAGATCGACCACTGCGTCATAGAGTACAGGCAGCAGGTACCCATCAACGCGACGGGTTCGGTGATAGTGGAGATCCACGACAAAAGGATGACGGACAACGAGTATTTGCAGGCGTCGTGGACTTTTCCGATCAGATGCAACATAGATCTCCACTACTTTTCAGCTTCGTTCTTCTCGCTCAAGGACCCAATTCCATGGAAATTGTACTACAGGGTCTGCGATACGAATGTTCATCAGAGGACCCACTTCGCGAAGTTCAAGGGGAAGCTGAAATTGTCGACGGCGAAGCACTCCGTAGATATACCCTTCCGGGCACCGACAGTGAAAATCCTGTCCAAACAGTTCACCGATAAAGATGTGGACTTCTCCCACGTCGACTACGGAAGATGGGAAAGGAAGCCCATCAGATGCGGGTCCATGTCCAGGGTTGGATTAAGAGGCCCAATTGAAATCAGGCCTGGTGAGTCGTGGGCTTCCAGAAGCACCATAGGCGTGGCCCAATCAGATGCGGATTCGGAGGTGGAGAACGAGATCCACCCATACAGACACCTGAACAGGCTGGGGACCAGCGTTCTGGACCCAGGAGAGTCTGCTTCTATTGTGGGAGCCCAGAGAGCGGTATCGAACATCACGATGTCGATGGGCCAATTAAACGAACTAGTTAGGACAACTGTCCAAGAGTGTATTAATAGTAATTGTAGGGCTTCTCAGCCAAAATCATTGCAATAA |
|
Protein Sequence
|
MESQLVNPPSAFNYIESHRDEYQLSHDLTEIILQFPSTASQLTARLSRSCMKIDHCVIEYRQQVPINATGSVIVEIHDKRMTDNEYLQASWTFPIRCNIDLHYFSASFFSLKDPIPWKLYYRVCDTNVHQRTHFAKFKGKLKLSTAKHSVDIPFRAPTVKILSKQFTDKDVDFSHVDYGRWERKPIRCGSMSRVGLRGPIEIRPGESWASRSTIGVAQSDADSEVENEIHPYRHLNRLGTSVLDPGESASIVGAQRAVSNITMSMGQLNELVRTTVQECINSNCRASQPKSLQ |